Sicherheitskonzepte für Big Data-Cluster für SQL Server
Gilt für:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
In diesem Artikel werden zentrale sicherheitsbezogene Konzepte erläutert.
Big Data-Cluster für SQL Server stellen eine kohärente und konsistente Autorisierung und Authentifizierung bereit. Ein Big Data-Cluster kann in Active Directory (AD) über eine vollständig automatisierte Bereitstellung integriert werden, die die AD-Integration für eine vorhandene Domäne einrichtet. Sobald ein Big Data-Cluster mit der AD-Integration konfiguriert ist, können Sie vorhandene Identitäten und Benutzergruppen für den einheitlichen Zugriff auf alle Endpunkte nutzen. Wenn Sie externe Tabellen in SQL Server erstellt haben, können Sie außerdem den Zugriff auf Datenquellen steuern, indem Sie den Benutzern und Gruppen von AD Zugriff auf externe Tabellen gewähren und so die Datenzugriffsrichtlinien an einem einzigen Ort zentralisieren.
In diesem 14-minütigen Video erhalten Sie einen Überblick über die Big Data-Clustersicherheit:
Authentifizierung
Die externen Clusterendpunkte unterstützen die AD-Authentifizierung. Verwenden Sie Ihre AD-Identität, um sich beim Big Data-Cluster zu authentifizieren.
Clusterendpunkte
Es gibt fünf Einstiegspunkte für den Big Data-Cluster:
Masterinstanz: TDS-Endpunkt für den Zugriff auf die SQL Server-Masterinstanz im Cluster mithilfe von Datenbanktools und Anwendungen wie SSMS oder Azure Data Studio. Wenn Sie HDFS- oder SQL Server-Befehle von Azure Data CLI (
azdata) verwenden, stellt das Tool je nach Vorgang eine Verbindung mit den anderen Endpunkten her.Gateway für den Zugriff auf HDFS-Dateien, Spark (Knox): HTTPS-Endpunkt für den Zugriff auf Dienste wie webHDFS und Spark.
(Controller-)Endpunkt für den Clusterverwaltungsdienst: Verwaltungsdienst für Big Data-Cluster, der REST-APIs für die Verwaltung des Clusters verfügbar macht. Das azdata-Tool erfordert eine Verbindung mit diesem Endpunkt.
Verwaltungsproxy: Für den Zugriff auf das Dashboard für die Protokollsuche und das Metrikdashboard.
Anwendungsproxy: Endpunkt zum Verwalten von Anwendungen, die im Big Data-Cluster bereitgestellt werden.
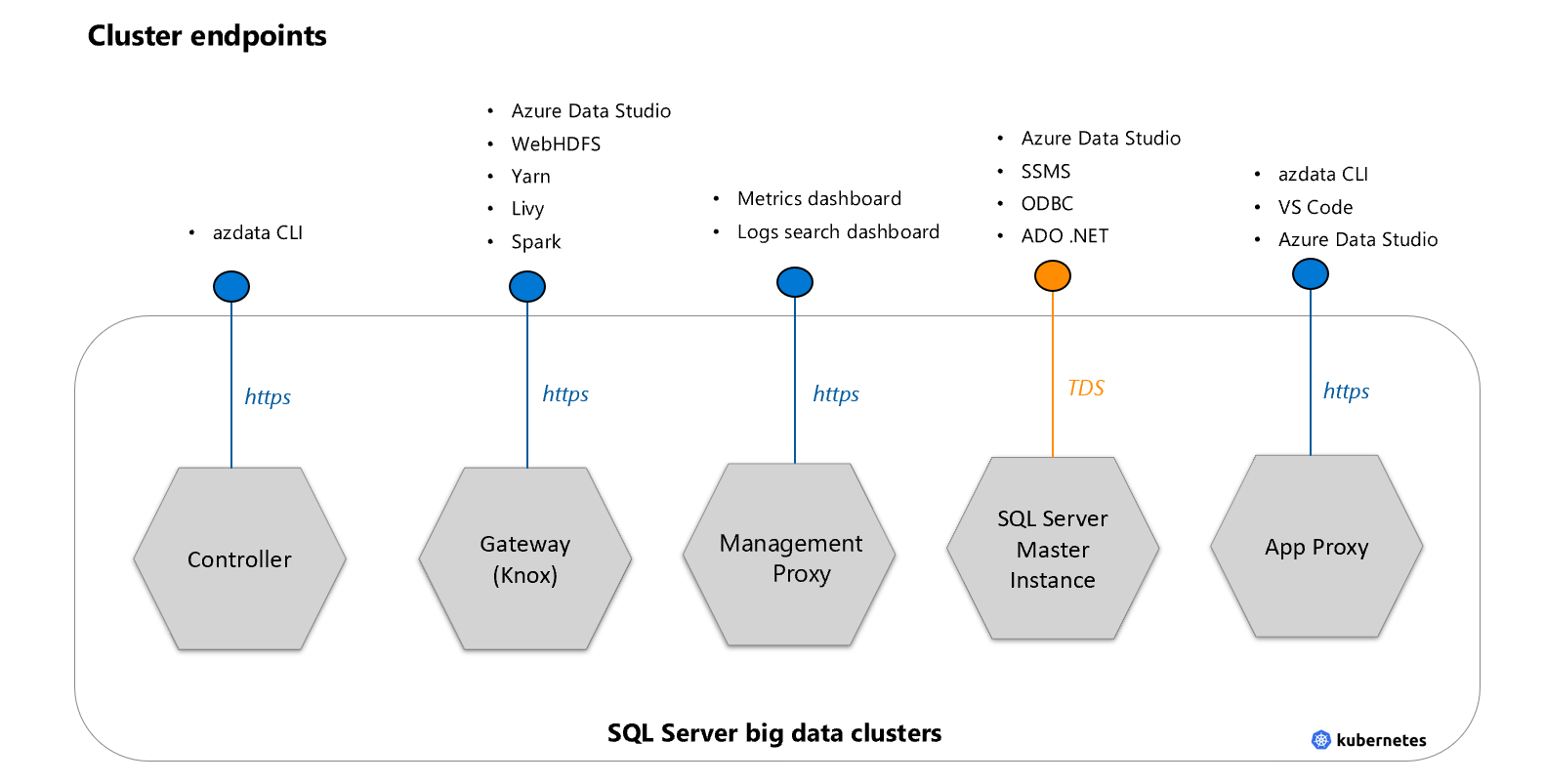
Derzeit gibt es keine Option, zusätzliche Ports zu öffnen, um von außen auf den Cluster zuzugreifen.
Authorization
Im gesamten Cluster lässt die integrierte Sicherheit zwischen verschiedenen Komponenten zu, dass die Identität des ursprünglichen Benutzers durch das Ausgeben von Abfragen von Spark und SQL Server bis hin zu HDFS übermittelt werden kann. Wie bereits erwähnt, unterstützen die verschiedenen externen Clusterendpunkte die AD-Authentifizierung.
Für die Verwaltung des Datenzugriffs gibt es im Cluster zwei Ebenen von Autorisierungsüberprüfungen. Die Autorisierung im Kontext von Big Data erfolgt in SQL Server mithilfe der herkömmlichen SQL Server-Berechtigungen für Objekte und in HDFS mit Steuerungslisten (ACLs), die Benutzeridentitäten bestimmten Berechtigungen zuordnen.
Ein sicherer Big Data-Cluster impliziert konsistente und kohärente Unterstützung für Authentifizierung- und Autorisierungsszenarien sowohl für SQL Server als auch für HDFS/Spark. Authentifizierung ist der Prozess, mit dem die Identität eines Benutzers oder Diensts überprüft und sichergestellt wird, dass der Benutzer oder Dienst das ist, was er zu sein vorgibt. Autorisierung bezieht sich auf das Gewähren oder Verweigern des Zugriffs auf bestimmte Ressourcen basierend auf der Identität des Benutzers, der den Zugriff anfordert. Dieser Schritt wird ausgeführt, nachdem ein Benutzer per Authentifizierung identifiziert wurde.
Im Big Data-Kontext erfolgt die Autorisierung über Zugriffssteuerungslisten (Access Control Lists, ACLs), die Benutzeridentitäten bestimmte Berechtigungen zuordnen. HDFS unterstützt die Autorisierung durch Einschränken des Zugriffs auf Dienst-APIs, HDFS-Dateien und die Auftragsausführung.
Verschlüsselung in Flight und andere Sicherheitsmechanismen
Die Verschlüsselung der Kommunikation zwischen Clients und externen Endpunkten sowie zwischen Komponenten innerhalb des Clusters wird mithilfe von Zertifikaten durch TLS/SSL gesichert.
Die gesamte Kommunikation zwischen SQL Server-Instanzen, wie z. B. die Kommunikation der SQL-Masterinstanz mit einem Datenpool, wird mithilfe von SQL-Anmeldungen gesichert.
Wichtig
Big Data-Cluster verwenden etcd zum Speichern von Anmeldeinformationen. Als bewährte Methode sollten Sie sicherstellen, dass Ihr Kubernetes-Cluster so konfiguriert ist, dass etcd-Verschlüsselung für ruhende Daten verwendet wird. Standardmäßig sind in etcd gespeicherte Geheimnisse unverschlüsselt. Weitere Informationen zu dieser Verwaltungsaufgabe finden Sie in der Kubernetes-Dokumentation unter https://kubernetes.io/docs/tasks/administer-cluster/kms-provider/ und https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/.
Datenverschlüsselung ruhender Daten
Die Verschlüsselungsfunktion für ruhende Daten von SQL Server Big Data-Clustern unterstützt das Kernszenario der Verschlüsselung auf Anwendungsebene für die SQL Server- und HDFS-Komponenten. Einen umfassenden Leitfaden zur Verwendung der Funktion finden Sie in dem Artikel Konzepte- und Konfigurationsleitfaden für die Verschlüsselung ruhender Daten.
Wichtig
Die Volumeverschlüsselung wird für alle SQL Server Big Data-Clusterbereitstellungen empfohlen. Vom Kunden bereitgestellte Speichervolumes, die in Kubernetes-Clustern konfiguriert wurden, sollten ebenfalls verschlüsselt werden, um einen umfassenden Ansatz bei der Verschlüsselung ruhender Daten zu verfolgen. Die Verschlüsselungsfunktion für ruhende Daten von SQL Server Big Data-Clustern ist eine zusätzliche Sicherheitsebene, die Verschlüsselung von SQL Server-Daten und -Protokolldateien auf Anwendungsebene sowie Unterstützung für HDFS-Verschlüsselungszonen bereitstellt.
Standardanmeldung für Administratoren
Sie können den Cluster entweder im AD-Modus oder nur mithilfe der Standardanmeldung für Administratoren bereitstellen. Für Administratorkontos nur eine Standardanmeldung zu verwenden, ist ein von der Produktion nicht unterstützter Sicherheitsmodus und für die Auswertung des Produkts vorgesehen.
Auch wenn Sie den Active Directory-Modus auswählen, werden Standardanmeldungen für den Clusteradministrator erstellt. Diese Funktion bietet alternativen Zugriff, falls die AD-Konnektivität unterbrochen wird.
Bei der Bereitstellung erhält diese Standardanmeldung Administratorberechtigungen im Cluster. Der Anmeldebenutzer ist der Systemadministrator in der SQL Server-Masterinstanz und ein Administrator im Clustercontroller. Hadoop-Komponenten unterstützen die Authentifizierung im gemischten Modus nicht. Dies bedeutet, dass für die Authentifizierung beim Gateway (Knox) keine Standardanmeldung für Administratoren verwendet werden kann.
Zu den Anmeldeinformationen, die Sie bei der Bereitstellung definieren müssen, gehört Folgendes:
Benutzername des Clusteradministrators:
AZDATA_USERNAME=<username>
Kennwort des Benutzeradministrators:
AZDATA_PASSWORD=<password>
Hinweis
Beachten Sie, dass der Benutzername in einem anderen als dem AD-Modus für die Authentifizierung beim Gateway (Knox) für den Zugriff auf HDFS/Spark in Kombination mit dem oben aufgeführten Kennwort verwendet werden muss. In früheren Versionen als SQL Server 2019 CU5 lautete der Benutzername root.
Beginnend mit SQL Server 2019 (15.x) CU 5 verwenden alle Endpunkte einschließlich Gateway AZDATA_USERNAME und AZDATA_PASSWORD, wenn Sie einen neuen Cluster mit Standardauthentifizierung bereitstellen. Endpunkte auf Clustern, die ein Upgrade auf CU 5 erhalten, verwenden weiterhin root als Nutzername für die Verbindung mit dem Gatewayendpunkt. Diese Änderung gilt nicht für Bereitstellungen, die die Active Directory-Authentifizierung verwenden. Weitere Informationen finden Sie unter Anmeldeinformationen für den Zugriff auf Dienste über den Gatewayendpunkt in den Versionshinweisen.
Verwalten von Schlüsselversionen
SQL Server 2019: Big Data-Cluster ermöglicht die Verwaltung von Schlüsselversionen für SQL Server und HDFS mithilfe von Verschlüsselungszonen. Weitere Informationen finden Sie unter Schlüsselversionen in Big Data-Clustern.
Nächste Schritte
Einführung in SQL Server 2019: Big Data-Cluster
Workshop: Microsoft Big Data-Cluster für SQL Server-Architektur
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für