Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
With custom speech, you can evaluate and improve the accuracy of speech recognition for your applications and products. A custom speech model can be used for real-time speech to text, speech translation, and batch transcription.
Out of the box, speech recognition utilizes a Universal Language Model as a base model that is trained with Microsoft-owned data and reflects commonly used spoken language. The base model is pretrained with dialects and phonetics representing various common domains. When you make a speech recognition request, the most recent base model for each supported language is used by default. The base model works well in most speech recognition scenarios.
A custom model can be used to augment the base model to improve recognition of domain-specific vocabulary specific to the application by providing text data to train the model. It can also be used to improve recognition based for the specific audio conditions of the application by providing audio data with reference transcriptions.
You can also train a model with structured text when the data follows a pattern, to specify custom pronunciations, and to customize display text formatting with custom inverse text normalization, custom rewrite, and custom profanity filtering.
How does it work?
With custom speech, you can upload your own data, test and train a custom model, compare accuracy between models, and deploy a model to a custom endpoint.
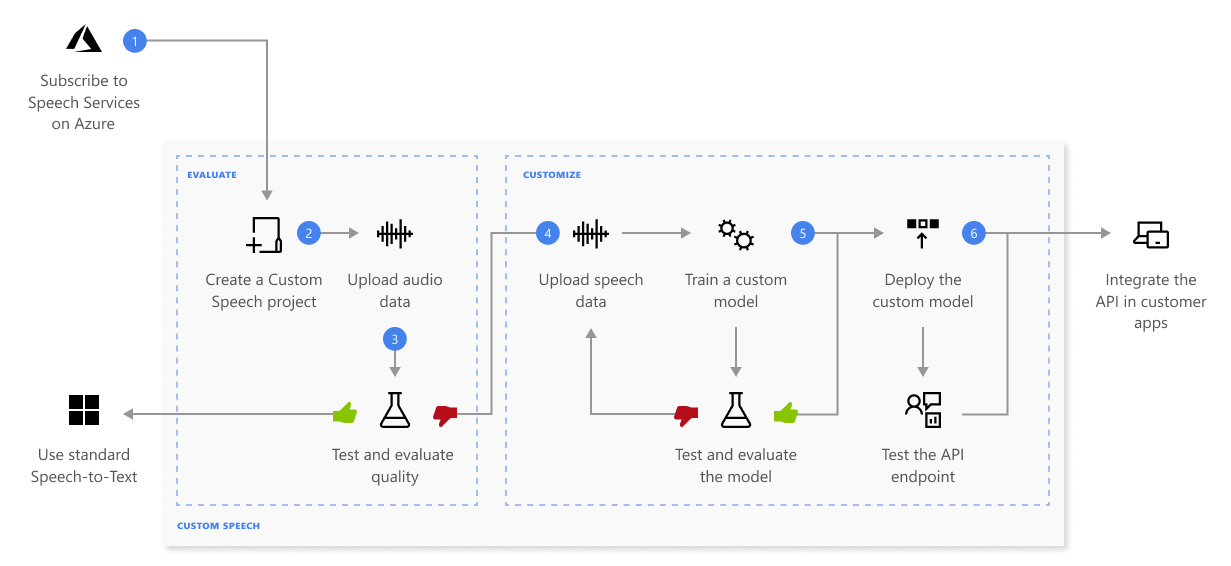
Here's more information about the sequence of steps shown in the previous diagram:
Create a project and choose a model. If you train a custom model with audio data, select a service resource in a region with dedicated hardware for training audio data. For more information, see footnotes in the regions table.
Upload test data. Upload test data to evaluate the speech to text offering for your applications, tools, and products.
Train a model. Provide written transcripts and related text, along with the corresponding audio data. Testing a model before and after training is optional but recommended.
Note
You pay for custom speech model usage and endpoint hosting. You're also charged for custom speech model training if the base model was created on October 1, 2023 and later. You're not charged for training if the base model was created prior to October 2023. For more information, see Azure Speech in Foundry Tools pricing and the Charge for adaptation section in the speech to text 3.2 migration guide.
Test recognition quality. Use the Speech Studio to play back uploaded audio and inspect the speech recognition quality of your test data.
Test model quantitatively. Evaluate and improve the accuracy of the speech to text model. The Speech service provides a quantitative word error rate (WER), which you can use to determine if more training is required.
Deploy a model. Once you're satisfied with the test results, deploy the model to a custom endpoint. Except for batch transcription, you must deploy a custom endpoint to use a custom speech model.
Tip
A hosted deployment endpoint isn't required to use custom speech with the Batch transcription API. You can conserve resources if the custom speech model is only used for batch transcription. For more information, see Speech service pricing.
Choose your model
There are a few approaches to using custom speech models:
- The base model provides accurate speech recognition out of the box for a range of scenarios. Base models are updated periodically to improve accuracy and quality. We recommend that if you use base models, use the latest default base models. If a required customization capability is only available with an older model, then you can choose an older base model.
- A custom model augments the base model to include domain-specific vocabulary shared across all areas of the custom domain.
- Multiple custom models can be used when the custom domain has multiple areas, each with a specific vocabulary.
One recommended way to see if the base model suffices is to analyze the transcription produced from the base model and compare it with a human-generated transcript for the same audio. You can compare the transcripts and obtain a word error rate (WER) score. If the WER score is high, training a custom model to recognize the incorrectly identified words is recommended.
Multiple models are recommended if the vocabulary varies across the domain areas. For instance, Olympic commentators report on various events, each associated with its own vernacular. Because each Olympic event vocabulary differs significantly from others, building a custom model specific to an event increases accuracy by limiting the utterance data relative to that particular event. As a result, the model doesn't need to sift through unrelated data to make a match. Regardless, training still requires a decent variety of training data. Include audio from various commentators who have different accents, gender, age, etcetera.
Model stability and lifecycle
A base model or custom model deployed to an endpoint using custom speech is fixed until you decide to update it. The speech recognition accuracy and quality remain consistent, even when a new base model is released. This allows you to lock in the behavior of a specific model until you decide to use a newer model.
Whether you train your own model or use a snapshot of a base model, you can use the model for a limited time. For more information, see Model and endpoint lifecycle.
Responsible AI
An AI system includes not only the technology, but also the people who use it, the people who are affected by it, and the environment in which it's deployed. Read the transparency notes to learn about responsible AI use and deployment in your systems.
- Transparency note and use cases
- Characteristics and limitations
- Integration and responsible use
- Data, privacy, and security