Konfigurieren der Datensammlung und Kostenoptimierung in Container Insights mithilfe einer Datensammlungsregel
In diesem Artikel wird beschrieben, wie Sie die Datensammlung in Container Insights mithilfe einer Datensammlungsregel (Data Collection Rule, DCR) für Ihr Kubernetes-Cluster konfigurieren. Dazu gehören voreingestellte Konfigurationen zur Optimierung Ihrer Kosten. Wenn Sie einen Cluster in Container Insights integrieren, wird eine Datensammlungsregel erstellt. Diese Datensammlungsregel wird vom containerisierten Agent verwendet, um die Datensammlung für den Cluster zu definieren.
Die Datensammlungsregel wird in erster Linie zum Konfigurieren der Datensammlung von Leistungs- und Bestandsdaten und zum Konfigurieren der Kostenoptimierung verwendet.
Mit einer Datensammlungsregel können Sie Folgendes konfigurieren:
- Aktivieren/Deaktivieren Sie Sammlungen und die Namespacefilterung von Leistungs- und Bestandsdaten.
- Definieren des Sammlungsintervalls für Leistungs- und Bestandsdaten
- Aktivieren/Deaktivieren der Syslog-Sammlung
- Auswählen des Protokollschemas
Wichtig
Die vollständige Konfiguration der Datensammlung in Container Insights erfordert möglicherweise die Bearbeitung sowohl des DCR als auch der ConfigMap für den Cluster, da jede Methode die Konfiguration einer anderen Gruppe von Einstellungen zulässt.
Siehe Konfigurieren der Datensammlung in Container Insights mit ConfigMap für eine Liste der Einstellungen und des Prozesses zum Konfigurieren der Datensammlung mithilfe von ConfigMap.
Voraussetzungen
- AKS-Cluster müssen entweder eine systemseitig oder eine benutzerseitig zugewiesene verwaltete Identität verwenden. Wenn der Cluster den Dienstprinzipal verwendet, müssen Sie ein Upgrade auf Verwaltete Identität durchführen.
Konfigurieren der Datensammlung
Die Datensammlungsregel, die beim Aktivieren von Container Insights erstellt wird, heißt MSCI-<Clusterregion>-<Clustername>. Sie können sie im Azure-Portal anzeigen, indem Sie im Azure-Portal im Menü Überwachen die Option Datensammlungsregeln auswählen. Anstatt die Datensammlungsregel direkt zu ändern, sollten Sie eine der unten beschriebenen Methoden verwenden, um die Datensammlung zu konfigurieren. Details zu den verfügbaren Einstellungen für die verschiedenen Methoden finden Sie unter Datensammlungsparameter.
Warnung
Die Standardbenutzeroberfläche „Containererkenntnisse“ hängt von allen vorhandenen Datenströmen ab. Wenn Sie einen oder mehrere der Standarddatenströme entfernen, ist die Oberfläche „Containererkenntnisse“ nicht verfügbar, und Sie müssen andere Tools wie Grafana-Dashboards und Protokollabfragen verwenden, um gesammelte Daten zu analysieren.
Sie können das Azure-Portal verwenden, um die Kostenoptimierung auf Ihrem vorhandenen Cluster zu aktivieren, nachdem Containererkenntnisse aktiviert wurden, oder Sie können Containererkenntnisse im Cluster zusammen mit der Kostenoptimierung aktivieren.
Wählen Sie den Cluster im Azure-Portal aus.
Wählen Sie im Menü Überwachung die Option Erkenntnisse aus.
Wenn Containererkenntnisse bereits im Cluster aktiviert wurde, wählen Sie die Schaltfläche Überwachungseinstellungen aus. Wählen Sie andernfalls Azure Monitor konfigurieren aus, und lesen Sie Überwachung auf Ihrem Kubernetes-Cluster mit Azure Monitor aktivieren für Details zum Aktivieren der Überwachung.
Wählen Sie für AKS und Arc-fähige Kubernetes die Option Verwaltete Identität verwenden aus, wenn Sie den Cluster noch nicht zur verwalteten Identitätsauthentifizierung migriert haben.
Wählen Sie eine der in den Kostenvoreinstellungen beschriebenen Kostenvoreinstellungen aus.
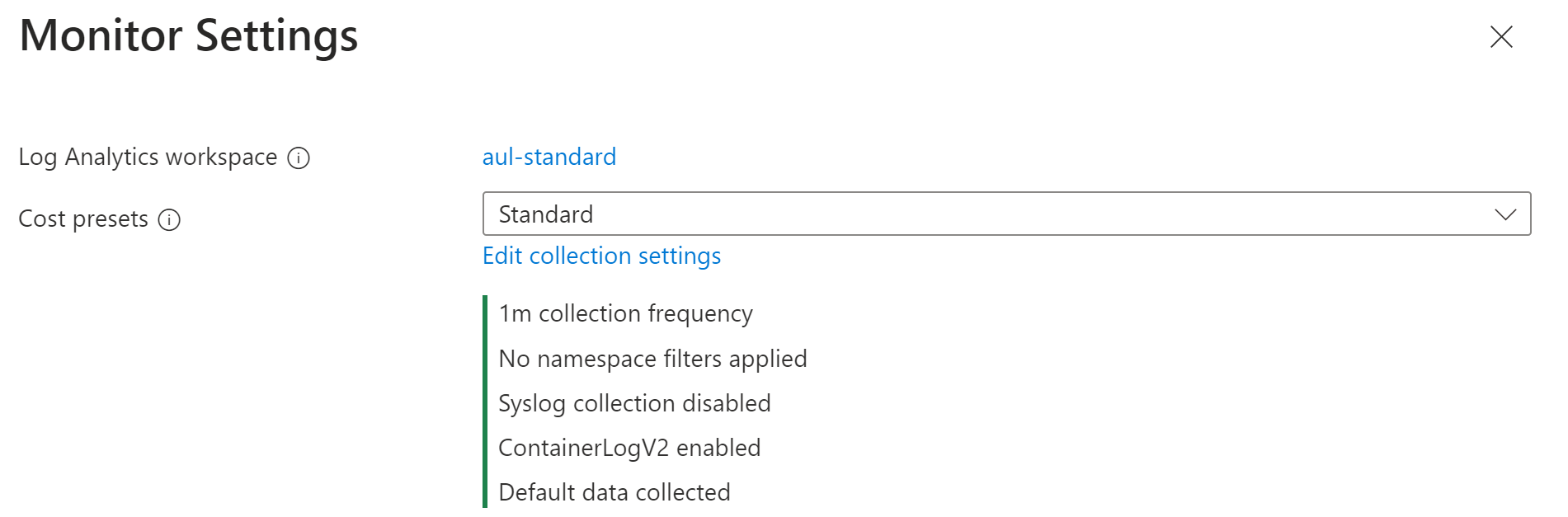
Wenn Sie die Einstellungen anpassen möchten, klicken Sie auf Sammlungseinstellungen bearbeiten. Details zu den einzelnen Einstellungen finden Sie unter Datensammlungsparameter. Informationen zu gesammelten Datenfinden Sie unten unter Gesammelte Daten.

Klicken Sie auf Konfigurieren, um die Einstellungen zu speichern.



Kostenvoreinstellungen
Wenn Sie das Azure-Portal zum Konfigurieren der Kostenoptimierung verwenden, können Sie aus den folgenden voreingestellten Konfigurationen auswählen. Sie können eine dieser Einstellungen auswählen oder eigene angepasste Einstellungen angeben. Standardmäßig verwendet Container Insights die Voreinstellung Standard.
| Kostenvoreinstellung | Sammlungshäufigkeit | Namespacefilter | Syslog-Sammlung | Gesammelte Daten |
|---|---|---|---|---|
| Standard | 1 m | Keine | Nicht aktiviert | Alle Container Insights-Standardtabellen |
| Kostenoptimiert | 5 m | Schließt „kube-system“, „gatekeeper-system“, „azure-arc“ aus. | Nicht aktiviert | Alle Container Insights-Standardtabellen |
| syslog | 1 m | Keine | Standardmäßig aktiviert | Alle Container Insights-Standardtabellen |
| Protokolle und Ereignisse | 1 m | Keine | Nicht aktiviert | ContainerLog/ContainerLogV2 KubeEvents KubePodInventory |
Gesammelte Daten
Mit der Option Gesammelte Daten können Sie die Tabellen auswählen, die für den Cluster aufgefüllt werden. Dies entspricht dem streams-Parameter beim Ausführen der Konfiguration mit CLI oder ARM. Wenn Sie eine andere Option als Alle (Standard)auswählen, ist die Oberfläche „Containererkenntnisse“ nicht verfügbar, und Sie müssen Grafana oder andere Methoden verwenden, um gesammelte Daten zu analysieren.

| Gruppierung | Tabellen | Hinweise |
|---|---|---|
| Alle (Standard) | Alle Container Insights-Standardtabellen | Zum Aktivieren der Container Insights-Standardvisualisierungen erforderlich |
| Leistung | Perf, InsightsMetrics | |
| Protokolle und Ereignisse | ContainerLog oder ContainerLogV2, KubeEvents, KubePodInventory | Empfohlen, wenn Sie verwaltete Prometheus-Metriken aktiviert haben |
| Workloads, Bereitstellungen und HPAs | InsightsMetrics, KubePodInventory, KubeEvents, ContainerInventory, ContainerNodeInventory, KubeNodeInventory, KubeServices | |
| Persistent Volumes | InsightsMetrics, KubePVInventory |
Parameter für die Datensammlung
In der folgenden Tabelle werden die unterstützten Datensammlungseinstellungen und der Name, der für die einzelnen Onboardingoptionen verwendet wird, beschrieben.
| Name | Beschreibung |
|---|---|
| Sammlungshäufigkeit CLI: intervalARM: dataCollectionInterval |
Bestimmt, wie oft der Agent Daten sammelt. Gültige Werte sind 1 Min. bis 30 Min. in 1 Min.-Intervallen. Der Standardwert ist 1 Min. Wenn sich der Wert außerhalb des zulässigen Bereichs befindet, wird er standardmäßig auf 1 Min. festgelegt. |
| Namespacefilterung CLI: namespaceFilteringModeARM: namespaceFilteringModeForDataCollection |
Include: Erfasst nur Daten aus den Werten im Feld Namespaces. Exclude: Erfasst Daten aus allen Namespaces mit Ausnahme der Werte im Feld Namespaces. Off: Ignoriert mögliche ausgewählte Namespaces und sammelt Daten für alle Namespaces. |
| Namespacefilterung CLI: namespacesARM: namespacesForDataCollection |
Array von durch Kommas getrennten Kubernetes-Namespaces zum Sammeln von Bestands- und Leistungsdaten basierend auf der namespaceFilteringMode. Beispielsweise werden bei namespaces = [“kube-system“, „default“] mit der Einstellung Include nur Daten für diese beiden Namespaces erfasst. Bei der Einstellung Exclude sammelt der Agent Daten aus allen Namespaces mit Ausnahme der Namespaces kube-system und default. Bei der Einstellung Off sammelt der Agent Daten aus allen Namespaces, einschließlich kube-system und default. Ungültige und nicht erkannte Namespaces werden ignoriert. |
| Aktivieren von ContainerLogV2 CLI: enableContainerLogV2ARM: enableContainerLogV2 |
Boolesches Flag zum Aktivieren des ContainerLogV2-Schemas. Wenn dieser Wert auf „true“ festgelegt ist, werden die Stdout/stderr-Protokolle in die Tabelle ContainerLogV2 aufgenommen. Andernfalls werden die Containerprotokolle in die Tabelle Containerlog aufgenommen, sofern nicht anders in der ConfigMap angegeben. Wenn Sie die einzelnen Datenströme angeben, müssen Sie die entsprechende Tabelle für „ContainerLog“ oder „ContainerLogV2“ einschließen. |
| Gesammelte Daten CLI: streamsARM: streams |
Ein Array von Containererkenntnis-Tabellendatenströmen. Weitere Informationen finden Sie unter den unterstützten Zuordnungen zwischen Datenströmen und Tabellen weiter oben. |
Anwendbare Tabellen und Metriken
Die Einstellungen für die Sammlungshäufigkeit und Namespacefilterung gelten nicht für alle Containererkenntnisdaten. In der folgenden Tabelle sind die Tabellen im Log Analytics-Arbeitsbereich aufgeführt, die von Container Insights verwendet werden, sowie die gesammelten Metriken mit den jeweils geltenden Einstellungen.
Hinweis
Diese Funktion konfiguriert Einstellungen für alle Containererkenntnistabellen mit Ausnahme von ContainerLog und ContainerLogV2. Um die Einstellungen für diese Tabellen zu konfigurieren, aktualisieren Sie die in den Agentdatensammlungs-Einstellungen beschriebene ConfigMap.
| Tabellenname | Interval? | Namespaces? | Hinweise |
|---|---|---|---|
| ContainerInventory | Ja | Ja | |
| ContainerNodeInventory | Ja | Nein | Die Einstellung zur Datensammlung für Namespaces ist nicht anwendbar, da Kubernetes Node keine Namespace-Ressource ist. |
| KubeNodeInventory | Ja | Nein | Die Einstellung für die Datensammlung für Namespaces ist nicht anwendbar; Kubernetes Node ist keine Namespace-Ressource |
| KubePodInventory | Ja | Ja | |
| KubePVInventory | Ja | Ja | |
| KubeServices | Ja | Ja | |
| KubeEvents | Nein | Ja | Die Einstellung zur Datensammlung für das Intervall ist für Kubernetes Events nicht anwendbar |
| Perf | Ja | Ja | Die Einstellung zur Datensammlung für Namespaces gilt nicht für die auf Kubernetes Node bezogenen Metriken, da Kubernetes Node kein Namespace-Objekt ist. |
| InsightsMetrics | Ja | Ja | Datensammlungseinstellungen gelten nur für die Metriken, die die folgenden Namespaces sammeln: container.azm.ms/kubestate, container.azm.ms/pv und container.azm.ms/gpu |
| Metriknamespace | Interval? | Namespaces? | Hinweise |
|---|---|---|---|
| Insights.container/nodes | Ja | Nein | Node ist keine Namespace-Ressource. |
| Insights.container/pods | Ja | Ja | |
| Insights.container/containers | Ja | Ja | |
| Insights.container/persistentvolumes | Ja | Ja |
Datenstromwerte
Wenn Sie die Tabellen angeben, die mit CLI oder ARM gesammelt werden sollen, geben Sie einen Datenstromnamen an, der einer bestimmten Tabelle im Log Analytics-Arbeitsbereich entspricht. In der folgenden Tabelle sind die Datenstromnamen für jede Tabelle aufgeführt.
Hinweis
Wenn Sie mit der Struktur einer Datensammlungsregel vertraut sind, können Sie die Datenstromnamen in dieser Tabelle im Abschnitt dataFlows der Datensammlungsregel angegeben.
| STREAM | Container Insights-Tabelle |
|---|---|
| Microsoft-ContainerInventory | ContainerInventory |
| Microsoft-ContainerLog | ContainerLog |
| Microsoft-ContainerLogV2 | ContainerLogV2 |
| Microsoft-ContainerNodeInventory | ContainerNodeInventory |
| Microsoft-InsightsMetrics | InsightsMetrics |
| Microsoft-KubeEvents | KubeEvents |
| Microsoft-KubeMonAgentEvents | KubeMonAgentEvents |
| Microsoft-KubeNodeInventory | KubeNodeInventory |
| Microsoft-KubePodInventory | KubePodInventory |
| Microsoft-KubePVInventory | KubePVInventory |
| Microsoft-KubeServices | KubeServices |
| Microsoft-Perf | Perf |
Auswirkungen auf Visualisierungen und Warnungen
Wenn Sie die obigen Tabellen derzeit für andere benutzerdefinierte Alarme oder Diagramme verwenden, kann die Änderung Ihrer Datenerfassungseinstellungen möglicherweise diese Erfahrungen beeinträchtigen. Wenn Sie Namespaces ausschließen oder die Häufigkeit der Datenerfassung reduzieren, überprüfen Sie Ihre bestehenden Warnmeldungen, Dashboards und Arbeitsmappen, die diese Daten verwenden.
Führen Sie die folgende Azure Resource Graph-Abfrage aus, um nach Warnungen zu suchen, die auf diese Tabellen verweisen:
resources
| where type in~ ('microsoft.insights/scheduledqueryrules') and ['kind'] !in~ ('LogToMetric')
| extend severity = strcat("Sev", properties["severity"])
| extend enabled = tobool(properties["enabled"])
| where enabled in~ ('true')
| where tolower(properties["targetResourceTypes"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["targetResourceType"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["scopes"]) matches regex 'providers/microsoft.operationalinsights/workspaces($|/.*)?'
| where properties contains "Perf" or properties contains "InsightsMetrics" or properties contains "ContainerInventory" or properties contains "ContainerNodeInventory" or properties contains "KubeNodeInventory" or properties contains"KubePodInventory" or properties contains "KubePVInventory" or properties contains "KubeServices" or properties contains "KubeEvents"
| project id,name,type,properties,enabled,severity,subscriptionId
| order by tolower(name) asc
Nächste Schritte
- Weitere Informationen zum Konfigurieren der Datensammlung mit ConfigMap anstelle einer Datensammlungsregel finden Sie unter Konfigurieren der Datensammlung in Container Insights mithilfe von ConfigMap.