Delta format in Azure Data Factory
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article highlights how to copy data to and from a delta lake stored in Azure Data Lake Store Gen2 or Azure Blob Storage using the delta format. This connector is available as an inline dataset in mapping data flows as both a source and a sink.
Mapping data flow properties
This connector is available as an inline dataset in mapping data flows as both a source and a sink.
Source properties
The below table lists the properties supported by a delta source. You can edit these properties in the Source options tab.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Format | Format must be delta |
yes | delta |
format |
| File system | The container/file system of the delta lake | yes | String | fileSystem |
| Folder path | The directory of the delta lake | yes | String | folderPath |
| Compression type | The compression type of the delta table | no | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Compression level | Choose whether the compression completes as quickly as possible or if the resulting file should be optimally compressed. | required if compressedType is specified. |
Optimal or Fastest |
compressionLevel |
| Time travel | Choose whether to query an older snapshot of a delta table | no | Query by timestamp: Timestamp Query by version: Integer |
timestampAsOf versionAsOf |
| Allow no files found | If true, an error isn't thrown if no files are found | no | true or false |
ignoreNoFilesFound |
Import schema
Delta is only available as an inline dataset and, by default, doesn't have an associated schema. To get column metadata, click the Import schema button in the Projection tab. This allows you to reference the column names and data types specified by the corpus. To import the schema, a data flow debug session must be active, and you must have an existing CDM entity definition file to point to.
Delta source script example
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Sink properties
The below table lists the properties supported by a delta sink. You can edit these properties in the Settings tab.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Format | Format must be delta |
yes | delta |
format |
| File system | The container/file system of the delta lake | yes | String | fileSystem |
| Folder path | The directory of the delta lake | yes | String | folderPath |
| Compression type | The compression type of the delta table | no | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Compression level | Choose whether the compression completes as quickly as possible or if the resulting file should be optimally compressed. | required if compressedType is specified. |
Optimal or Fastest |
compressionLevel |
| Vacuum | Deletes files older than the specified duration that is no longer relevant to the current table version. When a value of 0 or less is specified, the vacuum operation isn't performed. | yes | Integer | vacuum |
| Table action | Tells ADF what to do with the target Delta table in your sink. You can leave it as-is and append new rows, overwrite the existing table definition and data with new metadata and data, or keep the existing table structure but first truncate all rows, then insert the new rows. | no | None, Truncate, Overwrite | deltaTruncate, overwrite |
| Update method | When you select "Allow insert" alone or when you write to a new delta table, the target receives all incoming rows regardless of the Row policies set. If your data contains rows of other Row policies, they need to be excluded using a preceding Filter transform. When all Update methods are selected a Merge is performed, where rows are inserted/deleted/upserted/updated as per the Row Policies set using a preceding Alter Row transform. |
yes | true or false |
insertable deletable upsertable updateable |
| Optimized Write | Achieve higher throughput for write operation via optimizing internal shuffle in Spark executors. As a result, you may notice fewer partitions and files that are of a larger size | no | true or false |
optimizedWrite: true |
| Auto Compact | After any write operation has completed, Spark will automatically execute the OPTIMIZE command to re-organize the data, resulting in more partitions if necessary, for better reading performance in the future |
no | true or false |
autoCompact: true |
Delta sink script example
The associated data flow script is:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Delta sink with partition pruning
With this option under Update method above (i.e. update/upsert/delete), you can limit the number of partitions that are inspected. Only partitions satisfying this condition is fetched from the target store. You can specify fixed set of values that a partition column may take.
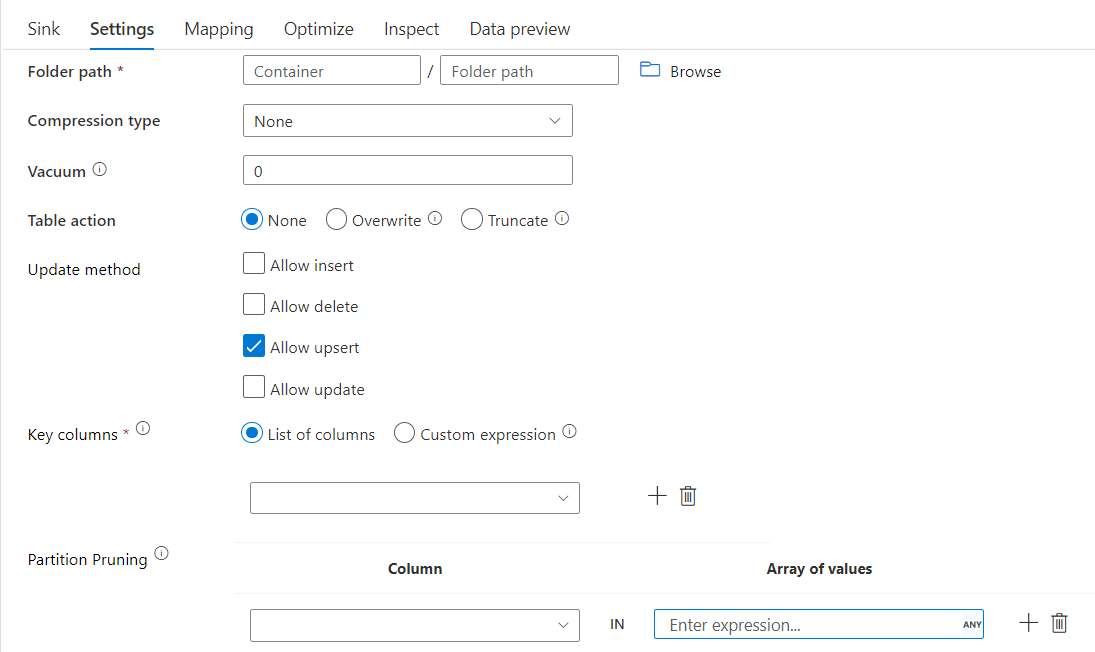
Delta sink script example with partition pruning
A sample script is given as below.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta will only read 2 partitions where part_col == 5 and 8 from the target delta store instead of all partitions. part_col is a column that the target delta data is partitioned by. It need not be present in the source data.
Delta sink optimization options
In Settings tab, you find three more options to optimize delta sink transformation.
When Merge schema option is enabled, it allows schema evolution, i.e. any columns that are present in the current incoming stream but not in the target Delta table is automatically added to its schema. This option is supported across all update methods.
When Auto compact is enabled, after an individual write, transformation checks if files can further be compacted, and runs a quick OPTIMIZE job (with 128 MB file sizes instead of 1GB) to further compact files for partitions that have the most number of small files. Auto compaction helps in coalescing a large number of small files into a smaller number of large files. Auto compaction only kicks in when there are at least 50 files. Once a compaction operation is performed, it creates a new version of the table, and writes a new file containing the data of several previous files in a compact compressed form.
When Optimize write is enabled, sink transformation dynamically optimizes partition sizes based on the actual data by attempting to write out 128 MB files for each table partition. This is an approximate size and can vary depending on dataset characteristics. Optimized writes improve the overall efficiency of the writes and subsequent reads. It organizes partitions such that the performance of subsequent reads improve.
Tip
The optimized write process will slow down your overall ETL job because the Sink will issue the Spark Delta Lake Optimize command after your data is processed. It is recommended to use Optimized Write sparingly. For example, if you have an hourly data pipeline, execute a data flow with Optimized Write daily.
Known limitations
When you write to a delta sink, there's a known limitation where the numbers of rows written won't show-up in the monitoring output.
Related content
- Create a source transformation in mapping data flow.
- Create a sink transformation in mapping data flow.
- Create an alter row transformation to mark rows as insert, update, upsert, or delete.