Regional disaster recovery for Azure Databricks clusters
This article describes a disaster recovery architecture useful for Azure Databricks clusters, and the steps to accomplish that design.
Azure Databricks architecture
When you create an Azure Databricks workspace from the Azure portal, a managed application is deployed as an Azure resource in your subscription, in the chosen Azure region (for example, West US). This appliance is deployed in an Azure Virtual Network with a Network Security Group and an Azure Storage account, available in your subscription. The virtual network provides perimeter level security to the Databricks workspace, and is protected via network security group. Within the workspace, you create Databricks clusters by providing the worker and driver VM type and Databricks runtime version. The persisted data is available in your storage account. Once the cluster is created, you can run jobs via notebooks, REST APIs, or ODBC/JDBC endpoints, by attaching them to a specific cluster.
The Databricks control plane manages and monitors the Databricks workspace environment. Any management operation, such as create cluster, will be initiated from the control plane. All metadata, such as scheduled jobs, is stored in an Azure Database, and the database backups are automatically geo-replicated for into paired regions where it's implemented.
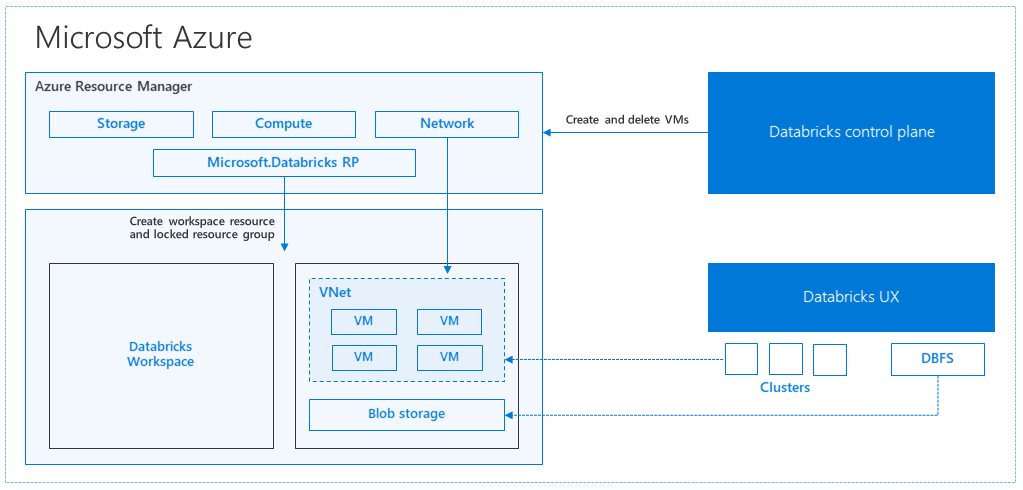
One of the advantages of this architecture is that users can connect Azure Databricks to any storage resource in their account. A key benefit is that both compute (Azure Databricks) and storage can be scaled independently of each other.
How to create a regional disaster recovery topology
In the preceding architecture description, there are a number of components used for a Big Data pipeline with Azure Databricks: Azure Storage, Azure Database, and other data sources. Azure Databricks is the compute for the Big Data pipeline. It is ephemeral in nature, meaning that while your data is still available in Azure Storage, the compute (Azure Databricks cluster) can be terminated to avoid paying for compute when you don’t need it. The compute (Azure Databricks) and storage sources must be in the same region so that jobs don’t experience high latency.
To create your own regional disaster recovery topology, follow these requirements:
Provision multiple Azure Databricks workspaces in separate Azure regions. For example, create the primary Azure Databricks workspace in East US. Create the secondary disaster-recovery Azure Databricks workspace in a separate region, such as West US. For a list of paired Azure regions, see Cross-region replication. For details about Azure Databricks regions, see Supported regions.
Use geo-redundant storage. By default, the data associated with Azure Databricks is stored in Azure Storage and the results from Databricks jobs are stored in Azure Blob Storage, so that the processed data is durable and remains highly available after the cluster is terminated. The cluster storage and job storage are located in the same availability zone. To protect against regional unavailability, Azure Databricks workspaces use geo-redundant storage by default. With geo-redundant storage, data is replicated to an Azure paired region. Databricks recommends that you keep the geo-redundant storage default, but if you need to use locally-redundant storage instead, you can set
storageAccountSkuNametoStandard_LRSin the ARM template for the workspace.Once the secondary region is created, you must migrate the users, user folders, notebooks, cluster configuration, jobs configuration, libraries, storage, init scripts, and reconfigure access control. Additional details are outlined in the following section.
Regional disaster
To prepare for regional disasters, you need to explicitly maintain another set of Azure Databricks workspaces in a secondary region. See Disaster recovery.
Our recommended tools for disaster recovery are mainly Terraform (for Infra replication) and Delta Deep Clone (for Data replication).
Detailed migration steps
Install the Databricks CLI
The examples in this article use the Databricks command-line interface (CLI), which is an easy-to-use wrapper over the Azure Databricks REST API.
Before performing any migration steps, install the Databricks CLI on your local computer or virtual machine. For more information, see Install the Databricks CLI.
Note
The Python scripts provided in this article work with Python 2.7 and above.
Configure two profiles.
Following the steps in _, configure two profiles: one for the primary workspace, and another one for the secondary workspace.
databricks configure --profile primary databricks configure --profile secondaryThe code blocks in this article switch between profiles in each subsequent step using the corresponding workspace command. Be sure that the names of the profiles you create are substituted into each code block.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"You can manually switch at the command line if needed:
databricks workspace list --profile primary databricks workspace list --profile secondaryMigrate Microsoft Entra ID (formerly Azure Active Directory) users
Manually add the same Microsoft Entra ID (formerly Azure Active Directory) users to the secondary workspace that exist in primary workspace.
Migrate the user folders and notebooks
Use the following python code to migrate the sandboxed user environments, which include the nested folder structure and notebooks per user.
Note
Libraries are not copied over in this step, as the underlying API doesn't support those.
Copy and save the following python script to a file, and run it at the command line. For example,
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "list", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")Migrate the cluster configurations
Once notebooks have been migrated, you can optionally migrate the cluster configurations to the new workspace. It's almost a fully automated step using the Databricks CLI, unless you would like to do selective cluster config migration.
Note
There is no create cluster config endpoint, and this script tries to create each cluster right away. If there aren't enough cores available in your subscription, the cluster creation may fail. The failure can be ignored, as long as the configuration is transferred successfully.
The following script provided prints a mapping from old to new cluster IDs, which could be used for job migration later (for jobs that are configured to use existing clusters).
Copy and save the following python script to a file, and run it at the command line. For example,
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")).splitlines() print("Printing Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append(cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")Migrate the jobs configuration
If you migrated cluster configurations in the previous step, you can opt to migrate job configurations to the new workspace. It is a fully automated step using the Databricks CLI, unless you would like to do selective job config migration rather than doing it for all jobs.
Note
The configuration for a scheduled job contains the "schedule" information as well, so by default that will start working as per configured timing as soon as it's migrated. Hence, the following code block removes any schedule information during the migration (to avoid duplicate runs across old and new workspaces). Configure the schedules for such jobs once you're ready for cutover.
The job configuration requires settings for a new or an existing cluster. If using existing cluster, the script /code below will attempt to replace the old cluster ID with new cluster ID.
Copy and save the following python script to a file. Replace the value for
old_cluster_idandnew_cluster_id, with the output from cluster migration done in previous step. Run it at the command line, for example,python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate " + str(job)) job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id " + str(job_req_settings_json['existing_cluster_id'])) continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Migrate libraries
There's currently no straightforward way to migrate libraries from one workspace to another. Instead, reinstall those libraries into the new workspace manually. You can automate this using the Databricks CLI to upload custom libraries to the workspace.
Migrate Azure blob storage and Azure Data Lake Storage mounts
Manually remount all Azure Blob storage and Azure Data Lake Storage (Gen 2) mount points using a notebook-based solution. The storage resources would have been mounted in the primary workspace, and that has to be repeated in the secondary workspace. There is no external API for mounts.
Migrate cluster init scripts
Any cluster initialization scripts can be migrated from old to new workspace using the Databricks CLI. First, copy the needed scripts to your local desktop or virtual machine. Next, copy those scripts into the new workspace at the same path.
Note
If you have initialization scripts stored in DBFS, migrate them to a supported location first. See _.
// Primary to local databricks fs cp dbfs:/Volumes/my_catalog/my_schema/my_volume/ ./old-ws-init-scripts --profile primary // Local to Secondary workspace databricks fs cp old-ws-init-scripts dbfs:/Volumes/my_catalog/my_schema/my_volume/ --profile secondaryManually reconfigure and reapply access control.
If your existing primary workspace is configured to use the Premium or Enterprise tier (SKU), it's likely you also are using the Access control.
If you do use the Access control, manually reapply the access control to the resources (Notebooks, Clusters, Jobs, Tables).
Disaster recovery for your Azure ecosystem
If you are using other Azure services, be sure to implement disaster recovery best practices for those services, too. For example, if you choose to use an external Hive metastore instance, you should consider disaster recovery for Azure SQL Database, Azure HDInsight, and/or Azure Database for MySQL. For general information about disaster recovery, see Disaster recovery for Azure applications.
Next steps
For more information, see Azure Databricks documentation.