Bereitstellen eines Azure Service Fabric-Clusters über Verfügbarkeitszonen hinweg
Verfügbarkeitszonen in Azure sind ein Hochverfügbarkeitsangebot, das Anwendungen und Daten vor Ausfällen von Rechenzentren schützt. Eine Verfügbarkeitszone ist ein eindeutiger physischer Standort, der mit unabhängiger Stromversorgung, Kühlung und Netzwerk innerhalb einer Azure-Region ausgestattet ist.
Zur Unterstützung von Clustern, die sich über die Verfügbarkeitszonen erstrecken, bietet Azure Service Fabric die beiden Konfigurationsmethoden, die im folgenden Artikel beschrieben werden. Verfügbarkeitszonen sind nur in ausgewählten Regionen verfügbar. Weitere Informationen finden Sie in der Übersicht über Verfügbarkeitszonen.
Beispielvorlagen sind auf der Seite mit verfügbarkeitszonenübergreifenden Service Fabric-Vorlagen verfügbar.
Topologie für das Verteilen eines primären Knotentyps auf Verfügbarkeitszonen
Hinweis
Der Vorteil, den primären Knotentyp über die Verfügbarkeitszonen hinweg zu verteilen, zeigt sich eigentlich nur bei drei Zonen und nicht bei zwei Zonen.
- Die Clusterzuverlässigkeitsstufe muss auf
Platinumfestgelegt werden - Eine einzelne Ressource für öffentliche IP-Adressen mit Standard-SKU
- Eine einzelne Lastenausgleichsressource mit Standard-SKU
- Eine Netzwerksicherheitsgruppe (Network Security Group, NSG), auf die das Subnetz verweist, in dem Sie Ihre VM-Skalierungsgruppen bereitstellen
Hinweis
Die Eigenschaft für die einzelne Platzierungsgruppe der VM-Skalierungsgruppe muss auf true festgelegt werden.
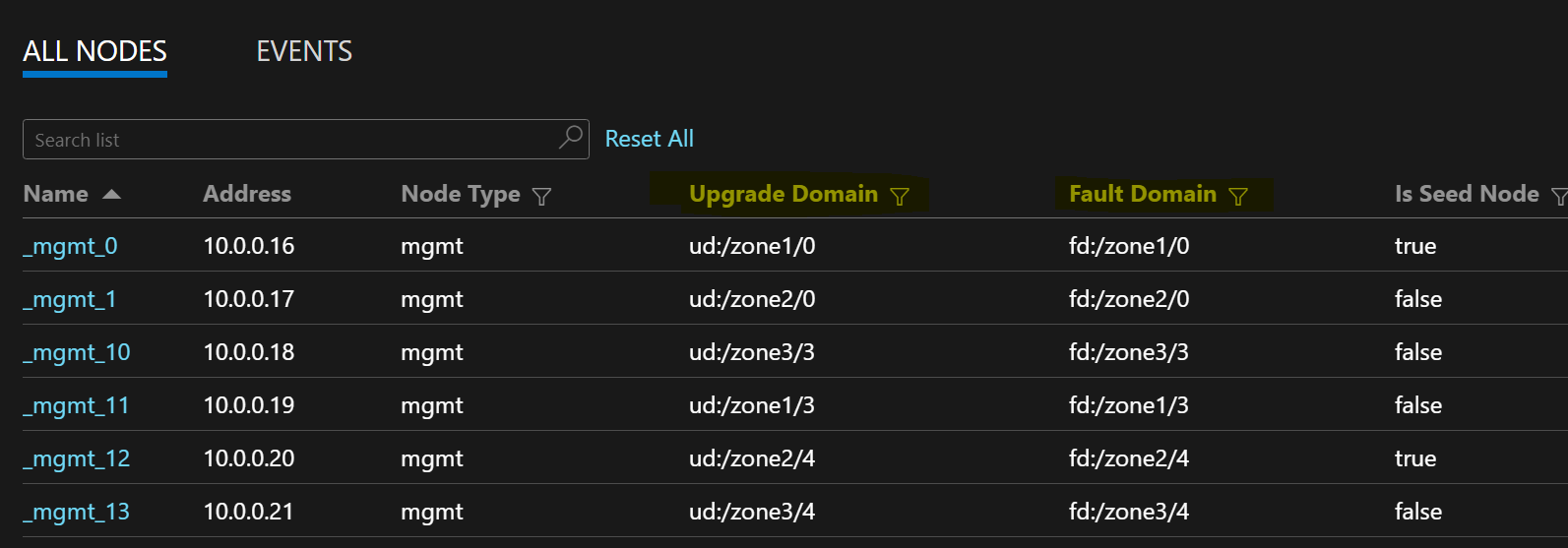
Die folgende Beispielknotenliste zeigt FD/UD-Formate in einer zonenübergreifenden VM-Skalierungsgruppe:
Zonenübergreifende Verteilung von Dienstreplikaten
Wenn ein Dienst für Knotentypen bereitgestellt wird, die sich über mehrere Verfügbarkeitszonen erstrecken, werden die Replikate in verschiedenen Zonen platziert. Die Fehlerdomänen für die Knoten dieser Knotentypen werden mit den Zoneninformationen konfiguriert (FD = fd:/zone1/1 usw.). Beispiel: Bei fünf Replikaten oder Dienstinstanzen lautet die Verteilung 2-2-1, und die Laufzeit versucht, die Replikate bzw. Instanzen gleichmäßig auf die Verfügbarkeitszonen zu verteilen.
Konfiguration von Benutzerdienstreplikaten
Zustandsbehaftete Benutzerdienste, die auf den Knotentypen innerhalb der Verfügbarkeitszonen bereitstellt werden, sollten wie folgt konfiguriert werden: Replikatanzahl mit Ziel = 9, Minimum = 5. Diese Konfiguration unterstützt den Dienst auch dann, wenn eine Zone ausfällt, da in den anderen beiden Zonen weiterhin sechs Replikate verfügbar sind. Ein Anwendungsupgrade ist in diesem Szenario ebenfalls erfolgreich.
Clusterzuverlässigkeitsstufe
Mit diesem Wert werden die Anzahl von Startknoten im Cluster sowie die Replikatgröße der Systemdienste definiert. Ein verfügbarkeitszonenübergreifendes Setup verfügt über eine größere Anzahl von Knoten, die für Zonenresilienz auf mehrere Zonen verteilt sind.
Mit einem höheren ReliabilityLevel-Wert wird sichergestellt, dass mehr Startknoten und Systemdienstreplikate vorhanden und gleichmäßig auf die Zonen verteilt sind. Sollte es zum Ausfall einer Zone kommen, wirkt sich dies bei einer solchen Konfiguration nicht auf den Cluster und die Systemdienste aus. Mit der Einstellung ReliabilityLevel = Platinum (empfohlen) wird sichergestellt, dass neun Startknoten auf die Zonen (drei Startknoten pro Zone) innerhalb des Clusters verteilt sind.
Szenario mit Zonenausfall
Wenn eine Zone ausfällt, werden alle Knoten und Dienstreplikate für diese Zone als ausgefallen angezeigt. Da in den anderen Zonen Replikate vorhanden sind, ist der Dienst jedoch weiterhin verfügbar. Für primäre Replikate wird ein Failover auf die funktionierenden Zonen durchgeführt. Für die Dienste wird ein Warnungszustand angezeigt, da die Anzahl von Zielreplikaten noch nicht erreicht wurde und die Anzahl von VMs immer noch höher ist als der Mindestwert der Zielreplikate.
Der Service Fabric-Lastenausgleich stellt in den Arbeitszonen die erforderliche Anzahl von Zielreplikaten bereit. An diesem Punkt erscheinen die Dienste fehlerfrei. Wenn die ausgefallene Zone wieder verfügbar ist, verteilt die Lastenausgleichsressource alle Dienstreplikate gleichmäßig auf die Zonen.
Die Anstehenden Optimierungen
- Um zuverlässige Infrastruktur-Updates bereitzustellen, erfordert Service Fabric, dass die Dauerhaftigkeit der virtuellen Computer-Skalierungsgruppe mindestens auf Silber festgelegt wird. Dadurch können die zugrunde liegende virtuellen Computer-Skalierungsgruppe und die Service Fabric-Laufzeit zuverlässige Updates bereitstellen. Dazu muss jede Zone mindestens 5 virtuelle Computer haben. Wir arbeiten daran, diese Anforderung auf 3 und 2 virtuelle Computer pro Zone für die primären und nicht-primären Knotentypen zu reduzieren.
- Alle unten genannten Konfigurationen und zukünftigen Aufgaben bieten eine direkte Migration zu den Kunden, bei denen derselbe Cluster aktualisiert werden kann, um die neue Konfiguration zu verwenden. Dazu werden neue Knotentypen hinzugefügt und die alten eingestellt.
Netzwerkanforderungen
Ressource für öffentliche IP-Adressen und Lastenausgleichsressource
Um die Eigenschaft zones für eine VM-Skalierungsgruppenressource zu aktivieren, müssen die Lastenausgleichs- und IP-Ressource, auf die diese VM-Skalierungsgruppe verweist, die Standard-SKU verwenden. Beim Erstellen einer Lastenausgleichs- oder IP-Ressource ohne die SKU-Eigenschaft wird eine Basic-SKU erstellt, die keine Verfügbarkeitszonen unterstützt. Eine Lastenausgleichsressource mit Standard-SKU blockiert standardmäßig den gesamten externen Datenverkehr. Um externen Datenverkehr zuzulassen, stellen Sie eine NSG im Subnetz bereit.
{
"apiVersion": "2018-11-01",
"type": "Microsoft.Network/publicIPAddresses",
"name": "[concat('LB','-', parameters('clusterName')]",
"location": "[parameters('computeLocation')]",
"sku": {
"name": "Standard"
}
}
{
"apiVersion": "2018-11-01",
"type": "Microsoft.Network/loadBalancers",
"name": "[concat('LB','-', parameters('clusterName')]",
"location": "[parameters('computeLocation')]",
"dependsOn": [
"[concat('Microsoft.Network/networkSecurityGroups/', concat('nsg', parameters('subnet0Name')))]"
],
"properties": {
"addressSpace": {
"addressPrefixes": [
"[parameters('addressPrefix')]"
]
},
"subnets": [
{
"name": "[parameters('subnet0Name')]",
"properties": {
"addressPrefix": "[parameters('subnet0Prefix')]",
"networkSecurityGroup": {
"id": "[resourceId('Microsoft.Network/networkSecurityGroups', concat('nsg', parameters('subnet0Name')))]"
}
}
}
]
},
"sku": {
"name": "Standard"
}
}
Hinweis
Es ist nicht möglich, eine direkte Änderung der SKU für die Ressource der öffentlichen IP-Adresse und die Lastenausgleichsressource vorzunehmen. Informationen zum Migrieren von vorhandenen Ressourcen mit Basic-SKU finden Sie im Abschnitt zur Migration in diesem Artikel.
NAT-Regeln für VM-Skalierungsgruppen
Die Regeln für eingehende Netzwerkadressenübersetzung für den Lastenausgleich sollten mit den NAT-Pools der VM-Skalierungsgruppe übereinstimmen. Jede VM-Skalierungsgruppe muss über einen eindeutigen NAT-Pool für eingehenden Datenverkehr verfügen.
{
"inboundNatPools": [
{
"name": "LoadBalancerBEAddressNatPool0",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "50999",
"frontendPortRangeStart": "50000",
"protocol": "tcp"
}
},
{
"name": "LoadBalancerBEAddressNatPool1",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "51999",
"frontendPortRangeStart": "51000",
"protocol": "tcp"
}
},
{
"name": "LoadBalancerBEAddressNatPool2",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "52999",
"frontendPortRangeStart": "52000",
"protocol": "tcp"
}
}
]
}
Ausgangsregeln für eine Lastenausgleichsressource mit Standard-SKU
Die Ressource für öffentlichen IP-Adressen und die Lastenausgleichsressource mit Standard-SKU bieten neue Funktionen und gehen mit einem anderen Verhalten bei ausgehenden Verbindungen einher als bei Verwendung von Basic-SKUs. Wenn Sie über Standard-SKUs verfügen und ausgehende Verbindungen nutzen möchten, müssen sie diese explizit mit öffentlichen IP-Adressen oder einer Lastenausgleichsressource mit Standard-SKU definieren. Weitere Informationen finden Sie unter Ausgehende Verbindungen und Was ist Azure Load Balancer?.
Hinweis
Die Standardvorlage verweist auf eine Netzwerksicherheitsgruppe, die standardmäßig jeglichen ausgehenden Datenverkehr zulässt. Der eingehende Datenverkehr ist auf die Ports beschränkt, die für Vorgänge zur Service Fabric-Verwaltung erforderlich sind. Die Regeln der Netzwerksicherheitsgruppe können an Ihre Anforderungen angepasst werden.
Wichtig
Für jeden Knotentyp in einem Service Fabric-Cluster, der eine Lastenausgleichsressource mit Standard-SKU verwendet, muss eine Regel definiert werden, die ausgehenden Datenverkehr an Port 443 zulässt. Dieser Schritt ist erforderlich, um die Clustereinrichtung abzuschließen. Bei Bereitstellungen ohne diese Regel tritt ein Fehler auf.
1. Aktivieren mehrerer Verfügbarkeitszonen in einer einzelnen VM-Skalierungsgruppe
Mit dieser Lösung können die Benutzer drei Verfügbarkeitszonen in demselben Knotentyp umfassen. Dies ist die empfohlene Bereitstellungstopologie, da sie eine Bereitstellung über die Verfügbarkeitszonen hinweg ermöglicht, während sie eine einzelne virtuelle Computer-Skalierungsgruppe verwaltet.
Eine vollständige Beispielvorlage ist auf GitHub verfügbar.
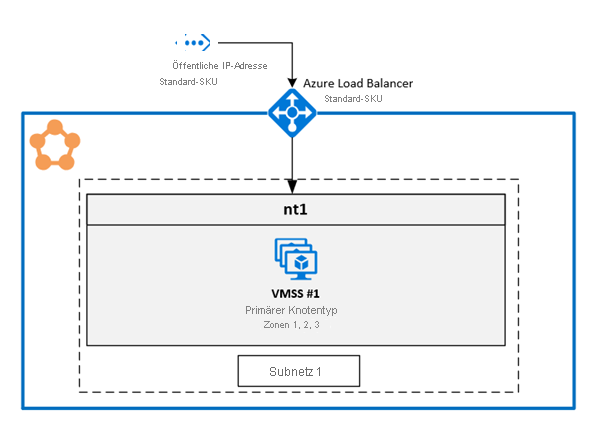
Konfigurieren von Zonen für eine VM-Skalierungsgruppe
Um Zonen für eine VM-Skalierungsgruppe zu aktivieren, fügen Sie die folgenden drei Werte in der VM-Skalierungsgruppenressource hinzu:
Der erste Wert ist die
zones-Eigenschaft, die angibt, welche Verfügbarkeitszonen in der VM-Skalierungsgruppe vorhanden sind.Der zweite Wert ist die Eigenschaft
singlePlacementGroup, die auftruefestgelegt werden muss. Die Skalierungsgruppe, die sich über drei Verfügbarkeitszonen erstreckt, kann selbst mit der EinstellungsinglePlacementGroup = trueauf bis zu 300 VMs hochskaliert werden.Der dritte Wert ist
zoneBalance, der einen strikten Zonenausgleich sicherstellt. Dieser Wert sollte auftruefestgelegt werden. Dadurch wird sichergestellt, dass die zonenübergreifenden VM-Verteilungen nicht unausgeglichen sind. Beim Ausfall einer Zone verfügen die anderen Zonen also über genügend VMs für einen unterbrechungsfreien Betrieb des Clusters.Ein Cluster mit einer unausgeglichenen VM-Verteilung ist in einem Szenario mit Zonenausfall möglicherweise nicht länger verfügbar, da diese Zone gegebenenfalls über die meisten VMs verfügt. Eine unausgeglichene zonenübergreifende VM-Verteilung führt außerdem zu Problemen bei der Dienstplatzierung sowie dazu, dass Infrastrukturupdates nicht erfolgreich abgeschlossen werden können. Weitere Informationen finden Sie unter zoneBalancing.
Die Außerkraftsetzungen FaultDomain und UpgradeDomain müssen nicht konfiguriert werden.
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Compute/virtualMachineScaleSets",
"name": "[parameters('vmNodeType1Name')]",
"location": "[parameters('computeLocation')]",
"zones": [ "1", "2", "3" ],
"properties": {
"singlePlacementGroup": true,
"zoneBalance": true
}
}
Hinweis
- Service Fabric-Cluster sollten über mindestens einen primären Knotentyp verfügen. Die Dauerhaftigkeitsstufe primärer Knotentypen sollte auf „Silver“ (Silber) oder höher festgelegt werden.
- Eine Verfügbarkeitszone, die eine VM-Skalierungsgruppe umfasst, sollte mit mindestens drei Verfügbarkeitszonen konfiguriert werden (unabhängig von der Dauerhaftigkeitsstufe).
- Eine Verfügbarkeitszone, die eine VM-Skalierungsgruppe mit der Dauerhaftigkeit „Silver“ (Silber) oder höher umfasst, sollte über mindestens 15 VMs (fünf pro Region) verfügen.
- Eine Verfügbarkeitszone, die eine VM-Skalierungsgruppe mit der Dauerhaftigkeit „Bronze“ umfasst, sollte über mindestens 15 VMs verfügen.
Aktivieren der Unterstützung für mehrere Zonen im Service Fabric-Knotentyp
Der Service Fabric-Knotentyp muss aktiviert werden, um mehrere Verfügbarkeitszonen zu unterstützen.
Der erste Wert lautet
multipleAvailabilityZones. Dieser Wert sollte für den Knotentyp auftruegesetzt werden.Der zweite, optionale Wert ist
sfZonalUpgradeMode. Diese Eigenschaft kann nicht geändert werden, wenn im Cluster bereits ein Knotentyp mit mehreren Verfügbarkeitszonen vorhanden ist. Diese Eigenschaft steuert die logische Gruppierung von VMs in Upgradedomänen.- Bei Festlegung auf
Parallelgilt Folgendes: VMs, die dem Knotentyp zugeordnet sind, werden in Upgradedomänen gruppiert. Die Zoneninformationen zu den fünf Upgradedomänen werden ignoriert. Mit dieser Einstellung werden die Upgradedomänen aller Zonen gleichzeitig aktualisiert. Dieser Bereitstellungsmodus ist bei Upgrades schneller, wird jedoch nicht empfohlen, da er gegen die SDP-Richtlinien verstößt, die festlegen, dass Updates jeweils in nur einer Zone angewendet werden sollten. - Wird dieser Wert ausgelassen oder auf
Hierarchicalfestgelegt, gilt Folgendes: VMs werden gemäß der Zonenverteilung in bis zu 15 Upgradedomänen gruppiert. Jede der drei Zonen verfügt über fünf Upgradedomänen. Dadurch wird sichergestellt, dass die Zonen nacheinander aktualisiert werden. Erst wenn der Vorgang für die fünf Upgradedomänen innerhalb der ersten Zone abgeschlossen wurde, wird mit der nächsten Zone fortgefahren. Dieser Updatevorgang bietet eine höhere Sicherheit für den Cluster und die Benutzeranwendung.
Diese Eigenschaft definiert lediglich das Upgradeverhalten für Service Fabric-Anwendungen und Codeupgrades. Upgrades der zugrunde liegenden VM-Skalierungsgruppen werden weiterhin in allen Verfügbarkeitszonen parallel ausgeführt. Diese Eigenschaft wirkt sich nicht auf die Verteilung von Upgradedomänen für Knotentypen aus, für die nicht mehrere Zonen aktiviert sind.
- Bei Festlegung auf
Der dritte Wert ist
vmssZonalUpgradeMode. Er ist optional und kann jederzeit aktualisiert werden. Diese Eigenschaft definiert das Upgradeschema für die VM-Skalierungsgruppe: parallel oder sequenziell über Verfügbarkeitszonen hinweg.- Ist der Wert auf
Parallelfestgelegt, werden alle Updates für Skalierungsgruppen parallel in allen Zonen durchgeführt. Dieser Bereitstellungsmodus ist bei Upgrades schneller, wird jedoch nicht empfohlen, da er gegen die SDP-Richtlinien verstößt, die festlegen, dass Updates jeweils in nur einer Zone angewendet werden sollten. - Ist der Wert nicht angegeben oder auf
Hierarchicalfestgelegt, werden die Zonen nacheinander aktualisiert. Erst wenn der Vorgang für die fünf Upgradedomänen innerhalb der ersten Zone abgeschlossen wurde, wird mit der nächsten Zone fortgefahren. Dieser Updatevorgang bietet eine höhere Sicherheit für den Cluster und die Benutzeranwendung.
- Ist der Wert auf
Wichtig
Die API-Version der Service Fabric-Clusterressource sollte „2020-12-01-preview“ oder höher lauten.
Die Clustercodeversion sollte mindestens 8.1.321 oder höher sein.
{
"apiVersion": "2020-12-01-preview",
"type": "Microsoft.ServiceFabric/clusters",
"name": "[parameters('clusterName')]",
"location": "[parameters('clusterLocation')]",
"dependsOn": [
"[concat('Microsoft.Storage/storageAccounts/', parameters('supportLogStorageAccountName'))]"
],
"properties": {
"reliabilityLevel": "Platinum",
"sfZonalUpgradeMode": "Hierarchical",
"vmssZonalUpgradeMode": "Parallel",
"nodeTypes": [
{
"name": "[parameters('vmNodeType0Name')]",
"multipleAvailabilityZones": true
}
]
}
}
Hinweis
- Die Ressource für öffentliche IP-Adressen und die Lastenausgleichsressource sollten die Standard-SKU verwenden, wie zuvor in diesem Artikel beschrieben.
- Die Eigenschaft
multipleAvailabilityZoneskann für den Knotentyp nur beim Erstellen definiert werden. Eine spätere Änderung ist nicht möglich. Vorhandene Knotentypen können also nicht mit dieser Eigenschaft konfiguriert werden. - Wenn
sfZonalUpgradeModeausgelassen oder aufHierarchicalfestgelegt wird, werden die Cluster- und Anwendungsbereitstellungen langsamer, da im Cluster mehr Upgradedomänen vorhanden sind. Für die erforderliche Upgradedauer der 15 Upgradedomänen müssen angemessene Upgraderichtlinientimeouts festgelegt werden. Die Upgraderichtlinie für App und Cluster sollte aktualisiert werden, um sicherzustellen, dass die Bereitstellung nicht das Timeout von 12 Stunden überschreitet, das für die Azure-Ressourcendienstbereitstellung festgelegt ist. Das bedeutet, dass die Bereitstellung für 15 Upgradedomänen nicht länger als 12 Stunden dauern sollte (also nicht mehr als 40 Minuten pro Upgradedomäne). - Legen Sie für den Cluster die Zuverlässigkeitsstufe
Platinumfest, um sicherzustellen, dass der Cluster in einem Szenario mit einer ausgefallenen Zone weiterhin verfügbar ist. - Das Upgrade des DurabilityLevel (Dauerhaftigkeitsstufe) für einen nodetype (Knotentyp) mit multipleAvailabilityZones (mehreren Verfügbarkeitszonen) wird nicht unterstützt. Erstellen Sie stattdessen einen neuen nodetype mit der höheren Dauerhaftigkeit.
- SF unterstützt nur 3 AvailabilityZones (Verfügbarkeitszonen). Eine höhere Zahl wird jetzt nicht unterstützt.
Tipp
Es wird empfohlen, sfZonalUpgradeMode auf Hierarchical festzulegen oder diesen Wert auszulassen. Bei der Bereitstellung wird die Zonenverteilung von VMs befolgt, die sich auf eine geringere Anzahl von Replikaten oder Instanzen auswirkt und sie dadurch sicherer macht.
Verwenden Sie sfZonalUpgradeMode mit der Einstellung Parallel, wenn die Bereitstellungsgeschwindigkeit Priorität hat oder lediglich eine zustandslose Workload auf dem Knotentyp mit mehreren Verfügbarkeitszonen ausgeführt wird. Dies führt dazu, dass die Upgradedomänen in allen Verfügbarkeitszonen parallel aktualisiert werden.
Migration zum Knotentyp mit mehreren Verfügbarkeitszonen
Für jedes Migrationsszenario muss ein neuer Knotentyp hinzugefügt werden, der mehrere Verfügbarkeitszonen unterstützt. Vorhandene Knotentypen können nicht migriert werden, um mehrere Zonen zu unterstützen. Im Artikel Hochskalieren des primären Knotentyps eines Service Fabric-Clusters sind die Schritte zum Hinzufügen eines neuen Knotentyps sowie weiterer Ressourcen beschrieben, die für den neuen Knotentyp benötigt werden (z. B. IP- und Lastenausgleichsressourcen). Außerdem wird in diesem Artikel beschrieben, wie Sie den vorhandenen Knotentyp außer Betrieb nehmen, nachdem der neue Knotentyp mit mehreren Verfügbarkeitszonen dem Cluster hinzugefügt wurde.
Die Migration von einem Knotentyp der einen grundlegenden Lastenausgleicher und IP-Ressourcen verwendet. Dieser Vorgang ist bereits in einem nachfolgenden Unterabschnitt für die Lösung mit einem Knotentyp pro Verfügbarkeitszone beschrieben.
Der einzige Unterschied für den neuen Knotentyp besteht darin, dass nur eine VM-Skalierungsgruppe und ein Knotentyp für alle Verfügbarkeitszonen vorhanden sind (anstelle von einem Knotentyp pro Verfügbarkeitszone).
Migration von einem Knotentyp mit Lastenausgleichs- und IP-Ressourcen der Standard-SKU: Befolgen Sie die zuvor beschriebenen Schritte. Es ist jedoch nicht erforderlich, neue Lastenausgleichs-, IP- und NSG-Ressourcen hinzuzufügen. Für den neuen Knotentyp können dieselben Ressourcen wiederverwendet werden.
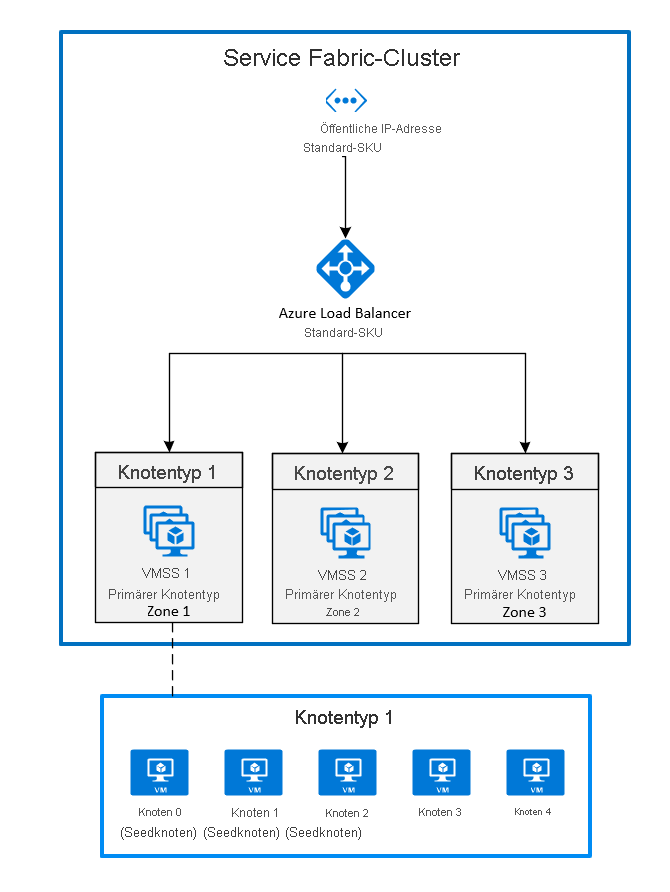
2. Bereitstellen von Zonen durch das Anheften von virtuellen Computer-Skalierungsgruppen an jede Zone
Das ist momentan die allgemein verfügbare Konfiguration. Um einen Service Fabric-Cluster über mehrere Verfügbarkeitszonen hinweg zu verteilen, müssen Sie in jeder von der Region unterstützten Verfügbarkeitszone einen primären Knotentyp erstellen. Dadurch werden Startknoten gleichmäßig auf jeden der primären Knotentypen verteilt.
Die empfohlene Topologie für den primären Knotentyp erfordert folgendes:
- Es müssen drei Knotentypen vorhanden sein, die als primäre Knotentypen markiert sind
- Jeder Knotentyp sollte einer eigenen VM-Skalierungsgruppe zugeordnet sein, die sich in einer anderen Zone befindet.
- Jede VM-Skalierungsgruppe sollte mindestens fünf Knoten aufweisen (Dauerhaftigkeit „Silver“ (Silber)).
Das folgende Diagramm zeigt die Architektur der Azure Service Fabric-Verfügbarkeitszonen:
Aktivieren von Zonen für VM-Skalierungsgruppen
Um eine Zone für eine VM-Skalierungsgruppe zu aktivieren, fügen Sie die folgenden drei Werte in der VM-Skalierungsgruppenressource hinzu:
- Der erste Wert ist die
zones-Eigenschaft, die angibt, in welcher Verfügbarkeitszone die VM-Skalierungsgruppe bereitgestellt wird. - Der zweite Wert ist die Eigenschaft
singlePlacementGroup, die auftruefestgelegt werden muss. - Der dritte Wert ist die Eigenschaft
faultDomainOverridein der Erweiterung der Service Fabric-VM-Skalierungsgruppe. Diese Eigenschaft sollte nur die Zone enthalten, in der diese VM-Skalierungsgruppe platziert wird. Beispiel:"faultDomainOverride": "az1". Da Azure Service Fabric-Cluster keine regionsübergreifende Unterstützung bieten, müssen alle VM-Skalierungsgruppenressourcen in derselben Region platziert werden.
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Compute/virtualMachineScaleSets",
"name": "[parameters('vmNodeType1Name')]",
"location": "[parameters('computeLocation')]",
"zones": [
"1"
],
"properties": {
"singlePlacementGroup": true
},
"virtualMachineProfile": {
"extensionProfile": {
"extensions": [
{
"name": "[concat(parameters('vmNodeType1Name'),'_ServiceFabricNode')]",
"properties": {
"type": "ServiceFabricNode",
"autoUpgradeMinorVersion": false,
"publisher": "Microsoft.Azure.ServiceFabric",
"settings": {
"clusterEndpoint": "[reference(parameters('clusterName')).clusterEndpoint]",
"nodeTypeRef": "[parameters('vmNodeType1Name')]",
"dataPath": "D:\\\\SvcFab",
"durabilityLevel": "Silver",
"certificate": {
"thumbprint": "[parameters('certificateThumbprint')]",
"x509StoreName": "[parameters('certificateStoreValue')]"
},
"systemLogUploadSettings": {
"Enabled": true
},
"faultDomainOverride": "az1"
},
"typeHandlerVersion": "1.0"
}
}
]
}
}
}
Aktivieren mehrerer primärer Knotentypen in der Service Fabric-Clusterressource
Legen Sie die isPrimary-Eigenschaft auf true fest, um einen oder mehrere Knotentypen in einer Clusterressource als primären Knotentyp festzulegen. Wenn Sie einen Service Fabric-Cluster über mehrere Verfügbarkeitszonen hinweg bereitstellen, sollten drei Knotentypen in unterschiedlichen Zonen bereitgestellt werden.
{
"reliabilityLevel": "Platinum",
"nodeTypes": [
{
"name": "[parameters('vmNodeType0Name')]",
"applicationPorts": {
"endPort": "[parameters('nt0applicationEndPort')]",
"startPort": "[parameters('nt0applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt0fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt0ephemeralEndPort')]",
"startPort": "[parameters('nt0ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt0fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt0InstanceCount')]"
},
{
"name": "[parameters('vmNodeType1Name')]",
"applicationPorts": {
"endPort": "[parameters('nt1applicationEndPort')]",
"startPort": "[parameters('nt1applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt1fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt1ephemeralEndPort')]",
"startPort": "[parameters('nt1ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt1fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt1InstanceCount')]"
},
{
"name": "[parameters('vmNodeType2Name')]",
"applicationPorts": {
"endPort": "[parameters('nt2applicationEndPort')]",
"startPort": "[parameters('nt2applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt2fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt2ephemeralEndPort')]",
"startPort": "[parameters('nt2ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt2fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt2InstanceCount')]"
}
]
}
Migration zu Verfügbarkeitszonen aus einem Cluster mit einer Lastenausgleichs- und IP-Ressource mit Basic-SKU
Wenn Sie einen Cluster migrieren möchten, der eine Lastenausgleichs- und IP-Ressource mit Basic-SKU nutzt, müssen Sie zunächst eine neue Lastenausgleichs- und IP-Ressource mit der Standard-SKU erstellen. Diese Ressourcen können nicht aktualisiert werden.
Verweisen Sie in den neuen verfügbarkeitszonenübergreifenden Knotentypen, die Sie verwenden möchten, auf die neuen Lastenausgleichs- und IP-Ressourcen. Im obigen Beispiel wurden drei neue VM-Skalierungsgruppenressourcen in den Zonen 1, 2 und 3 hinzugefügt. Diese VM-Skalierungsgruppen verweisen auf die neu erstellten Lastenausgleichs- und IP-Ressourcen, die in der Service Fabric-Clusterressource als primäre Knotentypen gekennzeichnet sind.
Fügen Sie zunächst die neuen Ressourcen zu Ihrer vorhandenen Azure Resource Manager-Vorlage hinzu. Diese Ressourcen umfassen Folgendes:
- Eine Ressource für öffentliche IP-Adressen mit Standard-SKU
- Eine Lastenausgleichsressource mit Standard-SKU
- Eine Netzwerksicherheitsgruppe (NSG), auf die das Subnetz verweist, in dem Sie Ihre VM-Skalierungsgruppen bereitstellen
- Es müssen drei Knotentypen vorhanden sein, die als primäre Knotentypen markiert sind
- Jeder Knotentyp sollte einer eigenen VM-Skalierungsgruppe zugeordnet sein, die sich in einer anderen Zone befindet.
- Jede VM-Skalierungsgruppe sollte mindestens fünf Knoten aufweisen (Dauerhaftigkeit „Silver“ (Silber)).
Ein Beispiel für diese Ressourcen finden Sie in der Beispielvorlage.
New-AzureRmResourceGroupDeployment ` -ResourceGroupName $ResourceGroupName ` -TemplateFile $Template ` -TemplateParameterFile $ParametersNach der Bereitstellung der Ressourcen können Sie die Knoten im primären Knotentyp des ursprünglichen Clusters deaktivieren. Sobald die Knoten deaktiviert sind, werden die Systemdienste zum neuen primären Knotentyp migriert, der im obigen Schritt bereitgestellt wurde.
Connect-ServiceFabricCluster -ConnectionEndpoint $ClusterName ` -KeepAliveIntervalInSec 10 ` -X509Credential ` -ServerCertThumbprint $thumb ` -FindType FindByThumbprint ` -FindValue $thumb ` -StoreLocation CurrentUser ` -StoreName My Write-Host "Connected to cluster" $nodeNames = @("_nt0_0", "_nt0_1", "_nt0_2", "_nt0_3", "_nt0_4") Write-Host "Disabling nodes..." foreach($name in $nodeNames) { Disable-ServiceFabricNode -NodeName $name -Intent RemoveNode -Force }Nachdem alle Knoten deaktiviert wurden, werden die Systemdienste auf dem primären Knotentyp ausgeführt, der auf mehrere Zonen verteilt ist. Sie können dann die deaktivierten Knoten aus dem Cluster entfernen. Nachdem die Knoten entfernt wurden, können Sie die ursprünglichen IP-, Lastenausgleichs- und VM-Skalierungsgruppenressourcen entfernen.
foreach($name in $nodeNames){ # Remove the node from the cluster Remove-ServiceFabricNodeState -NodeName $name -TimeoutSec 300 -Force Write-Host "Removed node state for node $name" } $scaleSetName="nt0" Remove-AzureRmVmss -ResourceGroupName $groupname -VMScaleSetName $scaleSetName -Force $lbname="LB-cluster-nt0" $oldPublicIpName="LBIP-cluster-0" $newPublicIpName="LBIP-cluster-1" Remove-AzureRmLoadBalancer -Name $lbname -ResourceGroupName $groupname -Force Remove-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname -ForceDann sollten Sie die Verweise auf diese Ressourcen aus der Resource Manager-Vorlage entfernen, die Sie bereitgestellt haben.
Abschließend aktualisieren Sie den DNS-Namen und die öffentliche IP-Adresse.
$oldprimaryPublicIP = Get-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname
$primaryDNSName = $oldprimaryPublicIP.DnsSettings.DomainNameLabel
$primaryDNSFqdn = $oldprimaryPublicIP.DnsSettings.Fqdn
Remove-AzureRmLoadBalancer -Name $lbname -ResourceGroupName $groupname -Force
Remove-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname -Force
$PublicIP = Get-AzureRmPublicIpAddress -Name $newPublicIpName -ResourceGroupName $groupname
$PublicIP.DnsSettings.DomainNameLabel = $primaryDNSName
$PublicIP.DnsSettings.Fqdn = $primaryDNSFqdn
Set-AzureRmPublicIpAddress -PublicIpAddress $PublicIP