Analytics and Business Intelligence (BI) on your Azure Cosmos DB data
Azure Cosmos DB offers various options to enable large-scale analytics and BI reporting on your operational data.
To get meaningful insights on your Azure Cosmos DB data, you may need to query across multiple partitions, collections, or databases. In some cases, you might combine this data with other data sources in your organization such as Azure SQL Database, Azure Data Lake Storage Gen2 etc. You might also query with aggregate functions such as sum, count etc. Such queries need heavy computational power, which likely consumes more request units (RUs) and as a result, these queries might potentially affect your mission critical workload performance.
To isolate transactional workloads from the performance impact of complex analytical queries, database data is ingested nightly to a central location using complex Extract-Transform-Load (ETL) pipelines. Such ETL-based analytics are complex, costly with delayed insights on business data.
Azure Cosmos DB addresses these challenges by providing zero ETL, cost-effective analytics offerings.
Zero ETL, near real-time analytics on Azure Cosmos DB
Azure Cosmos DB offers zero ETL, near real-time analytics on your data without affecting the performance of your transactional workloads or request units (RUs). These offerings remove the need for complex ETL pipelines, making your Azure Cosmos DB data seamlessly available to analytics engines. With reduced latency to insights, you can provide enhanced customer experience and react more quickly to changes in market conditions or business environment. Here are some sample scenarios you can achieve with quick insights into your data.
You can enable zero-ETL analytics and BI reporting on Azure Cosmos DB using the following options:
- Mirroring your data into Microsoft Fabric
- Enabling Azure Synapse Link to access data from Azure Synapse Analytics
Option 1: Mirroring your Azure Cosmos DB data into Microsoft Fabric
Mirroring enables you to seamlessly bring your Azure Cosmos DB database data into Microsoft Fabric. With zero ETL, you can get quick, rich business insights on your Azure Cosmos DB data using Fabric’s built-in analytics, BI, and AI capabilities.
Your Cosmos DB operational data is incrementally replicated into Fabric OneLake in near real-time. Data in OneLake is stored in open-source Delta Parquet format and made available to all analytical engines in Fabric. With open access, you can use it with various Azure services such as Azure Databricks, Azure HDInsight, and more. OneLake also helps unify your data estate for your analytical needs. Mirrored data can be joined with any other data in OneLake, such as Lakehouses, Warehouses or shortcuts. You can also join Azure Cosmos DB data with other mirrored database sources such as Azure SQL Database, Snowflake. You can query across Azure Cosmos DB collections or databases mirrored into OneLake.
With Mirroring in Fabric, you don't need to piece together different services from multiple vendors. Instead, you can enjoy a highly integrated, end-to-end, and easy-to-use product that is designed to simplify your analytics needs. You can use T-SQL to run complex aggregate queries and Spark for data exploration. You can seamlessly access the data in notebooks, use data science to build machine learning models, and build Power BI reports using Direct Lake powered by rich Copilot integration.

If you're looking for analytics on your operational data in Azure Cosmos DB, mirroring provides:
- Zero ETL, cost-effective near real-time analytics on Azure Cosmos DB data without affecting your request unit (RU) consumption
- Ease of bringing data across various sources into Fabric OneLake.
- Improved query performance of SQL engine handling delta tables, with V-order optimizations
- Improved cold start time for Spark engine with deep integration with ML/notebooks
- One-click integration with Power BI with Direct Lake and Copilot
- Richer app integration to access queries and views with GraphQL
- Open access to and from other services such as Azure Databricks
To get started with mirroring, visit "Get started with mirroring tutorial".
Option 2: Azure Synapse Link to access data from Azure Synapse Analytics
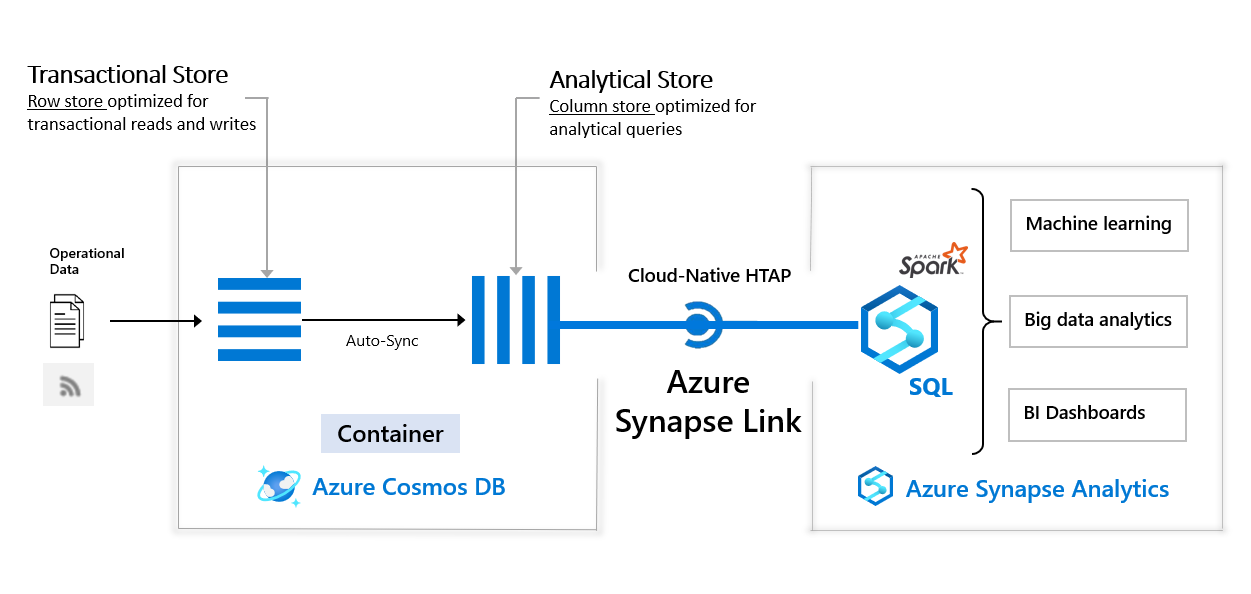
Azure Synapse Link for Azure Cosmos DB creates a tight seamless integration between Azure Cosmos DB and Azure Synapse Analytics, enabling zero ETL, near real-time analytics on your operational data. Transactional data is seamlessly synced to Analytical store, which stores the data in columnar format optimized for analytics.
Azure Synapse Analytics can access this data in Analytical store, without further movement, using Azure Synapse Link. Business analysts, data engineers, and data scientists can now use Synapse Spark or Synapse SQL interchangeably to run near real time business intelligence, analytics, and machine learning pipelines.
The following image shows the Azure Synapse Link integration with Azure Cosmos DB and Azure Synapse Analytics:
Important
Mirroring in Microsoft Fabric is now available in preview for NoSql API. This feature provides all the capabilities of Azure Synapse Link with better analytical performance, ability to unify your data estate with Fabric OneLake and open access to your data in OneLake with Delta Parquet format. If you are considering Azure Synapse Link, we recommend that you try mirroring to assess overall fit for your organization. To get started with mirroring, click here.
To get started with Azure Synapse Link, visit "Getting started with Azure Synapse Link".
Real-time analytics and BI on Azure Cosmos DB: Other options
There are a few other options to enable real-time analytics on Azure Cosmos DB data:
- Using change feed
- Using Spark connector directly on Azure Cosmos DB
- Using Power BI connector directly on Azure Cosmos DB
While these options are included for completeness and work well with single partition queries in real-time, these methods have the following challenges for analytical queries:
Performance impact on your workload:
Analytical queries tend to be complex and consume significant compute capacity. When these queries are run against your Azure Cosmos DB data directly, you might experience performance degradation on your transactional queries.
Cost impact:
When analytical queries are run directly against your database or collections, they increase the need for request units allocated, as analytical queries tend to be complex and need more computation power. Increased RU usage will likely lead to significant cost impact over time, if you run aggregate queries.
Instead of these options, we recommend that you use Mirroring in Microsoft Fabric or Azure Synapse Link, which provide zero ETL analytics, without affecting transactional workload performance or request units.