Ingest data from SQL Server
Important
LakeFlow Connect is in gated Public Preview. To participate in the preview, contact your Databricks account team.
This article describes how to ingest data from SQL Server and load it into Azure Databricks using LakeFlow Connect.
The Microsoft SQL Server (SQL Server) connector supports the following:
- Azure SQL Database
- Amazon RDS for SQL Server
Overview of steps
- Configure your source database for ingestion.
- Create a gateway, which connects to the SQL Server database, extracts snapshot and change data from the source database, and stores it in a staging Unity Catalog volume.
- Create an ingestion pipeline, which applies snapshot and change data from the staging volume into destination streaming tables.
- Schedule the ingestion pipeline.
Before you begin
To create an ingestion pipeline, you must meet the following requirements:
Your workspace is enabled for Unity Catalog.
Serverless compute is enabled for notebooks, workflows, and Delta Live Tables. See Enable serverless compute.
To create a connection:
CREATE CONNECTIONon the metastore.To use an existing connection:
USE CONNECTIONorALL PRIVILEGESon the connection.USE CATALOGon the target catalog.USE SCHEMA,CREATE TABLE, andCREATE VOLUMEon an existing schema orCREATE SCHEMAon the target catalog.Unrestricted permissions to create clusters, or a custom policy. A custom policy must meet the following requirements:
Family: Job Compute
Policy family overrides:
{ "cluster_type": { "type": "fixed", "value": "dlt" }, "num_workers": { "type": "unlimited", "defaultValue": 1, "isOptional": true }, "runtime_engine": { "type": "fixed", "value": "STANDARD", "hidden": true } }The worker nodes (
node_type_id) are not used but are required to run DLT. Specify a minimal node:
"driver_node_type_id": { "type": "unlimited", "defaultValue": "r5.xlarge", "isOptional": true }, "node_type_id": { "type": "unlimited", "defaultValue": "m4.large", "isOptional": true }For more information about cluster policies, see Select a cluster policy.
Set up the source database for ingestion
See Configure SQL Server for ingestion into Azure Databricks.
Create a SQL Server connection
The connector uses a Unity Catalog connection object to store and access the credentials for the source database.
Note
Permissions required
- To create a new connection,
CREATE CONNECTIONon the metastore. Contact a metastore admin to grant this. - To use an existing connection,
USE CONNECTIONorALL PRIVILEGESon the connection object. Contact the connection owner to grant these.
To create the connection, do the following:
- In the Azure Databricks workspace, click Catalog > External Data > Connections.
- Click Create connection. If you don’t see this button, you might not have
CREATE CONNECTIONprivileges. - Enter a unique Connection name.
- For Connection type select SQL Server.
- For Host, specify the SQL Server domain name.
- For User and Password, enter your SQL Server login credentials.
- Click Create.
Note
Test connection test that the host is reachable. It does not test user credentials for correct username and password values.
Create a staging catalog and schemas
The SQL Server connector creates a Unity Catalog staging volume to store intermediate data in a staging Unity Catalog catalog and schema that you specify.
The staging catalog and schema can be the same as the destination catalog and schema. The staging catalog cannot be a foreign catalog.
Note
Permissions required
- To create a new staging catalog,
CREATE CATALOGon the metastore. Contact a metastore administrator to grant this. - To use an existing staging catalog,
USE CATALOGon the catalog. Contact the catalog owner to grant this. - To create a new staging schema,
CREATE SCHEMAon the catalog. Contact the catalog owner to grant this. - To use an existing staging schema,
USE SCHEMA,CREATE VOLUME, andCREATE TABLEon the schema. Contact the schema owner to grant these.
Catalog Explorer
- In the Azure Databricks workspace, click Catalog.
- On the Catalog tab, do one of the following:
- Click Create catalog. If you don’t see this button, you don’t have
CREATE CATALOGprivileges. - Enter a unique name for the catalog, and then click Create.
- Select the catalog you created.
- Click Create schema. If you don’t see this button, you don’t have
CREATE SCHEMAprivileges. - Enter a unique name for the schema, and then click Create.
CLI
export CONNECTION_NAME="my_connection"
export TARGET_CATALOG="main"
export TARGET_SCHEMA="lakeflow_sqlserver_connector_cdc"
export STAGING_CATALOG=$TARGET_CATALOG
export STAGING_SCHEMA=$TARGET_SCHEMA
export DB_HOST="cdc-connector.database.windows.net"
export DB_USER="..."
export DB_PASSWORD="..."
output=$(databricks connections create --json '{
"name": "'"$CONNECTION_NAME"'",
"connection_type": "SQLSERVER",
"options": {
"host": "'"$DB_HOST"'",
"port": "1433",
"trustServerCertificate": "false",
"user": "'"$DB_USER"'",
"password": "'"$DB_PASSWORD"'"
}
}')
export CONNECTION_ID=$(echo $output | jq -r '.connection_id')
Create the gateway and ingestion pipeline
The gateway extracts snapshot and change data from the source database and stores it in the staging Unity Catalog volume. To avoid issues with gaps in the change data due to change log retention policies on the source database, run the gateway as a continuous pipeline.
The ingestion pipeline applies the snapshot and change data from the staging volume into destination streaming tables.
Note
Only one ingestion pipeline per gateway is supported.
Even though the API allows it, the ingestion pipeline does not support more than one destination catalog and schema. If you need to write to multiple destination catalogs or schemas, create multiple gateway-ingestion pipeline pairs.
Note
Permissions required
To create a pipeline, you need Unrestricted cluster creation permissions. Contact an account administrator.
Databricks Asset Bundles
This tab describes how to deploy an ingestion pipeline using Databricks Asset Bundles (DABs). Bundles can contain YAML definitions of jobs and tasks, are managed using the Databricks CLI, and can be shared and run in different target workspaces (such as development, staging, and production). For more information, see Databricks Asset Bundles.
Create a new bundle using the Databricks CLI:
databricks bundle initAdd two new resource files to the bundle:
- A pipeline definition file (
resources/sqlserver_pipeline.yml). - A workflow file that controls the frequency of data ingestion (
resources/sqlserver.yml).
The following is an example
resources/sqlserver_pipeline.ymlfile:variables: # Common variables used multiple places in the DAB definition. gateway_name: default: sqlserver-gateway dest_catalog: default: main dest_schema: default: ingest-destination-schema resources: pipelines: gateway: name: ${var.gateway_name} gateway_definition: connection_name: <sqlserver-connection> gateway_storage_catalog: main gateway_storage_schema: ${var.dest_schema} gateway_storage_name: ${var.gateway_name} target: ${var.dest_schema} catalog: ${var.dest_catalog} channel: PREVIEW pipeline_sqlserver: name: sqlserver-ingestion-pipeline ingestion_definition: ingestion_gateway_id: ${resources.pipelines.gateway.id} objects: # Modify this with your tables! - table: # Ingest the table test.ingestion_demo_lineitem to dest_catalog.dest_schema.ingestion_demo_line_item. source_catalog: test source_schema: ingestion_demo source_table: lineitem destination_catalog: ${var.dest_catalog} destination_schema: ${var.dest_schema} - schema: # Ingest all tables in the test.ingestion_whole_schema schema to dest_catalog.dest_schema. The destination # table name will be the same as it is on the source. source_catalog: test source_schema: ingestion_whole_schema destination_catalog: ${var.dest_catalog} destination_schema: ${var.dest_schema} target: ${var.dest_schema} catalog: ${var.dest_catalog} channel: PREVIEWThe following is an example
resources/sqlserver_job.ymlfile:resources: jobs: sqlserver_dab_job: name: sqlserver_dab_job trigger: # Run this job every day, exactly one day from the last run # See https://docs.databricks.com/api/workspace/jobs/create#trigger periodic: interval: 1 unit: DAYS email_notifications: on_failure: - <email-address> tasks: - task_key: refresh_pipeline pipeline_task: pipeline_id: ${resources.pipelines.pipeline_sqlserver.id}- A pipeline definition file (
Deploy the pipeline using the Databricks CLI:
databricks bundle deploy
Notebook
Update the Configuration cell in the following notebook with the source connection, target catalog, target schema, and tables to ingest from the source.
Create gateway and ingestion pipeline
CLI
To create the gateway:
output=$(databricks pipelines create --json '{
"name": "'"$GATEWAY_PIPELINE_NAME"'",
"gateway_definition": {
"connection_id": "'"$CONNECTION_ID"'",
"gateway_storage_catalog": "'"$STAGING_CATALOG"'",
"gateway_storage_schema": "'"$STAGING_SCHEMA"'",
"gateway_storage_name": "'"$GATEWAY_PIPELINE_NAME"'"
}
}')
export GATEWAY_PIPELINE_ID=$(echo $output | jq -r '.pipeline_id')
To create the ingestion pipeline:
databricks pipelines create --json '{
"name": "'"$INGESTION_PIPELINE_NAME"'",
"ingestion_definition": {
"ingestion_gateway_id": "'"$GATEWAY_PIPELINE_ID"'",
"objects": [
{"table": {
"source_catalog": "tpc",
"source_schema": "tpch",
"source_table": "lineitem",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'",
"destination_table": "<YOUR_DATABRICKS_TABLE>",
}},
{"schema": {
"source_catalog": "tpc",
"source_schema": "tpcdi",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'"
}}
]
}
}'
Set up a trigger schedule for the ingestion pipeline
Note
Only triggered mode is supported for running ingestion pipelines.
You can create a schedule for the pipeline using the DLT pipeline UI by clicking on the button in the top right-hand corner of the pipeline UI screen.
The UI automatically creates a job to run the pipeline according to the specified schedule. The job is shown in the Jobs tab.
Verify successful data ingestion
The list view in the ingestion pipeline UI shows the number of records processed as data is ingested. These numbers automatically refresh.
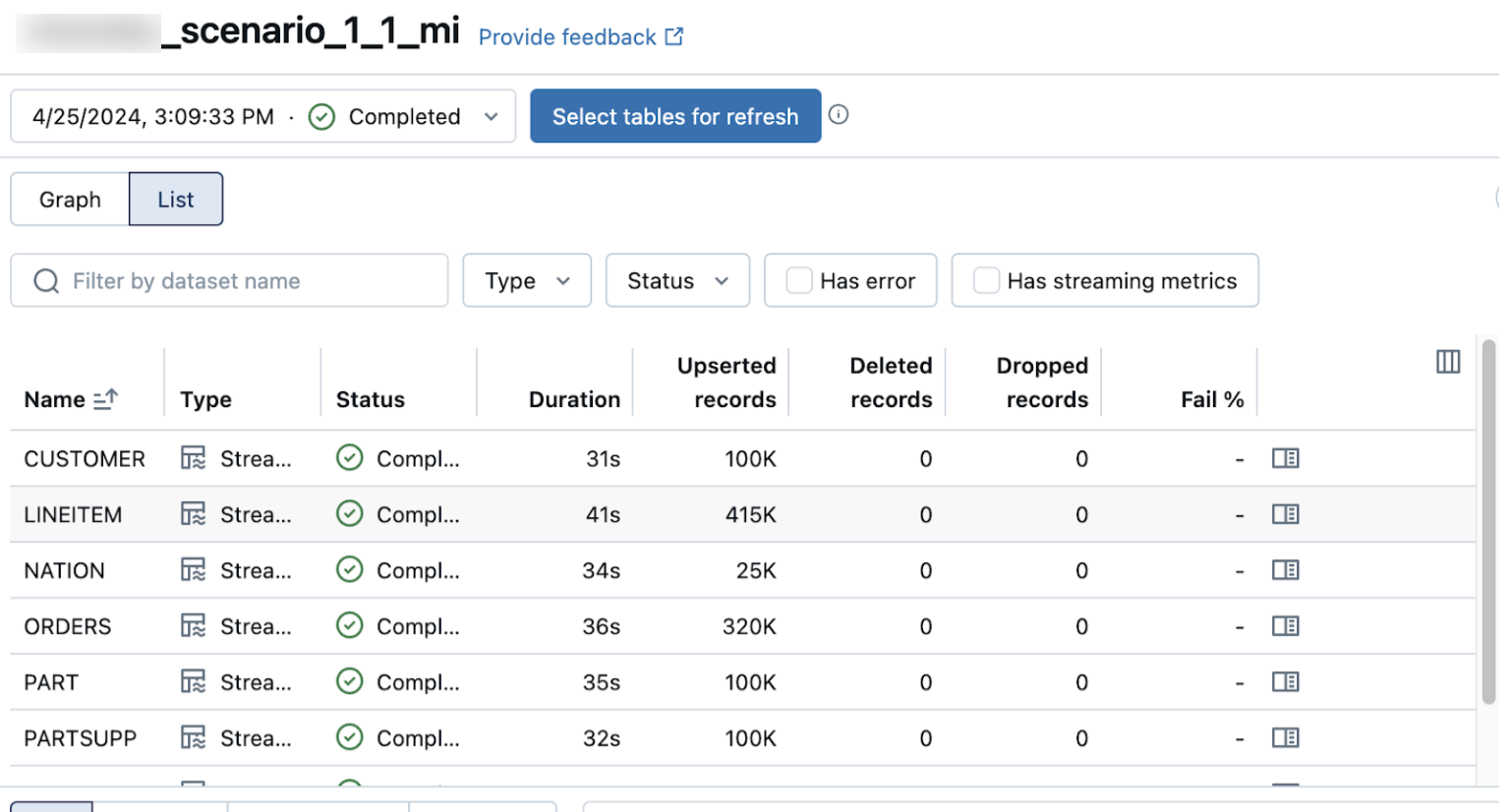
The Upserted records and Deleted records columns are not shown by default. You can enable them by clicking on the columns configuration ![]() button and selecting them.
button and selecting them.
Start, schedule, and set alerts on your pipeline
After the pipeline has been created, revisit the Databricks workspace, and then click Delta Live Tables.
The new pipeline appears in the pipeline list.
To view the pipeline details, click the pipeline name.
On the pipeline details page, run the pipeline by clicking Start. You can schedule the pipeline by clicking Schedule.
To set alerts on the pipeline, click Schedule, click More options, and then add a notification.
After ingestion completes, you can query your tables.