Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article explains how to get workspace, classic compute, dashboard, directory, model, notebook, and job identifiers and URLs in Azure Databricks.
Workspace instance names, URLs, and IDs
A unique instance name, also known as a per-workspace URL, is assigned to each Azure Databricks deployment. It is the fully-qualified domain name used to log into your Azure Databricks deployment and make API requests.
An Azure Databricks workspace is where the Azure Databricks platform runs and where you can create Spark clusters and schedule workloads. A workspace has a unique numerical workspace ID.
Per-workspace URL
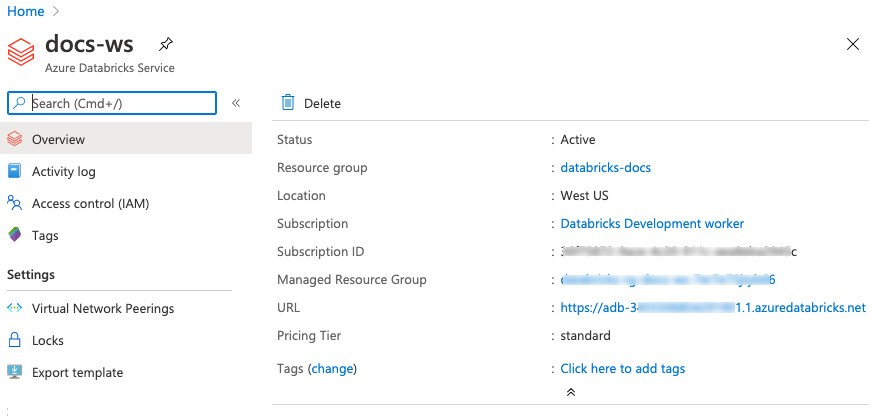
The unique per-workspace URL has the format adb-<workspace-id>.<random-number>.azuredatabricks.net. The workspace ID appears immediately after adb- and before the “dot” (.). For the per-workspace URL https://adb-5555555555555555.19.azuredatabricks.net/:
- The workspace URL is
https://adb-5555555555555555.19.azuredatabricks.net/ - The instance name is
adb-5555555555555555.19.azuredatabricks.net. - The workspace ID is
5555555555555555.
Determine per-workspace URL
You can determine the per-workspace URL for your workspace:
In your browser when you are logged in:

In the Azure portal, by selecting the resource and noting the value in the URL field:
Using the Azure API. See Get a per-workspace URL using the Azure API.
Legacy regional URL
Important
Avoid legacy regional URLs. They:
- May not work with new workspaces.
- Are less reliable and slower than per-workspace URLs.
- Can break features that require workspace IDs.
The legacy regional URL is composed of the region where the Azure Databricks workspace is deployed plus the domain azuredatabricks.net, for example, https://westus.azuredatabricks.net/.
- If you log in to a legacy regional URL like
https://westus.azuredatabricks.net/, the instance name iswestus.azuredatabricks.net. - The workspace ID appears in the URL only after you have logged in using a legacy regional URL. It appears after the
o=. In the URLhttps://<databricks-instance>/?o=6280049833385130, the workspace ID is6280049833385130.
Compute resource URL and ID
Azure Databricks compute resources provide a unified platform for various use cases such as running production ETL pipelines, streaming analytics, ad-hoc analytics, and machine learning. Each classic compute resource has a unique ID called the cluster ID. This applies to both all-purpose and job clusters, but not serverless compute. You need the cluster ID to get the details of a cluster using the REST API.
To get the cluster ID, click ![]() Compute on the sidebar and then select a cluster name. The cluster ID is the number after the
Compute on the sidebar and then select a cluster name. The cluster ID is the number after the /clusters/ component in the URL of this page.
https://<databricks-instance>/compute/clusters/<cluster-id>
In the following screenshot, the cluster ID is 0130-201722-abcdefgh.

Dashboard URL and ID
An AI/BI dashboard is a presentation of data visualizations and commentary. Each dashboard has a unique ID. You can use this ID to construct direct links that include preset filter and parameter values, or access the dashboard using the REST API.
Example dashboard URL:
https://adb-62800498333851.30.azuredatabricks.net/sql/dashboardsv3/01ef9214fcc7112984a50575bf2b460f
- Example dashboard ID:
01ef9214fcc7112984a50575bf2b460f
Notebook URL and ID
A notebook is a web-based interface to a document that contains runnable code, visualizations, and narrative text. Notebooks are one interface for interacting with Azure Databricks. Each notebook has a unique ID. The notebook URL has the notebook ID, hence the notebook URL is unique to a notebook. It can be shared with anyone on Azure Databricks platform with permission to view and edit the notebook. In addition, each notebook command (cell) has a different URL.
To find a notebook URL or ID, open a notebook. To find a cell URL, click the contents of the command.
Example notebook URL:
https://adb-62800498333851.30.azuredatabricks.net/?o=6280049833385130#notebook/1940481404050342`Example notebook ID:
1940481404050342.Example command (cell) URL:
https://adb-62800498333851.30.azuredatabricks.net/?o=6280049833385130#notebook/1940481404050342/command/2432220274659491
Folder ID
A folder is a directory used to store files that can used in the Azure Databricks workspace. These files can be notebooks, libraries or subfolders. There is a specific id associated with each folder and each individual sub-folder. The Permissions API refers to this id as a directory_id and is used in setting and updating permissions for a folder.
To retrieve the directory_id , use the Workspace API:
curl -n -X GET -H 'Content-Type: application/json' -d '{"path": "/Users/me@example.com/MyFolder"}' \
https://<databricks-instance>/api/2.0/workspace/get-status
This is an example of the API call response:
{
"object_type": "DIRECTORY",
"path": "/Users/me@example.com/MyFolder",
"object_id": 123456789012345
}
Model ID
A model refers to an MLflow registered model, which lets you manage MLflow Models in production through stage transitions and versioning. The registered model ID is required for changing the permissions on the model programmatically through the Permissions API.
To get the ID of a registered model, you can use the Workspace API endpoint mlflow/databricks/registered-models/get. For example, the following code returns the registered model object with its properties, including its ID:
curl -n -X GET -H 'Content-Type: application/json' -d '{"name": "model_name"}' \
https://<databricks-instance>/api/2.0/mlflow/databricks/registered-models/get
The returned value has the format:
{
"registered_model_databricks": {
"name": "model_name",
"id": "ceb0477eba94418e973f170e626f4471"
}
}
Job URL and ID
A job is a way of running a notebook or JAR either immediately or on a scheduled basis.
To get a job URL, click ![]() Jobs & Pipelines on the sidebar and click a job name. The job ID appears after
Jobs & Pipelines on the sidebar and click a job name. The job ID appears after /jobs/ in the URL. Use the job URL to navigate to a job and its run history. To link directly to a specific run, for example to share in a support ticket, use the run URL instead. See Job run URL and ID.
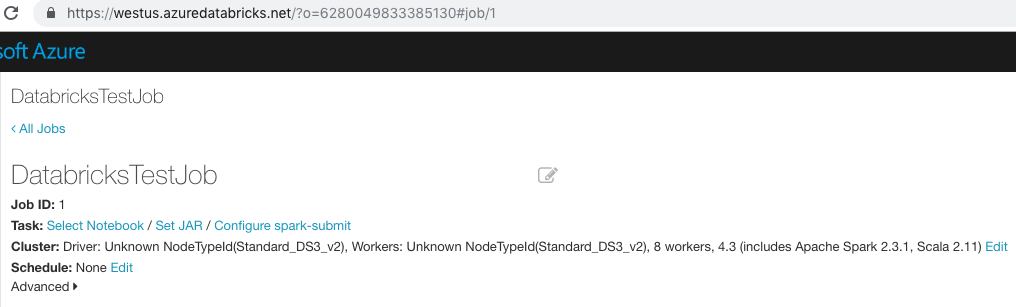
In the following screenshot, the job URL is:
https://adb-westus.18.azuredatabricks.net/jobs/5?o=1248852073749208
In this example, the job ID is 5.
Job run URL and ID
A single job can have many runs. Each run has its own unique run ID and its own URL, which are distinct from the job ID and job URL. When you share a link to a specific run, for example, in a support ticket, use the run URL rather than the job URL so the recipient opens the correct run.
The run URL has the format:
https://<databricks-instance>/jobs/<job-id>/runs/<run-id>
To find the run ID or URL in the workspace UI:
- On the Runs tab for a job, click the link in the Start time column to open the Job run details page. The run ID appears in the browser address bar after
/runs/. Copy the address to share the run. - On the Job run details page, the URL in the address bar contains both the job ID and the run ID in the form
/jobs/<job-id>/runs/<run-id>.
To get the run ID or URL programmatically:
- Jobs API: Call the Get a single job run endpoint. The response includes
run_idandrun_page_url, which is the direct UI link to the run. - System tables: The
system.lakeflow.job_run_timelinetable includes bothjob_idandrun_idcolumns. See Jobs system table reference.
Note
For runs triggered by another job, for example a task that uses the Run Job task type, the parent_run_id field identifies the parent run. See Add notifications on a job.