Verschieben von Daten in den vFXT-Cluster – Parallele Datenerfassung
Nachdem Sie einen neuen vFXT-Cluster erstellt haben, besteht Ihre erste Aufgabe möglicherweise darin, Daten auf ein neues Speichervolumen in Azure zu verschieben. Wenn Ihre übliche Methode zum Verschieben von Daten jedoch einen einfachen Kopierbefehl von einem Client ausgibt, werden Sie wahrscheinlich eine langsame Kopierleistung feststellen. Der Singlethread-Kopiervorgang ist keine geeignete Option, um Daten in den Back-End-Speicher des Avere vFXT-Clusters zu kopieren.
Da der Avere vFXT-Cluster for Azure ein skalierbarer Multi-Client-Cache ist, besteht die schnellste und effizienteste Methode darin, die Daten mit mehreren Clients zu kopieren. Dieses Verfahren sorgt für die parallele Erfassung der Dateien und Objekte.
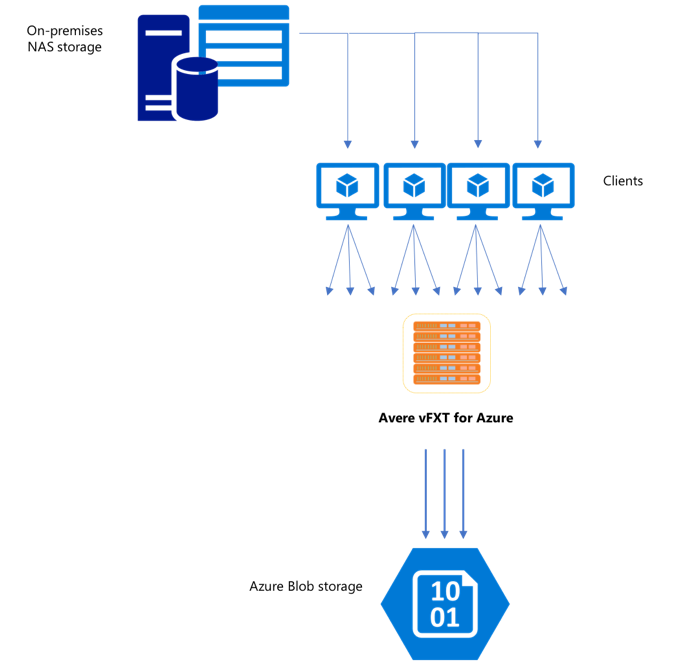
Die Befehle cp oder copy, die häufig verwendet werden, um Daten von einem Speichersystem zu einem anderen zu übertragen, sind Singlethread-Prozesse, die nur eine Datei zur Zeit kopieren. Das bedeutet, dass der Dateiserver immer nur eine Datei auf einmal erfasst, was eine Verschwendung der Ressourcen des Clusters darstellt.
In diesem Artikel werden Strategien zur Erstellung eines Dateikopiersystems mit mehreren Clients und mehreren Threads erläutert, mit dem Daten auf den Avere vFXT-Cluster verschoben werden können. Es werden Konzepte für die Dateiübertragung und Entscheidungspunkte erläutert, die für eine effiziente Datenkopie mit mehreren Clients und einfachen Kopierbefehlen verwendet werden können.
Es werden auch einige Hilfsprogramme erläutert, die hilfreich sein können. Das Hilfsprogramm msrsync kann verwendet werden, um den Prozess der Aufteilung eines Datasets in Buckets und der Verwendung von rsync-Befehlen teilweise zu automatisieren. Das parallelcp-Skript ist ein weiteres Hilfsprogramm, das das Quellverzeichnis liest und automatisch Kopierbefehle ausgibt. Außerdem kann das rsync-Tool in zwei Phasen verwendet werden, um eine schnellere Kopie bereitzustellen, die dennoch Datenkonsistenz bietet.
Klicken Sie auf den Link, um zu einem Abschnitt zu wechseln:
- Beispiel zum manuellen Kopieren: Eine ausführliche Beschreibung mit Kopierbefehlen.
- Beispiel für rsync in zwei Phasen
- Beispiel zur teilweisen Automatisierung (msrsync)
- Beispiel zum parallelen Kopieren
VM-Vorlage zur Datenerfassung
Eine Resource Manager-Vorlage ist auf GitHub verfügbar, um automatisch einen virtuellen Computer mit den in diesem Artikel erwähnten Tools zur parallelen Datenerfassung zu erstellen.
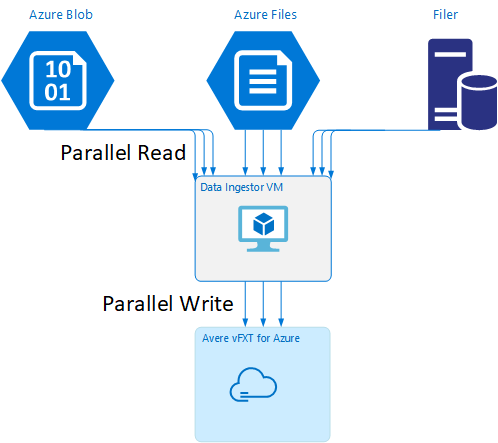
Der virtuelle Computer für die Datenerfassung ist Teil eines Tutorials, in dem der neu erstellte virtuelle Computer den Avere vFXT-Cluster einbindet und sein Bootstrap-Skript aus dem Cluster herunterlädt. Weitere Informationen finden Sie unter Bootstrap eines virtuellen Computers für die Datenerfassung.
Strategische Planung
Wenn Sie eine Strategie zum parallelen Kopieren von Daten entwerfen, sollten Sie die Kompromisse hinsichtlich Dateigröße, Anzahl der Dateien und Verzeichnistiefe kennen.
- Bei kleinen Dateien ist die relevante Metrik „Dateien pro Sekunde“.
- Bei großen Dateien (10 MB oder mehr) ist die relevante Metrik „Bytes pro Sekunde“.
Jeder Kopiervorgang hat eine Durchsatzrate und eine Übertragungsrate, die gemessen werden kann, indem die Dauer des Kopierbefehls gemessen wird und Dateigröße sowie Anzahl der Dateien berücksichtigt werden. Die Erläuterung der Vorgehensweise zur Messung der Raten liegt außerhalb des Rahmens dieses Dokuments, aber es ist wichtig zu verstehen, ob es sich um kleine oder große Dateien handelt.
Beispiel zum manuellen Kopieren
Sie können eine Kopie mit mehreren Threads manuell auf einem Client erstellen, indem Sie mehrere Kopierbefehle gleichzeitig im Hintergrund für vordefinierte Gruppen von Dateien oder Pfaden ausführen.
Der Linux/UNIX-Befehl cp enthält das Argument -p, um Besitz und mtime-Metadaten zu erhalten. Das Hinzufügen dieses Arguments zu den folgenden Befehlen ist optional. (Das Hinzufügen des Arguments erhöht die Anzahl der Dateisystemaufrufe, die vom Client an das Zieldateisystem zur Änderung der Metadaten gesendet werden.)
Dieses einfache Beispiel kopiert zwei Dateien parallel:
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
Nach der Ausführung dieses Befehls zeigt der Befehl jobs an, dass zwei Threads ausgeführt werden.
Vorhersagbare Dateinamenstruktur
Wenn Ihre Dateinamen vorhersagbar sind, können Sie Ausdrücke verwenden, um parallele Kopierthreads zu erstellen.
Wenn Ihr Verzeichnis z. B. 1000 Dateien enthält, die von 0001 bis 1000 durchnummeriert sind, können Sie die folgenden Ausdrücke verwenden, um zehn parallele Threads zu erstellen, die jeweils 100 Dateien kopieren:
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Unbekannte Dateinamenstruktur
Wenn Ihre Dateinamenstruktur nicht vorhersagbar ist, können Sie Dateien nach Verzeichnisnamen gruppieren.
In diesem Beispiel werden ganze Verzeichnisse gesammelt, um sie an cp-Befehle zu senden, die als Hintergrundaufgaben ausgeführt werden:
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
Nachdem die Dateien gesammelt wurden, können Sie parallele Kopierbefehle ausführen, um die Unterverzeichnisse und ihren gesamten Inhalt rekursiv zu kopieren:
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Zeitpunkt für das Hinzufügen von Bereitstellungspunkten
Nachdem Sie ausreichend parallele Threads auf einen einzelnen Bereitstellungspunkt des Zielsystems ausgerichtet haben, gibt es einen Punkt, an dem das Hinzufügen weiterer Threads nicht zu einem höheren Durchsatz führt. (Der Durchsatz wird in Dateien/Sekunde oder Bytes/Sekunde gemessen, abhängig vom Datentyp.) Im schlimmsten Fall kann eine zu große Anzahl von Threads zu einer Verringerung des Durchsatzes führen.
In diesem Fall können Sie clientseitige Bereitstellungspunkte zu anderen IP-Adressen des vFXT-Clusters hinzufügen, wobei Sie denselben Bereitstellungspfad des Remotedateisystems verwenden:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
Das Hinzufügen von clientseitigen Bereitstellungspunkten ermöglicht es Ihnen, weitere Kopierbefehle für die zusätzlichen /mnt/destination[1-3]-Bereitstellungspunkte abzuspalten, um die Parallelität zu erhöhen.
Wenn Sie z. B. sehr große Dateien verwenden, können Sie die Kopierbefehle so definieren, dass sie unterschiedliche Zielpfade verwenden und mehr Befehle parallel vom Client aus senden, der den Kopiervorgang durchführt.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
Im obigen Beispiel sind die Kopiervorgänge der Clientdateien auf alle drei Zielbereitstellungspunkte ausgerichtet.
Zeitpunkt zum Hinzufügen von Clients
Wenn Sie die Kapazitäten des Clients erreicht haben, führt das Hinzufügen weiterer Kopierthreads oder zusätzlicher Bereitstellungspunkte nicht zu einer weiteren Erhöhung der „Dateien/Sekunde“ oder „Bytes/Sekunde“. In dieser Situation können Sie einen weiteren Client mit demselben Satz von Bereitstellungspunkten bereitstellen, der auch eigene Sätze von Dateikopiervorgängen ausführen wird.
Beispiel:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Erstellen von Dateimanifesten
Nachdem Sie die oben genannten Ansätze verstanden haben (mehrere Kopierthreads pro Ziel, mehrere Ziele pro Client, mehrere Clients pro netzwerkfähigem Quelldateisystem), sollten Sie die folgende Empfehlung beachten: Erstellen Sie Dateimanifeste, und verwenden Sie sie dann mit Kopierbefehlen für mehrere Clients.
Dieses Szenario verwendet den UNIX-Befehl find, um Manifeste von Dateien oder Verzeichnissen zu erstellen:
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Leiten Sie dieses Ergebnis in eine Datei um: find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
Dann können Sie das Manifest mithilfe von BASH-Befehlen durchlaufen, um Dateien zu zählen und die Größe der Unterverzeichnisse zu bestimmen:
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Schließlich müssen Sie die eigentlichen Befehle zum Kopieren von Dateien an die Clients anpassen.
Wenn Sie über vier Clients verfügen, verwenden Sie den folgenden Befehl:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Bei fünf Clients verwenden Sie einen Befehl wie den folgenden:
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
Und für sechs Befehle... Extrapolieren Sie bei Bedarf.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Sie erhalten N Ergebnisdateien, eine für jeden Ihrer N Clients, der über die Pfadnamen zu den Level-4-Verzeichnissen verfügt, die als Teil der Ausgabe des Befehls find erhalten wurden.
Verwenden Sie die einzelnen Dateien, um den Kopierbefehl zu erstellen:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
Das obige Beispiel liefert Ihnen N Dateien, jede mit einem Kopierbefehl pro Zeile, die als BASH-Skript auf dem Client ausgeführt werden können.
Ziel ist es, mehrere Threads dieser Skripts gleichzeitig pro Client parallel auf mehreren Clients auszuführen.
Verwenden eines rsync-Prozesses in zwei Phasen
Das rsync-Standardhilfsprogramm funktioniert nicht gut für das Auffüllen des Cloudspeichers über Avere vFXT für das Azure-System, da es eine große Anzahl von Dateierstellungs- und -umbenennungsvorgängen generiert, um die Datenintegrität zu gewährleisten. Allerdings können Sie die Option --inplace mit rsync auf sichere Weise verwenden, um das ausführlichere Kopierverfahren zu überspringen, wenn Sie anschließend einen zweiten Testlauf durchführen, um die Dateiintegrität zu überprüfen.
Bei einem rsync-Standardkopiervorgang wird eine temporäre Datei erstellt und mit Daten aufgefüllt. Wenn die Datenübertragung erfolgreich abgeschlossen wurde, wird die temporäre Datei in den ursprünglichen Dateinamen umbenannt. Diese Methode gewährleistet Konsistenz selbst dann, wenn während des Kopiervorgangs auf die Dateien zugegriffen wird. Diese Methode generiert jedoch weitere Schreibvorgänge, wodurch die Dateibewegung durch den Cache verlangsamt wird.
Mit der Option --inplace wird die neue Datei direkt an ihren endgültigen Speicherort geschrieben. Es ist nicht garantiert, dass Dateien während der Übertragung konsistent sind, aber das ist nicht wichtig, wenn Sie ein Speichersystem für die spätere Verwendung vorbereiten.
Der zweite rsync-Vorgang dient als Konsistenzprüfung für den ersten Vorgang. Da die Dateien bereits kopiert wurden, ist die zweite Phase eine schnelle Überprüfung, um sicherzustellen, dass die Dateien im Ziel den Dateien in der Quelle entsprechen. Wenn Dateien nicht übereinstimmen, werden Sie erneut kopiert.
Beide Phasen können mit einem Befehl ausgegeben werden:
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Diese Methode ist eine einfache und zeiteffektive Methode für Datasets bis zur Anzahl der Dateien, die der interne Verzeichnis-Manager verarbeiten kann. (Hierbei handelt es sich in der Regel um 200 Millionen Dateien für einen Cluster mit drei Knoten, 500 Millionen Dateien für einen Cluster mit sechs Knoten usw.)
Verwenden des msrsync-Hilfsprogramms
Das msrsync-Tool kann auch verwendet werden, um Daten in eine Back-End-Kernspeichereinheit für den Avere-Cluster zu verschieben. Dieses Tool wurde entwickelt, um die Bandbreitenauslastung durch die Ausführung mehrerer paralleler rsync-Prozesse zu optimieren. Es ist bei GitHub unter https://github.com/jbd/msrsync erhältlich.
msrsync unterteilt das Quellverzeichnis in separate „Buckets“ und führt dann einzelne rsync-Prozesse für die einzelnen Buckets aus.
Vorläufige Tests mit einem virtuellen Computer mit vier Kernen zeigten die höchste Effizienz bei der Verwendung von 64 Prozessen. Verwenden Sie die msrsync-Option -p, um die Anzahl der Prozesse auf 64 festzulegen.
Sie können auch das --inplace-Argument mit msrsync-Befehlen verwenden. Wenn Sie diese Option verwenden, sollten Sie ggf. einen zweiten Befehl ausführen (wie bei rsync, siehe oben), um die Datenintegrität sicherzustellen.
msrsync kann nur auf lokale Volumes und von lokalen Volumes schreiben. Quelle und Ziel müssen als lokale Bereitstellungen im virtuellen Netzwerk des Clusters zugänglich sein.
Befolgen Sie diese Anweisungen, um mit msrsync ein Azure-Cloudvolume mit einem Avere-Cluster aufzufüllen:
Installieren Sie
msrsyncund seine Voraussetzungen (rsync und Python 2.6 oder höher)Bestimmen Sie die Gesamtzahl der zu kopierenden Dateien und Verzeichnisse.
Verwenden Sie z.B. das Avere-Hilfsprogramm
prime.pymit den Argumentenprime.py --directory /path/to/some/directory(verfügbar durch Herunterladen der URL https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py).Wenn Sie
prime.pynicht verwenden, können Sie die Anzahl der Elemente mit dem GNU-Toolfindwie folgt berechnen:find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Teilen Sie die Anzahl der Elemente durch 64, um die Anzahl der Elemente pro Prozess zu ermitteln. Verwenden Sie diese Zahl zusammen mit der Option
-f, um die Größe der Buckets festzulegen, wenn Sie den Befehl ausführen.Führen Sie den Befehl
msrsyncaus, um Dateien zu kopieren:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Wenn Sie
--inplaceverwenden, fügen Sie eine zweite Ausführung ohne die Option hinzu, um zu überprüfen, ob die Daten ordnungsgemäß kopiert werden:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Dieser Befehl ist z. B. so konzipiert, dass 11.000 Dateien in 64 Prozessen von „/test/source-repository“ nach „/mnt/vfxt/repository“ verschoben werden:
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Verwenden des Skripts zum parallelen Kopieren
Das parallelcp-Skript kann auch hilfreich sein, um Daten in den Back-End-Speicher Ihres vFXT-Clusters zu verschieben.
Das folgende Skript fügt die ausführbare Datei parallelcp hinzu. (Dieses Skript ist für Ubuntu vorgesehen. Wenn Sie eine andere Distribution verwenden, müssen Sie parallel separat installieren.)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Beispiel zum parallelen Kopieren
In diesem Beispiel wird das Skript zum parallelen Kopieren verwendet, um glibc mit Quelldateien aus dem Avere-Cluster zu kompilieren.
Die Quelldateien werden auf dem Bereitstellungspunkt des Avere-Clusters und die Objektdateien auf der lokalen Festplatte gespeichert.
Dieses Skript verwendet das oben beschriebene parallele Kopierskript. Die Option -j wird zusammen mit parallelcp und make verwendet, um eine Parallelisierung zu erreichen.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j