Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
By default, notebooks in Databricks are created in .ipynb (IPython or Jupyter) format. You can also choose to use source format instead.
You can still import and export notebooks in various formats. See Import and export Databricks notebooks.
Notebook formats
Databricks supports creating and editing notebooks in two formats: IPYNB (default) and source.
You can manage source files, including notebooks, using Git folders. Only certain Databricks asset types are supported in Git folders. The format affects how notebooks are committed to remote repositories, as described in the table below.
| Notebook source format | Description |
|---|---|
| source | A basic format that only captures source code, with a suffix that signals the code language, such as .py, .scala, .r and .sql. |
| IPYNB (Jupyter) | A rich format that captures source code, notebook environment, visualization definitions, notebook widgets, and optional outputs. An IPYNB notebook can contain code in any language supported by Databricks notebooks (despite the py part of .ipynb). Using the IPYNB format, you can optionally version control the output of a notebook along with the notebook. |
The IPYNB format also supports a better viewing experience for Databricks notebooks on remote Git repositories. If you use GitHub or GitLab, you can enable features that give you enhanced diffs of your notebooks in pull requests, making it easier to view and code review changes to a notebook.
To learn more about GitHub support for rich diffs of IPYNB notebooks, see Feature Preview: Rich Jupyter Notebook Diffs. To learn more about GitLab support for IPYNB notebook diffs, see Jupyter Notebook files.
To distinguish source format notebooks from regular Python, Scala, and SQL files, Azure Databricks adds the comment “Databricks notebook source” to the top of Python, Scala, and SQL notebooks. This comment ensures that Azure Databricks correctly parses the file as a notebook rather than a script file.
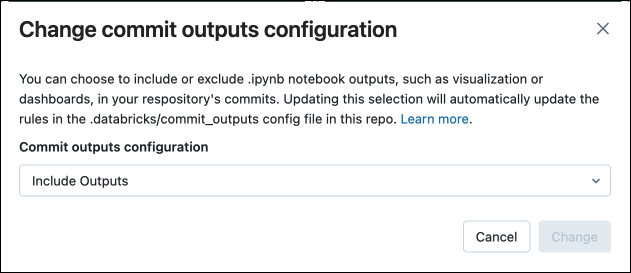
Change the default notebook format setting
IPYNB notebooks are the default format when creating a new notebook on Azure Databricks.
To change the default to the Azure Databricks source format, log into your Azure Databricks workspace, click your profile in the upper-right of the page, then click Settings and navigate to Developer. Change the notebook format default under the Editor settings heading.
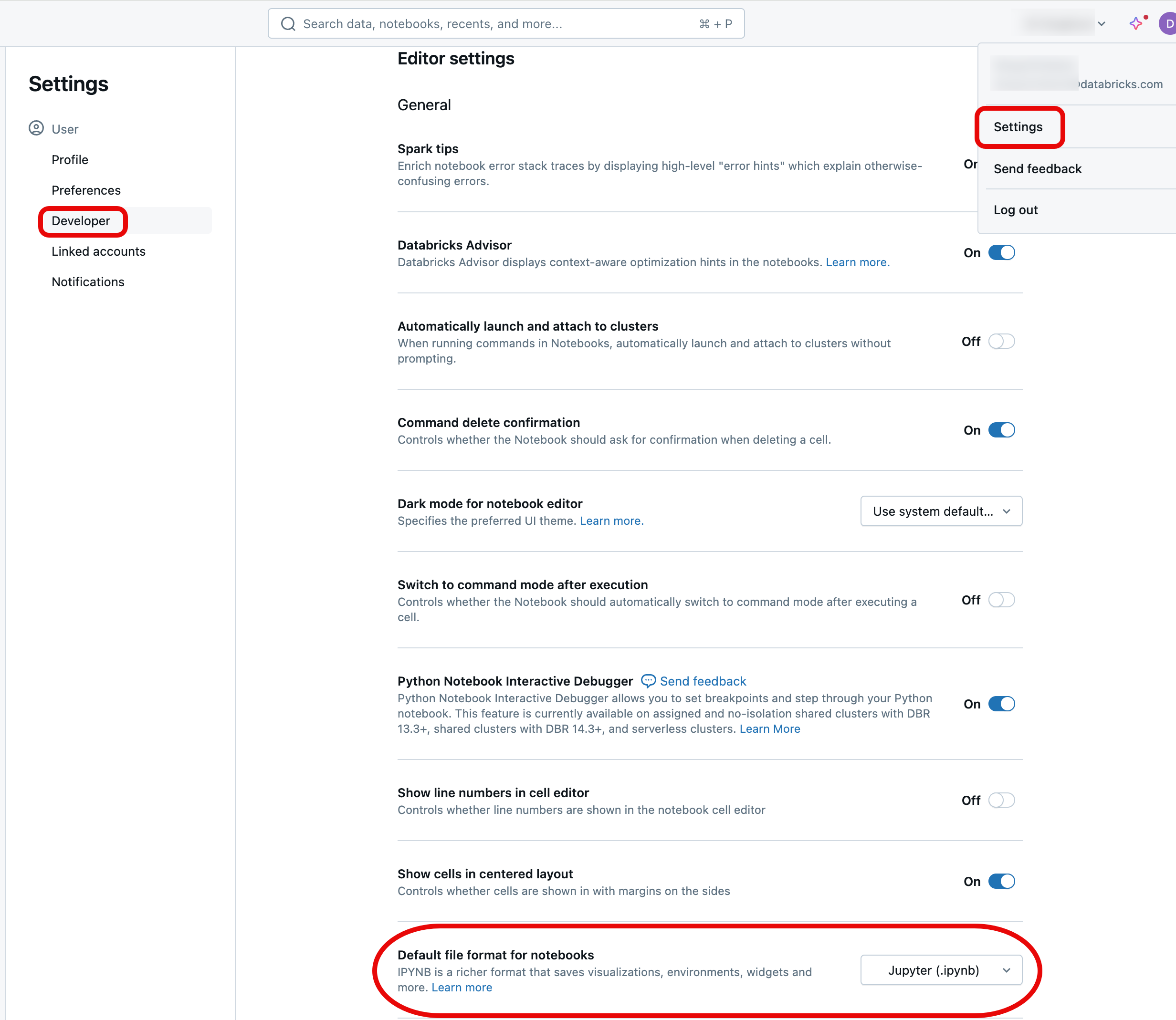
Convert notebook format
You can convert an existing notebook to another format through the Azure Databricks UI.
To convert an existing notebook to another format:
Open the notebook in your workspace.
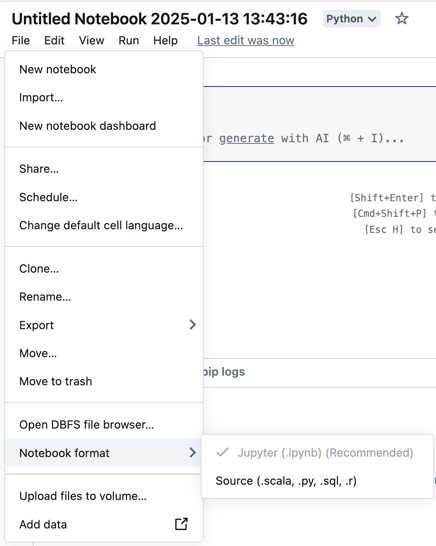
Select File from the workspace menu, select Notebook format, and choose the format you want. You can choose either Jupyter (.ipynb) (Recommended) or Source (.scala, .py, .sql, .r). The notebook's current format is greyed out and has a checkmark next to it.
For more information on the kinds of notebooks supported in Azure Databricks, see Import and export Databricks notebooks.
Manage IPYNB notebook output commits
Outputs are the results of running a notebook on the Databricks platform, including table displays and visualizations. For IPYNB notebooks in source-controlled folders, you can manage how notebook outputs are committed to the remote repository.
Allow committing .ipynb notebook output
Outputs can be committed only if a workspace administrator has enabled this feature. By default, the administrative setting for Git folders doesn't allow .ipynb notebook output to be committed. If you have administrator privileges for the workspace, you can change this setting:
Go to Admin settings > Workspace settings in the Azure Databricks administrator console.
Under Git folders, choose Allow Git folders to Export IPYNB outputs and then select Allow: IPYNB outputs can be toggled on.

Important
When outputs are included, the visualization and dashboard configurations are included in the .ipynb notebooks you create.
Control IPYNB notebook output artifact commits
When you commit an .ipynb file, Databricks creates a configuration file that lets you control how you commit outputs: .databricks/commit_outputs.
If you have a
.ipynbnotebook file but no configuration file in your remote repository, go to the Git Status dialog.In the notification dialog, select Create commit_outputs config file.
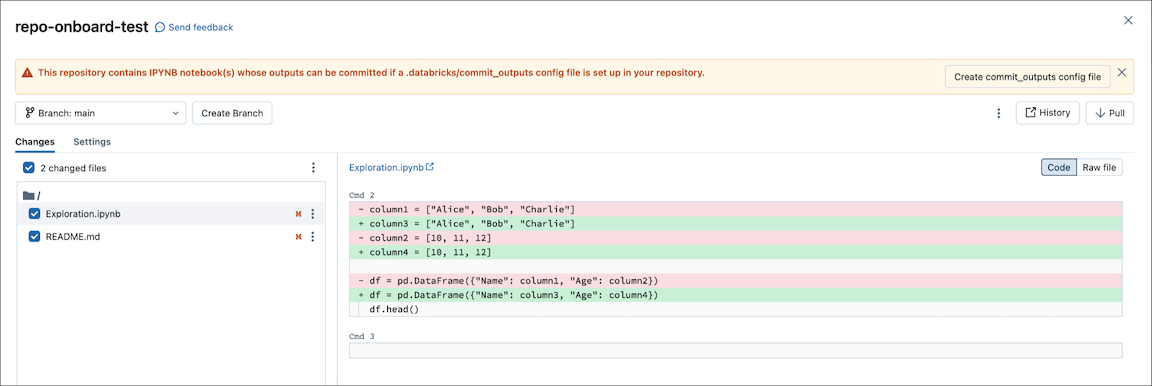
You can also generate configuration files from the File menu. The File menu has a control to automatically update the configuration file where you can specify the inclusion or exclusion of outputs for a specific IPYNB notebook.
In the File menu, select Commit notebooks outputs.
In the dialog box, confirm your choice to commit notebook outputs.