Gemeinsame Nutzung von Funktionstabellen in verschiedenen Arbeitsbereichen (Legacy)
Wichtig
- Diese Dokumentation wurde eingestellt und wird unter Umständen nicht aktualisiert.
- Databricks empfiehlt die Verwendung des Feature Engineering in Unity Catalog, um Featuretabellen in mehreren Arbeitsbereichen gemeinsam nutzen zu können. Der Ansatz in diesem Artikel ist veraltet.
Azure Databricks unterstützt das Freigeben von Featuretabellen in mehreren Arbeitsbereichen. Beispielsweise können Sie aus Ihrem eigenen Arbeitsbereich eine Featuretabelle in einem zentralisierten Featurespeicher erstellen, in diese schreiben oder aus dieser lesen. Dies ist nützlich, wenn mehrere Teams gleichermaßen auf Featuretabellen zugreifen oder wenn Ihre Organisation über mehrere Arbeitsbereiche für verschiedene Entwicklungsstadien verfügt.
Für einen zentralisierten Featurespeicher empfiehlt Databricks, einen einzelnen Arbeitsbereich zum Speichern aller Metadaten festzulegen und Konten für alle Benutzer*innen zu erstellen, die Zugriff auf den Featurespeicher benötigen.
Wenn Ihre Teams auch Modelle arbeitsbereichsübergreifend freigeben, können Sie denselben zentralisierten Arbeitsbereich sowohl für Featuretabellen als auch für Modelle verwenden, oder Sie können jeweils unterschiedliche zentralisierte Arbeitsbereiche angeben.
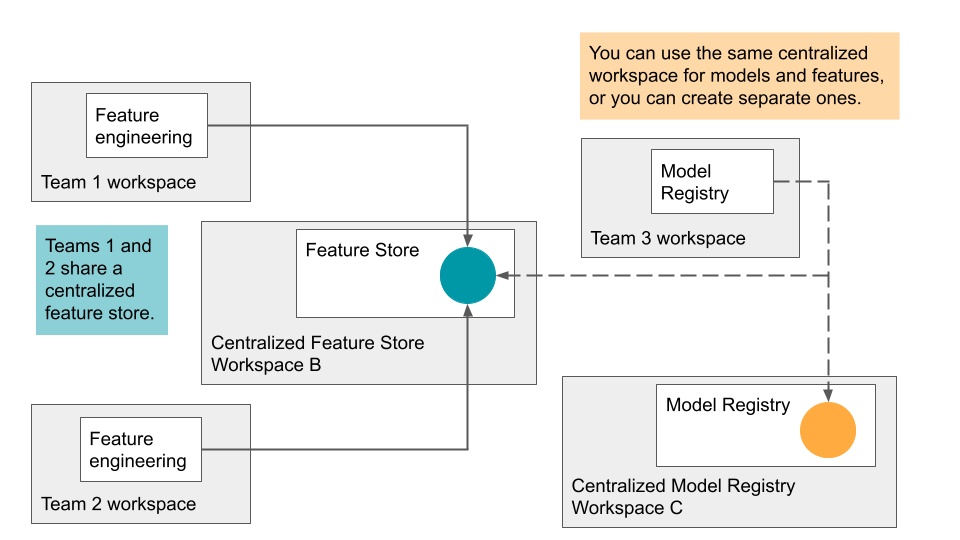
Der Zugriff auf den zentralisierten Featurespeicher wird durch Token gesteuert. Alle Benutzer*innen oder Skripts, die Zugriff benötigen, erstellen ein persönliches Zugriffstoken im zentralen Featurespeicher und kopieren dieses Token in den Geheimnis-Manager des lokalen Arbeitsbereichs. Jede API-Anforderung, die an den Arbeitsbereich des zentralisierten Featurespeichers gesendet wird, muss das Zugriffstoken enthalten. Der Featurespeicher-Client bietet einen einfachen Mechanismus zum Angeben von Geheimnissen, die bei arbeitsbereichsübergreifenden Vorgängen verwendet werden sollen.
Hinweis
Als bewährte Methode für die Sicherheit empfiehlt Databricks, dass Sie bei der Authentifizierung mit automatisierten Tools, Systemen, Skripten und Anwendungen persönliche Zugriffstoken verwenden, die zu Dienstprinzipalen und nicht zu Benutzern des Arbeitsbereichs gehören. Informationen zum Erstellen von Token für Dienstprinzipale finden Sie unter Verwalten von Token für einen Dienstprinzipal.
Anforderungen
Die arbeitsbereichsübergreifende Verwendung eines Featurespeichers erfordert Folgendes:
- Featurespeicherclient v0.3.6 und höher
- Beide Arbeitsbereiche müssen Zugriff auf die rohen Featuredaten haben. Sie müssen denselben externen Hive-Metastore nutzen und über Zugriff auf denselben DBFS-Speicher verfügen.
- Wenn IP-Zugriffslisten aktiviert sind, müssen sich die IP-Adressen des Arbeitsbereichs in Zugriffslisten befinden.
Einrichten des API-Tokens für eine Remoteregistrierung
In diesem Abschnitt bezieht sich „Arbeitsbereich B“ auf den Arbeitsbereich des zentralisierten Featurespeichers oder des Remotefeaturespeichers.
- Erstellen Sie ein Zugriffstoken im Arbeitsbereich B.
- Erstellen Sie Geheimnisse in Ihrem lokalen Arbeitsbereich, um das Zugriffstoken und Informationen zum Arbeitsbereich B zu speichern:
- Erstellen Sie einen Geheimnisbereich:
databricks secrets create-scope --scope <scope>. - Wählen Sie einen eindeutigen Bezeichner für den Arbeitsbereich B aus (hier angezeigt als
<prefix>). Erstellen Sie dann drei Geheimnisse mit den angegebenen Schlüsselnamen:databricks secrets put --scope <scope> --key <prefix>-host: Geben Sie den Hostnamen des Arbeitsbereichs B ein. Verwenden Sie die folgenden Python-Befehle, um den Hostnamen eines Arbeitsbereichs abzurufen:import mlflow host_url = mlflow.utils.databricks_utils.get_webapp_url() host_urldatabricks secrets put --scope <scope> --key <prefix>-token: Geben Sie das Zugriffstoken aus dem Arbeitsbereich B ein.databricks secrets put --scope <scope> --key <prefix>-workspace-id: Geben Sie die Arbeitsbereichs-ID für den Arbeitsbereich B ein. Diese finden Sie in der URL jeder beliebigen Seite.
- Erstellen Sie einen Geheimnisbereich:
Hinweis
Sie sollten den Geheimnisbereich für andere Benutzer freigeben, da die Anzahl der Geheimnisbereiche pro Arbeitsbereich beschränkt ist.
Angeben eines Remote-Featurespeichers
Sie können auf der Grundlage des Geheimnisbereichs und des Namenspräfixes, die Sie für den Arbeitsbereich des Remote-Featurespeichers erstellt haben, einen Featurespeicher-URI mit dem folgenden Format erstellen:
feature_store_uri = f'databricks://<scope>:<prefix>'
Geben Sie dann den URI explizit an, wenn Sie einen FeatureStoreClient instanziieren:
fs = FeatureStoreClient(feature_store_uri=feature_store_uri)
Erstellen einer Datenbank für Featuretabellen im freigegebenen DBFS-Speicherort
Bevor Sie Featuretabellen im Remotefeaturespeicher erstellen, müssen Sie eine Datenbank erstellen, um sie zu speichern. Die Datenbank muss am freigegebenen DBFS-Speicherort vorhanden sein.
Wenn Sie beispielsweise eine Datenbank recommender am freigegebenen Speicherort /mnt/sharederstellen möchten, verwenden Sie den folgenden Befehl:
%sql CREATE DATABASE IF NOT EXISTS recommender LOCATION '/mnt/shared'
Erstellen einer Featuretabelle im Remote-Featurespeicher
Die API zum Erstellen einer Featuretabelle in einem Remote-Featurespeicher hängt von der verwendeten Version von Databricks Runtime ab.
Version 0.3.6 und höher
Verwenden Sie die FeatureStoreClient.create_table-API:
fs = FeatureStoreClient(feature_store_uri=f'databricks://<scope>:<prefix>')
fs.create_table(
name='recommender.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer-keyed features'
)
Version 0.3.5 und niedriger
Verwenden Sie die FeatureStoreClient.create_feature_table-API:
fs = FeatureStoreClient(feature_store_uri=f'databricks://<scope>:<prefix>')
fs.create_feature_table(
name='recommender.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer-keyed features'
)
Beispiele für andere Feature Store-Methoden finden Sie unter Notebookbeispiel: Arbeitsbereichsübergreifendes Freigeben von Featuretabellen.
Verwenden einer Featuretabelle aus dem Remote-Featurespeicher
Sie können eine Featuretabelle im Remote-Featurespeicher mit der FeatureStoreClient.read_table-Methode lesen, indem Sie zu erst den feature_store_uri festlegen:
fs = FeatureStoreClient(feature_store_uri=f'databricks://<scope>:<prefix>')
customer_features_df = fs.read_table(
name='recommender.customer_features',
)
Andere Hilfsmethoden für den Zugriff auf die Featuretabelle werden ebenfalls unterstützt:
fs.read_table()
fs.get_feature_table() # in v0.3.5 and below
fs.get_table() # in v0.3.6 and above
fs.write_table()
fs.publish_table()
fs.create_training_set()
Verwenden eine Remote-Modellregistrierung
Zusätzlich zur Angabe eines URI des Remote-Featurespeichers können Sie auch einen URI der Remote-Modellregistrierung angeben, um Modelle arbeitsbereichsübergreifend freizugeben.
Wenn Sie eine Remote-Modellregistrierung zur Modellprotokollierung oder -bewertung angeben möchten, können Sie einen Modellregistrierungs-URI verwenden, um einen „FeatureStoreClient“ zu instanziieren.
fs = FeatureStoreClient(model_registry_uri=f'databricks://<scope>:<prefix>')
customer_features_df = fs.log_model(
model,
"recommendation_model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="recommendation_model"
)
Mit feature_store_uri und model_registry_uri können Sie ein Modell mithilfe einer beliebigen lokalen Featuretabelle oder Remote-Featuretabelle trainieren und dann das Modell in einer beliebigen lokalen Modellregistrierung oder Remote-Modellregistrierung registrieren.
fs = FeatureStoreClient(
feature_store_uri=f'databricks://<scope>:<prefix>',
model_registry_uri=f'databricks://<scope>:<prefix>'
)
Notebookbeispiel: Arbeitsbereichsübergreifendes Freigeben von Featuretabellen
Das folgende Notebook zeigt, wie Sie mit einem zentralisierten Featurespeicher arbeiten.