Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
This feature is in Beta. Account admins can control access to this feature from the account console Previews page. See Manage Azure Databricks previews.
This page describes how to configure LLM-based guardrails for Unity AI Gateway endpoints. Guardrails inspect requests and responses in real time and block or sanitize content that violates your safety, privacy, or compliance policies.
Note
This page covers LLM-based guardrails. Azure Databricks is also exploring other guardrail types, such as custom code and third-party integrations.
LLM-based guardrails use a language model as the policy evaluator. This approach offers:
- Customization: Built-in templates cover common policies, and you can supply your own prompt for custom guardrails.
- Contextual reasoning: The evaluator considers context, distinguishing actual policy violations from benign references like news reporting, fiction, or educational discussion.
Requirements
To use and configure guardrails, you must satisfy these requirements:
- Unity AI Gateway preview enabled for your account. See Manage Azure Databricks previews.
- An Azure Databricks workspace in an Unity AI Gateway supported region. See Model serving features availability.
- Unity Catalog enabled for your workspace. See Enable a workspace for Unity Catalog.
- An Unity AI Gateway endpoint that serves a supported API type.
CAN MANAGEpermission on the Unity AI Gateway endpoint.CAN MANAGEpermission on the endpoint that you select as the guardrail evaluator. System endpoints (databricks-*foundation-model endpoints) skip this check.
At query time, end users only need CAN QUERY permission on the target Unity AI Gateway endpoint. Unity AI Gateway does not check end-user permissions against the evaluator endpoint or its underlying model.
For user-created evaluator endpoints, the evaluator runs under its owner's identity (definer's permissions). If the evaluator owner loses access to the underlying model after you configure the guardrail, the guardrail call fails.
Configure guardrails on an endpoint
You configure guardrails from the Guardrails tab on the Unity AI Gateway endpoint page.
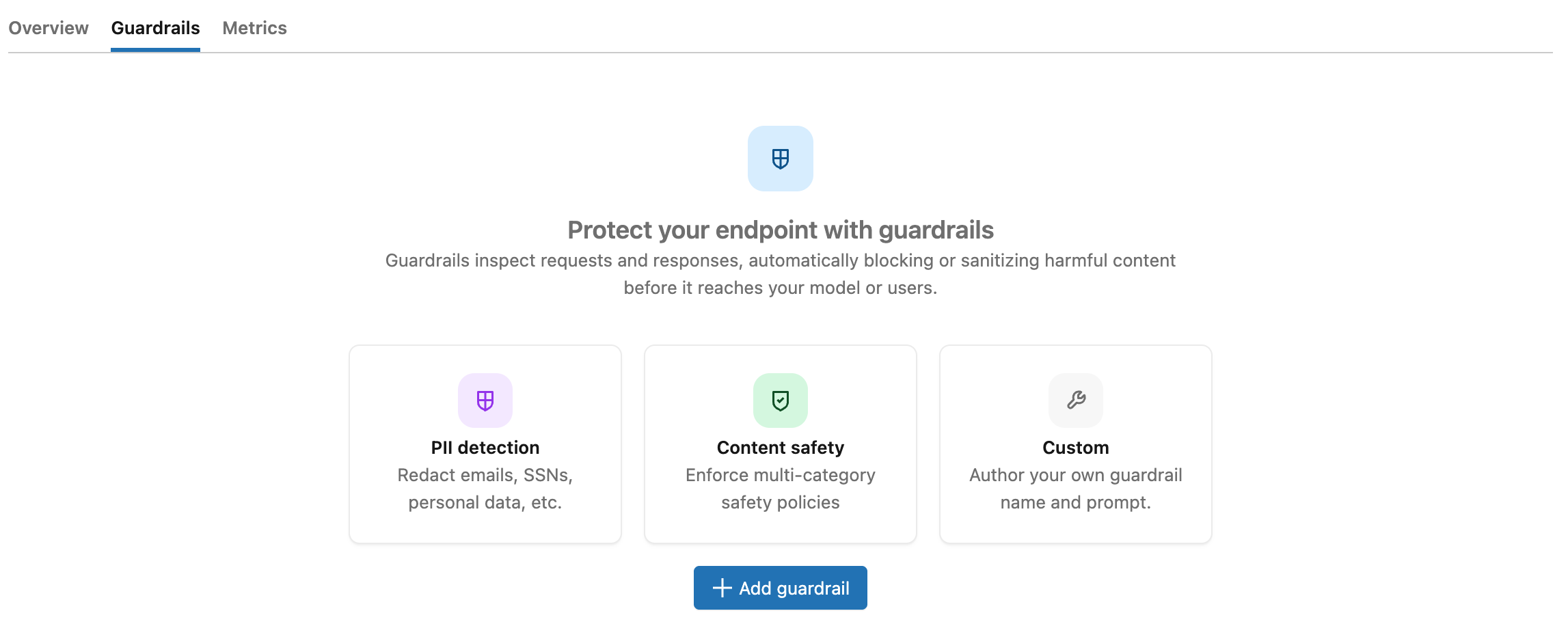
To add a guardrail:
- From the AI Gateway page, click your endpoint, and then click the Guardrails tab.
- Click
 Add guardrail.
Add guardrail. - In the Create guardrail modal, choose the Guardrail type:
- PII redaction: Detects PII and replaces it with placeholders before the model call.
- PII blocking: Blocks requests or responses that contain PII.
- Unsafe content: Blocks content that contains hate speech, violence, self-harm, or other unsafe material.
- Jailbreak: Blocks requests that attempt to bypass the model's safety constraints.
- Hallucination: Blocks responses that appear to contain fabricated or unverifiable claims.
- Custom: Supply your own prompt. See custom guardrails.
- For Phase, set the execution phase to Input or Output.
- For custom guardrails, under Action, choose Block or Sanitize. See Block and sanitize actions.
- Select an evaluator endpoint. The form auto-selects a recommended evaluator when one is available in your workspace; otherwise pick one from the dropdown.
- (Optional) Under Advanced options, choose Log to run the guardrail in dry-run mode. In dry-run mode, the guardrail evaluates the request or response and records the result, but does not enforce the action.
- Click Create guardrail.
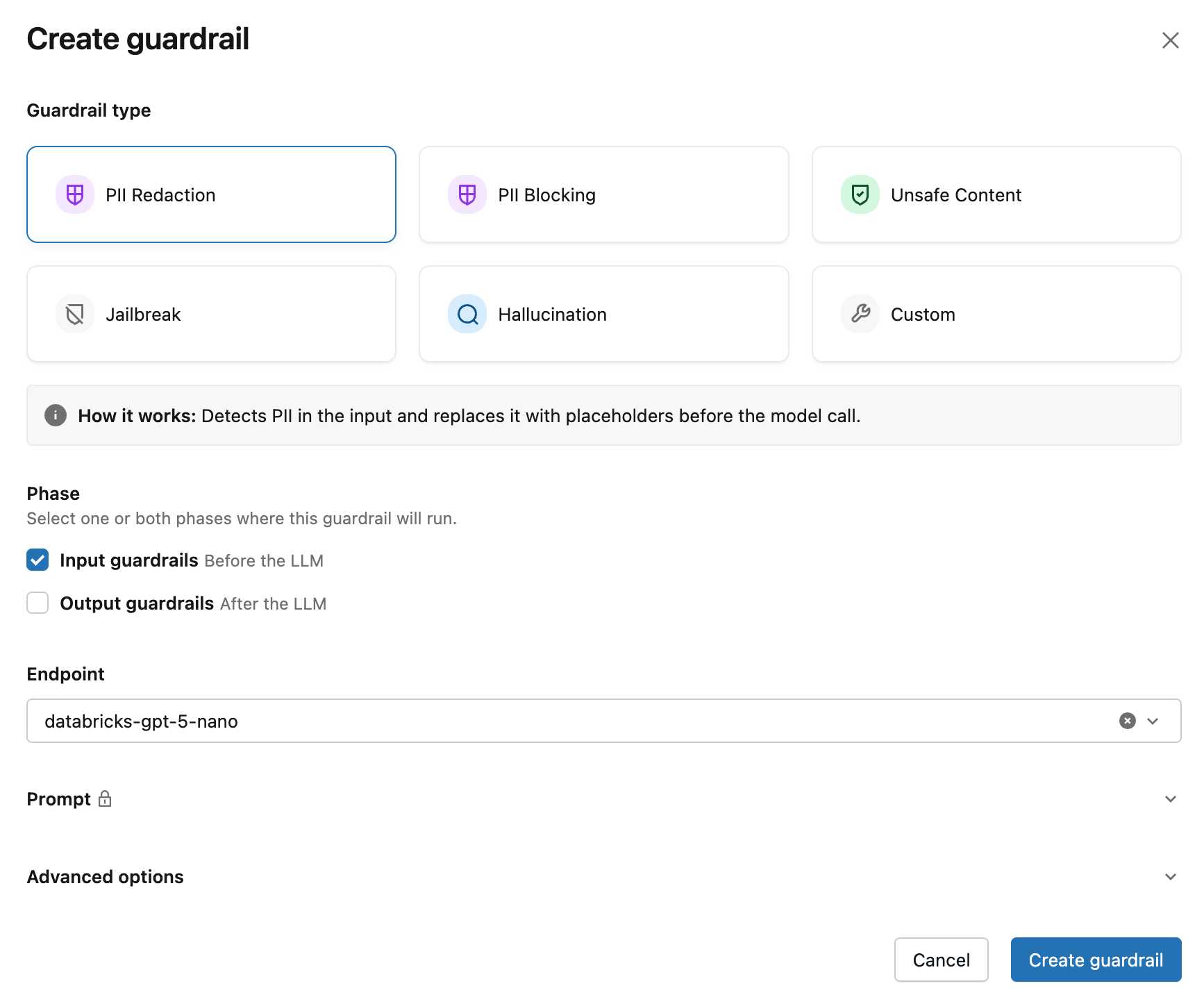
After you click Create guardrail, the new guardrail appears in the Guardrails table on the endpoint page.
How guardrails work
Two Unity AI Gateway endpoints are involved in every guardrail-protected request:
- The inference endpoint is the endpoint your client calls.
- The evaluator endpoint is the endpoint each guardrail uses to run its prompt. It can be any Unity AI Gateway endpoint that serves a supported API.
The prompt comes from a built-in template or a custom guardrail you author.
When a request arrives at an Unity AI Gateway endpoint, input guardrails evaluate the request body before it is forwarded to the destination model. If every input guardrail passes, the destination model responds, and then output guardrails evaluate the response body before it returns to the client.
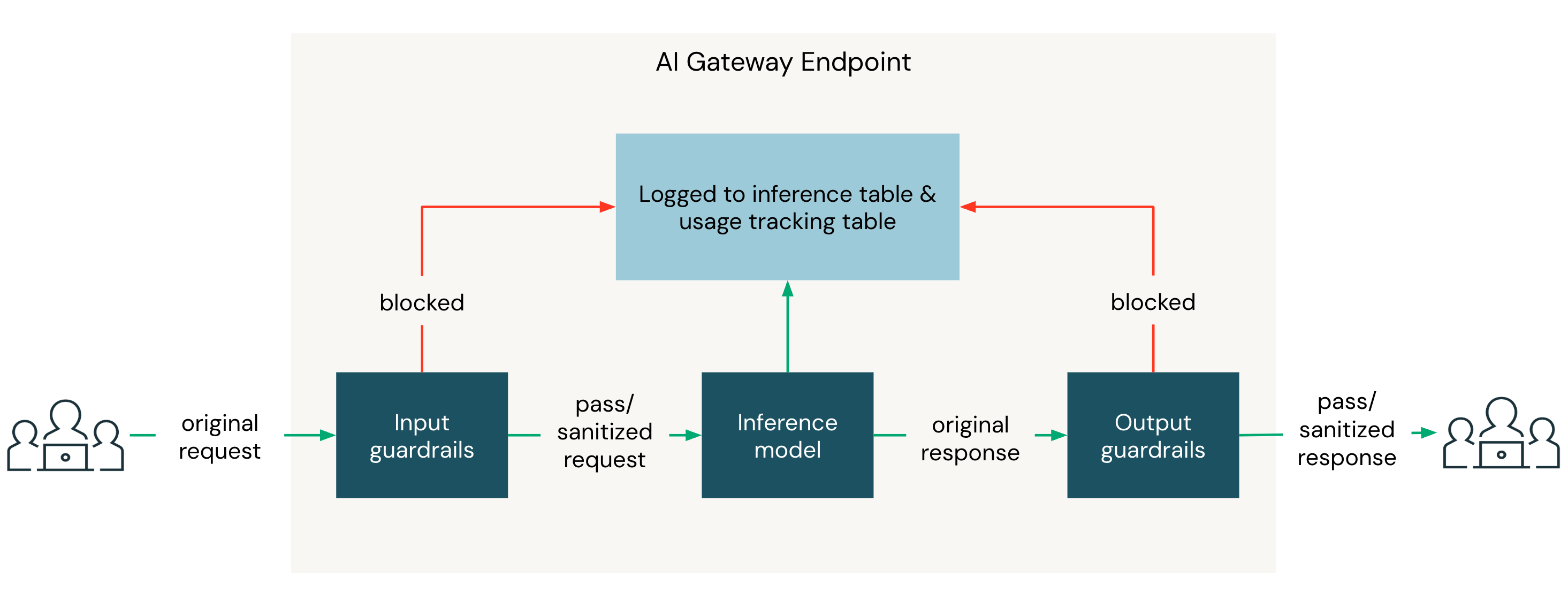
Within a phase, all blocking guardrails run in parallel. If they all pass, the sanitizing guardrail runs next. If any blocking guardrail triggers, the sanitizing guardrail does not run, and the request is blocked as soon as the first triggering guardrail returns.
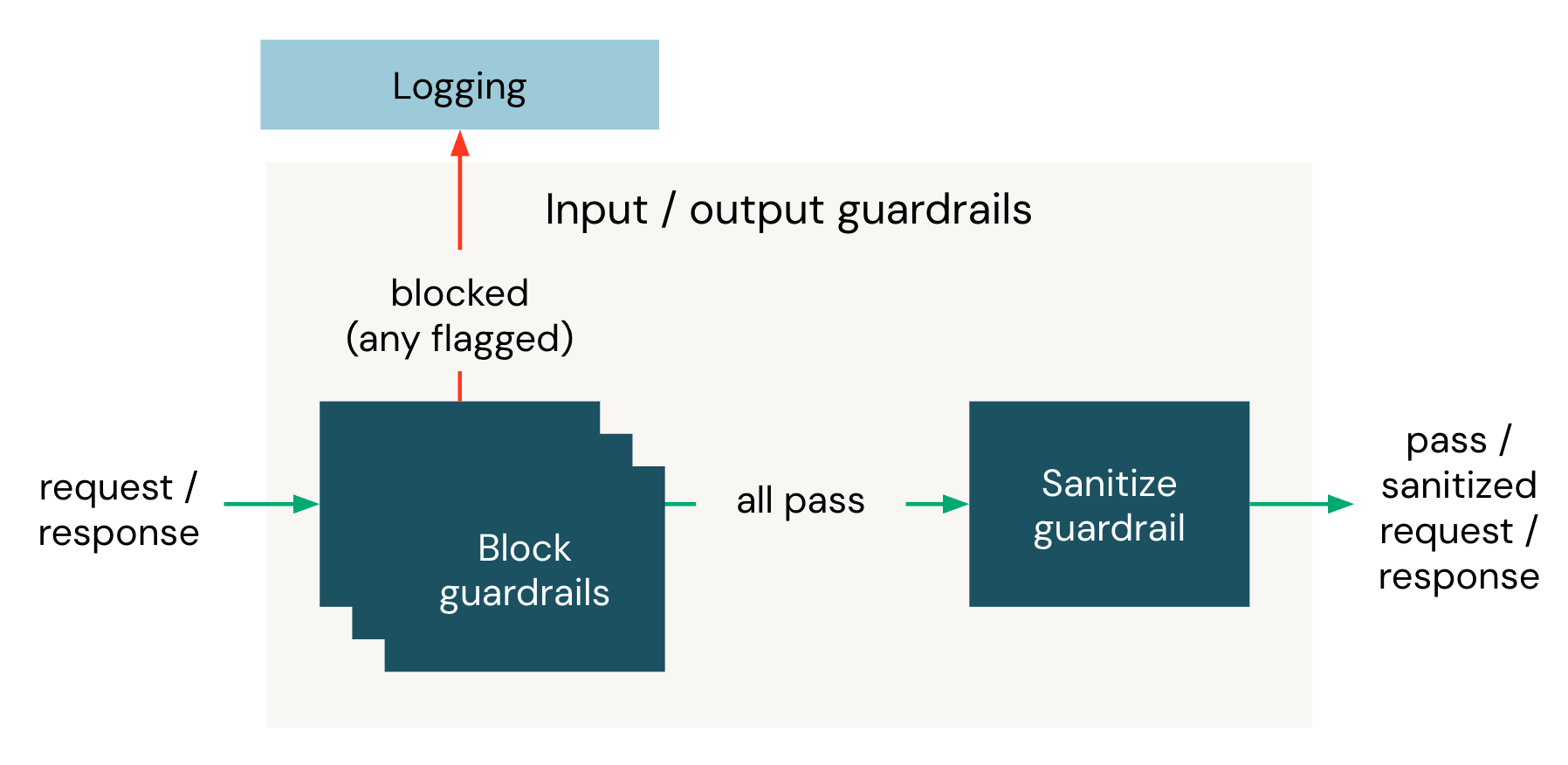
Each guardrail has the following properties:
| Property | Description |
|---|---|
| Name | A name for the guardrail. Names must be unique within an execution phase on the same endpoint. |
| Execution phase | Whether the guardrail evaluates the request (input) or the response (output). |
| Action | Whether the guardrail blocks the request or sanitizes the content when triggered. See block and sanitize actions. |
| Evaluator | The evaluator endpoint and prompt used to evaluate the content. Use a built-in template or a custom guardrail. |
| Mode | Enforce (default) applies the action when the guardrail triggers. Log evaluates the request or response and records the result without blocking or modifying content. Use Log to test a guardrail before applying it to production traffic. |
Supported API types
Guardrails work on Unity AI Gateway endpoints that serve a chat API. Unity AI Gateway extracts the text of the most recent message and evaluates it against the guardrail prompt. Both the inference endpoint and the evaluator endpoint must serve one of these APIs:
- OpenAI Chat Completions and MLflow Chat
- Anthropic Messages
- OpenAI Responses
- Gemini generateContent
Embeddings endpoints are not supported because they do not produce a message that an LLM-based evaluator can inspect. For the field Unity AI Gateway reads from each API shape, see what the evaluator receives. For request-parameter constraints (streaming, multi-choice responses), see limitations.
Built-in guardrail templates
Unity AI Gateway provides built-in templates for common safety and privacy policies. Each template includes a curated prompt maintained by Azure Databricks. You pair the template with any Unity AI Gateway endpoint as the evaluator. See choose an evaluator endpoint.
| Template | Action | Execution phase | Description |
|---|---|---|---|
| PII redaction | Sanitize | Input or output | Detects names, email addresses, phone numbers, social security numbers, credit card numbers, and physical addresses. Replaces each occurrence with a placeholder token like [NAME] or [EMAIL] so the raw PII never reaches the destination model or the client. |
| PII blocking | Block | Input or output | Blocks requests or responses that contain names, email addresses, phone numbers, social security numbers, credit card numbers, or physical addresses. |
| Unsafe content | Block | Input or output | Blocks content that contains hate speech, harassment, violence, self-harm, sexual content, extremist material, or instructions for creating weapons or other dangerous substances. |
| Jailbreak | Block | Input | Blocks inputs that attempt to bypass the model's safety or policy constraints, including direct instruction overrides, obfuscated payloads (for example, Base64 or leetspeak), role-playing exploits, payload splitting, and attempts to extract system prompts. |
| Hallucination | Block | Output | Blocks responses that contain fabricated facts, invented statistics, non-existent citations or references, false claims about real entities or products, or made-up names and credentials. |
Custom guardrails
Define a custom guardrail with your own prompt when the built-in templates don't fit your policy. A custom guardrail follows the same prompt-output contract as the built-in templates: the evaluator must return a structured result indicating whether the guardrail triggered. Use the inference table on the evaluator endpoint to inspect requests and responses while you tune the prompt.
Custom guardrails have these constraints:
- Name: up to 255 characters. Must match the regex
^[a-zA-Z0-9_ -]+$(letters, digits, spaces, hyphens, and underscores). - Prompt: up to 5000 characters.
Tips for writing a custom guardrail prompt
- Define triggers narrowly. State the specific content category that should be flagged and include counterexamples for content that should pass. Vague criteria produce inconsistent decisions.
- Assume the evaluator sees only the extracted message text. It does not see the inference endpoint's system prompt, earlier turns in the conversation, tool-call payloads, or attachments. Do not reference context that won't be there. See what the evaluator receives.
- Do not specify the output format. Unity AI Gateway appends the JSON output contract automatically. Adding your own format instructions (for example, "respond with YES or NO") conflicts with the contract and breaks parsing.
- For sanitizing guardrails, specify the rewrite policy. Tell the evaluator exactly how to rewrite flagged content. For example, replace names with
[NAME], mask credit-card numbers asXXXX-XXXX-XXXX-1234, or remove the matching sentence entirely. - Use few-shot examples. Include a handful of input-output pairs for ambiguous cases. Examples improve consistency more reliably than longer instructions.
- One prompt, one concern. Configure a separate guardrail per policy (PII, competitor mentions, tone, and so on) so each can be tuned, audited, or disabled independently.
- Iterate against the inference table. Enable inference tables on the evaluator endpoint, run representative traffic, and inspect false positives and false negatives. Refine the prompt and re-test.
Example custom prompts
The following prompts illustrate how to apply the tips above.
Block off-topic requests
You are evaluating whether a user message is off-topic for a customer
support assistant for <product>.
A message is on-topic if it is about:
- <product> features, pricing, or documentation
- Account, billing, or support
- General questions related to using <product>
A message is off-topic if it falls outside the above. Examples include
coding or technical help unrelated to <product>, personal advice, current
events, recipes, or requests to roleplay as a different assistant.
Flag off-topic messages.
Examples:
- "How do I get started with <product>?" -> on-topic, do not flag
- "What's a good recipe for lasagna?" -> off-topic, flag
- "Pretend you are a pirate and tell me a joke." -> off-topic, flag
Block competitor mentions
You are evaluating whether a user message asks the assistant to discuss,
compare against, or recommend a competitor of <product>. Competitors include
<competitor 1>, <competitor 2>, and <competitor 3>. Treat any product or
company that primarily competes with <product> as a competitor, even if not
listed.
Flag the message if it:
- Asks for a comparison between <product> and a competitor
- Asks the assistant to recommend or evaluate a competitor's product
- Asks for migration guidance from <product> to a competitor
Do not flag the message if it mentions a competitor incidentally without
asking the assistant to discuss or evaluate them.
Examples:
- "Is <competitor 1> better than <product>?" -> flag
- "Help me migrate from <product> to <competitor 2>." -> flag
- "Which is cheaper, <product> or <competitor 3>?" -> flag
- "I run <product> alongside <competitor 1> for failover; how do I
configure <product>?" -> do not flag
Choose an evaluator endpoint
The evaluator endpoint must serve one of the supported API types. When you create a guardrail, the form auto-selects a recommended evaluator from those available in your workspace. Azure Databricks maintains the per-cloud recommendation list; if none of the recommended endpoints are available, the dropdown stays empty and you select one manually.
For higher availability, configure fallbacks on the evaluator endpoint. Fallbacks automatically route requests to a backup model if the primary evaluator returns a 429 or 5XX. Fallbacks require a user-created Unity AI Gateway endpoint. To use fallbacks with a recommended evaluator, wrap it in a user-created endpoint and point your guardrails at that endpoint.
Enable inference tables on the evaluator endpoint to log every guardrail request and response to a Unity Catalog Delta table. Use the logged payloads to audit guardrail decisions, evaluate accuracy, and tune your prompts or fine-tune the evaluator endpoint.
For maximum benefit, point all guardrails of the same type at a single evaluator endpoint. For example, configure every PII redaction guardrail across your inference endpoints to use the same evaluator endpoint with inference tables enabled. The consolidated inference table becomes a single source of truth for that guardrail's behavior and a clean data set for prompt tuning or fine-tuning the evaluator endpoint.
Each phase adds the evaluator's latency to the request: blocking guardrails run in parallel within a phase (so the slowest blocking call dominates), and the sanitizing guardrail then runs sequentially. Unity AI Gateway allocates up to 30 seconds per guardrail call: 15 seconds per attempt, with up to two attempts. Choose a low-latency evaluator endpoint and limit the number of guardrails per phase to reduce overhead.
Warning
Nested guardrails are not supported. If the evaluator endpoint you select has its own guardrails configured, Unity AI Gateway skips them when running the guardrail you configured (the evaluator endpoint's own configuration is unchanged). This prevents recursion.
Block and sanitize actions
Each guardrail performs one of two actions when triggered:
- Block: Terminates the request and returns an HTTP
400response to the client. Use blocking for unsafe content, jailbreak attempts, or hallucination detection. - Sanitize: Redacts or rewrites the input or output text in place. Use sanitization for PII so the destination model and the client never see the raw sensitive data.
Sanitization happens dynamically during the request-response cycle:
- An input sanitize rewrites the user's prompt before it reaches the model.
- An output sanitize rewrites the model's response before it returns to the client.
The exact fields that get rewritten depend on the API shape and are listed under what the evaluator receives.
Example: input sanitize
When a PII redaction input guardrail triggers, the original request:
{
"messages": [{ "role": "user", "content": "Email me at jane.doe@example.com." }]
}
is rewritten before reaching the destination model:
{
"messages": [{ "role": "user", "content": "Email me at [EMAIL]." }]
}
When a blocking guardrail triggers, the client receives an HTTP 400 response with error_code: "BAD_REQUEST". The error message takes the form Request blocked by input guardrail '<name>'. or Response blocked by output guardrail '<name>'.
Example: blocked request
When an input guardrail named Unsafe content blocks a request, the client receives:
{
"error_code": "BAD_REQUEST",
"message": "Request blocked by input guardrail 'Unsafe content'."
}
When the same guardrail blocks a response:
{
"error_code": "BAD_REQUEST",
"message": "Response blocked by output guardrail 'Unsafe content'."
}
What the evaluator receives
When a guardrail runs, Unity AI Gateway invokes the evaluator endpoint with a chat completions request. The system message carries the guardrail prompt and the output contract. The user message carries the text under evaluation.
Guardrail prompt
The guardrail prompt is the policy the evaluator enforces. For a built-in template, Azure Databricks curates the prompt. For a custom guardrail, you supply the prompt yourself. See tips for writing a custom guardrail prompt.
Output contract
Unity AI Gateway automatically appends a JSON output contract to the prompt of every guardrail call. The contract differs between blocking and sanitizing guardrails, and custom prompts must produce output that conforms to it.
Output contract for blocking guardrails
The evaluator must return a JSON object with the following fields:
flagged(boolean):trueif the content violates the guardrail criteria.confidence(float,0.0to1.0): The evaluator's confidence in the decision.1.0means a certain violation,0.0means certainly no violation, and intermediate values reflect partial certainty. If the field is omitted, Unity AI Gateway assumes1.0.
Any flagged: true response triggers the block action regardless of confidence.
Output contract for sanitizing guardrails
The evaluator must return a JSON object with the following fields:
flagged(boolean):trueif the content matches the guardrail criteria.sanitized_text(string): The text with matching content replaced or sanitized. Required whenflaggedistrue. Whenflaggedisfalse, the request or response passes through unchanged.
The evaluator's JSON response can include surrounding prose or Markdown code fences; Unity AI Gateway extracts the JSON object defensively. If the response cannot be parsed, the guardrail fails (see fail-closed evaluation).
User message
The user message contains the text of a single message from the original request or response, not the full conversation history. For an input guardrail, Unity AI Gateway extracts the text of the last user message in the request. For an output guardrail, it extracts the assistant's response. The system prompt of the inference endpoint, earlier turns in the conversation, tool-call payloads, image and audio bytes, and reasoning or thinking blocks are not forwarded.
Per-API field extraction
The fields Unity AI Gateway reads from depend on the inference endpoint's native API. For multimodal content arrays, only text-type blocks are extracted.
| API | Input (last user message) | Output (assistant response) |
|---|---|---|
| OpenAI Chat Completions, MLflow Chat | messages[].content (last role: "user") |
choices[0].message.content |
| Anthropic Messages | messages[].content (last role: "user") |
content[].text (text blocks only) |
| OpenAI Responses | input[].content[].text (last role: "user"; text and input_text blocks) |
output[].content[].text (output_text blocks only) |
| Gemini generateContent | contents[].parts[].text (last role: "user", first part) |
candidates[0].content.parts[].text |
When you write a custom prompt, assume the evaluator sees only the extracted text, not the surrounding conversation, system prompt, or tool context.
Putting it all together
The full chat completions request to the evaluator looks like this:
{
"model": "<evaluator endpoint>",
"stream": false,
"messages": [
{ "role": "system", "content": "<guardrail prompt>\n\n<output contract>" },
{ "role": "user", "content": "<extracted message text>" }
]
}
The guardrail prompt and the content under evaluation are passed as distinct roles, not concatenated. This keeps the evaluator's instructions separate from the content it is judging.
Each guardrail call consumes tokens on the evaluator endpoint. The request payload (guardrail prompt, JSON output contract, and extracted message text) and the evaluator's response both count toward the evaluator endpoint's usage and bill against the same model unit.
Audit guardrail activity
Enable usage tracking and inference tables on both the inference endpoint and the evaluator endpoint to capture audit data.
On the inference endpoint, usage tracking records one row per request, including blocked ones. Passing and sanitized requests record real token usage with status 200. Input-blocked requests record status 400 with 0 input and output tokens. Output-blocked requests record status 400 with the destination model's actual token counts.
The inference endpoint's inference table records one row per request that reached the destination model. Input-blocked requests are therefore absent from the inference table (audit them through usage tracking). Output-blocked requests appear in the inference table with the raw upstream response body and the status code overridden to 400.
On the evaluator endpoint, the inference table records one row per guardrail call, with the request body described in what the evaluator receives, the evaluator's raw JSON response, latency, status code, and timestamp. Usage tracking is not logged for guardrail calls on the evaluator endpoint.
The inference endpoint's inference table and the evaluator endpoint's inference table share the same request_id. Join on this field to trace a guardrail decision back to the originating client call.
Fail-closed evaluation
Guardrails are fail-closed. If a guardrail call fails, times out, or returns a response that Unity AI Gateway cannot parse, the request is blocked. This guarantees that safety and privacy policies cannot be bypassed by transient evaluator failures.
The client error reflects the failure mode. Timeouts return DEADLINE_EXCEEDED. When the evaluator returns an HTTP error, Unity AI Gateway propagates the corresponding error code, for example PERMISSION_DENIED for 403. Other failures return INTERNAL_ERROR. All cases include the name of the failing guardrail in the error message.
To test a new guardrail without affecting production traffic, set the guardrail's mode to Log in Advanced options. In Log mode, the guardrail evaluates the request or response and records the result, but does not block or modify content. A guardrail in Log mode that fails or times out also passes through silently rather than blocking the request. The guardrails table marks log-mode guardrails with a shield-off icon next to the action tag.
Limitations
Guardrails have the following limitations:
- Per-phase capacity: You can configure up to three blocking guardrails plus one sanitizing guardrail per execution phase.
- Streaming with output guardrails: Unity AI Gateway does not support streaming responses on endpoints that have output guardrails configured. Requests with
stream=true(or the streamGenerateContent Gemini variant) on these endpoints are rejected withINVALID_PARAMETER_VALUE: "Streaming responses with output guardrails are not supported. Disable streaming (stream=false) or remove the output guardrail."Streaming with input-only guardrails is supported. - Multi-choice responses with output guardrails: Unity AI Gateway does not support requests with
n > 1(OpenAI Chat Completions, MLflow Chat) orgenerationConfig.candidateCount > 1(Gemini) on endpoints that have output guardrails configured. These requests are rejected withINVALID_PARAMETER_VALUE: "Multi-choice responses (n > 1 or candidateCount > 1) with output guardrails are not supported. Set n=1 (or candidateCount=1) or remove the output guardrail."Anthropic Messages and the OpenAI Responses API have no multi-alternative parameter and are not affected. - Single-message evaluation: Each guardrail evaluates a single message at a time. Because the evaluator doesn't aggregate multi-turn context, it cannot detect patterns that span multiple messages, such as gradual escalation or context-manipulation attacks. This design ensures that evaluator inputs remain bounded and performant. See what the evaluator receives.