Architektur des dedizierten SQL-Pools (früher SQL DW) in Azure Synapse Analytics
Azure Synapse Analytics ist ein Analysedienst, der Data Warehousing für Unternehmen mit Big Data-Analysen vereint. Er ermöglicht es Ihnen, Daten zu ihren Bedingungen abzufragen.
Hinweis
Weitere Informationen zu Azure Synapse Analytics finden Sie in diesem Video, in dem die Verbesserungen des Datenverschiebung erläutert werden.
Architekturkomponenten von Synapse SQL
Der dedizierte SQL-Pool (früher SQL DW) nutzt eine Architektur mit horizontaler Skalierung zum Verteilen der Berechnungsverarbeitung von Daten auf mehrere Knoten. Die Skalierungseinheit ist eine Abstraktion der Computeleistung, die als Data Warehouse-Einheit bezeichnet wird. Compute- und Speicherressourcen sind getrennt, sodass Sie Compute unabhängig von den Daten in Ihrem System skalieren können.
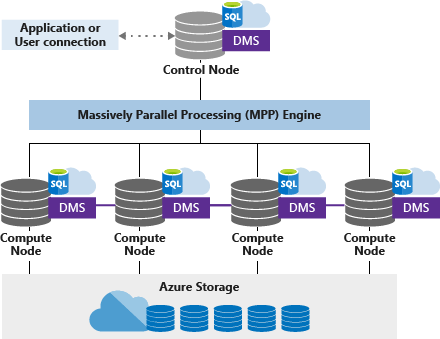
Der dedizierte SQL-Pool (früher SQL DW) verwendet eine knotenbasierte Architektur. Anwendungen stellen eine Verbindung her und geben T-SQL-Befehle an einen Steuerknoten aus. Der Steuerknoten hostet die Engine für verteilte Abfragen, die Abfragen für die Parallelverarbeitung optimiert und dann Vorgänge an Serverknoten übergibt, sodass die Vorgänge parallel ausgeführt werden.
Auf den Serverknoten werden alle Benutzerdaten in Azure Storage gespeichert und die parallelen Abfragen ausgeführt. Der Datenverschiebungsdienst (Data Movement Service, DMS) ist ein interner Dienst auf Systemebene, der Daten nach Bedarf zwischen den Knoten verschiebt, sodass Abfragen parallel ausgeführt und genaue Ergebnisse zurückgegeben werden.
Mit entkoppeltem Speicher und Compute ist bei Verwendung eines dedizierten SQL-Pools (früher SQL DW) Folgendes möglich:
- Anpassen der Größe der Computeleistung unabhängig von den Speicheranforderungen
- Vergrößern oder Verkleinern der Computeleistung innerhalb eines dedizierten SQL-Pools (früher SQL DW), ohne Daten verschieben zu müssen.
- Anhalten der Computekapazität ohne Beeinträchtigung der Daten und nur Bezahlung für den Speicher
- Fortsetzen der Computekapazität während der Betriebszeiten
Azure Storage
Der dedizierte SQL-Pool (früher SQL DW) nutzt Azure Storage, um Ihre Benutzerdaten zu schützen. Da Ihre Daten von Azure Storage gespeichert und verwaltet werden, werden die Kosten für Ihre Speichernutzung getrennt berechnet. Die Daten werden zur Optimierung der Systemleistung in Verteilungen horizontal partitioniert. Beim Definieren der Tabelle können Sie das Shardingmuster zum Verteilen der Daten auswählen. Folgende Shardingmuster werden unterstützt:
- Hash
- Roundrobin
- Replikat
Steuerknoten
Der Steuerknoten ist der zentrale Knoten der Architektur. Dies ist das Front-End, das mit allen Anwendungen und Verbindungen interagiert. Die Engine für verteilte Abfragen wird auf dem Steuerknoten ausgeführt, um parallele Abfragen zu optimieren und zu koordinieren. Wenn Sie eine T-SQL-Abfrage übermitteln, wird sie vom Steuerknoten in Abfragen transformiert, die für die einzelnen Verteilungen parallel ausgeführt werden.
Serverknoten
Die Serverknoten liefern die Rechnerleistung. Verteilungen werden Serverknoten zur Verarbeitung zugeordnet. Wenn Sie weitere kostenpflichtige Computeressourcen nutzen, werden die Verteilungen den verfügbaren Serverknoten neu zugeordnet. Die Anzahl der Serverknoten liegt zwischen 1 und 60 und wird durch die Dienstebene für Synapse SQL bestimmt.
Jedem Serverknoten ist eine Knoten-ID zugewiesen, die in Systemsichten sichtbar ist. Sie können die Serverknoten-ID anzeigen, indem Sie in den Systemsichten, deren Namen mit „sys.pdw_nodes“ beginnen, nach der Spalte „node_id“ suchen. Eine Liste dieser Systemsichten finden Sie unter Synapse SQL-Systemsichten.
Datenverschiebungsdienst
Der Datenverschiebungsdienst (Data Movement Service, DMS) ist die Datentransporttechnologie, mit der die Datenverschiebung zwischen den Serverknoten koordiniert wird. Einige Abfragen erfordern eine Datenverschiebung, damit sichergestellt ist, dass die parallelen Abfragen genaue Ergebnisse zurückgeben. Wenn eine Datenverschiebung erforderlich ist, wird durch den Datenverschiebungsdienst sichergestellt, dass die richtigen Daten an die richtige Position verschoben werden.
Verteilungen
Eine Verteilung ist die Basiseinheit zur Speicherung und Verarbeitung von parallelen Abfragen, die für verteilte Daten ausgeführt werden. Wenn Synapse SQL eine Abfrage ausführt, wird der Vorgang in 60 kleinere Abfragen unterteilt, die parallel ausgeführt werden.
Die einzelnen 60 kleineren Abfragen werden jeweils auf einer der Datenverteilungen ausgeführt. Auf jedem Serverknoten werden eine oder mehrere der 60 Verteilungen verwaltet. Bei einem dedizierten SQL-Pool (früher SQL DW) mit maximalen Computeressourcen befindet sich eine Verteilung auf jeweils einem Serverknoten. Bei einem dedizierten SQL-Pool (früher SQL DW) mit minimalen Computeressourcen befinden sich alle Verteilungen auf einem einzigen Serverknoten.
Hinweis
Empfehlungen für die beste Tabellenverteilungsstrategie, die basierend auf Ihren Workloads verwendet werden soll, finden Sie im Azure Synapse SQL Distribution Advisor.
Tabellen mit Hashverteilung
Eine Tabelle mit Hashverteilung kann die höchste Abfrageleistung für Verknüpfungen und Aggregationen in großen Tabellen bieten.
Zum horizontalen Partitionieren von Daten in eine Tabelle mit Hashverteilung wird eine Hashfunktion verwendet, um jede Zeile deterministisch zu einer einzigen Verteilung zuzuweisen. In der Tabellendefinition wird eine der Spalten als Verteilungsspalte festgelegt. Die Hashfunktion verwendet die Werte in der Verteilungsspalte, um jede Zeile einer Verteilung zuzuweisen.
Im folgenden Diagramm ist dargestellt, wie eine vollständige (nicht verteilte) Tabelle als Tabelle mit Hashverteilung gespeichert wird.

- Jede Zeile gehört zu einer Verteilung.
- Mit einem deterministischen Hashalgorithmus wird jede Zeile einer Verteilung zugewiesen.
- Die Anzahl von Tabellenzeilen pro Verteilung variiert, wie an den unterschiedlichen Größen von Tabellen zu sehen ist.
Bei der Auswahl einer Verteilungsspalte sollten einige Aspekte in Bezug auf die Leistung beachtet werden, z.B. Eindeutigkeit, eventuelle Datenschiefe und die Arten von Abfragen, die im System ausgeführt werden.
Tabellen mit Roundrobin-Verteilung
Eine Roundrobin-Tabelle lässt sich am einfachsten erstellen und bietet schnelle Leistung, wenn sie als Stagingtabelle für Ladevorgänge verwendet wird.
In einer Tabelle mit Roundrobin-Verteilung werden Daten gleichmäßig auf die Tabelle aufgeteilt, dies erfolgt jedoch ohne weitere Optimierung. Eine Verteilung wird zunächst nach dem Zufallsprinzip ausgewählt. Dann werden Zeilenpuffer sequenziell Verteilungen zugewiesen. Die Daten lassen sich schnell in eine Roundrobin-Tabelle laden, die Abfrageleistung ist jedoch häufig bei Tabellen mit Hashverteilung besser. Verknüpfungen für Roundrobin-Tabellen machen eine neue Verteilung der Daten erforderlich. Dies erfordert zusätzlich Zeit.
Replizierte Tabellen
Eine replizierte Tabelle bietet die schnellste Abfrageleistung für kleine Tabellen.
In einer Tabelle, die repliziert wird, wird eine vollständige Kopie der Tabelle auf jedem Serverknoten zwischengespeichert. Daher müssen beim Replizieren einer Tabelle Daten vor einer Verknüpfung oder Aggregation nicht mehr auf Serverknoten übertragen werden. Replizierte Tabellen werden am besten mit kleinen Tabellen verwendet. Zusätzlicher Speicherplatz ist erforderlich, und beim Schreiben von Daten entsteht zusätzlicher Mehraufwand, sodass dies für große Tabellen nicht praktikabel ist.
Das nachstehende Diagramm zeigt eine replizierte Tabelle, die bei der ersten Verteilung auf den einzelnen Serverknoten zwischengespeichert wird.

Nächste Schritte
Nachdem Sie sich mit den Grundlagen von Azure Synapse vertraut gemacht haben, informieren Sie sich nun darüber, wie Sie innerhalb kurzer Zeit einen dedizierten SQL-Pool (früher SQL DW) erstellen und Beispieldaten laden können. Falls Sie mit Azure noch nicht vertraut sind und auf neue Terminologie stoßen, ist das Azure-Glossar sehr nützlich. Oder sehen Sie sich einige der folgenden weiteren Azure Synapse-Ressourcen an: