Tutorial: Bereitstellen und Abfragen eines benutzerdefinierten Modells
Dieser Artikel enthält die grundlegenden Schritte für das Bereitstellen und Abfragen eines benutzerdefinierten Modells, bei dem es sich um ein traditionelles ML-Modell mit Mosaic AI Model Serving handelt. Das Modell muss im Unity Catalog oder in der Arbeitsbereichsmodellregistrierung registriert sein.
Informationen zum Bereitstellen von generativen KI-Modellen finden Sie in den folgenden Artikeln:
Schritt 1: Protokollieren des Modells
Es gibt verschiedene Möglichkeiten, das Modell für die Modellbereitstellung zu protokollieren:
| Protokollierungsverfahren | Beschreibung |
|---|---|
| Automatische Protokollierung | Dieses Verfahren wird automatisch aktiviert, wenn Sie Databricks Runtime for Machine Learning verwenden. Dies benötigt am wenigsten Aufwand, bietet jedoch auch am wenigsten Kontrolle. |
| Protokollierung mit integrierten MLflow-Varianten | Sie können das Modell manuell mit den integrierten Modellvarianten von MLflow protokollieren. |
Benutzerdefinierte Protokollierung mit pyfunc |
Verwenden Sie dieses Verfahren, wenn Sie über ein benutzerdefiniertes Modell verfügen oder zusätzliche Schritte vor oder nach dem Rückschluss benötigen. |
Das folgende Beispiel veranschaulicht, wie Sie Ihr MLflow-Modell mithilfe der transformer-Variante protokollieren und die Parameter angeben, die Sie für Ihr Modell benötigen.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
Nachdem Ihr Modell protokolliert wurde, vergewissern Sie sich, dass Ihr Modell entweder im Unity-Katalog oder in der MLflow-Modellregistrierung registriert ist.
Schritt 2: Erstellen eines Endpunkts mithilfe der Benutzeroberfläche für die Bereitstellung
Wenn Sie Ihr registriertes Modell nach dem Protokollieren bereitzustellen möchten, können Sie mithilfe der Benutzeroberfläche für die Bereitstellung einen Modellbereitstellungsendpunkt erstellen.
Klicken Sie auf der Seitenleiste auf Bereitstellung, um die Benutzeroberfläche für die Bereitstellung anzuzeigen.
Klicken Sie auf Bereitstellungsendpunkt erstellen.
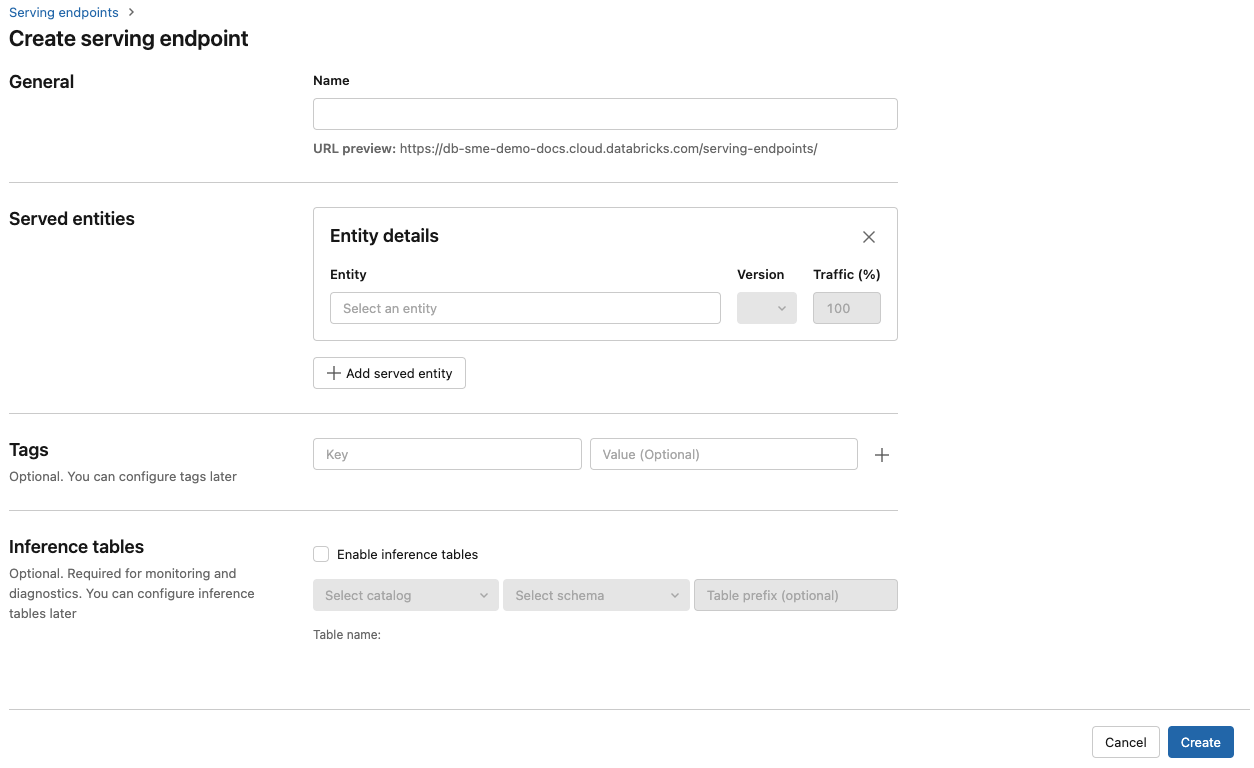
Geben Sie im Feld Name einen Namen für Ihren Endpunkt an.
Im Abschnitt Bereitgestellte Entitäten
- Wählen Sie das Feld Entität aus, um das Formular Bereitgestellte Entität auswählen zu öffnen.
- Wählen Sie den Modelltyp aus, den Sie bereitstellen möchten. Das Formular wird basierend auf Ihrer Auswahl dynamisch aktualisiert.
- Wählen Sie aus, welches Modell und welche Modellversion Sie bereitstellen möchten.
- Wählen Sie den Prozentsatz des Datenverkehrs aus, der an Ihr bereitgestelltes Modell weitergeleitet wird.
- Wählen Sie die zu verwendende Computegröße aus.
- Wählen Sie unter Horizontale Computeskalierung die Größe der horizontalen Computeskalierung aus. Sie sollte der Anzahl der Anforderungen entsprechen, die dieses bereitgestellte Modell gleichzeitig verarbeiten kann. Diese Zahl sollte ungefähr dem Ergebnis der folgenden Rechnung entsprechen: QPS × Modellausführungszeit.
- Verfügbare Größen sind Klein für 0–4 Anforderungen, Mittel 8–16 Anforderungen und Große für 16–64 Anforderungen.
- Geben Sie an, ob der Endpunkt auf null skaliert werden soll, wenn er nicht verwendet wird.
Klicken Sie auf Erstellen. Die Seite Bereitstellungsendpunkte wird mit dem Status „Nicht bereit“ für den Bereitstellungsendpunkt angezeigt.
Wenn Sie es vorziehen, einen Endpunkt programmgesteuert mit der Bereitstellungs-API von Databricks zu erstellen, lesen Sie Erstellen von benutzerdefinierten Endpunkten für die Modellbereitstellung.
Schritt 3: Abfragen des Endpunkts
Die einfachste und schnellste Möglichkeit zum Testen und Senden von Bewertungsanforderungen an Ihr bereitgestelltes Modell ist die Verwendung der Benutzeroberfläche für die Bereitstellung.
Wählen Sie auf der Seite Bereitstellungsendpunkt die Option Abfrageendpunkt aus.
Fügen Sie die Modelleingabedaten im JSON-Format ein, und klicken Sie auf Anforderung senden. Wenn das Modell mit einem Eingabebeispiel protokolliert wurde, klicken Sie auf Show Example (Beispiel anzeigen), um das Eingabebeispiel zu laden.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Erstellen Sie zum Senden von Bewertungsanforderungen eine JSON-Datei mit einem der unterstützten Schlüssel und einem dem Eingabeformat entsprechenden JSON-Objekt. Die unterstützten Formate und einen Leitfaden zum Senden von Bewertungsanforderungen mithilfe der API finden Sie unter Abfragen von Bereitstellungsendpunkten für benutzerdefinierte Modelle.
Wenn Sie beabsichtigen, außerhalb der Azure Databricks-Benutzeroberfläche für die Bereitstellung auf Ihren Dienstendpunkt zuzugreifen, benötigen Sie ein DATABRICKS_API_TOKEN-Element.
Wichtig
Als bewährte Sicherheitsmethode für Produktionsszenarien empfiehlt Databricks, Computer-zu-Computer-OAuth-Token für die Authentifizierung während der Produktion zu verwenden.
Für die Test- und Entwicklungsphase empfiehlt Databricks die Verwendung eines persönlichen Zugriffstokens, das Dienstprinzipalen anstelle von Arbeitsbereichsbenutzern gehört. Informationen zum Erstellen von Token für Dienstprinzipale finden Sie unter Verwalten von Token für einen Dienstprinzipal.
Beispielnotebooks
Im folgenden Notebook finden Sie Informationen zum Bereitstellen eines transformers-Modells von MLflow mit der Modellbereitstellung.
Bereitstellen eines transformers-Modellnotebooks von Hugging Face
Im folgenden Notebook finden Sie Informationen zum Bereitstellen eines pyfunc-Modells von MLflow mit der Modellbereitstellung. Weitere Informationen zum Anpassen Ihrer Modellimplementierungen finden Sie unter Bereitstellen von Python-Code mit der Modellbereitstellung.