K-Means Clustering
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
- Siehe Migrieren zu Azure Machine Learning
- Weitere Informationen zu Azure Machine Learning.
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
Konfiguriert und initialisiert ein K-Means-Clusteringmodell
Kategorie: Machine Learning/Initialize Model/Clustering
Hinweis
Gilt nur für: Machine Learning Studio ( klassisch)
Ähnliche Drag & Drop-Module sind im Azure Machine Learning-Designer verfügbar.
Modulübersicht
In diesem Artikel wird beschrieben, wie Sie das K-Means-Clustering-Modul in Machine Learning Studio (klassisch) verwenden, um ein nicht trainiertes K-Means-Clusteringmodell zu erstellen.
K-means ist einer der einfachsten und bekanntesten unüberwachten Lernalgorithmen und kann für eine Vielzahl von Machine Learning-Aufgaben verwendet werden, z. B. für die Erkennung abnormaler Daten, das Clustering von Textdokumenten und die Analyse eines Datasets, bevor andere Klassifizierungs- oder Regressionsmethoden verwendet werden. Um ein Clusteringmodell zu erstellen, fügen Sie dieses Modul Ihrem Experiment hinzu. Stellen Sie dann eine Verbindung mit einem Dataset her. Legen Sie anschließend Parameter fest, wie z.B. die erwartete Anzahl von Clustern, die bei der Erstellung der Cluster verwendete Entfernungsmetrik u.v.m.
Nachdem Sie die Modulhyperparameter konfiguriert haben, verbinden Sie das nicht trainierte Modell mit dem Train Clustering Model oder den Sweep Clustering-Modulen , um das Modell für die von Ihnen bereitgestellten Eingabedaten zu trainieren. Da der k-Means-Algorithmus eine unbeaufsichtigte Lernmethode ist, ist eine Bezeichnungsspalte optional.
- Wenn Ihre Daten eine Bezeichnung enthalten, können Sie die Bezeichnungswerte verwenden, um die Auswahl der Cluster zu steuern und das Modell zu optimieren.
- Wenn Ihre Daten keine Bezeichnung haben, erstellt der Algorithmus Cluster, die mögliche Kategorien darstellen, ausschließlich basierend auf den Daten.
Tipp
Wenn Ihre Trainingsdaten Bezeichnungen aufweisen, sollten Sie eine der überwachten Klassifizierungsmethoden in Machine Learning verwenden. Beispielsweise können Sie die Ergebnisse der Clustererstellung mit den Ergebnissen vergleichen, wenn Sie einen der Algorithmen der Entscheidungsstruktur mit mehreren Klassen verwenden.
Grundlegendes zu K-Means Clustering
Im Allgemeinen werden beim Clustering iterative Techniken befolgt, um Fälle in einem Datensatz in Clustern zu gruppieren, die ähnliche Merkmale enthalten. Diese Gruppierungen eignen sich für die Erkundung von Daten, die Erkennung von Anomalien in den Daten und möglicherweise für Vorhersagen. Clusteringmodelle können Ihnen auch helfen, Beziehungen in einem Dataset zu erkennen, die sich möglicherweise durch Durchsuchen oder einfaches Beobachten nicht logisch zu erkennen geben. Aus diesen Gründen erfolgt das Clustering oft in der Frühphase maschineller Lernaufgaben, um die Daten zu untersuchen und unerwartete Korrelationen zu entdecken.
Wenn Sie ein Clusteringmodell mit der k-Means-Methode konfigurieren, müssen Sie einen Zielwert k angeben, der die Anzahl der im Modell gewünschten Schwerpunkte angibt. Der Schwerpunkt ist ein Punkt, der für jeden Cluster repräsentativ ist. Der k-Means-Algorithmus ordnet jeden eingehenden Datenpunkt einem der Cluster zu, indem er die Summe der Quadrate innerhalb des Clusters minimiert.
Bei der Verarbeitung der Trainingsdaten beginnt der k-Means-Algorithmus mit einer ersten Reihe zufällig gewählter Schwerpunkte, die als Ausgangspunkt jedes Clusters dienen, und wendet den Lloyd-Algorithmus an, um die Positionen der Schwerpunkte iterativ zu verbessern. Der k-Means-Algorithmus beendet die Bildung und Verbesserung von Clustern, sobald er eine oder mehrere dieser Bedingungen erfüllt:
Die Schwerpunkte stabilisieren sich, was bedeutet, dass sich die Clusterzuweisungen für einzelne Punkte nicht mehr ändern und der Algorithmus zu einer Lösung konvergiert ist.
Der Algorithmus hat die angegebene Anzahl von Iterationen ausgeführt.
Nach der Trainingsphase verwenden Sie das Modul Assign Data to Clusters (Zuweisen von Daten zu Clustern), um neue Fälle einem der Cluster zuzuordnen, die vom k-Means-Algorithmus gefunden wurden. Die Clusterzuweisung erfolgt durch Berechnung der Entfernung zwischen dem neuen Fall und dem Schwerpunkt jedes Clusters. Jeder neue Fall wird dem Cluster mit dem nächstgelegenen Schwerpunkt zugeordnet.
Konfigurieren des K-Means-Clusterings
Fügen Sie Ihrem Experiment das Modul K-Means Clustering hinzu.
Geben Sie an, wie das Modell trainiert werden soll, indem Sie die Option Create trainer mode (Trainermodus erstellen) aktivieren.
Single Parameter (Einzelner Parameter): Wenn Sie die genauen Parameter kennen, die Sie im Clusteringmodell verwenden möchten, können Sie eine bestimmte Menge von Werten als Argumente angeben.
Parameterbereich: Wenn Sie sich nicht sicher sind, welche Parameter am besten geeignet sind, können Sie die optimalen Parameter ermitteln, indem Sie mehrere Werte angeben und das Modul Sweep Clustering verwenden, um die optimale Konfiguration zu finden.
Der Trainer durchläuft mehrere Kombinationen der von Ihnen bereitgestellten Einstellungen und bestimmt die Kombination von Werten, die die optimalen Clusterergebnisse ergibt.
Geben Sie unter Anzahl von Centroids die Anzahl von Clustern ein, mit denen der Algorithmus beginnen soll.
Es gibt keine Garantie dafür, dass das Modell genau diese Anzahl von Clustern produziert. Der Algorithn beginnt mit dieser Anzahl von Datenpunkten und iteiert, um die optimale Konfiguration zu finden, wie im Abschnitt Technische Hinweise beschrieben.
Wenn Sie einen Parameter sweep ausführen, ändert sich der Name der Eigenschaft in Bereich für Die Anzahl der Centroids. Sie können den Bereichs-Generator verwenden, um einen Bereich anzugeben, oder Sie können eine Reihe von Zahlen eingeben, die unterschiedliche Anzahl von Clustern darstellen, die beim Initialisieren jedes Modells erstellt werden sollen.
Die Eigenschaften Initialisierung oder Initialisierung für Sweep werden verwendet, um den Algorithmus anzugeben, der zum Definieren der anfänglichen Clusterkonfiguration verwendet wird.
First N: Eine gewisse anfängliche Anzahl von Datenpunkten wird aus dem Dataset ausgewählt und als Initialmittel verwendet.
Dies wird auch als Forgy-Methode bezeichnet.
Random (Zufällig): Der Algorithmus platziert einen Datenpunkt nach dem Zufallsprinzip in einem Cluster und berechnet dann den Anfangsmittelwert als Schwerpunkt der zufällig zugewiesenen Punkte des Clusters.
Wird auch Random Partition-Methode bezeichnet.
k-Means++ : Dies ist die Standardmethode für die Initialisierung von Clustern.
Der k-Means ++ Algorithmus wurde 2007 von David Arthur und Sergei Vassilvitskii vorgeschlagen, um schlechtes Clustering durch den standardmäßigen k-Means Algorithmus zu vermeiden. k-Means ++ verbessert den standardmäßigen k-Means-Algorithmus durch Verwenden einer anderen Methode zur Auswahl der anfänglichen Clusterzentren.
K-Means++Fast: Eine Variante des K-means++- Algorithmus, die für schnelleres Clustering optimiert wurde.
Gleichmäßig: Zentroiden befinden sich im d-Dimensionalen Raum von n Datenpunkten äquidistant voneinander.
Bezeichnungsspalte verwenden: Die Werte in der Bezeichnungsspalte werden verwendet, um die Auswahl von Schwerpunkten zu leiten.
Geben Sie für Random number seed (zufällig gewählter Startwert) optional einen Wert ein, der als Startwert für die Clusterinitialisierung verwendet wird. Dieser Wert kann erhebliche Auswirkungen auf die Clusterauswahl haben.
Wenn Sie einen Parameter sweep verwenden, können Sie angeben, dass mehrere anfängliche Samen erstellt werden, um nach dem besten anfänglichen Seedwert zu suchen. Geben Sie unter Anzahl der zu fegenden Samen die Gesamtzahl der zufälligen Startwerte ein, die als Startpunkte verwendet werden sollen.
Wählen Sie für Metric (Metrik) die Funktion, mit der Sie die Entfernung zwischen Clustervektoren oder zwischen neuen Datenpunkten und dem zufällig gewählten Schwerpunkt messen möchten. Machine Learning unterstützt die folgenden Clusterabstandsmetriken:
Euclidean (Euklidisch): Die euklidische Entfernung wird beim K-Means-Clustering häufig als ein Maß der Clusterstreuung verwendet. Diese Metrik wird bevorzugt, da sie die mittlere Entfernung zwischen Punkten und den Schwerpunkten minimiert.
Kosinus: Die Kosinusfunktion wird verwendet, um die Clusterähnlichkeit zu messen. Kosinusähnlichkeit ist nützlich in Fällen, in denen Sie sich nicht um die Länge eines Vektors kümmern, nur um seinen Winkel.
Geben Sie für Iterations (Iterationen) die Anzahl der Iterationen des Algorithmus über die Trainingsdaten ein, bevor Sie die Auswahl der Schwerpunkte abschließen.
Sie können diesen Parameter so anpassen, dass die Genauigkeit im Verhältnis zur Trainingszeit ausgeglichen wird.
Wählen Sie für Assign label mode (Bezeichnungsmodus zuweisen) eine Option, die angibt, wie eine Bezeichnungsspalte, falls im Datensatz vorhanden, behandelt werden soll.
Da K-Means-Clustering eine unüberwachte maschinelle Lernmethode ist, sind Bezeichnungen optional. Wenn Ihr Dataset jedoch bereits eine Bezeichnungsspalte aufweist, können Sie diese Werte verwenden, um die Auswahl der Cluster zu steuern, oder Sie können festlegen, dass die Werte ignoriert werden sollen.
Ignore label column (Bezeichnungsspalte ignorieren): Die Werte in der Bezeichnungsspalte werden ignoriert und nicht für die Erstellung des Modells verwendet.
Fill missing values (Fehlende Werte auffüllen): Die Werte der Bezeichnungsspalte werden als Features verwendet, um die Erstellung der Cluster zu unterstützen. Wenn in Zeilen eine Bezeichnung fehlt, wird der Wert durch Verwendung anderer Features impliziert.
Overwrite from closest to center (Vom nächstgelegenen zum Zentrum überschreiben): Die Werte der Bezeichnungsspalte werden durch vorhergesagte Bezeichnungswerte ersetzt, wobei die Bezeichnung des Punkts verwendet wird, der dem aktuellen Schwerpunkt am nächsten liegt.
Trainieren des Modells.
Wenn Sie Create trainer mode (Trainermodus erstellen) auf Single Parameter (Einzelner Parameter) festlegen, fügen Sie ein mit Tags versehenes Dataset hinzu, und trainieren Sie das Modell mit dem Modul Train Clustering Model (Trainieren des Clusteringsmodells).
Wenn Sie den Modus Trainer erstellen auf Parameterbereich festlegen, fügen Sie ein getaggtes Dataset hinzu, und trainieren Sie das Modell mithilfe von Sweep Clustering. Sie können das trainierte Modell mithilfe dieser Parameter verwenden oder die Parametereinstellungen notieren, die beim Konfigurieren eines Teilnehmers verwendet werden.
Ergebnisse
Nach Abschluss der Konfiguration und des Trainings des Modells haben Sie ein Modell, mit dem Sie Ergebnisse generieren können. Es gibt jedoch mehrere Möglichkeiten, das Modell zu trainieren, die Ergebnisse anzuzeigen und sie zu nutzen:
Erfassen einer Momentaufnahme des Modells in Ihrem Arbeitsbereich
Wenn Sie das Modul Trainieren des Clusteringmodells verwendet haben
- Klicken Sie mit der rechten Maustaste auf das Modul Train Clustering Model.
- Wählen Sie Trained model (Trainiertes Modell) aus, und klicken Sie dann auf Save as Trained Model (Als trainiertes Modell speichern).
Wenn Sie das Modul Sweep Clustering zum Trainieren des Modells verwendet haben
- Klicken Sie mit der rechten Maustaste auf das Modul Sweep Clustering .
- Wählen Sie Best Trainiertes Modell aus, und klicken Sie dann auf Als trainiertes Modell speichern.
Das gespeicherte Modell stellt die Trainingsdaten zum Zeitpunkt der Speicherung des Modells dar. Wenn Sie die im Experiment verwendeten Trainingsdaten später aktualisieren, wird das gespeicherte Modell nicht aktualisiert.
Anzeigen einer visuellen Darstellung der Cluster im Modell
Wenn Sie das Modul Train Clustering Model (Trainieren des Clusteringmodells) verwendet haben
- Klicken Sie mit der rechten Maustaste auf das Modul, und wählen Sie Ergebnisdataset aus.
- Wählen Sie Visualisieren aus.
Wenn Sie das Sweep Clustering-Modul verwendet haben
Fügen Sie eine instance des Moduls Zuweisen von Daten zu Clustern hinzu, und generieren Sie Bewertungen mithilfe des Best Trained-Modells.
Klicken Sie mit der rechten Maustaste auf das Modul Daten zu Clustern zuweisen , wählen Sie Ergebnisdataset und dann Visualisieren aus.
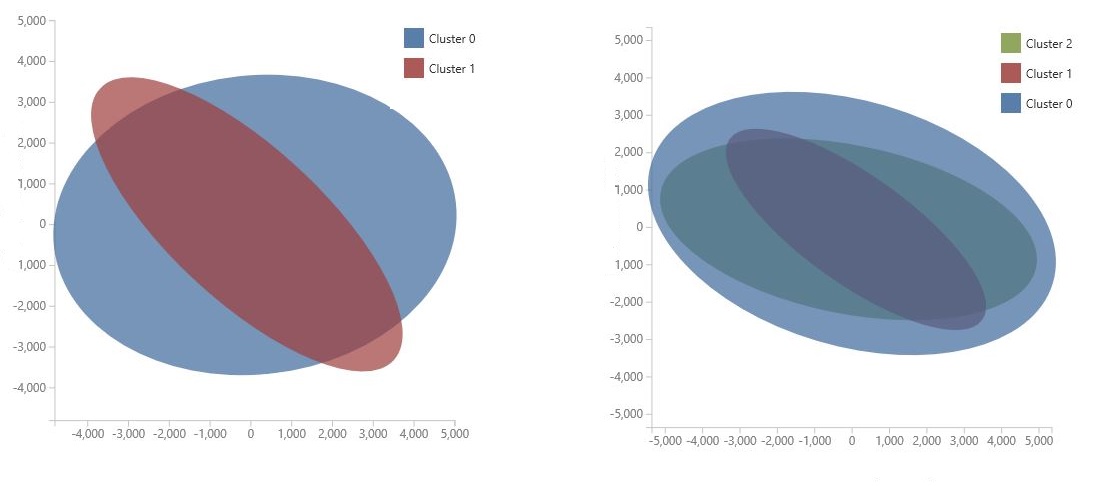
Das Diagramm wird mithilfe der Prinzipalkomponentenanalyse generiert, einer Methode in Data Science zum Komprimieren des Featureraums eines Modells. Das Diagramm zeigt eine Reihe von Features, komprimiert in zwei Dimensionen, die den Unterschied zwischen den Clustern am besten charakterisieren. Durch visuelle Überprüfung der allgemeinen Größe des Featurebereichs für jeden Cluster und wie stark sich die Cluster überschneiden, können Sie eine Vorstellung davon erhalten, wie gut Ihr Modell funktionieren könnte.
Die folgenden PCA-Diagramme stellen beispielsweise die Ergebnisse von zwei Modellen dar, die mit denselben Daten trainiert wurden: Das erste wurde für die Ausgabe von zwei Clustern konfiguriert, und das zweite wurde für die Ausgabe von drei Clustern konfiguriert. Anhand dieser Diagramme können Sie sehen, dass die Erhöhung der Anzahl von Clustern nicht notwendigerweise die Trennung der Klassen verbessert hat.
Tipp
Verwenden Sie das Modul Sweep Clustering , um den optimalen Satz von Hyperparametern auszuwählen, einschließlich des zufälligen Ausgangswerts und der Anzahl der Startschwerpunkte.
Sehen Sie sich die Liste der Datenpunkte und die Cluster an, zu der sie gehören.
Es gibt zwei Optionen zum Anzeigen des Datasets mit Ergebnissen, je nachdem, wie Sie das Modell trainiert haben:
Wenn Sie das Modul Sweep Clustering zum Trainieren des Modells verwendet haben
- Verwenden Sie das Kontrollkästchen im Modul Sweep Clustering , um anzugeben, ob Die Eingabedaten zusammen mit den Ergebnissen oder nur die Ergebnisse angezeigt werden sollen.
- Wenn das Training abgeschlossen ist, klicken Sie mit der rechten Maustaste auf das Modul, und wählen Sie Ergebnisdataset (Ausgabenummer 2) aus.
- Klicken Sie auf Visualisieren.
Wenn Sie das Modul Train Clustering Model (Trainieren des Clusteringmodells) verwendet haben
- Fügen Sie das Modul Daten zu Clustern zuweisen hinzu , und verbinden Sie das trainierte Modell mit der linken Eingabe. Verbinden Sie ein Dataset mit der rechten Eingabe.
- Fügen Sie ihrem Experiment das Modul In Dataset konvertieren hinzu, und verbinden Sie es mit der Ausgabe von Zuweisen von Daten zu Clustern.
- Verwenden Sie das Kontrollkästchen im Modul Daten zu Clustern zuweisen , um anzugeben, ob Sie die Eingabedaten zusammen mit den Ergebnissen oder nur die Ergebnisse anzeigen möchten.
- Führen Sie das Experiment aus, oder führen Sie nur das Modul Convert to Dataset (In Dataset konvertieren ) aus.
- Klicken Sie mit der rechten Maustaste auf In Dataset konvertieren, wählen Sie Ergebnisdataset aus, und klicken Sie auf Visualisieren.
Die Ausgabe enthält zuerst die Eingabedatenspalten, wenn Sie sie eingeschlossen haben, und die folgenden Spalten für jede Zeile mit Eingabedaten:
Zuweisung: Die Zuweisung ist ein Wert zwischen 1 und n, wobei n die Gesamtzahl der Cluster im Modell ist. Jede Datenzeile kann nur einem Cluster zugewiesen werden.
DistancesToClusterCenter no.n: Dieser Wert misst den Abstand zwischen dem aktuellen Datenpunkt und dem Schwerpunkt für den Cluster. Eine separate Spalte in der Ausgabe für jeden Cluster im trainierten Modell.
Die Werte für den Clusterabstand basieren auf der Entfernungsmetrik, die Sie in der Option Metrik zum Messen des Clusterergebnisses ausgewählt haben. Selbst wenn Sie einen Parameter sweep für das Clusteringmodell ausführen, kann während des Sweeps nur eine Metrik angewendet werden. Wenn Sie die Metrik ändern, erhalten Sie möglicherweise unterschiedliche Entfernungswerte.
Visualisieren von clusterinternen Entfernungen
Klicken Sie im Dataset der Ergebnisse aus dem vorherigen Abschnitt auf die Spalte mit den Entfernungen für jeden Cluster. Studio (klassisch) zeigt ein Histogramm an, das die Verteilung der Entfernungen für Punkte innerhalb des Clusters visualisiert.
Die folgenden Histogramme zeigen z. B. die Verteilung der Clusterabstände vom selben Experiment, wobei vier verschiedene Metriken verwendet werden. Alle anderen Einstellungen für den Parameter sweep waren identisch. Das Ändern der Metrik führte zu einer unterschiedlichen Anzahl von Clustern in einem Modell.
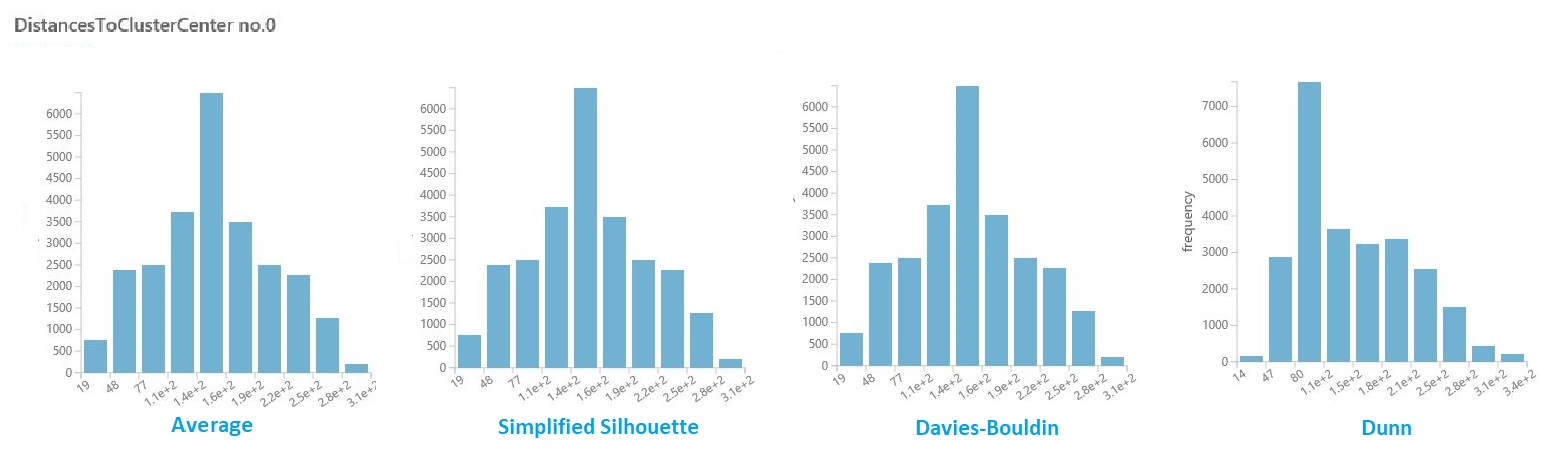
Im Allgemeinen sollten Sie eine Metrik auswählen, die den Abstand zwischen Datenpunkten in verschiedenen Klassen maximiert und die Entfernungen innerhalb einer Klasse minimiert. Sie können die vorberechneten Mittel und andere Werte im Bereich Statistik verwenden, um Sie bei dieser Entscheidung zu unterstützen.
Tipp
Sie können mittel und andere Werte extrahieren, die in Visualisierungen verwendet werden, indem Sie das PowerShell-Modul für Machine Learning verwenden.
Oder verwenden Sie das Modul Execute R Script , um eine benutzerdefinierte Entfernungsmatrix zu berechnen.
Tipps zum Generieren des besten Clusteringmodells
Es ist bekannt, dass der beim Clustering verwendete Seeding--Prozess das Modell erheblich beeinflussen kann. Seeding bedeutet die anfängliche Platzierung von Punkten in potenziellen Schwerpunkten.
Wenn das Dataset beispielsweise viele Ausreißer enthält und ein Ausreißer für das Seeding der Cluster gewählt wird, passen keine anderen Datenpunkte gut zu diesem Cluster, sodass der Cluster ein Singleton sein könnte: also ein Cluster mit nur einem Punkt.
Es gibt verschiedene Möglichkeiten, dieses Problem zu vermeiden:
Verwenden Sie einen Parameter sweep, um die Anzahl der Schwerpunkte zu ändern und mehrere Ausgangswerte auszuprobieren.
Erstellen Sie mehrere Modelle, wobei Sie die Metrik variieren oder mehr Iterationen vornehmen.
Verwenden Sie eine Methode wie PCA, um Variablen zu finden, die sich negativ auf das Clustering auswirken. Eine Demonstration dieser Technik finden Sie im Beispiel Zum Suchen ähnlicher Unternehmen .
Im Allgemeinen ist es bei Clusteringmodellen möglich, dass eine bestimmte Konfiguration zu einer lokal optimierten Menge von Clustern führt. Mit anderen Worten, die vom Modell zurückgegebene Menge von Clustern passt nur zu den aktuellen Datenpunkten und ist nicht für andere Daten generalisierbar. Wenn Sie eine andere Anfangskonfiguration verwendet haben, kann die k-Means-Methode eine andere, vielleicht sogar bessere Konfiguration finden.
Wichtig
Es wird empfohlen, immer mit den Parametern zu experimentieren, mehrere Modelle zu erstellen und die resultierenden Modelle zu vergleichen.
Beispiele
Beispiele für die Verwendung von K-Means-Clustering in Machine Learning finden Sie in den folgenden Experimenten im Azure KI-Katalog:
Irisdaten gruppieren: Vergleicht die Ergebnisse von K-Means-Clustering und Multiclass Logistic Regression für einen Klassifizierungstask.
Beispiel für die Farbquantisierung: Erstellt mehrere K-Means-Modelle mit verschiedenen Parametern, um die optimale Bildkomprimierung zu finden.
Clustering: Ähnliche Unternehmen: Variiert die Anzahl der Schwerpunkte, um Gruppen ähnlicher Unternehmen im S&P500 zu finden.
Technische Hinweise
Mit einer bestimmten Anzahl von Clustern (K) für die Suche nach einem Set von D-dimensionalen Datenpunkten mit N Datenpunkten erstellt der K-Means-Algorithmus folgende Cluster:
Das Modul initialisiert ein K-by-D-Array mit den endgültigen Schwerpunkten, die die gefundenen K-Cluster definieren.
Standardmäßig weist das Modul den K-Clustern die ersten K-Datenpunkte zu.
Beginnend mit einem anfänglichen Satz von K-Schwerpunkten, verwendet die Methode den Lloyd-Algorithmus zum iterativen Optimieren der Orte der Schwerpunkte.
Der Algorithmus wird beendet, wenn sich die Schwerpunkte stabilisieren oder wenn eine vorgegebene Anzahl von Iterationen durchlaufen wurde.
Eine Ähnlichkeitsmetrik (standardmäßig euklidische Distanz) dient zum Zuweisen aller Datenpunkte zu dem Cluster mit dem am nächsten gelegenen Schwerpunkt.
Warnung
- Wenn Sie einen Parameterbereich an Train Clustering Model übergeben, wird nur der erste Wert in der Parameterbereichsliste verwendet.
- Wenn Sie einen einzelnen Satz von Parameterwerten an das Sweep Clustering-Modul übergeben und einen Bereich von Einstellungen für jeden Parameter erwartet, werden die Werte ignoriert und die Standardwerte für den Lernenden verwendet.
- Wenn Sie die Option Parameter Range (Parameterbereich) auswählen und einen einzelnen Wert für einen beliebigen Parameter eingeben, wird dieser angegebene einzelne Wert während des gesamten Löschvorgangs verwendet, auch wenn andere Parameter in einem Wertebereich geändert werden.
Modulparameter
| Name | Range | type | Standard | BESCHREIBUNG |
|---|---|---|---|---|
| Anzahl der Schwerpunkte | >=2 | Integer | 2 | Anzahl der Schwerpunkte |
| Metrik | List (subset) | Metrik | Euklidisch | Ausgewählte Metrik |
| Initialisierung | List | Centroid Initialization-Methode | K-Means++ | Initialisierungsalgorithmus |
| Iterationen | >=1 | Integer | 100 | Number of iterations |
Ausgaben
| Name | Typ | BESCHREIBUNG |
|---|---|---|
| Untrainiertes Modell | ICluster-Schnittstelle | Untrainiertes K-Means Clustering-Modell |
Ausnahmen
Eine Liste aller Ausnahmen finden Sie unter Fehlercodes des Machine Learning-Moduls.
| Ausnahme | Beschreibung |
|---|---|
| Fehler 0003 | Eine Ausnahme tritt auf, wenn mindestens eine Eingabe NULL oder leer ist. |
Weitere Informationen
Clustering
Assign Data to Clusters (Zuweisen von Daten zu Clustern)
Trainieren des Clusteringmodells
Bereinigungs-Clustering (Sweep)