Massenkopieren aus einer Datenbank mit einer Steuertabelle
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Sie müssen große Datenmengen aus mehreren Tabellen laden, um Daten aus einem Data Warehouse in Oracle Server, Netezza, Teradata oder SQL Server in Azure Synapse Analytics zu kopieren. In der Regel müssen die Daten in den einzelnen Tabellen partitioniert werden, um Zeilen mit mehreren Threads parallel aus einer einzelnen Tabelle laden zu können. In diesem Artikel wird eine Vorlage für diese Szenarios beschrieben.
Hinweis
Wenn Sie Daten aus einer kleinen Anzahl von Tabellen mit relativ geringem Datenvolumen in Azure Synapse Analytics kopieren möchten, ist es effizienter, das Tool zum Kopieren von Daten in Azure Data Factory zu verwenden. Die in diesem Artikel beschriebene Vorlage ist für dieses Szenario umfangreicher als notwendig.
Informationen zu dieser Lösungsvorlage
Mit dieser Vorlage wird eine Liste der Quelldatenbankpartitionen abgerufen, die aus einer externen Steuertabelle kopiert werden sollen. Anschließend wird jede Partition in der Quelldatenbank durchlaufen und die Daten werden in das Ziel kopiert.
Die Vorlage enthält drei Aktivitäten:
- Die Lookup-Aktivität ruft die Liste der sicheren Datenbankpartitionen aus einer externen Steuertabelle ab.
- Die ForEach-Aktivität ruft die Partitionsliste aus der Lookup-Aktivität ab und durchläuft jede Partition für die Kopieraktivität.
- Die Kopieraktivität kopiert alle Partitionen aus dem Quelldatenbankspeicher in den Zielspeicher.
Die Vorlage definiert die folgenden Parameter:
- Control_Table_Name entspricht Ihrer externen Steuertabelle, in der die Partitionsliste für die Quelldatenbank gespeichert wird.
- Control_Table_Schema_PartitionID entspricht dem Spaltennamen in Ihrer externen Steuertabelle, in der die Partitions-IDs gespeichert werden. Stellen Sie sicher, dass die Partitions-IDs für jede Partition in der Quelldatenbank eindeutig sind.
- Control_Table_Schema_SourceTableName entspricht Ihrer externen Steuertabelle, in der alle Tabellennamen aus der Quelldatenbank gespeichert werden.
- Control_Table_Schema_FilterQuery entspricht dem Spaltennamen in Ihrer externen Steuertabelle, in der die Filterabfragen zum Abrufen der Daten aus den Partitionen in der Quelldatenbank gespeichert werden. Wenn die Daten beispielsweise nach Jahr partitioniert wurden, kann die in den einzelnen Zeilen gespeicherte Abfrage wie die folgende aussehen: 'select * from datasource where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''.
- Data_Destination_Folder_Path ist der Pfad, an den die Daten in Ihren Zielspeicher kopiert werden (zutreffend, wenn das ausgewählte Ziel „Dateisystem“ oder „Azure Data Lake Storage Gen1“ ist).
- Data_Destination_Container ist der Stammordnerpfad, in den die Daten in Ihrem Zielspeicher kopiert werden.
- Data_Destination_Directory ist der Verzeichnispfad unter dem Stammelement, in den die Daten in Ihrem Zielspeicher kopiert werden.
Die letzten drei Parameter, die den Pfad im Zielspeicher definieren, werden nur angezeigt, wenn es sich bei dem ausgewählten Ziel um einen dateibasierten Speicher handelt. Wenn Sie „Azure Synapse Analytics“ als Zielspeicher auswählen, sind diese Parameter nicht erforderlich. Die Tabellennamen und das Schema in Azure Synapse Analytics müssen jedoch den Tabellennamen und dem Schema in der Quelldatenbank entsprechen.
So verwenden Sie diese Lösungsvorlage
Erstellen Sie eine Steuertabelle in SQL Server oder Azure SQL-Datenbank zum Speichern der Partitionsliste der Quelldatenbank für den Massenkopiervorgang. Im folgenden Beispiel enthält die Quelldatenbank fünf Partitionen. Drei Partitionen sind für die Tabelle datasource_table und die zwei anderen für die Tabelle project_table. Die Spalte LastModifyTime wird verwendet, um die Daten in der Tabelle datasource_table aus der Quelldatenbank zu partitionieren. Die Abfrage zum Lesen der ersten Partition lautet wie folgt: 'select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''. Sie können eine ähnliche Abfrage zum Lesen von Daten aus anderen Partitionen verwenden.
Create table ControlTableForTemplate ( PartitionID int, SourceTableName varchar(255), FilterQuery varchar(255) ); INSERT INTO ControlTableForTemplate (PartitionID, SourceTableName, FilterQuery) VALUES (1, 'datasource_table','select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''), (2, 'datasource_table','select * from datasource_table where LastModifytime >= ''2016-01-01 00:00:00'' and LastModifytime <= ''2016-12-31 23:59:59.999'''), (3, 'datasource_table','select * from datasource_table where LastModifytime >= ''2017-01-01 00:00:00'' and LastModifytime <= ''2017-12-31 23:59:59.999'''), (4, 'project_table','select * from project_table where ID >= 0 and ID < 1000'), (5, 'project_table','select * from project_table where ID >= 1000 and ID < 2000');Wechseln Sie zur Vorlage Bulk Copy from Database (Massenkopieren aus einer Datenbank). Stellen Sie eine neue Verbindung mit der externen Steuertabelle her, die Sie in Schritt 1 erstellt haben.
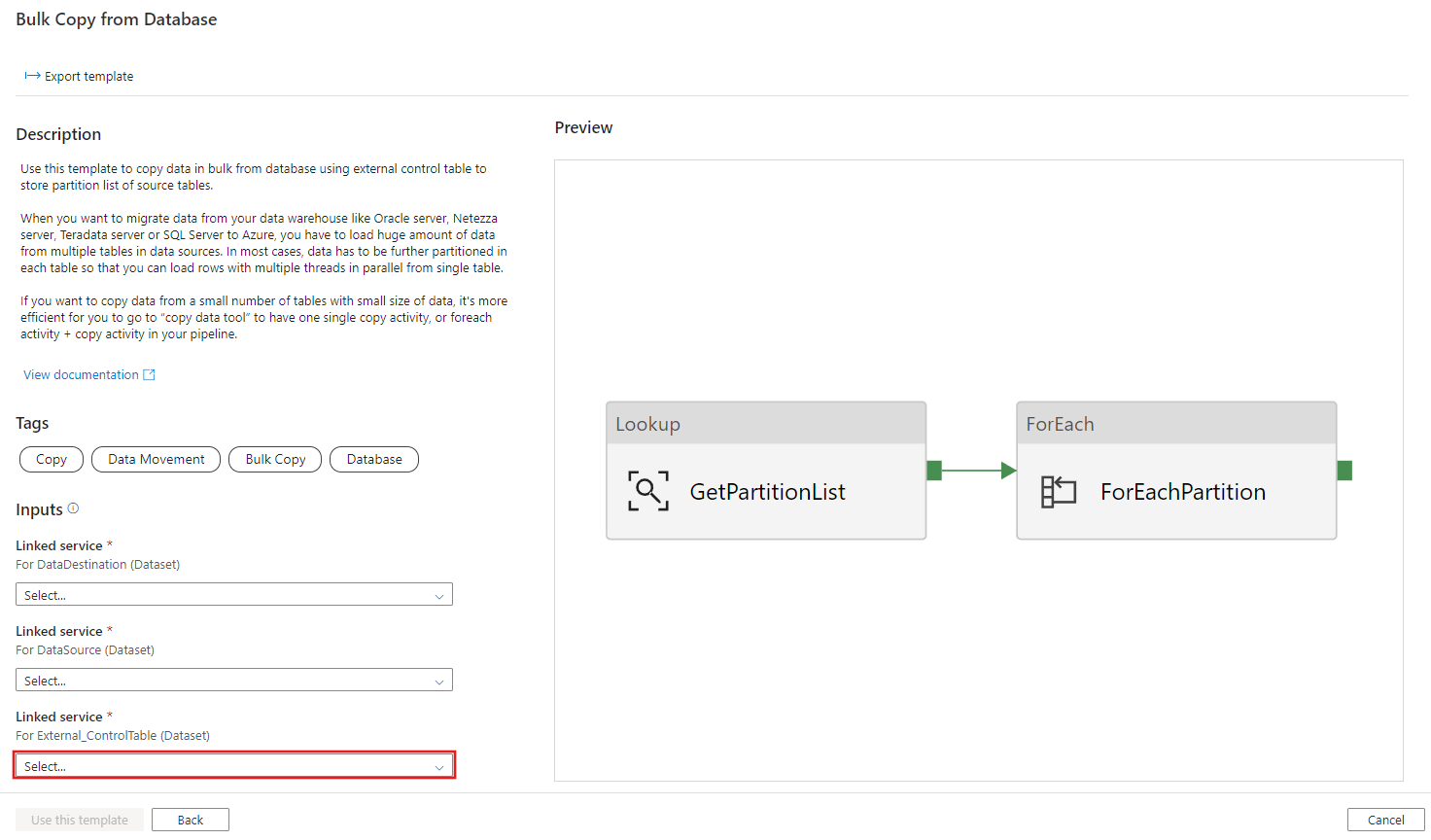
Stellen Sie eine neue Verbindung mit der Quelldatenbank her, aus der Sie Daten kopieren.
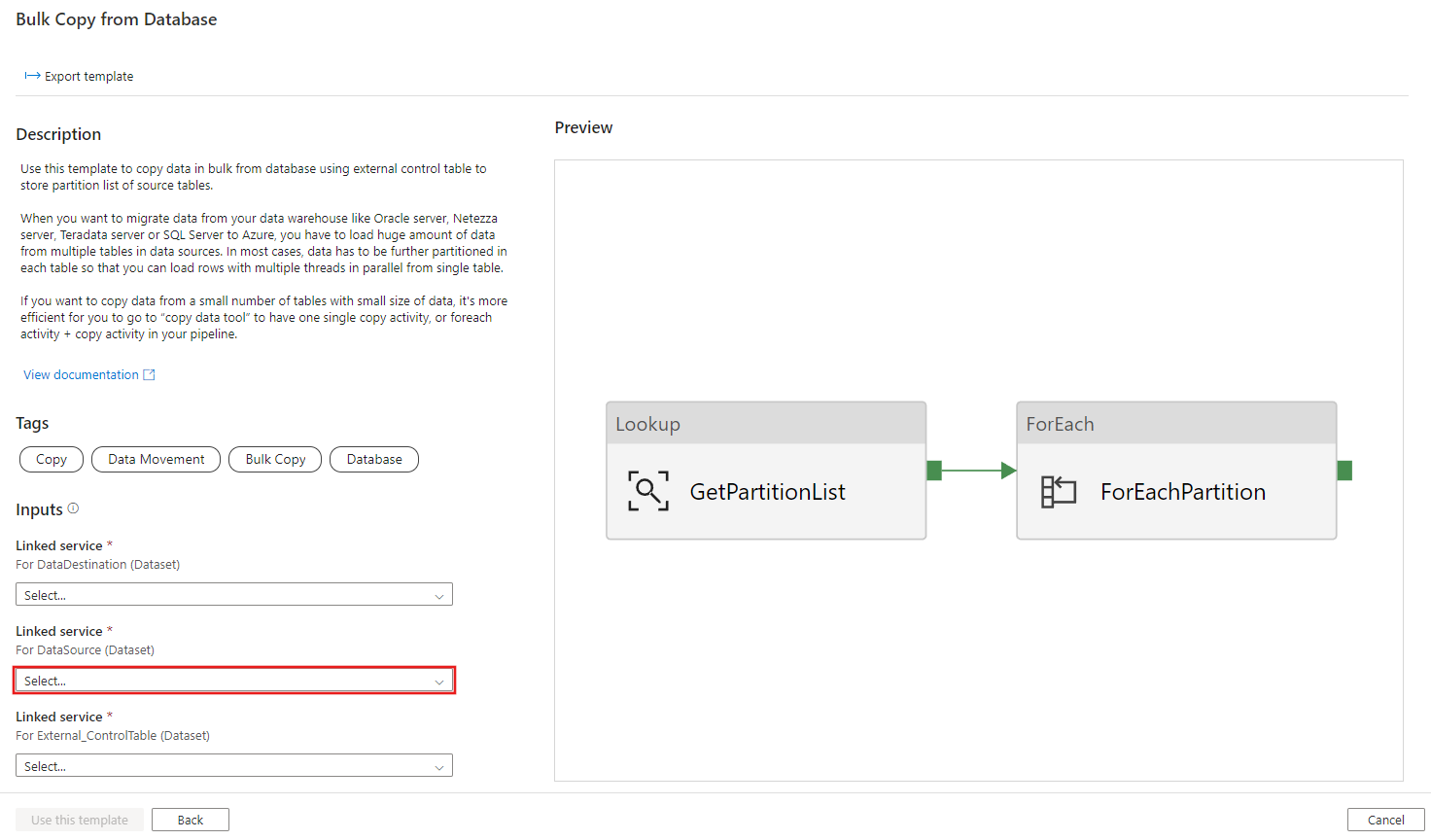
Stellen Sie eine neue Verbindung mit dem Zieldatenspeicher her, in den Sie Daten kopieren.
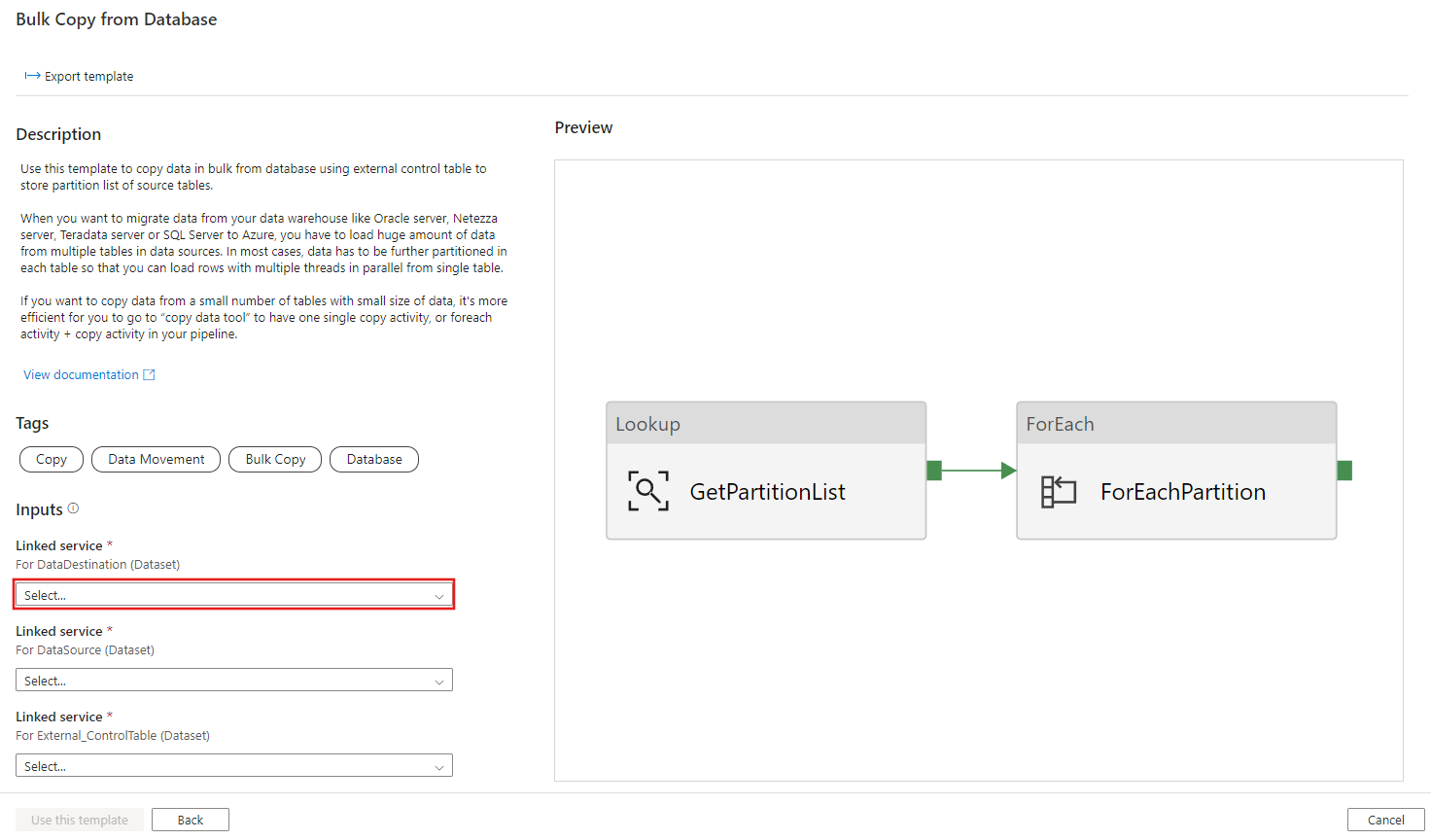
Klicken Sie auf Diese Vorlage verwenden.
Daraufhin wird die Pipeline wie im folgenden Beispiel angezeigt:
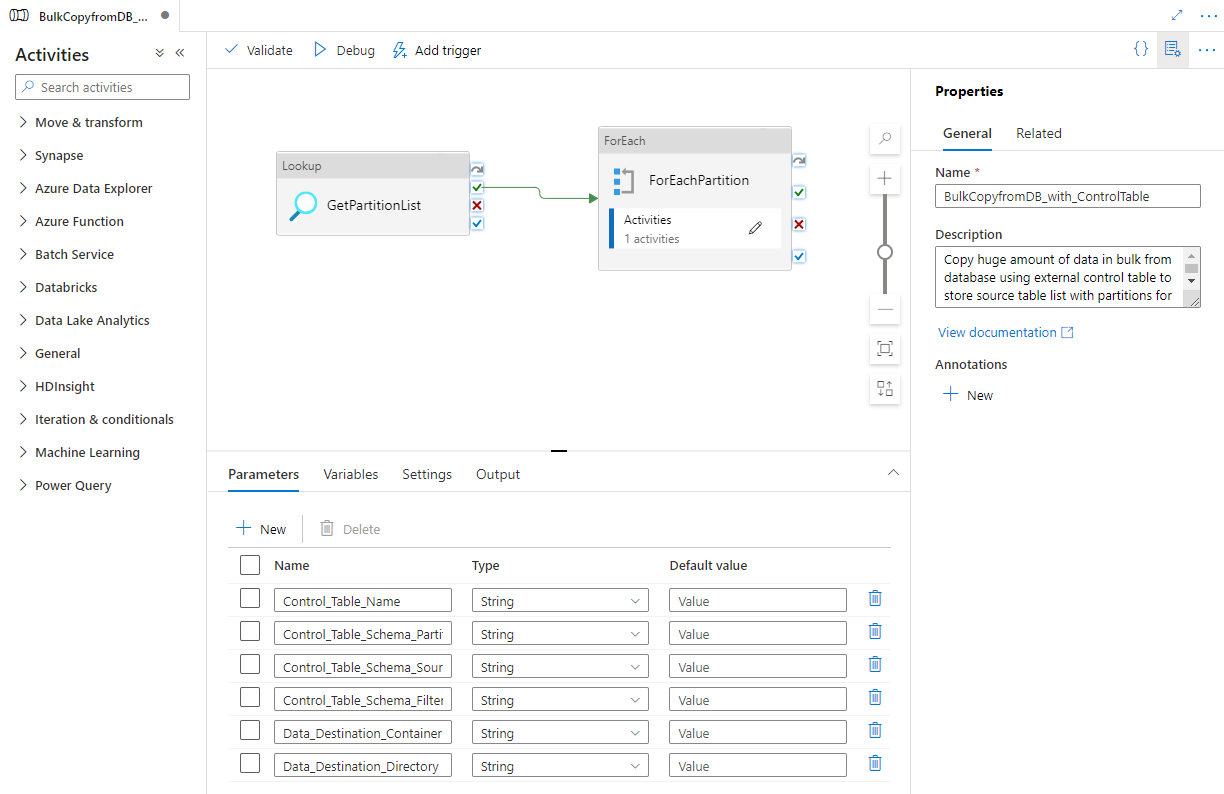
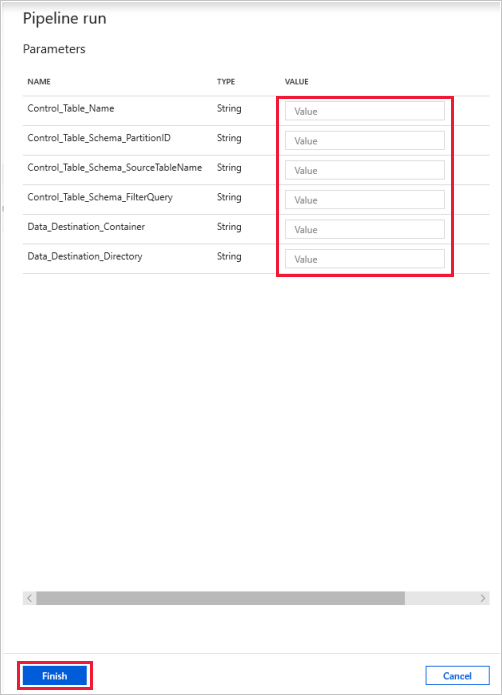
Klicken Sie auf Debuggen, geben Sie die Parameter ein, und klicken Sie dann auf Fertig stellen.
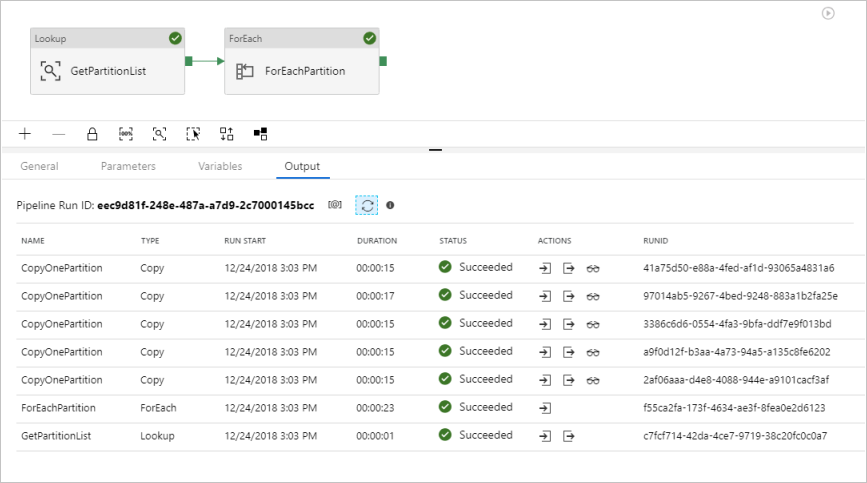
Ihnen werden Ergebnisse angezeigt, die dem folgenden Beispiel ähneln:
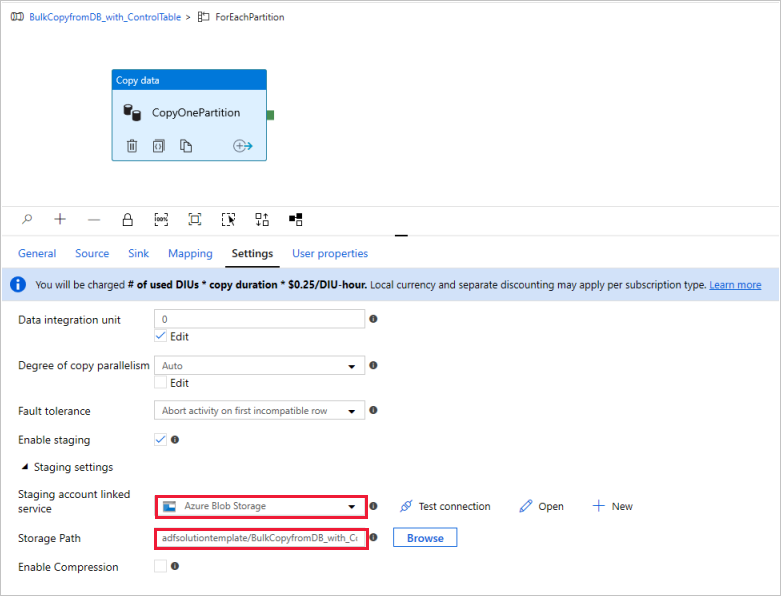
(Optional:) Wenn Sie „Azure Synapse Analytics“ als Datenziel auswählen, müssen Sie eine Verbindung mit Azure Blob Storage für den Stagingprozess eingeben, da dies für Azure Synapse Analytics PolyBase erforderlich ist. Die Vorlage generiert automatisch einen Containerpfad für Ihren Blob Storage. Überprüfen Sie nach der Pipelineausführung, ob der Container erstellt wurde.