Feature Engineering und Bereitstellung
Diese Seite befasst sich mit Feature-Engineering- und Bereitstellungsfunktionen für Arbeitsbereiche, die für Unity Catalog aktiviert sind. Wenn Ihr Arbeitsbereich nicht für Unity Catalog aktiviert ist, lesen Sie Workspace Featurespeicher (Legacy).
Was spricht für die Verwendung von Databricks als Featurespeicher?
Mit der Databricks Data Intelligence Platform findet der gesamte Workflow des Modelltrainings auf einer einzigen Plattform statt:
- Datenpipelines, die Rohdaten aufnehmen, Featuretabellen erstellen, Modelle trainieren und Batch-Rückschlüsse durchführen. Wenn Sie ein Modell mit Feature Engineering in Unity Catalog trainieren und protokollieren, enthält das Modell Featuremetadaten. Wenn Sie das Modell für Batchbewertungen oder Onlinerückschlüsse verwenden, ruft es automatisch Featurewerte ab. Der Aufrufer muss diese nicht kennen oder eine Logik zum Suchen oder Verbinden von Features einfügen, um neue Daten zu bewerten.
- Modelle und Funktionen für Endpunkte, die mit einem einzigen Klick verfügbar sind und eine Latenzzeit von Millisekunden bieten.
- Daten- und Modellüberwachung.
Darüber hinaus bietet die Plattform Folgendes:
- Featureermittlung. Sie können in der Databricks-Benutzeroberfläche nach Features suchen.
- Governance. Featuretabellen, Funktionen und Modelle werden alle von Unity Catalog verwaltet. Wenn Sie ein Modell trainieren, erbt es die Berechtigungen der Daten, mit denen es trainiert wurde.
- Herkunft. Wenn Sie eine Featuretabelle in Azure Databricks erstellen, werden die zur Erstellung der Featuretabelle verwendeten Datenquellen gespeichert und sind zugänglich. Für jedes Feature in einer Featuretabelle können Sie auch auf die Modelle, Notebooks, Aufträge und Endpunkte zugreifen, die das Feature verwenden.
- Arbeitsbereichsübergreifender Zugriff. Featuretabellen, Funktionen und Modelle sind automatisch in jedem Arbeitsbereich verfügbar, der Zugriff auf den Katalog hat.
Anforderungen
- Ihr Arbeitsbereich muss für Unity Catalog aktiviert sein.
- Feature Engineering in Unity Catalog erfordert Databricks Runtime 13.3 LTS oder höher.
Wenn Ihr Arbeitsbereich diese Anforderungen nicht erfüllt, lesen Sie Arbeitsbereichfeaturespeicher (Legacy), um die Verwendung des Arbeitsbereichsfeaturespeichers zu erfahren.
Wie funktioniert Feature Engineering für Databricks?
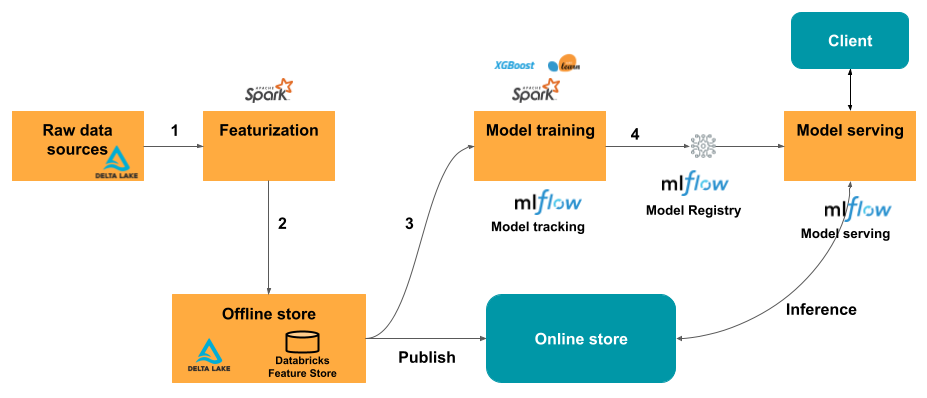
Der typische Machine Learning-Workflow mit Feature Engineering für Databricks folgt diesem Muster:
- Schreiben Sie Code, um Rohdaten in Features zu konvertieren und einen Spark-DataFrame zu erstellen, der die gewünschten Features enthält.
- Erstellen einer Delta-Tabelle in Unity Catalog. Jede Delta-Tabelle mit einem Primärschlüssel ist automatisch eine Featuretabelle.
- Trainieren und Protokollieren eines Modells mithilfe der Featuretabelle. Wenn Sie dies tun, speichert das Modell die Spezifikationen von Features, die für Trainings verwendet werden. Wenn das Modell für den Rückschluss verwendet wird, werden automatisch Features aus den entsprechenden Featuretabellen verknüpft.
- Registrieren des Modells in der Modellregistrierung.
Anschließend können Sie das Modell dazu nutzen, um Vorhersagen für neue Daten zu treffen. Für Batchanwendungsfälle ruft das Modell automatisch die benötigten Features aus dem Feature Store ab.
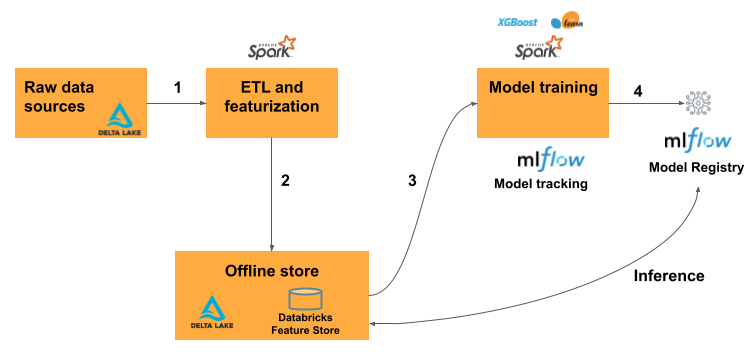
Veröffentlichen Sie die Features für echtzeitbasierte Anwendungsfälle in einer Onlinetabelle. Onlinespeicher von Drittanbietern werden ebenfalls unterstützt. Siehe Onlinespeicher von Drittanbietern.
Zum Zeitpunkt des Rückschlusses liest das Modell vorab berechnete Features aus dem Onlinespeicher aus und verknüpft sie mit den Daten, die in der Clientanforderung für den Modellbereitstellungsendpunkt bereitgestellt werden.
Beginnen Sie mit der Verwendung von Feature Engineering –Beispiel-Notebooks
Probieren Sie zunächst diese Beispiel-Notebooks aus. Im grundlegenden Notebook erfahren Sie, wie Sie eine Feature-Tabelle erstellen, sie zum Trainieren eines Modells verwenden und anschließend Batchbewertungen mithilfe des automatischen Feature-Lookups durchführen. Außerdem wird die Feature Engineering-Benutzeroberfläche vorgestellt und gezeigt, wie Sie damit nach Features suchen und verstehen können, wie Features erstellt und verwendet werden.
Grundlegendes zum Feature Engineering im Beispielnotebook für Unity Catalog
Das Beispielnotebook „Taxi“ veranschaulicht den Prozess der Erstellung von Features, deren Aktualisierung und deren Verwendung für das Modelltraining und den Batchrückschluss.
Notebook mit Feature Engineering-Taxibeispiel in Unity Catalog
Unterstützte Datentypen
Feature Engineering in Unity Catalog und im Arbeitsbereichfeaturespeicher unterstützen die folgenden PySpark-Datentypen:
IntegerTypeFloatTypeBooleanTypeStringTypeDoubleTypeLongTypeTimestampTypeDateTypeShortTypeArrayTypeBinaryType[1]DecimalType[1]MapType[1]StructType[2]
[1] BinaryType, DecimalType und MapType werden in allen Versionen von Feature Engineering im Unity-Katalog und im Arbeitsbereich Feature Store v0.3.5 oder höher unterstützt.
[2] StructType wird in Feature Engineering v0.6.0 oder höher unterstützt.
Die oben aufgeführten Datentypen unterstützen Featuretypen, die in Machine Learning-Anwendungen üblich sind. Beispiele:
- Sie können Vektoren mit hoher Dichte, Tensoren und Einbettungen als
ArrayTypespeichern. - Sie können Vektoren mit geringer Dichte, Tensoren und Einbettungen als
MapTypespeichern. - Sie können Text als
StringTypespeichern.
Wenn sie in Onlineshops veröffentlicht werden, werden ArrayType- und MapType-Features im JSON-Format gespeichert.
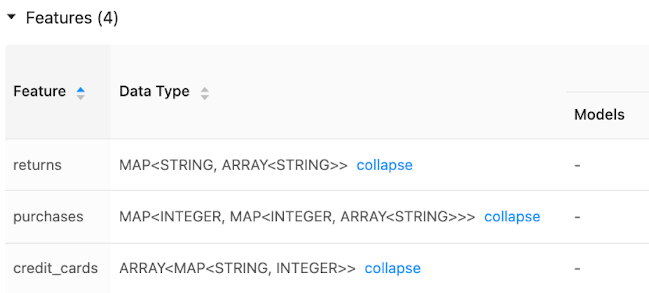
Die Benutzeroberfläche des Featurespeichers zeigt Metadaten zu Featuredatentypen an:
Weitere Informationen
Für weitere Informationen zu bewährten Methoden laden Sie den Umfassenden Leitfaden für Featurespeicher herunter.