Herstellen einer Verbindung mit Pools
Hinweis
Wenn Ihre Workload serverloses Computing unterstützt, empfiehlt Databricks die Verwendung von serverlosem Computing anstelle von Pools, um immer aktivierte, skalierbare Compute zu nutzen. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit serverlosem Compute.
Azure Databricks-Pools sind einsatzbereite Instanzen im Leerlauf. Wenn Clusterknoten mithilfe der sich im Leerlauf befindenden Instanzen erstellt werden, werden die Start- und Autoskalierungszeiten des Clusters reduziert. Wenn der Pool keine Leerlaufinstanzen enthält, wird er erweitert, indem eine neue Instanz vom Instanzenanbieter zugeordnet wird, um die Anforderung des Clusters zu erfüllen.
Wenn ein Cluster eine Instanz freigibt, wird sie an den Pool zurückgegeben und kann von einem anderen Cluster verwendet werden. Nur an einen Pool angefügte Cluster können die Leerlaufinstanzen dieses Pools verwenden.
Solange sich Instanzen im Pool im Leerlauf befinden, werden in Azure Databricks keine DBU-Stunden berechnet. Abrechnung des Instanzenanbieters gilt. Siehe Preise.
Sie können Pools mithilfe der Benutzeroberfläche verwalten oder die Instanzpool-API aufrufen.
Erstellen eines Pools
Um einen Pool zu erstellen, müssen Sie über die Berechtigung zum Erstellen von Pools verfügen. Standardmäßig verfügen nur Arbeitsbereichsadministratoren über Poolerstellungsberechtigungen.
So erstellen Sie einen Pool über die Benutzeroberfläche
- Klicken Sie auf der Seitenleiste auf
 Compute.
Compute. - Klicken Sie auf die Registerkarte Pools.
- Klicken Sie auf die Schaltfläche Pool erstellen.
- Geben Sie die Poolkonfiguration an.
- Klicken Sie auf die Schaltfläche Erstellen .
Anfügen eines Clusters an einen Pool
Wenn Sie einen Cluster über die Benutzeroberfläche für die Clustererstellung an einen Pool anfügen möchten, wählen Sie beim Konfigurieren des Clusters den Pool in der Dropdownliste Treibertyp oder Workertyp aus. Verfügbare Pools werden oben in jeder Dropdownliste aufgeführt. Sie können denselben Pool oder verschiedene Pools für den Treiberknoten und die Workerknoten verwenden.
Wenn Sie die Cluster-API verwenden, müssen Sie driver_instance_pool_id für den Treiberknoten und instance_pool_id für die Workerknoten angeben.
Weitere bewährte Methoden für Pools finden Sie unter Bewährte Methoden für Pools.
Poolberechtigungen
Es gibt drei Berechtigungsstufen für einen Pool: KEINE BERECHTIGUNGEN, KANN ANFÜGEN AN und KANN VERWALTEN. Weitere Informationen finden Sie unter Zugriffssteuerungslisten für Pools.
Konfigurieren von Poolberechtigungen
In diesem Abschnitt wird beschrieben, wie Sie Berechtigungen über die Benutzeroberfläche des Arbeitsbereichs verwalten. Sie können auch die Berechtigungs-API oder den Databricks-Terraform-Anbieter verwenden.
Sie benötigen die Berechtigung KANN VERWALTEN für einen Pool, um Berechtigungen zu konfigurieren.
Klicken Sie auf der Seitenleiste auf Compute.
Klicken Sie auf die Registerkarte Pools.
Wählen Sie den Pool aus, den Sie aktualisieren möchten.
Klicken Sie auf die Schaltfläche Berechtigungen.
Wählen Sie unter Berechtigungseinstellungen das Dropdownmenü Benutzer, Gruppe oder Dienstprinzipal auswählen… und dann einen*eine Benutzer*in, eine Gruppe oder einen Dienstprinzipal aus.
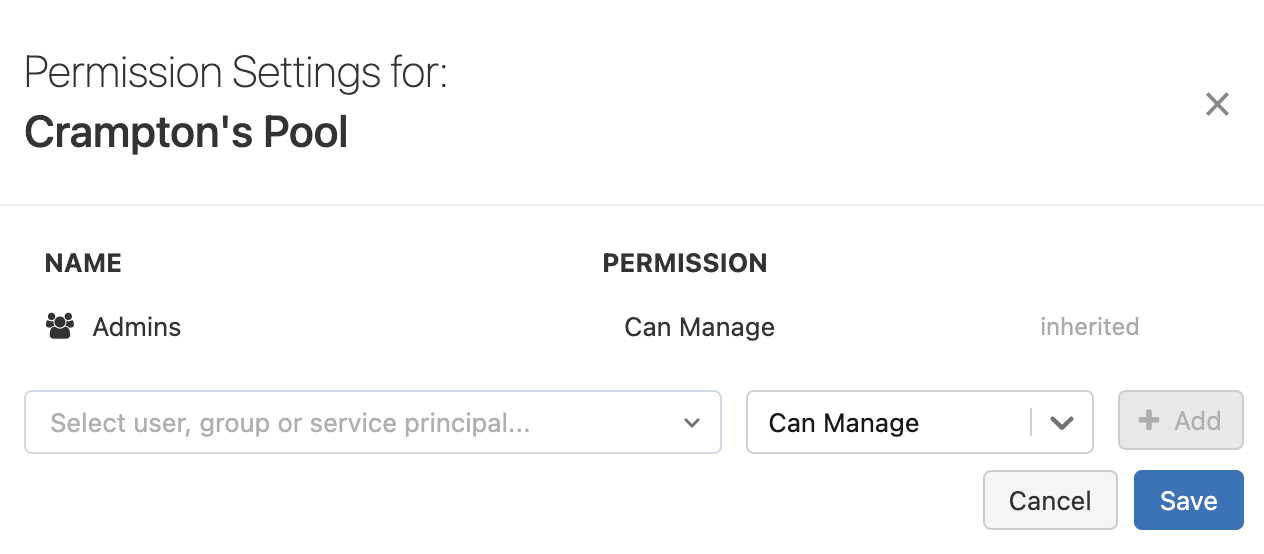
Wählen Sie im Dropdownmenü „Berechtigung“ eine Berechtigung aus.
Klicken Sie auf Hinzufügen und dann auf Speichern.
Löschen eines Pools
Durch das Löschen eines Pools werden dessen im Leerlauf befindliche Instanzen beendet und seine Konfiguration entfernt. Zum Löschen eines Pools klicken Sie auf das Symbol ![]() ihn den Aktionen auf der Seite „Pools“. Wenn Sie einen Pool löschen:
ihn den Aktionen auf der Seite „Pools“. Wenn Sie einen Pool löschen:
- An den Pool angefügte ausgeführte Cluster werden weiterhin ausgeführt, können aber während der Größenänderung oder Hochskalierung keine Instanzen zuordnen.
- An den Pool angefügte beendete Cluster können nicht gestartet werden.
Wichtig
Dieser Vorgang lässt sich nicht rückgängig machen.