Computemetriken anzeigen
In diesem Artikel wird erläutert, wie Sie das native Computemetriktool auf der Azure Databricks-Benutzeroberfläche verwenden, um wichtige Hardware- und Spark-Metriken zu sammeln. Die Metrikbenutzeroberfläche ist für Mehrzweck- und Auftrags-Compute verfügbar.
Hinweis
Serverloses Computing für Notebooks und Workflows verwendet Abfrageerkenntnisse anstelle der Metrikbenutzeroberfläche. Weitere Informationen zu Metriken beim serverlosen Computing finden Sie unter Anzeigen von Abfrageerkenntnissen.
Metriken sind in nahezu Echtzeit mit einer üblichen Verzögerung von weniger als einer Minute verfügbar. Die Metriken werden in dem von Azure Databricks verwalteten Speicher gespeichert, nicht im Speicher des Kunden.
Inwiefern unterscheiden sich diese neuen Metriken von Ganglia?
Die neue Benutzeroberfläche für Computemetriken bietet einen umfassenderen Überblick über die Ressourcennutzung Ihres Clusters, einschließlich Spark-Nutzung und interner Databricks-Prozesse. Im Gegensatz dazu misst die Ganglia-Benutzeroberfläche nur die Spark-Containernutzung. Dieser Unterschied kann zu Abweichungen bei den Metrikwerten zwischen den beiden Oberflächen führen.
Zugreifen auf die Benutzeroberfläche für Computemetriken
So zeigen Sie die Benutzeroberfläche für Computemetriken an:
- Klicken Sie in der Randleiste auf Compute.
- Klicken Sie auf die Computeressource, für die Sie Metriken anzeigen möchten.
- Klicken Sie auf die Registerkarte Metriken.
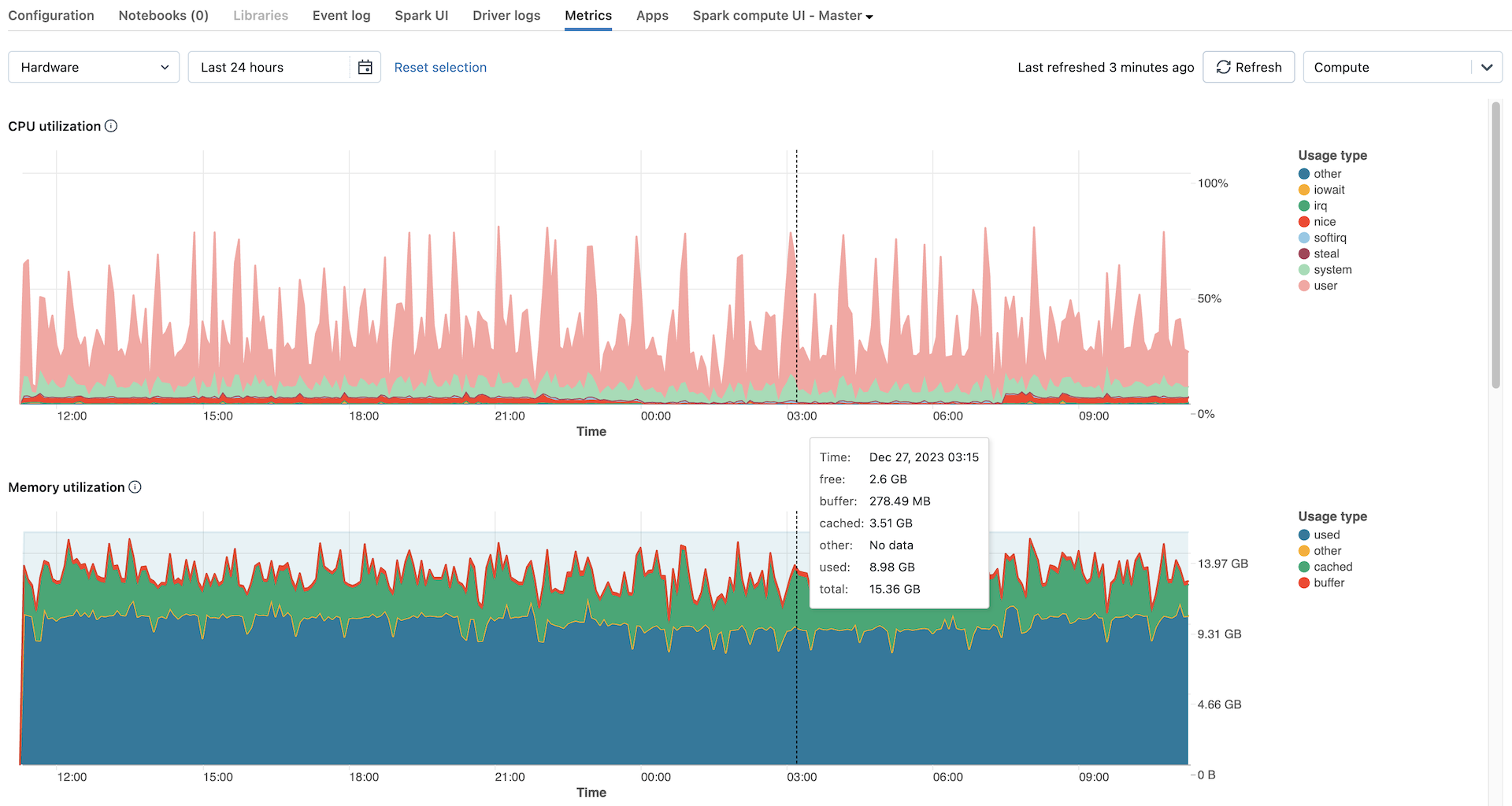
Hardwaremetriken werden standardmäßig angezeigt. Klicken Sie zum Anzeigen von Spark-Metriken auf das Dropdownmenü Hardware, und wählen Sie Spark aus. Sie können auch GPU auswählen, wenn die Instanz GPU-fähig ist.
Filtern von Metriken nach Zeitraum
Sie können Verlaufsmetriken anzeigen, indem Sie mithilfe des Datumsauswahlfilters einen Zeitbereich auswählen. Die Metriken werden jede Minute erfasst, sodass Sie nach einem beliebigen Tages-, Stunden- oder Minutenbereich der letzten 30 Tage filtern können. Klicken Sie auf das Kalendersymbol, um vordefinierte Datenbereiche auszuwählen, oder klicken Sie in das Textfeld, um benutzerdefinierte Werte zu definieren.
Hinweis
Die in den Diagrammen angezeigten Zeitintervalle werden basierend auf der angezeigten Zeitdauer angepasst. Die meisten Metriken sind Durchschnittswerte, die auf dem Zeitintervall basieren, das Sie derzeit anzeigen.
Sie können auch die neuesten Metriken abrufen, indem Sie auf die Schaltfläche Aktualisieren klicken.
Anzeigen von Metriken auf Knotenebene
Sie können Metriken für einzelne Knoten anzeigen, indem Sie auf das Dropdownmenü Compute klicken und den Knoten auswählen, für den Sie Metriken anzeigen möchten. GPU-Metriken sind nur auf Einzelknotenebene verfügbar. Spark-Metriken sind für einzelne Knoten nicht verfügbar.
Hinweis
Wenn Sie keinen bestimmten Knoten auswählen, ist das Ergebnis der Mittelwert aller Knoten innerhalb eines Clusters (einschließlich des Treibers).
Hardwaremetrikdiagramme
Folgende Hardwaremetrikdiagramme können auf der Benutzeroberfläche für Computemetriken angezeigt werden:
- Serverlastverteilung: Diesem Diagramm zeigt die CPU-Auslastung der letzten Minute für jeden Knoten.
- CPU-Auslastung: der Prozentsatz der Zeit, die die CPU in jedem Modus aufgewendet hat, basierend auf den Gesamtkosten für CPU-Sekunden. Die Metrik wird basierend auf dem im Diagramm angezeigten Zeitintervall gemittelt. Die folgenden Modi werden nachverfolgt:
- guest: Bei Ausführung von VMs die von diesen VMs verwendete CPU
- iowait: Zeit für das Warten auf E/A
- idle: Zeit, in der die CPU nichts zu tun hatte
- irq: Die für Unterbrechungsanforderungen aufgewendete Zeit
- nice: Die Zeit, die von Prozessen mit einer positiven Genauigkeit (d. h. einer niedrigeren Priorität als andere Aufgaben) aufgewendet wurde
- softirq: Die für Softwareunterbrechungsanforderungen aufgewendete Zeit
- steal: Im Fall einer VM die Zeit, die andere VMs von den CPUs „gestohlen“ haben
- system: Die im Kernel aufgewendete Zeit
- user: Die in der Benutzerumgebung aufgewendete Zeit
- Arbeitsspeicherauslastung: Die Gesamtarbeitsspeicherauslastung durch jeden Modus, gemessen in Bytes und gemittelt über das im Diagramm angezeigte Zeitintervall Die folgenden Verwendungstypen werden nachverfolgt:
- verwendet: Verwendeter Arbeitsspeicher (einschließlich des Arbeitsspeichers, der von Hintergrundprozessen verwendet wird, die auf einem Compute ausgeführt werden)
- free: Nicht verwendeter Arbeitsspeicher
- buffer: Von Kernelpuffern verwendeter Speicher
- cached: Vom Dateisystemcache auf Betriebssystemebene verwendeter Arbeitsspeicher
- Arbeitsspeicheraustausch-Auslastung: Die Gesamtarbeitsspeicheraustausch-Auslastung durch jeden Modus, gemessen in Bytes und gemittelt über das im Diagramm angezeigte Zeitintervall
- Freier Dateisystem-Speicherplatz: Die Gesamtauslastung des Dateisystems für jeden Bereitstellungspunkt, gemessen in Bytes und gemittelt über das im Diagramm angezeigte Zeitintervall
- Über das Netzwerk empfangen: Die Anzahl der von jedem Gerät über das Netz empfangenen Bytes, gemittelt über das im Diagramm angezeigte Zeitintervall
- Über das Netzwerk übertragen: Die Anzahl der von jedem Gerät über das Netz übertragenen Bytes, gemittelt über das im Diagramm angezeigte Zeitintervall
- Anzahl der aktiven Knoten: Hier wird die Anzahl der aktiven Knoten zu jedem Zeitstempel für das angegebene Compute angezeigt.
Spark-Metrikdiagramme
Die folgenden Spark-Metrikdiagramme können auf der Benutzeroberfläche für Computemetriken angezeigt werden:
- Serverlastverteilung: Diesem Diagramm zeigt die CPU-Auslastung der letzten Minute für jeden Knoten.
- Aktive Aufgaben: Die Gesamtzahl der Aufgaben, die zu einem bestimmten Zeitpunkt ausgeführt werden, gemittelt über das im Diagramm angezeigte Zeitintervall
- Gesamtzahl der fehlgeschlagenen Aufgaben: Die Gesamtzahl der fehlgeschlagenen Aufgaben in Executors, gemittelt über das im Diagramm angezeigte Zeitintervall
- Gesamtzahl der abgeschlossenen Aufgaben: Die Gesamtzahl der abgeschlossenen Aufgaben in Executors, gemittelt über das im Diagramm angezeigte Zeitintervall
- Gesamtzahl der Aufgaben: Die Gesamtzahl aller Aufgaben (ausgeführt, fehlgeschlagen und abgeschlossen) in Executors, gemittelt über das im Diagramm angezeigte Zeitintervall
- Shufflelesedaten gesamt: Die Gesamtgröße der Shufflelesedaten, gemessen in Bytes und gemittelt über das im Diagramm angezeigte Zeitintervall
Shuffle readist die Summe der serialisierten Lesedaten auf allen Executors am Anfang einer Phase. - Shuffleschreibdaten gesamt: Die Gesamtgröße der Shuffleschreibdaten, gemessen in Bytes und gemittelt über das im Diagramm angezeigte Zeitintervall.
Shuffle Writeist die Summe aller geschriebenen serialisierten Daten auf allen Executors vor der Übertragung (normalerweise am Ende einer Phase). - Gesamtdauer der Aufgabe: Die gesamte verstrichene Zeit, die die JVM mit der Ausführung von Aufgaben auf Executors verbracht hat, gemessen in Sekunden und gemittelt über das im Diagramm angezeigte Zeitintervall
GPU-Metrikdiagramme
Die folgenden GPU-Metrikdiagramme können auf der Benutzeroberfläche für Computemetriken angezeigt werden:
- Serverlastverteilung: Diesem Diagramm zeigt die CPU-Auslastung der letzten Minute für jeden Knoten.
- Decoderauslastung pro GPU: Der prozentuale Anteil der GPU-Decoderauslastung, gemittelt über das im Diagramm angezeigte Zeitintervall
- Encoderauslastung pro GPU: Der prozentuale Anteil der GPU-Encoderauslastung, gemittelt über das im Diagramm angezeigte Zeitintervall
- Auslastung des Framepufferspeichers pro GPU in Bytes: Die Framepuffer-Speicherauslastung, gemessen in Bytes und gemittelt über das im Diagramm angezeigte Zeitintervall
- Arbeitsspeicherauslastung pro GPU: Der prozentuale Anteil der Arbeitsspeicherauslastung, gemittelt über das im Diagramm angezeigte Zeitintervall
- Auslastung pro GPU: Der prozentuale Anteil der GPU-Auslastung, gemittelt über das im Diagramm angezeigte Zeitintervall
Problembehandlung
Wenn für einen Zeitraum unvollständige oder fehlende Metriken angezeigt werden, kann dies eines der folgenden Probleme sein:
- Ein Ausfall im Databricks-Dienst, der für das Abfragen und Speichern von Metriken verantwortlich ist.
- Netzwerkprobleme auf kundenseitiger Seite.
- Das Compute befindet sich oder war in einem fehlerhaften Zustand.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für