Konfigurieren einer SQL Server Always On-Verfügbarkeitsgruppe unter Windows und Linux (plattformübergreifend)
Gilt für:![]() SQL Server 2017 (14.x) und höher
SQL Server 2017 (14.x) und höher
In diesem Artikel werden die Schritte zum Erstellen einer Always On-Verfügbarkeitsgruppe (VG) mit einem Replikat auf einem Windows-Server und dem anderen Replikat auf einem Linux-Server erläutert.
Wichtig
Plattformübergreifende SQL Server-Verfügbarkeitsgruppen, die heterogene Replikate mit vollständiger Unterstützung für Hochverfügbarkeit und Notfallwiederherstellung umfassen, sind mit DH2i DxEnterprise verfügbar. Weitere Informationen finden Sie unter SQL Server Verfügbarkeitsgruppen mit gemischten Betriebssystemen.
Im folgenden Video erfahren Sie mehr über plattformübergreifende Verfügbarkeitsgruppen mit DH2i.
Diese Konfiguration ist plattformübergreifend, da die Replikate unter unterschiedlichen Betriebssystemen ausgeführt werden. Verwenden Sie diese Konfiguration für die Migration von einer Plattform zur anderen oder zur Notfallwiederherstellung. Diese Konfiguration unterstützt keine Hochverfügbarkeit.
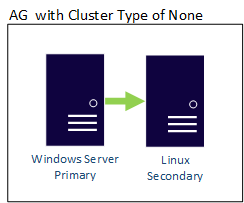
Bevor Sie fortfahren, sollten Sie mit der Installation und Konfiguration für SQL Server-Instanzen unter Windows und Linux vertraut sein.
Szenario
In diesem Szenario werden zwei Server unter verschiedenen Betriebssystemen ausgeführt. Auf einem Computer mit Windows Server 2022 namens WinSQLInstance wird das primäre Replikat gehostet. Auf einem Linux-Server namens LinuxSQLInstance wird das sekundäre Replikat gehostet.
Konfigurieren der Verfügbarkeitsgruppe
Die Schritte zum Erstellen der Verfügbarkeitsgruppe sind identisch mit den Schritten zum Erstellen einer Verfügbarkeitsgruppe für Workloads mit Leseskalierung. Die Verfügbarkeitsgruppe weist den Clustertyp NONE auf, weil kein Cluster-Manager vorhanden ist.
Hinweis
In den Skripts in diesem Artikel werden Werte, die Sie Ihrer Umgebung entsprechend ersetzen müssen, in spitzen Klammern (< und >) angegeben. Die spitzen Klammern selbst sind für die Skripts nicht erforderlich.
Installieren Sie SQL Server 2022 (16.x) unter Windows Server 2022, aktivieren Sie Always On-Verfügbarkeitsgruppen von SQL Server-Konfigurations-Manager, und legen Sie die Authentifizierung im gemischten Modus fest.
Tipp
Wenn Sie diese Lösung in Azure überprüfen, fügen Sie beide Server in dieselbe Verfügbarkeitsgruppe ein, damit sie im Rechenzentrum voneinander getrennt werden.
Aktivieren von Verfügbarkeitsgruppen
Anweisungen hierzu finden Sie unter Aktivieren und Deaktivieren von Always On-Verfügbarkeitsgruppen (SQL Server).
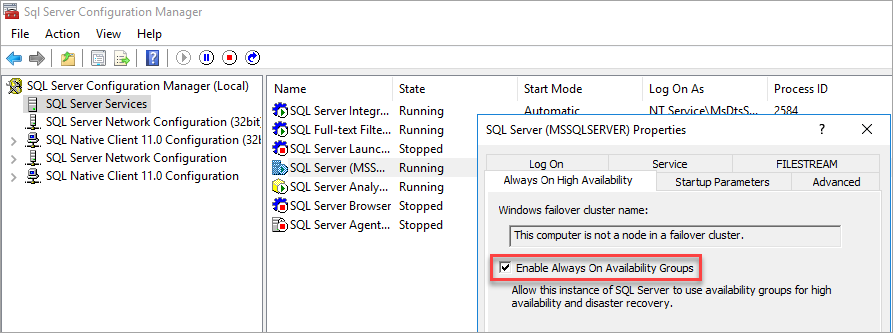
Der SQL Server-Konfigurations-Manager erkennt, dass es sich bei dem Computer nicht um einen Knoten in einem Failovercluster handelt.
Nachdem Sie Verfügbarkeitsgruppen aktiviert haben, starten Sie SQL Server neu.
Festlegen der Authentifizierung im gemischten Modus
Anweisungen hierzu finden Sie unter Ändern des Serverauthentifizierungsmodus.
Installieren von SQL Server 2022 (16.x) unter Linux Anweisungen hierzu finden Sie unter Installieren von SQL Server. Aktivieren Sie
hadrmit mssql-conf.Um
hadrmit dem Befehl mssql-conf über eine Shelleingabeaufforderung zu aktivieren, geben Sie den folgenden Befehl ein:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Nachdem Sie
hadraktiviert haben, starten Sie die SQL Server-Instanz neu:sudo systemctl restart mssql-server.serviceKonfigurieren Sie die
hosts-Datei auf beiden Servern, oder registrieren Sie die Servernamen bei DNS.Öffnen Sie Firewallports für TCP 1433 und 5022 unter Windows und Linux.
Erstellen Sie auf dem primären Replikat einen Anmeldenamen und ein Kennwort für die Datenbank.
CREATE LOGIN dbm_login WITH PASSWORD = '<C0m9L3xP@55w0rd!>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOErstellen Sie auf dem primären Replikat einen Hauptschlüssel und ein Zertifikat, und sichern Sie das Zertifikat mit einem privaten Schlüssel.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<C0m9L3xP@55w0rd!>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<C0m9L3xP@55w0rd!>' ); GOKopieren Sie das Zertifikat und den privaten Schlüssel auf den Linux-Server (sekundäres Replikat) unter
/var/opt/mssql/data. Sie könnenpscpverwenden, um die Dateien auf den Linux-Server zu kopieren.Legen Sie die Gruppe und den Besitz des privaten Schlüssels und des Zertifikats auf
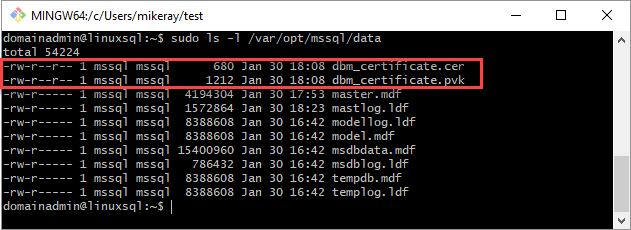
mssql:mssqlfest.Mit dem folgenden Skript werden die Gruppe und der Besitz der Dateien festgelegt.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerIn der folgenden Abbildung sind Besitz und Gruppe für Zertifikat und Schlüssel ordnungsgemäß festgelegt.
Erstellen Sie auf dem sekundären Replikat einen Anmeldenamen und ein Kennwort für die Datenbank, und erstellen Sie einen Hauptschlüssel.
CREATE LOGIN dbm_login WITH PASSWORD = '<C0m9L3xP@55w0rd!>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<M@st3rKeyP@55w0rD!>' GOStellen Sie auf dem sekundären Replikat das Zertifikat wieder her, das Sie in
/var/opt/mssql/datakopiert haben.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<C0m9L3xP@55w0rd!>' ) GOErstellen Sie auf dem primären Replikat einen Endpunkt.
CREATE ENDPOINT [Hadr_endpoint] AS TCP (LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022) FOR DATA_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GOWichtig
Die Firewall muss für den TCP-Listenerport geöffnet sein. Im vorherigen Skript wird Port 5022 verwendet. Verwenden Sie einen beliebigen verfügbaren TCP-Port.
Erstellen Sie den Endpunkt auf dem sekundären Replikat. Wiederholen Sie das vorherige Skript auf dem sekundären Replikat, um den Endpunkt zu erstellen.
Erstellen Sie auf dem primären Replikat die Verfügbarkeitsgruppe mit
CLUSTER_TYPE = NONE. Im Beispielskript wirdSEEDING_MODE = AUTOMATICverwendet, um die Verfügbarkeitsgruppe zu erstellen.Hinweis
Wenn die Windows-Instanz von SQL Server unterschiedliche Pfade für Daten- und Protokolldateien verwendet, schlägt das automatische Seeding für die Linux-Instanz von SQL Server fehl, da diese Pfade auf dem sekundären Replikat nicht vorhanden sind. Damit das folgende Skript für eine plattformübergreifende Verfügbarkeitsgruppe verwendet werden kann, muss in der Datenbank für die Daten- und Protokolldateien auf dem Windows-Server derselbe Pfad angegeben werden. Alternativ können Sie das Skript so aktualisieren, dass
SEEDING_MODE = MANUALfestgelegt wird, und anschließend die Datenbank mitNORECOVERYsichern und wiederherstellen, um für die Datenbank ein Seeding auszuführen.Dieses Verhalten gilt für Azure Marketplace-Images.
Weitere Informationen zum automatischen Seeding finden Sie unter Automatisches Seeding – Datenträgerlayout.
Aktualisieren Sie vor dem Ausführen des Skripts die Werte für Ihre Verfügbarkeitsgruppen.
Ersetzen Sie
<WinSQLInstance>durch den Servernamen der SQL Server-Instanz des primären Replikats.Ersetzen Sie
<LinuxSQLInstance>durch den Servernamen der SQL Server-Instanz des sekundären Replikats.
Aktualisieren Sie zum Erstellen der Verfügbarkeitsgruppe die Werte, und führen Sie das Skript auf dem primären Replikat aus.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); ) GOWeitere Informationen finden Sie unter CREATE AVAILABILITY GROUP (Transact-SQL).
Verknüpfen Sie die Verfügbarkeitsgruppe auf dem sekundären Replikat.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOErstellen Sie eine Datenbank für das sekundäre Replikat. In den Beispielschritten wird eine Datenbank mit dem Namen
TestDBverwendet. Wenn Sie das automatische Seeding verwenden, legen Sie für die Daten- und die Protokolldateien denselben Pfad fest.Aktualisieren Sie vor dem Ausführen des Skripts die Werte für die Datenbank.
Ersetzen Sie
TestDBdurch den Namen Ihrer Datenbank.Ersetzen Sie
<F:\Path>durch den Pfad der Datenbank und der Protokolldateien. Verwenden Sie für die Datenbank- und Protokolldateien denselben Pfad.
Sie können auch die Standardpfade verwenden.
Führen Sie das Skript aus, um die Datenbank zu erstellen.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON ( NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOErstellen Sie eine vollständige Sicherung der Datenbank.
Wenn Sie kein automatisches Seeding verwenden, stellen Sie die Datenbank auf dem sekundären Replikatserver (Linux) wieder her. Migrieren einer SQL Server-Datenbank von Windows zu Linux mithilfe der Funktion Sichern und Wiederherstellen Stellen Sie die Datenbank
WITH NORECOVERYauf dem sekundären Replikat wieder her.Fügen Sie die Datenbank der Verfügbarkeitsgruppe hinzu. Aktualisieren Sie das Beispielskript. Ersetzen Sie
TestDBdurch den Namen Ihrer Datenbank. Führen Sie auf dem primären Replikat die T-SQL-Abfrage aus, um der Verfügbarkeitsgruppe die Datenbank hinzuzufügen.ALTER AG [ag1] ADD DATABASE TestDB; GOStellen Sie sicher, dass die Datenbank auf dem sekundären Replikat aufgefüllt wird.
Ausführen eines Failovers für das primäre Replikat
Jede Verfügbarkeitsgruppe hat nur ein primäres Replikat. Das primäre Replikat lässt Lese- und Schreibvorgänge zu. Sie können ein Failover ausführen, um das primäre Replikat zu ändern. In einer typischen Verfügbarkeitsgruppe automatisiert der Cluster-Manager den Failoverprozess. In einer Verfügbarkeitsgruppe mit dem Clustertyp „NONE“ erfolgt der Failovervorgang manuell.
Es gibt zwei Möglichkeiten, ein Failover für ein primäres Replikat in einer Verfügbarkeitsgruppe mit dem Clustertyp „NONE“ auszuführen:
- Manuelles Failover ohne Datenverlust
- Erzwungenes manuelles Failover mit Datenverlust
Manuelles Failover ohne Datenverlust
Verwenden Sie diese Methode, wenn das primäre Replikat verfügbar ist. Dabei müssen Sie allerdings vorübergehend oder dauerhaft ändern, welche Instanz das primäre Replikat hostet. Um potenzielle Datenverluste zu vermeiden, stellen Sie vor der Ausführung eines manuellen Failovers sicher, dass das sekundäre Zielreplikat aktuell ist.
So führen ein manuelles Failover ohne Datenverlust aus:
Verwenden Sie
SYNCHRONOUS_COMMITfür das aktuelle primäre Replikat und das sekundäre Zielreplikat.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Um zu ermitteln, ob für aktive Transaktionen ein Commit auf das primäre Replikat und gleichzeitig auf mindestens ein synchrones sekundäres Replikat ausgeführt wurde, führen Sie die folgende Abfrage aus:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;Das sekundäre Replikat wird synchronisiert, wenn
synchronization_state_descSYNCHRONIZEDist.Aktualisieren Sie
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITauf 1.Das folgende Skript legt
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITauf „1“ für eine Verfügbarkeitsgruppe mit dem Namenag1fest. Ersetzen Sieag1vor der Ausführung des Skripts durch den Namen Ihrer Verfügbarkeitsgruppe:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Diese Einstellung stellt sicher, dass für jede aktive Transaktion ein Commit auf das primäre Replikat und auf mindestens ein synchrones sekundäres Replikat ausgeführt wurde.
Hinweis
Diese Einstellung ist nicht failoverspezifisch und sollte anhand der Umgebungsanforderungen festgelegt werden.
Legen Sie zur Vorbereitung auf die Rollenänderung das primäre Replikat und die sekundären Replikate, die nicht am Failover beteiligt sind, offline fest:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEStufen Sie das sekundäre Zielreplikat auf ein primäres hoch.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Aktualisieren Sie die Rolle des alten primären Replikats und weiterer sekundärer Replikate auf
SECONDARY, und führen Sie den folgenden Befehl auf der SQL Server-Instanz aus, die das alte primäre Replikat hostet:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Hinweis
Verwenden Sie DROP AVAILABILITY GROUP (Verfügbarkeitsgruppe löschen), um eine Verfügbarkeitsgruppe zu löschen. Führen Sie bei Verfügbarkeitsgruppen, die mit dem Clustertyp „NONE“ oder „EXTERNAL“ erstellt wurden, den Befehl für alle Replikate aus, die der Verfügbarkeitsgruppe angehören.
Setzen Sie die Datenverschiebung fort, und führen Sie folgenden Befehl für jede Datenbank in der Verfügbarkeitsgruppe auf der SQL Server-Instanz aus, die das primäre Replikat hostet:
ALTER DATABASE [db1] SET HADR RESUMEErstellen Sie jeden Listener neu, den Sie für Leseskalierungszwecke erstellt haben und der nicht von einem Cluster-Manager verwaltet wird. Wenn der ursprüngliche Listener auf das alte primäre Replikat zeigt, löschen Sie ihn, und erstellen Sie ihn neu, um auf das neue primäre Replikat zu verweisen.
Erzwungenes manuelles Failover mit Datenverlust
Wenn das primäre Replikat nicht verfügbar ist und nicht sofort wieder hergestellt werden kann, müssen Sie ein Failover auf das sekundäre Replikat mit Datenverlust erzwingen. Wenn das ursprüngliche primäre Replikat jedoch nach einem Failover wieder hergestellt wird, nimmt es die primäre Rolle an. Um zu vermeiden, dass jedes Replikat einen anderen Zustand aufweist, entfernen Sie das ursprüngliche primäre Replikat nach einem erzwungenen Failover mit Datenverlust aus der Verfügbarkeitsgruppe. Wenn das ursprüngliche primäre Replikat wieder online ist, entfernen Sie die Verfügbarkeitsgruppe vollständig.
Gehen Sie folgendermaßen vor, um ein manuelles Failover mit Datenverlust vom primären Replikat N1 zum sekundären Replikat N2 zu erzwingen:
Initiieren Sie auf dem sekundären Replikat (N2) das erzwungene Failover:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;Entfernen Sie auf dem neuen primären Replikat (N2) das ursprüngliche primäre Replikat (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Überprüfen Sie, ob der gesamte Anwendungsdatenverkehr auf den Listener und/oder das neue primäre Replikat verweist.
Wenn das ursprüngliche primäre Replikat (N1) online geschaltet wird, schalten Sie die Verfügbarkeitsgruppe „AGRScale“ auf der ursprünglichen primären Datenbank (N1) offline:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEWenn Daten oder nicht synchronisierte Änderungen vorhanden sind, behalten Sie diese Datei über Sicherungskopien oder andere Datenreplikationsoptionen bei, die Ihren Geschäftsanforderungen entsprechen.
Entfernen Sie als Nächstes die Verfügbarkeitsgruppe aus der ursprünglichen primären Datenbank (N1):
DROP AVAILABILITY GROUP [AGRScale];Löschen Sie die Datenbank der Verfügbarkeitsgruppe auf dem ursprünglichen primären Replikat (N1):
USE [master] GO DROP DATABASE [AGDBRScale] GO(Optional) Sie können, wenn gewünscht, N1 jetzt wieder als neues sekundäres Replikat der Verfügbarkeitsgruppe „AGRScale“ hinzufügen.
In diesem Artikel wurden die Schritte zum Erstellen einer plattformübergreifenden Verfügbarkeitsgruppe zur Unterstützung der Migration oder von Workloads mit Leseskalierung beschrieben. Dieser Artikel kann für die manuelle Notfallwiederherstellung verwendet werden. In diesem Artikel wurde zudem erläutert, wie für die Verfügbarkeitsgruppe ein Failover ausgeführt wird. Eine plattformübergreifende Verfügbarkeitsgruppe verwendet den Clustertyp NONE und unterstützt keine Hochverfügbarkeit.
Zugehöriger Inhalt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für