Бележка
Достъпът до тази страница изисква удостоверяване. Можете да опитате да влезете или да промените директориите.
Достъпът до тази страница изисква удостоверяване. Можете да опитате да промените директориите.
Applies to: ![]() SQL Server 2017 (14.x) and later versions
SQL Server 2017 (14.x) and later versions ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
In this quickstart, you'll create and train a predictive model using Python. You'll save the model to a table in your SQL Server instance, and then use the model to predict values from new data using SQL Server Machine Learning Services, Azure SQL Managed Instance Machine Learning Services, or SQL Server Big Data Clusters.
You'll create and execute two stored procedures running in SQL. The first one uses the classic Iris flower data set and generates a Naïve Bayes model to predict an Iris species based on flower characteristics. The second procedure is for scoring - it calls the model generated in the first procedure to output a set of predictions based on new data. By placing Python code in a SQL stored procedure, operations are contained in SQL, are reusable, and can be called by other stored procedures and client applications.
By completing this quickstart, you'll learn:
- How to embed Python code in a stored procedure
- How to pass inputs to your code through inputs on the stored procedure
- How stored procedures are used to operationalize models
Prerequisites
You need the following prerequisites to run this quickstart.
A SQL database on one of these platforms:
- SQL Server Machine Learning Services. To install, see the Windows installation guide or the Linux installation guide.
- SQL Server Big Data Clusters. See how to enable Machine Learning Services on SQL Server Big Data Clusters.
- Azure SQL Managed Instance Machine Learning Services. For information, see the Azure SQL Managed Instance Machine Learning Services overview.
A tool for running SQL queries that contain Python scripts. This quickstart uses the MSSQL extension for Visual Studio Code.
The sample data used in this exercise is the Iris sample data. Follow the instructions in Iris demo data to create the sample database irissql.
Create a stored procedure that generates models
In this step, you'll create a stored procedure that generates a model for predicting outcomes.
Connect to your SQL instance with the MSSQL extension for Visual Studio Code, and open a new query window.
Connect to the irissql database.
USE irissql GOCopy in the following code to create a new stored procedure.
When executed, this procedure calls sp_execute_external_script to start a Python session.
Inputs needed by your Python code are passed as input parameters on this stored procedure. Output will be a trained model, based on the Python scikit-learn library for the machine learning algorithm.
This code uses pickle to serialize the model. The model will be trained using data from columns 0 through 4 from the iris_data table.
The parameters you see in the second part of the procedure articulate data inputs and model outputs. As much as possible, you want the Python code running in a stored procedure to have clearly defined inputs and outputs that map to stored procedure inputs and outputs passed in at run time.
CREATE PROCEDURE generate_iris_model (@trained_model VARBINARY(max) OUTPUT) AS BEGIN EXECUTE sp_execute_external_script @language = N'Python' , @script = N' import pickle from sklearn.naive_bayes import GaussianNB GNB = GaussianNB() trained_model = pickle.dumps(GNB.fit(iris_data[["Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"]], iris_data[["SpeciesId"]].values.ravel())) ' , @input_data_1 = N'select "Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width", "SpeciesId" from iris_data' , @input_data_1_name = N'iris_data' , @params = N'@trained_model varbinary(max) OUTPUT' , @trained_model = @trained_model OUTPUT; END; GOVerify the stored procedure exists.
If the T-SQL script from the previous step ran without error, a new stored procedure called generate_iris_model is created and added to the irissql database. You can find stored procedures in the Visual Studio Code Object Explorer, under Programmability.
Execute the procedure to create and train models
In this step, you execute the procedure to run the embedded code, creating a trained and serialized model as an output.
Models that are stored for reuse in your database are serialized as a byte stream and stored in a VARBINARY(MAX) column in a database table. Once the model is created, trained, serialized, and saved to a database, it can be called by other procedures or by the PREDICT T-SQL function in scoring workloads.
Run the following script to execute the procedure. The specific statement for executing a stored procedure is
EXECUTEon the fourth line.This particular script deletes an existing model of the same name ("Naive Bayes") to make room for new ones created by rerunning the same procedure. Without model deletion, an error occurs stating the object already exists. The model is stored in a table called iris_models, provisioned when you created the irissql database.
DECLARE @model varbinary(max); DECLARE @new_model_name varchar(50) SET @new_model_name = 'Naive Bayes' EXECUTE generate_iris_model @model OUTPUT; DELETE iris_models WHERE model_name = @new_model_name; INSERT INTO iris_models (model_name, model) values(@new_model_name, @model); GOVerify that the model was inserted.
SELECT * FROM dbo.iris_modelsResults
model_name model Naive Bayes 0x800363736B6C6561726E2E6E616976655F62617965730A...
Create and execute a stored procedure for generating predictions
Now that you have created, trained, and saved a model, move on to the next step: creating a stored procedure that generates predictions. You'll do this by calling sp_execute_external_script to run a Python script that loads the serialized model and gives it new data inputs to score.
Run the following code to create the stored procedure that performs scoring. At run time, this procedure will load a binary model, use columns
[1,2,3,4]as inputs, and specify columns[0,5,6]as output.CREATE PROCEDURE predict_species (@model VARCHAR(100)) AS BEGIN DECLARE @nb_model VARBINARY(max) = ( SELECT model FROM iris_models WHERE model_name = @model ); EXECUTE sp_execute_external_script @language = N'Python' , @script = N' import pickle irismodel = pickle.loads(nb_model) species_pred = irismodel.predict(iris_data[["Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"]]) iris_data["PredictedSpecies"] = species_pred OutputDataSet = iris_data[["id","SpeciesId","PredictedSpecies"]] print(OutputDataSet) ' , @input_data_1 = N'select id, "Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width", "SpeciesId" from iris_data' , @input_data_1_name = N'iris_data' , @params = N'@nb_model varbinary(max)' , @nb_model = @nb_model WITH RESULT SETS(( "id" INT , "SpeciesId" INT , "SpeciesId.Predicted" INT )); END; GOExecute the stored procedure, giving the model name "Naive Bayes" so that the procedure knows which model to use.
EXECUTE predict_species 'Naive Bayes'; GOWhen you run the stored procedure, it returns a Python data.frame. This line of T-SQL specifies the schema for the returned results:
WITH RESULT SETS ( ("id" int, "SpeciesId" int, "SpeciesId.Predicted" int));. You can insert the results into a new table, or return them to an application.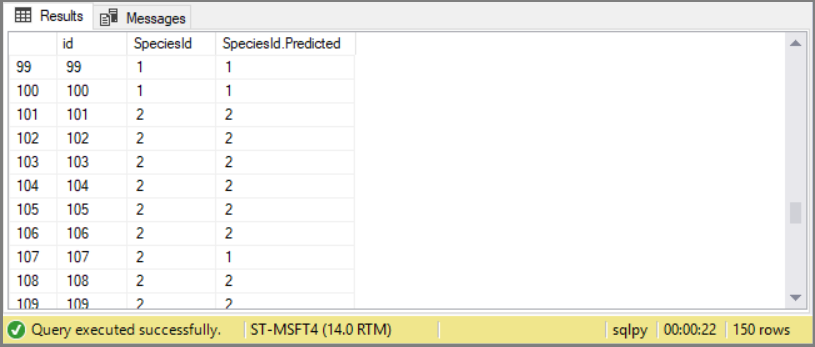
The results are 150 predictions about species using floral characteristics as inputs. For the majority of the observations, the predicted species matches the actual species.
This example has been made simple by using the Python iris dataset for both training and scoring. A more typical approach would involve running a SQL query to get the new data, and passing that into Python as
InputDataSet.
Conclusion
In this exercise, you learned how to create stored procedures dedicated to different tasks, where each stored procedure used the system stored procedure sp_execute_external_script to start a Python process. Inputs to the Python process are passed to sp_execute_external as parameters. Both the Python script itself and data variables in a database are passed as inputs.
Generally, you should only plan on using Visual Studio Code with polished Python code, or simple Python code that returns row-based output. As a tool, Visual Studio Code supports query languages like T-SQL and returns flattened rowsets. If your code generates visual output like a scatterplot or histogram, you need a separate tool or end-user application that can render the image outside of the stored procedure.
For some Python developers who are used to writing all-inclusive script handling a range of operations, organizing tasks into separate procedures might seem unnecessary. But training and scoring have different use cases. By separating them, you can put each task on a different schedule and scope permissions to each operation.
A final benefit is that the processes can be modified using parameters. In this exercise, Python code that created the model (named "Naive Bayes" in this example) was passed as an input to a second stored procedure calling the model in a scoring process. This exercise only uses one model, but you can imagine how parameterizing the model in a scoring task would make that script more useful.
Next steps
For more information on tutorials for Python with SQL machine learning, see: