Data import and export jobs overview
To create and manage data import and export jobs, you use the Data management workspace. By default, the data import and export process creates a staging table for each entity in the target database. Staging tables let you verify, cleanup, or convert data before you move it.
Note
This article assumes that you are familiar with data entities.
Data import/export process
Here are the steps to import or export data.
Create an import or export job where you complete the following tasks:
- Define the project category.
- Identify the entities to import or export.
- Set the data format for the job.
- Sequence the entities, so that they're processed in logical groups and in an order that makes sense.
- Determine whether to use staging tables.
Validate that the source data and target data are mapped correctly.
Verify the security for your import or export job.
Run the import or export job.
Validate that the job ran as expected by reviewing the job history.
Clean up the staging tables.
The remaining sections of this article provide more information about each step of the process.
Note
In order to refresh the Data import/export form to see the latest progress, use the form refresh icon. Browser level refresh is not recommended because it interrupts any import/export jobs that aren't run in a batch.
Create an import or export job
A data import or export job can be run one time or many times.
Define the project category
We recommend that you take the time to select an appropriate project category for your import or export job. Project categories can help you manage related jobs.
Identify the entities to import or export
You can add specific entities to an import or export job or select a template to apply. Templates fill a job with a list of entities. The Apply template option is available after you give the job a name and save the job.
Set the data format for the job
When you select an entity, you must select the format of the data that's exported or imported. You define formats by using the Data sources setup tile. A source data format is a combination of Type, File format, Row delimiter, and Column delimiter. There are other, but these attributes are the key attributes to understand. The following table lists the valid combinations.
| File Format | Row/Column delimiter | XML Style |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | XML-Element XML-Attribute |
| Delimited, fixed width | Comma, semicolon, tab, vertical bar, colon | -NA- |
Note
It's important to select the correct value for Row delimiter, Column delimiter, and Text qualifier, if the File format option is set to Delimited. Make sure that your data doesn't contain the character used as delimiter or qualifier, as this may result in errors during import and export.
Note
For XML-based file formats, make sure to only use legal characters. For more information about valid characters, see Valid Characters in XML 1.0. XML 1.0 does not allow any control characters except for tabs, carriage returns, and line feeds. Examples of illegal characters are square brackets, curly brackets, and backslashes.
To import or export data, use Unicode instead of a specific code page. This helps provide the most consistent results and eliminate data management jobs to fail because they include Unicode characters. The system-defined source data formats that use Unicode all have Unicode in the source name. The Unicode format is applied by selecting a Unicode encoding ANSI code page as Code page in the Regional settings tab. Select one of the following code pages for Unicode:
| Code page | Display name |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
For more information about Code pages, see Code Page Identifiers.
Sequence the entities
Entities can be sequenced in a data template, or in import and export jobs. When you run a job that contains more than one data entity, you must make sure that the data entities are correctly sequenced. You sequence entities primarily so that you can address any functional dependencies among entities. If entities don’t have any functional dependencies, they can be scheduled for parallel import or export.
Execution units, levels, and sequences
The execution unit, level in the execution unit, and sequence of an entity help control the order that the data is exported or imported in.
- In each execution unit, entities are processed in parallel.
- In each execution unit, entities are processed in parallel if they have the same level.
- In each level, entities are processed according to their sequence number in that level.
- After one level is processed, the next level is processed.
Resequencing
You might want to resequence your entities in the following situations:
- If only one data job is used for all your changes, you can use resequencing options to optimize the execution time for the full job. In these cases, you can use the execution unit to represent the module, the level to represent the feature area in the module, and the sequence to represent the entity. By using this approach, you can work across modules in parallel, but you can still work in sequence in a module. To help guarantee that parallel operations succeed, you must consider all dependencies.
- If multiple data jobs are used (for example, one job for each module), you can use sequencing to affect the level and sequence of entities for optimal execution.
- If there are no dependencies at all, you can sequence entities at different execution units for maximum optimization.
The Resequencing menu is available when multiple entities are selected. You can resequence based on execution unit, level, or sequence options. You can set an increment to resequence the entities that are selected. The unit, level, and/or sequence number selected for each entity updates by the specified increment.
Sorting
Use can use the Sort by option to view the entity list in sequential order.
Truncating
For import projects, you can choose to truncate records in the entities prior to import. Truncating is useful if your records must be imported into a clean set of tables. This setting is off by default.
Validate that the source data and target data are mapped correctly
Mapping is a function that applies to both import and export jobs.
- In the context of an import job, mapping describes which columns in the source file become the columns in the staging table. Therefore, the system can determine which column data in the source file must be copied into which column of the staging table.
- In the context of an export job, mapping describes which columns of the staging table (that is, the source) become the columns in the target file.
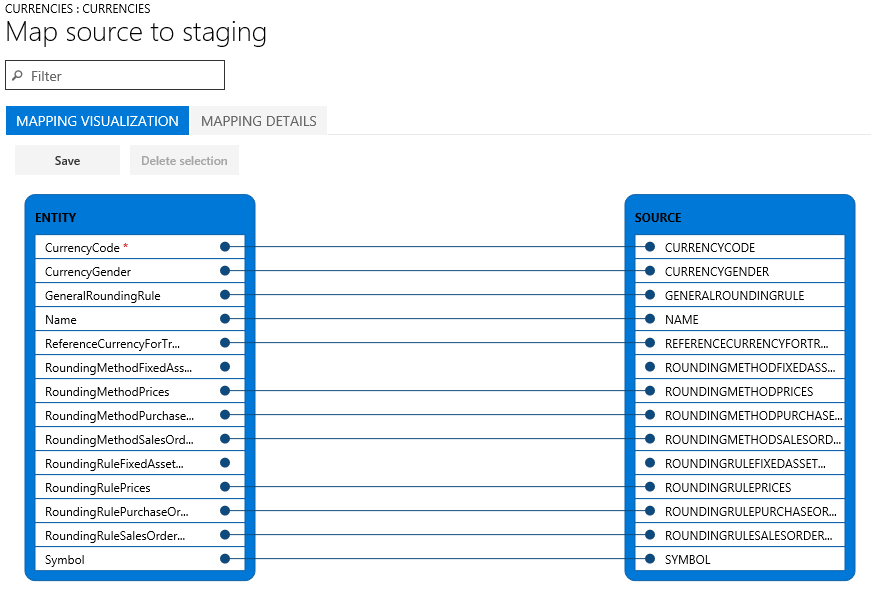
If the column names in the staging table and the file match, the system automatically establishes the mapping, based on the names. However, if the names differ, columns aren’t mapped automatically. In these cases, you must complete the mapping by selecting the View map option on the entity in the data job.
There are two mapping views: Mapping visualization, which is the default view, and Mapping details. A red asterisk (*) identifies any required fields in the entity. These fields must be mapped before you can work with the entity. You can unmap other fields as you require when you work with the entity. To unmap a field, select the field in either the Entity column or the Source column, and then select Delete selection. Select Save to save your changes, and then close the page to return to the project. You can use the same process to edit the field mapping from source to staging after your import.
You can generate a mapping on the page by selecting Generate source mapping. A generated mapping behaves like an automatic mapping. Therefore, you must manually map any unmapped fields.
Verify the security for your import or export job
Access to the Data management workspace can be restricted, so that nonadministrator users can access only specific data jobs. Access to a data job implies full access to the execution history of that job and access to the staging tables. Therefore, you must make sure that appropriate access controls are in place when you create a data job.
Secure a job by roles and users
Use the Applicable roles menu to restrict the job to one or more security roles. Only users in those roles have access to the job.
You can also restrict a job to specific users. When you secure a job by users instead of roles, there's more control if multiple users are assigned to a role.
Secure a job by legal entity
Data jobs are global in nature. Therefore, if a data job was created and used in a legal entity, the job is visible in other legal entities in the system. This default behavior might be preferred in some application scenarios. For example, an organization that imports invoices by using data entities might provide a centralized invoice processing team that is responsible for managing invoice errors for all divisions in the organization. In this scenario, it’s useful for the centralized invoice processing team to have access to invoice import jobs from all legal entities. Therefore, the default behavior meets the requirement from a legal entity perspective.
However, an organization might want to have invoice processing teams per legal entity. In this case, a team in a legal entity should have access only to the invoice import job in its own legal entity. To meet this requirement, you can configure legal entity–based access control on the data jobs by using the Applicable legal entities menu inside the data job. After the configuration is done, users can see only jobs that are available in the legal entity that they're currently signed in to. To see jobs from another legal entity, users must switch to that legal entity.
A job can be secured by roles, users, and legal entity at the same time.
Run the import or export job
You can run a job one time by selecting the Import or Export button after you define the job. To set up a recurring job, select Create recurring data job.
Note
An import or an export job can be run by selecting the Import or Export button. This action schedules a batch job to run only once. The job may not execute immediately if batch service is throttling due to the load on the batch service. The jobs can also be run synchronously by selecting Import now or Export now. This starts the job immediately and is useful if the batch does not start due to throttling. The jobs can also be scheduled to execute at a later time. This can be done by choosing the Run in batch option. Batch resources are subject to throttling, so the batch job might not start immediately. Using a batch is the recommended option because it also helps with large volumes of data that need to be imported or exported. Batch jobs can be scheduled to run on a specific batch group, which allows more control from a load balancing perspective.
Validate that the job ran as expected
The job history is available for troubleshooting and investigation on both import and export jobs. Historical job runs are organized by time ranges.
Each job run provides the following details:
- Execution details
- Execution log
Execution details show the state of each data entity that the job processed. Therefore, you can quickly find the following information:
- The entities that were processed.
- For an entity, how many records were successfully processed, and how many failed.
- The staged records for each entity.
You can download the staging data in a file for export jobs, or you can download it as a package for import and export jobs.
From the execution details, you can also open the execution log.
Parallel imports
To speed up the import of data, parallel processing of importing a file can be enabled if the entity supports parallel imports. To configure the parallel import for an entity, the following steps must be followed.
Go to System administration > Workspaces > Data management.
In the Import / Export section, select the Framework parameters tile to open the Data import/export framework parameters page.
On the Entity settings tab, select Configure entity execution parameters to open the Entity import execution parameters page.
Set the following fields to configure parallel import for an entity:
- In the Entity field, select the entity. If the entity field is empty, the empty value is used as default setting for all subsequent imports, if the entity supports parallel import.
- In the Import threshold record count field, enter the threshold record count for import. This determines the record count to be processed by a thread. If a file has 10K records, a record count of 2,500 with a task count of four means each thread processes 2,500 records.
- In the Import task count field, enter the count of import tasks. The count must not exceed the max batch threads allocated for batch processing in System administration >Server configuration.
Note
Adding too many parallel tasks causes the underlying infrastructure to use the resource capacity at 100% and impacta the environment performance and other operations. It's suggested you understand the resource capacity of the environment and consumption based on the parallel import tasks configured and limit the number of tasks.
Job history cleanup
By default, job history entries and related staging table data that are older than 90 days are automatically deleted. The job history cleanup functionality in data management can be used to configure periodic cleanup of the execution history with a lower retention period than this default. This functionality replaces the previous staging table cleanup functionality, which is now deprecated. The following tables are cleaned up by the cleanup process.
All staging tables
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
The Execution history cleanup feature is accessed from Data management > Job history cleanup.
Scheduling parameters
When you schedule the cleanup process, the following parameters must be specified to define the cleanup criteria.
Number of days to retain history – This setting is used to control the amount of execution history to be preserved. History is specified in number of days. When the cleanup job is scheduled as a recurring batch job, this setting acts like a continuously moving window thereby, always leaving the history for the specified number of days intact while deleting the rest. The default is seven days.
Number of hours to execute the job – Depending on the amount of history to be cleaned up, the total execution time for the cleanup job can vary from a few minutes to a few hours. This parameter must be set to the number of hours that the job executes. After the cleanup job has executed for the specified number of hours, the job exist and resumes the cleanup the next time it's run based on the recurrence schedule.
A maximum execution time can be specified by setting a max limit on the number of hours the job must run using this setting. The cleanup logic goes through one job execution ID at a time in a chronologically arranged sequence, with oldest being first for the cleanup of related execution history. It stops picking up new execution IDs for cleanup when the remaining execution duration is within the last 10% of the specified duration. In some cases, the cleanup job continues beyond the specified max time. This duration largely depends on the number of records to be deleted for the current execution ID that was started before the 10% threshold was reached. The cleanup that was started must be completed to ensure data integrity, which means that cleanup continues despite exceeding the specified limit. When complete, new execution IDs aren't picked up, and the cleanup job completes. The remaining execution history that wasn't cleaned up due to lack of enough execution time, is picked up the next time the cleanup job is scheduled. The default and minimum value for this setting is set to 2 hours.
Recurring batch – The cleanup job can be run as a one-time, manual execution, or it can be also scheduled for recurring execution in batch. The batch can be scheduled using the Run in background settings, which is the standard batch setup.
Note
If the Job history cleanup feature is not used, execution history older than 90 days is still automatically deleted. Job history cleanup can be run in addition to this automatic deletion. Ensure that the cleanup job is scheduled to run in recurrence. As explained above, in any cleanup execution the job only cleans up as many execution IDs as is possible within the provided maximum hours.
Job history cleanup and archival
Job history cleanup and archival functionality replace the previous versions of the cleanup functionality. This section explains these new capabilities.
One of the main changes to the cleanup functionality is the use of the system batch job for cleaning up the history. The use of the system batch job allows finance and operations apps to have the cleanup batch job automatically scheduled and running as soon as the system is ready. It's no longer required to schedule the batch job manually. In this default execution mode, the batch job executes every hour starting at midnight and retains the execution history for the most recent seven days. The purged history is archived for future retrieval. Starting with version 10.0.20, this feature in always on.
The second change in the cleanup process is the archival of the purged execution history. The cleanup job archives the deleted records to the blob storage that DIXF uses for regular integrations. The archived file is in the DIXF package format and is available for seven days in the blob during which time it can be downloaded. The default longevity of seven days for the archived file can be changed to a maximum of 90 days in the parameters.
Changing the default settings
This functionality is currently in preview and must be explicitly turned on by enabling the flight DMFEnableExecutionHistoryCleanupSystemJob. The staging cleanup feature must also be turned on in feature management.
To change the default setting for the longevity of the archived file, go to the data management workspace and select Job history cleanup. Set Days to retain package in blob to a value between 7 and 90 (inclusive). This change takes effect on the archives that are created after this change was made.
Downloading the archived package
This functionality is currently in preview and must be explicitly turned on by enabling the flight DMFEnableExecutionHistoryCleanupSystemJob. The staging cleanup feature must also be turned on in feature management.
To download the archived execution history, go to the data management workspace and select Job history cleanup. Select Package backup history to open the history form. This form shows the list of all archived packages. An archive can be selected and downloaded by selecting Download package. The downloaded package is in the DIXF package format and contains the following files:
- The entity staging table file
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Sorting composite entity data using xslt
This functionality lets you export a composite entity and apply xslt file to sort the data in xml file.
To sort composite entity data using xslt, follow these steps.
- Create an xslt file to sort the data in XML format. For example, if you have an XSLT file for the out of the box entity Purchase orders composite V3, you can sort the XML attribute format data in order by INVOICEVENDORACCOUNTNUMBER for PURCHPURCHASEORDERHEADERV2ENTITY and order by LINENUMBER for PURCHPURCHASEORDERLINEV2ENTITY.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Go to the Data management workspace.
- From the list of data export projects, select a project with XML data source and select View map.
- Select View map for any entity.
- Go to the Transformations tab
- Select New and upload the xslt file created in step 1.