Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
Azure Cosmos DB for PostgreSQL is no longer supported for new projects. Don't use this service for new projects. Instead, use one of these two services:
Use Azure Cosmos DB for NoSQL for a distributed database solution designed for high-scale scenarios with a 99.999% availability service level agreement (SLA), instant autoscale, and automatic failover across multiple regions.
Use the Elastic Clusters feature of Azure Database For PostgreSQL for sharded PostgreSQL using the open-source Citus extension.
Choosing each table's distribution column is one of the most important modeling decisions you'll make. Azure Cosmos DB for PostgreSQL stores rows in shards based on the value of the rows' distribution column.
The correct choice groups related data together on the same physical nodes, which makes queries fast and adds support for all SQL features. An incorrect choice makes the system run slowly.
General tips
Here are four criteria for choosing the ideal distribution column for your distributed tables.
Pick a column that is a central piece in the application workload.
You might think of this column as the "heart," "central piece," or "natural dimension" for partitioning data.
Examples:
device_idin an IoT workloadsecurity_idfor a financial app that tracks securitiesuser_idin user analyticstenant_idfor a multi-tenant SaaS application
Pick a column with decent cardinality, and an even statistical distribution.
The column should have many values, and distribute thoroughly and evenly between all shards.
Examples:
- Cardinality over 1000
- Don't pick a column that has the same value on a large percentage of rows (data skew)
- In a SaaS workload, having one tenant much bigger than the rest can cause data skew. For this situation, you can use tenant isolation to create a dedicated shard to handle the tenant.
Pick a column that benefits your existing queries.
For a transactional or operational workload (where most queries take only a few milliseconds), pick a column that appears as a filter in
WHEREclauses for at least 80% of queries. For instance, thedevice_idcolumn inSELECT * FROM events WHERE device_id=1.For an analytical workload (where most queries take 1-2 seconds), pick a column that enables queries to be parallelized across worker nodes. For instance, a column frequently occurring in GROUP BY clauses, or queried over multiple values at once.
Pick a column that is present in the majority of large tables.
Tables over 50 GB should be distributed. Picking the same distribution column for all of them enables you to co-locate data for that column on worker nodes. Co-location makes it efficient to run JOINs and rollups, and enforce foreign keys.
The other (smaller) tables can be local or reference tables. If the smaller table needs to JOIN with distributed tables, make it a reference table.
Use-case examples
We've seen general criteria for picking the distribution column. Now let's see how they apply to common use cases.
Multi-tenant apps
The multi-tenant architecture uses a form of hierarchical database modeling to distribute queries across nodes in the cluster. The top of the data hierarchy is known as the tenant ID and needs to be stored in a column on each table.
Azure Cosmos DB for PostgreSQL inspects queries to see which tenant ID they involve and finds the matching table shard. It routes the query to a single worker node that contains the shard. Running a query with all relevant data placed on the same node is called colocation.
The following diagram illustrates colocation in the multi-tenant data model. It contains two tables, Accounts and Campaigns, each distributed by account_id. The shaded boxes represent shards. Green shards are stored together on one worker node, and blue shards are stored on another worker node. Notice how a join query between Accounts and Campaigns has all the necessary data together on one node when both tables are restricted to the same account_id.
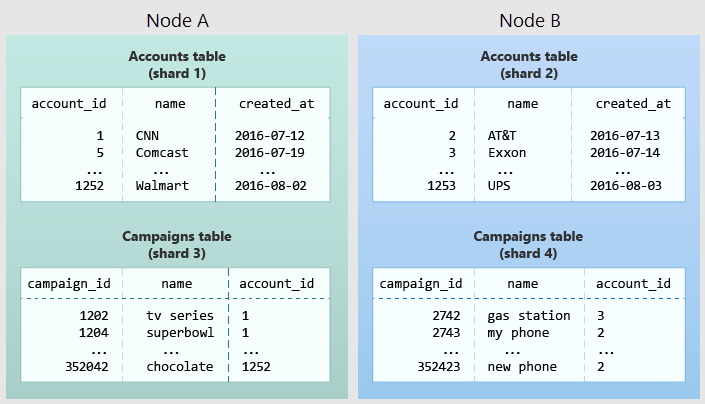
To apply this design in your own schema, identify what constitutes a tenant in your application. Common instances include company, account, organization, or customer. The column name will be something like company_id or customer_id. Examine each of your queries and ask yourself, would it work if it had more WHERE clauses to restrict all tables involved to rows with the same tenant ID? Queries in the multi-tenant model are scoped to a tenant. For instance, queries on sales or inventory are scoped within a certain store.
Best practices
- Distribute tables by a common tenant_id column. For instance, in a SaaS application where tenants are companies, the tenant_id is likely to be the company_id.
- Convert small cross-tenant tables to reference tables. When multiple tenants share a small table of information, distribute it as a reference table.
- Restrict filter all application queries by tenant_id. Each query should request information for one tenant at a time.
Read the multi-tenant tutorial for an example of how to build this kind of application.
Real-time apps
The multi-tenant architecture introduces a hierarchical structure and uses data colocation to route queries per tenant. By contrast, real-time architectures depend on specific distribution properties of their data to achieve highly parallel processing.
We use "entity ID" as a term for distribution columns in the real-time model. Typical entities are users, hosts, or devices.
Real-time queries typically ask for numeric aggregates grouped by date or category. Azure Cosmos DB for PostgreSQL sends these queries to each shard for partial results and assembles the final answer on the coordinator node. Queries run fastest when as many nodes contribute as possible, and when no single node must do a disproportionate amount of work.
Best practices
- Choose a column with high cardinality as the distribution column. For comparison, a Status field on an order table with values New, Paid, and Shipped is a poor choice of distribution column. It assumes only those few values, which limits the number of shards that can hold the data, and the number of nodes that can process it. Among columns with high cardinality, it's also good to choose those columns that are frequently used in group-by clauses or as join keys.
- Choose a column with even distribution. If you distribute a table on a column skewed to certain common values, data in the table tends to accumulate in certain shards. The nodes that hold those shards end up doing more work than other nodes.
- Distribute fact and dimension tables on their common columns. Your fact table can have only one distribution key. Tables that join on another key won't be colocated with the fact table. Choose one dimension to colocate based on how frequently it's joined and the size of the joining rows.
- Change some dimension tables into reference tables. If a dimension table can't be colocated with the fact table, you can improve query performance by distributing copies of the dimension table to all of the nodes in the form of a reference table.
Read the real-time dashboard tutorial for an example of how to build this kind of application.
Time-series data
In a time-series workload, applications query recent information while they archive old information.
The most common mistake in modeling time-series information in Azure Cosmos DB for PostgreSQL is to use the timestamp itself as a distribution column. A hash distribution based on time distributes times seemingly at random into different shards rather than keeping ranges of time together in shards. Queries that involve time generally reference ranges of time, for example, the most recent data. This type of hash distribution leads to network overhead.
Best practices
- Don't choose a timestamp as the distribution column. Choose a different distribution column. In a multi-tenant app, use the tenant ID, or in a real-time app use the entity ID.
- Use PostgreSQL table partitioning for time instead. Use table partitioning to break a large table of time-ordered data into multiple inherited tables with each table containing different time ranges. Distributing a Postgres-partitioned table creates shards for the inherited tables.
Next steps
- Learn how colocation between distributed data helps queries run fast.
- Discover the distribution column of a distributed table, and other useful diagnostic queries.