Trainieren von ML-Modellen mit der Mosaik AutoML UI
In diesem Artikel wird veranschaulicht, wie Sie ein Machine Learning-Modell mithilfe von AutoML und der Databricks Mosaic KI-Benutzeroberfläche trainieren. Die AutoML-Benutzeroberfläche führt Sie schrittweise durch das Training eines Klassifizierungs-, Regressions- oder Vorhersagemodells für ein Dataset.
Weitere Informationen finden Sie unter Anforderungen für AutoML-Experimente.
Öffnen der Benutzeroberfläche für automatisiertes ML
So greifen Sie auf die Benutzeroberfläche für automatisiertes ML zu
Wählen Sie auf der Randleiste Neu > AutoML-Experiment aus.
Sie können auch ein neues AutoML-Experiment auf der Seite Experimente erstellen.
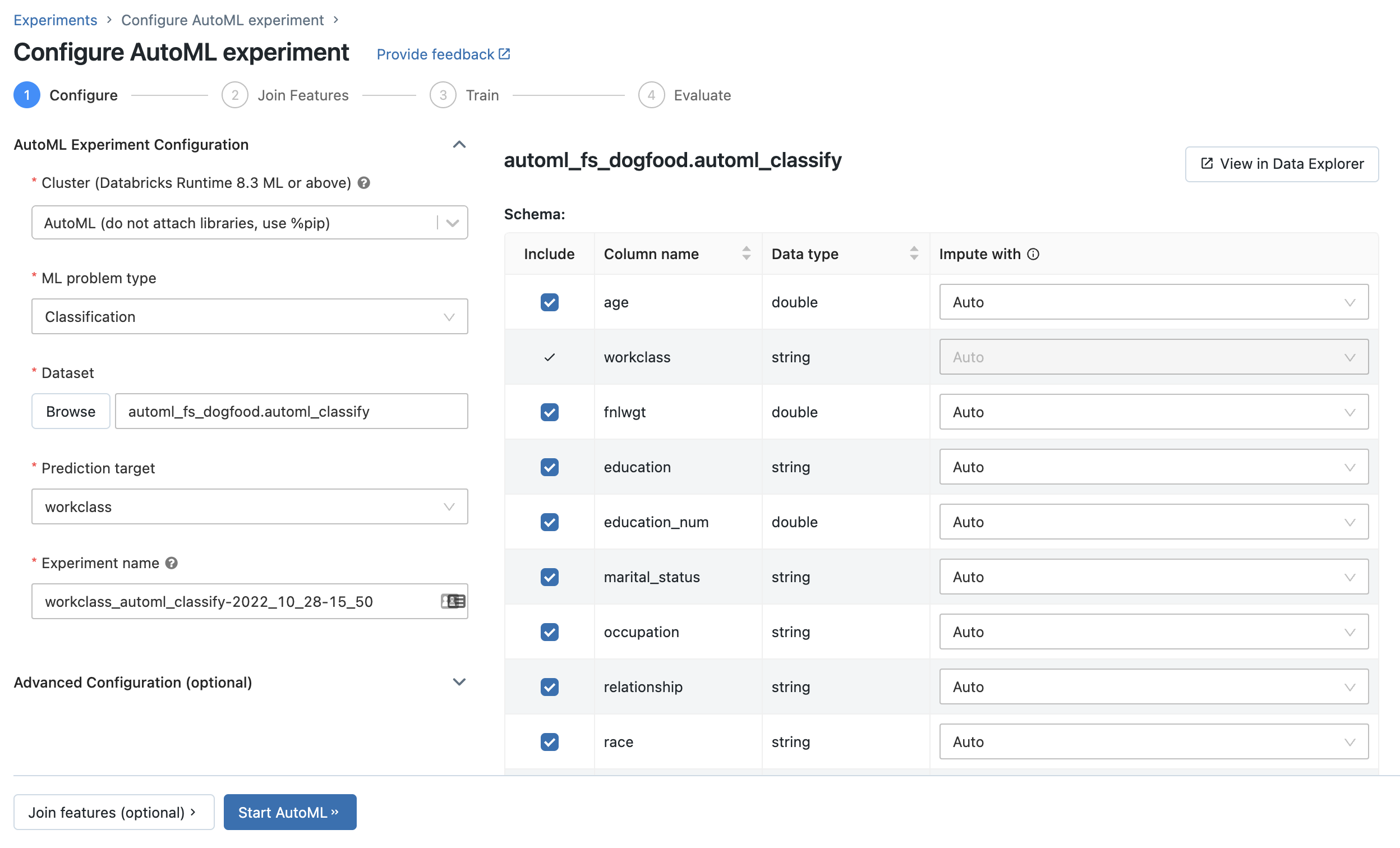
Die Seite AutoML-Experiment konfigurieren wird angezeigt. Auf dieser Seite konfigurieren Sie den AutoML-Prozess und geben die Spalten für Dataset, Problemtyp, Ziel oder Bezeichnung, die vorhergesagt werden sollen, die Metrik zum Auswerten und Bewerten der Experimentausführungen sowie die Bedingungen zum Beenden an.
Einrichten eines Klassifizierungs- oder Regressionsproblems
Sie können ein Klassifizierungs- oder Regressionsproblem in der AutoML-Benutzeroberfläche anhand der folgenden Schritte einrichten:
Wählen Sie im Feld Compute einen Cluster aus, auf dem Databricks Runtime ML ausgeführt wird.
Wählen Sie im Dropdownmenü ML-Problemtyp die Option Regression oder Klassifizierung aus. Wenn Sie versuchen, einen kontinuierlichen numerischen Wert für jede Beobachtung vorherzusagen, z. B. das jährliche Einkommen, wählen Sie „Regression“ aus. Wenn Sie versuchen, jede Beobachtung einer diskreten Menge von Klassen zuzuweisen, z. B. eine gute Kreditrisikobewertung oder eine schlechte Kreditrisikobewertung, wählen Sie die Klassifizierung aus.
Wählen Sie unter Dataset die Option Durchsuchen aus.
Navigieren Sie zu der Tabelle, die Sie verwenden möchten, und klicken Sie auf Auswählen. Das Tabellenschema wird angezeigt.
- In Databricks Runtime 10.3 ML und höher können Sie angeben, welche Spalten automatisiertes maschinelles Lernen für das Training verwenden soll. Sie können die Spalte, die Sie als Vorhersageziel oder als Zeitspalte zum Aufteilen der Daten ausgewählt wurde, nicht entfernen.
- In Databricks Runtime 10.4 LTS ML und höher können Sie angeben, wie NULL-Werte imputiert werden. Wählen Sie dazu eine Option aus dem Dropdownmenü Imputation mit aus. AutoML wählt als Standard eine Imputationsmethode auf der Grundlage des Spaltentyps und des Inhalts aus.
Hinweis
Wenn Sie eine nicht standardmäßige Imputationsmethode angeben, führt AutoML keine semantische Typerkennung durch.
Klicken Sie in das Feld Vorhersageziel. Eine Dropdownliste mit den im Schema angezeigten Spalten wird angezeigt. Wählen Sie die Spalte aus, die das Modell vorhersagen soll.
Im Feld Experimentname wird der Standardname angezeigt. Geben Sie den neuen Namen in das Feld ein, um ihn zu ändern.
Weitere Funktionen:
- Geben Sie zusätzlichen Konfigurationsoptionen an.
- Verwenden Sie vorhandene Featuretabellen im Feature-Store, um das ursprüngliche Eingabedataset zu erweitern.
Einrichten von Vorhersageproblemen
Sie können ein Vorhersageproblem in der AutoML-Benutzeroberfläche anhand der folgenden Schritte einrichten:
Wählen Sie im Feld Compute einen Cluster aus, auf dem Databricks Runtime 10.0 ML oder höher ausgeführt wird.
Wählen Sie im Dropdownmenü ML Problemtyp die Option Vorhersage aus.
Klicken Sie unter Dataset auf Durchsuchen. Navigieren Sie zu der Tabelle, die Sie verwenden möchten, und klicken Sie auf Auswählen. Das Tabellenschema wird angezeigt.
Klicken Sie in das Feld Vorhersageziel. Ein Dropdownmenü mit den im Schema angezeigten Spalten wird angezeigt. Wählen Sie die Spalte aus, die das Modell vorhersagen soll.
Klicken Sie in das Feld Zeitspalte. Eine Dropdown-Ansicht mit den Dataset-Spalten des Typs
timestampoderdatewird angezeigt. Wählen Sie die Spalte mit den Zeiträumen für die Zeitreihe aus.Wählen Sie für die Mehrreihen-Vorhersage die Spalten aus dem Dropdown Zeitreihenbezeichner aus, die die einzelnen Zeitreihen bezeichnen. AutoML gruppiert die Daten nach diesen Spalten als unterschiedliche Zeitreihen und trainiert ein Modell für jede Reihe unabhängig voneinander. Wenn Sie dieses Feld leer lassen, geht AutoML davon aus, dass das Dataset eine einzelne Zeitreihe enthält.
Geben Sie in den Feldern Vorhersagehorizont und Häufigkeit die Anzahl der Zeiträume in der Zukunft an, für die AutoML vorhergesagte Werte berechnen soll. Geben Sie im linken Feld die ganze Zahl der Zeiträume ein, die vorhergesagt werden sollen. Wählen Sie im rechten Feld die Einheiten aus.
Hinweis
Um Auto-ARIMA verwenden zu können, muss die Zeitreihe eine reguläre Häufigkeit haben, bei der das Intervall zwischen zwei beliebigen Punkten während der gesamten Zeitreihe identisch sein muss. Die Häufigkeit muss mit der im API-Aufruf oder in der AutoML-Benutzeroberfläche angegebenen Häufigkeitseinheit übereinstimmen. AutoML behandelt fehlende Zeitschritte, indem diese Werte mit dem vorherigen Wert aufgefüllt werden.
In Databricks Runtime 11.3 LTS ML und höher können Sie Vorhersageergebnisse speichern. Geben Sie dazu eine Datenbank im Feld Ausgabedatenbank an. Klicken Sie auf Durchsuchen, und wählen Sie im Dialogfeld eine Datenbank aus. AutoML schreibt die Vorhersageergebnisse in eine Tabelle in dieser Datenbank.
Im Feld Experimentname wird der Standardname angezeigt. Geben Sie den neuen Namen in das Feld ein, um ihn zu ändern.
Weitere Funktionen:
- Geben Sie zusätzlichen Konfigurationsoptionen an.
- Verwenden Sie vorhandene Featuretabellen im Feature-Store, um das ursprüngliche Eingabedataset zu erweitern.
Verwenden vorhandener Featuretabellen aus dem Databricks-Featurespeicher
In Databricks Runtime 11.3 LTS ML und höher können Sie Featuretabellen im Databricks-Feature-Store verwenden, um das Eingabetrainingsdataset für Ihre Klassifizierungs- und Regressionsprobleme zu erweitern.
In Databricks Runtime 12.2 LTS ML und höher können Sie Featuretabellen im Feature Store von Databricks verwenden, um das Eingabetrainingsdataset für alle Ihre Probleme für automatisiertes ML zu erweitern: Klassifizierung, Regression und Vorhersage.
Informationen zum Erstellen einer Featuretabelle finden Sie unter Create a feature table in Unity Catalog bzw. Create a feature table in Databricks Feature Store.
Nachdem Sie das Experiment für automatisiertes ML konfiguriert haben, können Sie anhand der folgenden Schritte eine Featuretabelle auswählen:
Klicken Sie auf Features verknüpfen (optional).
Wählen Sie auf der Seite Zusätzliche Features verknüpfen im Feld Featuretabelle eine Featuretabelle aus.
Wählen Sie für jeden Primärschlüssel der Featuretabelle den entsprechenden Nachschlageschlüssel aus. Der Nachschlageschlüssel sollte eine Spalte in dem Trainingsdataset sein, das Sie für Ihr AutoML-Experiment bereitgestellt haben.
Wählen Sie für Zeitreihen-Featuretabellen den entsprechenden Zeitstempel-Nachschlageschlüssel aus. Der Zeitstempel-Nachschlageschlüssel sollte in ähnlicher Weise eine Spalte in dem Trainingsdataset sein, das Sie für Ihr AutoML-Experiment bereitgestellt haben.
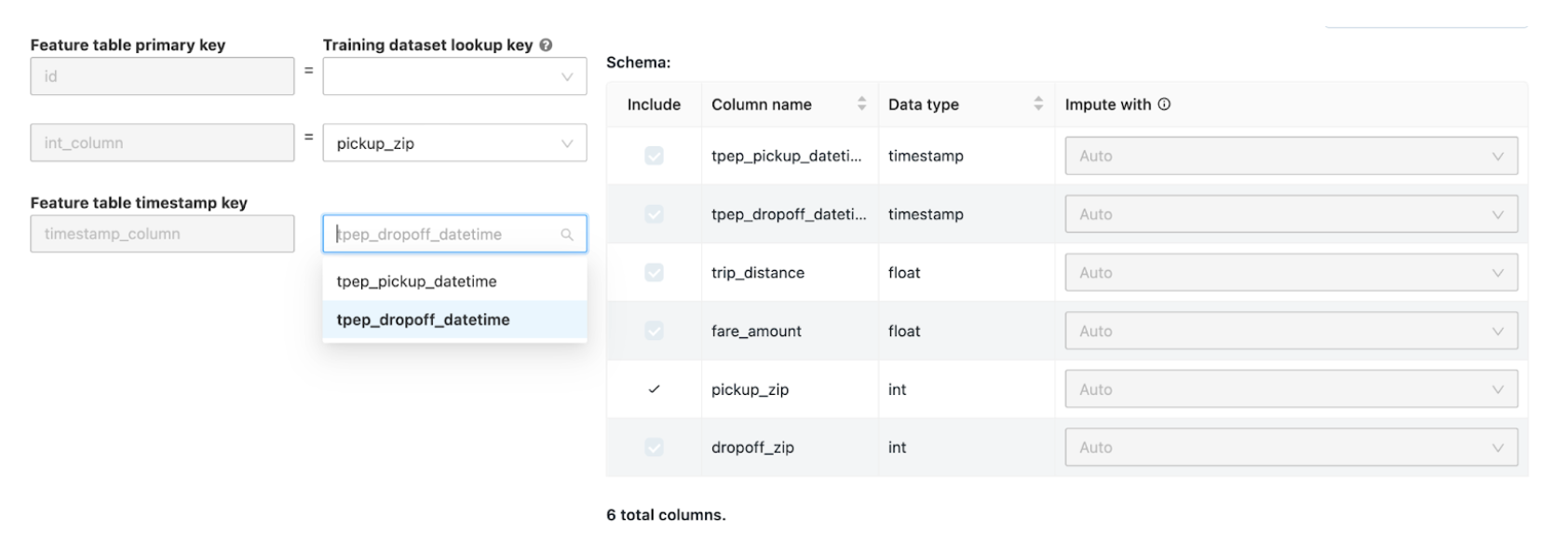
Um weitere Featuretabellen hinzuzufügen, klicken Sie auf Weitere Tabelle hinzufügen, und wiederholen Sie die oben genannten Schritte.
Erweiterte Konfigurationen
Öffnen Sie den Abschnitt Erweiterte Konfiguration (optional), um auf diese Parameter zuzugreifen.
- Die Auswertungsmetrik ist die primäre Metrik, die zum Bewerten der Ausführungen verwendet wird.
- In Databricks Runtime 10.4 LTS ML und höher können Sie Trainings-Frameworks von der Berücksichtigung ausschließen. AutoML trainiert standardmäßig Modelle mithilfe von Frameworks, die unter AutoML-Algorithmen aufgeführt sind.
- Sie können die Bedingungen zum Beenden bearbeiten. Standardmäßige Bedingungen zum Beenden sind:
- Bei Vorhersageexperimenten nach 120 Minuten beenden.
- In Databricks Runtime 10.4 LTS ML und unterhalb werden Klassifizierungs- und Regressionsexperimenten nach 60 Minuten oder nach Abschluss von 200 Testversionen beendet, je nachdem, was früher geschieht. Für Databricks-Runtime 11.0 ML und höher wird die Anzahl der Testversionen nicht als Stoppbedingung verwendet.
- Databricks Runtime 10.4 LTS ML und höher beinhaltet AutoML frühes Beenden für Klassifizierungs- und Regressionsexperimente. Es beendet das Training und die Optimierung von Modellen, wenn sich die Validierungsmetrik nicht weiter verbessert.
- In Databricks Runtime 10.4 LTS ML und höher können Sie eine Zeitspalte auswählen, um die Daten für Training, Validierung und Tests in chronologischer Reihenfolge aufzuteilen (gilt nur für Klassifizierung und Regression).
- Databricks empfiehlt, das Feld Datenverzeichnis nicht aufzufüllen. Wenn Sie es auffüllen, wird das Standardverhalten ausgelöst, bei dem das Dataset sicher als MLflow-Artefakt gespeichert wird. Ein DBFS-Pfad kann angegeben werden, in diesem Fall erbt das Dataset jedoch nicht die Zugriffsberechtigungen des AutoML-Experiments.
Ausführen des Experiments und Überwachen der Ergebnisse
Klicken Sie auf AutoML starten, um das AutoML-Experiment zu starten. Das Experiment beginnt mit der Ausführung, und die AutoML-Trainingsseite wird angezeigt. Klicken Sie auf  , um die Liste zu aktualisieren.
, um die Liste zu aktualisieren.
Auf der Seite haben Sie folgende Möglichkeiten:
- Beenden Sie das Experiment jederzeit.
- Öffnen Sie das Notebook für das Durchsuchen von Daten.
- Überwachen Sie Ausführungen.
- Navigieren Sie für jede Ausführung zur Ausführungsseite.
Bei Databricks Runtime 10.1 ML und höher zeigt AutoML Warnungen für potenzielle Probleme mit dem Dataset an, z. B. nicht unterstützte Spaltentypen oder Spalten mit hoher Kardinalität.
Hinweis
Databricks versucht, potenzielle Fehler oder Probleme anzuzeigen. Dies ist jedoch möglicherweise nicht umfassend und erfasst möglicherweise nicht die Probleme oder Fehler, nach denen Sie suchen.
Um Warnungen für das Dataset anzuzeigen, klicken Sie auf der Trainingsseite oder nach Abschluss des Experiments auf der Experimentseite auf die Registerkarte Warnungen.
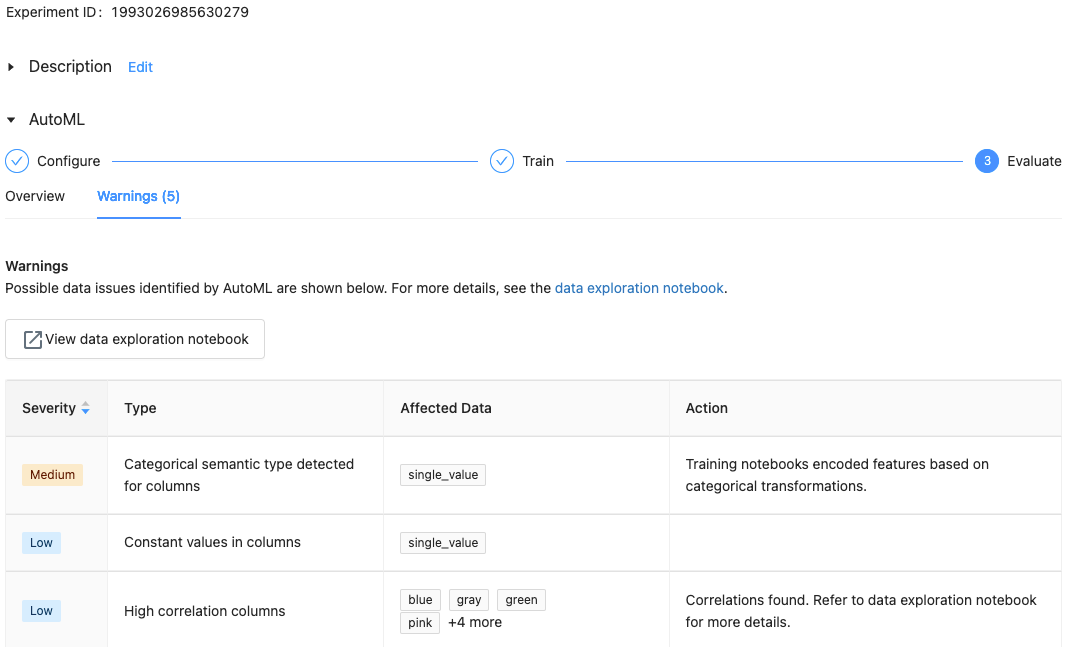
Nach Abschluss des Experiments haben Sie folgende Möglichkeiten:
- Registrieren Sie eines der Modelle und stellen Sie es mit MLflow bereit.
- Wählen Sie Notebook für das beste Modell anzeigen aus, um das Notebook, das das beste Modell erstellt hat, zu überprüfen und zu bearbeiten.
- Wählen Sie Notebook für das Durchsuchen von Daten anzeigen aus, um das Notebook für die Datenuntersuchung zu öffnen.
- Suchen, filtern und sortieren Sie die Ausführungen in der Tabelle „Ausführungen“.
- Details zu jeder Ausführung finden Sie hier:
- Sie können das generierte Notebook mit dem Quellcode für eine Testausführung anzeigen, indem Sie in die MLflow-Ausführung klicken. Das Notebook ist im Abschnitt Artifacts (Artefakte) der Ausführungsseite gespeichert. Sie können dieses Notebook herunterladen und in den Arbeitsbereich importieren, wenn das Herunterladen von Artefakten von Ihren Arbeitsbereichsadministratoren aktiviert wurde.
- Klicken Sie auf die Spalte Modelle oder die Spalte Startzeit, um die Ausführungsergebnisse anzuzeigen. Die Ausführungsseite wird angezeigt und enthält Informationen über den Testlauf (z. B. Parameter, Metriken und Tags) sowie die durch die Ausführung erstellten Artefakte, einschließlich des Modells. Diese Seite enthält auch Codeausschnitte, die Sie verwenden können, um mit dem Modell Vorhersagen zu machen.
Um später zu diesem AutoML-Experiment zurückzukehren, finden Sie es in der Tabelle auf der Experimente-Seite. Die Ergebnisse der einzelnen AutoML-Experimente, einschließlich der Notebooks für Datenuntersuchungen und Trainings, werden in dem Order databricks_automl im Home-Ordner des Benutzers gespeichert, der das Experiment ausgeführt hat.
Registrieren und Bereitstellen eines Modells
Sie können Ihr Modell mit der AutoML-Benutzeroberfläche registrieren und bereitstellen:
- Klicken Sie auf den Link in der Spalte Modelle, damit das Modell registriert werden kann. Wenn eine Ausführung abgeschlossen ist, enthält die oberste Zeile das beste Modell (basierend auf der primären Metrik).
- Wählen Sie die
 aus, um das Modell in der Modellregistrierung zu registrieren.
aus, um das Modell in der Modellregistrierung zu registrieren. - Wählen Sie auf der Randleiste
 Modelle aus, um zu der Modellregistrierung zu navigieren.
Modelle aus, um zu der Modellregistrierung zu navigieren. - Klicken Sie in der Modelltabelle auf den Namen Ihres Modells.
- Auf der Seite mit den registrierten Modellen können Sie das Modell mit Modellbereitstellung bereitstellen.
Kein Modul mit dem Namen „pandas.core.indexes.numeric
Wenn Sie ein Modell bereitstellen, das mithilfe von automatisiertem ML mit Model Serving erstellt wurde, erhalten Sie möglicherweise den Fehler: No module named 'pandas.core.indexes.numeric.
Dies ist auf eine inkompatible pandas-Version zwischen automatisiertes ML und der Endpunktumgebung der Modellbereitstellung zurückzuführen. Sie können diesen Fehler beheben, indem Sie das Skript „add-pandas-dependency.py“ ausführen. Das Skript bearbeitet die requirements.txt und conda.yaml für Ihr protokolliertes Modell so, dass die entsprechende pandas-Abhängigkeitsversion enthalten ist: pandas==1.5.3
- Ändern Sie das Skript so, dass es die
run_idder MLflow-Ausführung einschließt, in der Ihr Modell protokolliert wurde. - Erneutes Registrieren des Modells in der MLflow-Modellregistrierung.
- Versuchen Sie, die neue Version des MLflow-Modells bereitzustellen.