CREATE EXTERNAL TABLE (Transact-SQL)
Erstellt eine externe Tabelle.
Dieser Artikel stellt die Syntax, Argumente, Anweisungen, Berechtigungen und Beispiele für das SQL-Produkt Ihrer Wahl bereit.
Weitere Informationen zu Syntaxkonventionen finden Sie unter Transact-SQL-Syntaxkonventionen.
Auswählen eines Produkts
Wählen Sie in der folgenden Zeile den Namen des Produkts aus, an dem Sie interessiert sind. Dann werden nur Informationen zu diesem Produkt angezeigt.
* SQL Server *
Übersicht: SQL Server
Dieser Befehl erstellt eine externe Tabelle für PolyBase, um auf Daten in einem Hadoop-Cluster oder in Azure Blob Storage zuzugreifen. Eine externe PolyBase-Tabelle, die auf Daten in einem Hadoop-Cluster oder in Azure Blob Storage verweist.
Gilt für: SQL Server 2016 (oder höher)
Verwendet eine externe Tabelle mit einer externen Datenquelle für PolyBase-Abfragen. Externe Datenquellen werden zum Herstellen von Verbindungen verwendet und unterstützen diese primären Anwendungsfälle:
- Datenvirtualisierung und Laden von Dateien mithilfe von PolyBase
- Massenladevorgänge mit SQL Server oder SQL-Datenbank mithilfe von
BULK INSERToderOPENROWSET
Siehe auch CREATE EXTERNAL DATA SOURCE und DROP EXTERNAL TABLE.
Syntax
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumente
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Ein- bis dreiteiliger Name der Tabelle, die erstellt werden soll. Für eine externe Tabelle speichert SQL nur die Metadaten der Tabelle mit den grundlegenden Statistiken über die Datei oder den Ordner, auf die in Hadoop oder Azure Blob Storage verwiesen wird. Es werden keine tatsächlichen Daten in SQL Server verschoben oder gespeichert.
Wichtig
Wenn der externe Datenquellentreiber einen dreiteiligen Namen unterstützt, wird dringend empfohlen, diesen dreiteiligen Namen anzugeben, um eine optimale Leistung zu erzielen.
<column_definition> [ ,...n ]
„CREATE EXTERNAL TABLE“ unterstützt das Konfigurieren von Spaltenname, Datentyp, NULL-Zulässigkeit und Sortierung. Sie können DEFAULT CONSTRAINT nicht für externe Tabellen verwenden.
Die Spaltendefinitionen, einschließlich der Datentypen und der Anzahl der Spalten, müssen mit den Daten in den externen Dateien übereinstimmen. Wenn ein Konflikt besteht, werden die Zeilen der Datei beim Abfragen der tatsächlichen Daten zurückgewiesen.
LOCATION = 'folder_or_filepath'
Gibt den Ordner oder den Dateipfad und Dateinamen für die tatsächlichen Daten in Hadoop oder Azure Blob Storage an. Ab SQL Server 2022 (16.x) wird außerdem S3-kompatibler Objektspeicher unterstützt. Der Speicherort beginnt im Stammordner. Der Stammordner ist der in der externen Datenquelle angegebene Datenspeicherort.
In SQL Server erstellt die Anweisung CREATE EXTERNAL TABLE den Pfad und den Ordner, wenn diese noch nicht vorhanden sind. Sie können dann INSERT INTO zum Exportieren von Daten aus einer lokalen SQL Server-Tabelle in die externe Datenquelle verwenden. Weitere Informationen finden Sie unter PolyBase-Abfragen.
Wenn LOCATION als Ordner angegeben wird, ruft eine PolyBase-Abfrage, die aus der externen Tabelle auswählt, Dateien aus dem Ordner und allen Unterordnern ab. PolyBase gibt wie Hadoop keine ausgeblendeten Ordner zurück. Es werden auch keine Dateien zurückgegeben, deren Dateiname mit einem Unterstrich (_) oder einem Punkt (.) beginnt.
Wenn LOCATION='/webdata/', gibt eine PolyBase-Abfrage im folgenden Beispielbild Zeilen aus mydata.txt und mydata2.txt zurück. mydata3.txt wird nicht zurückgegeben, da es sich um eine Datei eines ausgeblendeten Unterordners handelt. Und _hidden.txt wird nicht zurückgegeben, da es sich um eine ausgeblendete Datei handelt.
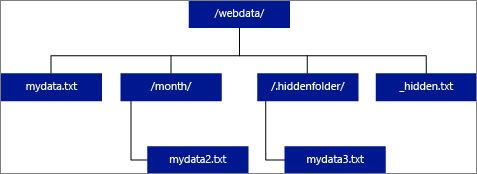
Legen Sie das Attribut <polybase.recursive.traversal> in der Konfigurationsdatei „core-site.xml“ auf FALSE fest, um den Standardordner zu ändern und nur aus dem Stammordner zu lesen. Diese Datei befindet sich unter <SqlBinRoot>\PolyBase\Hadoop\Conf unter dem bin-Stammverzeichnis von SQL Server. Beispielsweise C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Gibt den Namen der externen Datenquelle an, die den Speicherort der externen Daten enthält. Bei diesem Speicherort handelt es sich um ein Hadoop-Dateisystem (HDFS), einen Azure Blob Storage-Container oder Azure Data Lake Store. Verwenden Sie zum Erstellen einer externen Datenquelle CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Gibt den Namen des externen Dateiformatobjekts an, das den Dateityp und die Komprimierungsmethode der externen Daten speichert. Verwenden Sie zum Erstellen eines externen Dateiformats CREATE EXTERNAL FILE FORMAT.
Externe Dateiformate können von mehreren ähnlichen externen Dateien wiederverwendet werden.
Reject-Optionen
Diese Option kann nur mit externen Datenquellen verwendet werden, die den Typ Hadoop aufweisen.
Sie können Reject-Parameter angeben, die bestimmen, wie PolyBase modifizierte Datensätze behandelt, die aus der externen Datenquelle abgerufen werden. Ein Datensatz gilt als „dirty“ (modifiziert), wenn die tatsächlichen Datentypen oder die Anzahl der Spalten nicht den Spaltendefinitionen der externen Tabelle entsprechen.
Wenn Sie die Reject-Werte nicht angeben oder ändern, verwendet PolyBase Standardwerte. Diese Informationen über die Reject-Parameter werden als zusätzliche Metadaten gespeichert, wenn Sie eine externe Tabelle mit der CREATE EXTERNAL TABLE-Anweisung erstellen. Wenn eine zukünftige SELECT- oder SELECT INTO SELECT-Anweisung Daten aus der externen Tabelle auswählt, wird PolyBase die Reject-Optionen verwenden, um die Anzahl oder den Prozentsatz der Zeilen zu bestimmen, die zurückgewiesen werden können, bevor die tatsächliche Abfrage fehlschlägt. Die Abfrage gibt (Teil-) Ergebnisse zurück, bis der Reject-Schwellenwert überschritten wird. Daraufhin wird eine entsprechende Fehlermeldung ausgelöst.
REJECT_TYPE = value | percentage
Gibt an, ob die Option „REJECT_VALUE“ als Literalwert oder als Prozentsatz angegeben wird.
value
REJECT_VALUE ist ein Literalwert und kein Prozentsatz. Die Abfrage schlägt fehl, wenn die Anzahl der abgelehnten Zeilen reject_value überschreitet.
Die SELECT-Abfrage schlägt beispielsweise bei REJECT_VALUE = 5 und REJECT_TYPE = value fehl, nachdem fünf Zeilen abgelehnt wurden.
Prozentwert
REJECT_VALUE ist ein Prozentsatz und kein Literalwert. Eine Abfrage schlägt fehl, wenn der Prozentsatz fehlerhafter Zeilen reject_value überschreitet. Der Prozentsatz der fehlerhaften Zeilen wird in Intervallen berechnet.
REJECT_VALUE = reject_value
Gibt den Wert oder den Prozentsatz der Zeilen an, die zurückgewiesen werden können, bevor die Abfrage fehlschlägt.
Wenn REJECT_TYPE = Wert, muss reject_value eine ganze Zahl zwischen 0 und 2.147.483.647 sein.
Wenn REJECT_TYPE = Prozentzahl, muss reject_value eine Gleitkommazahl zwischen 0 und 100 sein.
REJECT_SAMPLE_VALUE = reject_sample_value
Dieses Attribut ist erforderlich, wenn Sie REJECT_TYPE = Prozentsatz angeben. Bestimmt die Anzahl der Zeilen, bei denen versucht wird, sie abzurufen, bevor die PolyBase den Prozentsatz der abgelehnten Zeilen neu berechnet.
Der reject_sample_value-Parameter muss eine ganze Zahl zwischen 0 und 2.147.483.647 sein.
Ist beispielsweise REJECT_SAMPLE_VALUE = 1000, dann berechnet PolyBase den Prozentsatz von fehlerhaften Zeilen nach dem Importversuch von 1000 Zeilen aus der externen Datendatei. Ist der Prozentsatz von fehlerhaften Zeilen kleiner als reject_value, führt PolyBase einen erneuten Abrufversuch von 1000 Zeilen aus. Nach jedem weiteren Importversuch von 1000 Zeilen wird der Prozentsatz von fehlerhaften Zeilen weiterhin neu berechnet.
Hinweis
Da die Berechnung des Prozentsatzes von fehlerhaften Zeilen durch PolyBase in Intervallen erfolgt, kann der tatsächliche Prozentsatz fehlerhafter Zeilen reject_value überschreiten.
Beispiel:
In diesem Beispiel wird verdeutlicht, wie die drei REJECT-Optionen interagieren. Gilt beispielsweise REJECT_TYPE = Prozentsatz, REJECT_VALUE = 30 und REJECT_SAMPLE_VALUE = 100, dann könnte das folgende Szenario auftreten:
- PolyBase versucht, die ersten 100 Zeilen abzurufen. Davon sind 25 fehlerhaft und 75 erfolgreich.
- Der berechnete Prozentsatz fehlerhafter Zeilen ist mit 25 % kleiner als der REJECT-Wert von 30 %. Aus diesem Grund wird PolyBase weiterhin versuchen, Daten aus der externen Datenquelle abzurufen.
- PolyBase versucht, die nächsten 100 Zeilen zu laden. Dieses Mal sind 25 Zeilen erfolgreich und 75 Zeilen fehlerhaft.
- Der Prozentsatz fehlerhafter Zeilen wird mit 50 % neu berechnet. Der Prozentsatz fehlerhafter Zeilen hat den REJECT-Wert von 30 % überschritten.
- Die PolyBase-Abfrage schlägt fehl, da nach der Rückgabe der ersten 200 Zeilen 50 % der Zeilen abgelehnt werden. Beachten Sie, dass übereinstimmende Zeilen zurückgegeben wurden, bevor die PolyBase-Abfrage erkennt, dass der Schwellenwert zum Zurückweisen überschritten wurde.
REJECTED_ROW_LOCATION = Verzeichnis
Gilt für: SQL Server ab Version 2019 CU6, Azure Synapse Analytics.
Gibt das Verzeichnis in der externen Datenquelle an, in das die abgelehnten Zeilen und die entsprechende Fehlerdatei geschrieben werden sollen.
Ist das angegebene Verzeichnis nicht vorhanden, wird es von PolyBase für Sie erstellt. Es wird ein untergeordnetes Verzeichnis mit dem Namen „_rejectedrows“ erstellt. Mit dem Unterstrich (_) wird sichergestellt, dass das Verzeichnis für andere Datenverarbeitungsvorgänge übergangen wird, es sei denn, es ist explizit im LOCATION-Parameter angegeben. In diesem Verzeichnis befindet sich ein Ordner, der ausgehend von der Zeit der Lastübermittlung im Format YearMonthDay -HourMinuteSecond erstellt wurde (z. B. 20230330-173205). In diesen Ordner werden zwei Arten von Dateien geschrieben: die Ursachendatei (_reason-Datei) und die Datendatei. Diese Option kann nur mit externen Datenquellen verwendet werden, bei denen gilt: TYPE = HADOOP und für externe Tabellen DELIMITEDTEXT FORMAT_TYPE. Weitere Informationen finden Sie unter CREATE EXTERNAL DATA SOURCE und unter CREATE EXTERNAL FILE FORMAT.
Sowohl die Ursachendateien als auch die Datendateien haben die „queryID“, die der CTAS-Anweisung zugeordnet ist. Da die Daten und die Ursachen in getrennten Dateien gespeichert sind, haben die zugehörigen Dateien ein entsprechendes Suffix.
Berechtigungen
Folgende Benutzerberechtigungen sind erforderlich:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT (gilt nur für externe Datenquellen von Hadoop und Azure Storage)
- CONTROL DATABASE (gilt nur für Datenquellen von Hadoop und Azure Storage)
Beachten Sie, dass die in DATABASE SCOPED CREDENTIAL angegebene Remoteanmeldung, die im Befehl CREATE EXTERNAL TABLE verwendet wird, über Leseberechtigungen für den Pfad/die Tabelle/die Sammlung der im LOCATION-Parameter angegebenen externen Datenquelle verfügen muss. Wenn Sie diese EXTERNE TABELLE verwenden möchten, um Daten in eine externe Datenquelle von Hadoop oder Azure Storage zu exportieren, muss die angegebene Anmeldung über Schreibberechtigungen auf dem in LOCATION angegebenen Pfad verfügen. Beachten Sie, dass Hadoop in SQL Server 2022 (16.x) derzeit nicht unterstützt wird.
Für Azure Blob Storage gilt, dass Sie beim Konfigurieren von Zugriffstasten und SAS (Shared Access Signature) im Azure-Portal für die Azure Blob Storage- oder ADLS Gen2-Speicherkonten die Zulässigen Berechtigungen so konfigurieren, dass mindestens Lese- und Schreibberechtigungen gewährt werden. Die Berechtigung Liste ist möglicherweise auch für ordnerübergreifende Suchen erforderlich. Zudem müssen Sie sowohl Container als auch Objekt als zulässige Ressourcentypen auswählen.
Wichtig
Mit der Berechtigung ALTER ANY EXTERNAL DATA SOURCE besitzt jeder Prinzipal die Fähigkeit, beliebige externe Datenquellenobjekte zu erstellen und zu ändern. Damit ist auch der Zugriff auf alle datenbankweit gültigen Anmeldeinformationen der Datenbank möglich. Da es sich hierbei um eine weitreichende Berechtigung handelt, darf sie nur vertrauenswürdigen Prinzipalen innerhalb des Systems erteilt werden.
Fehlerbehandlung
Beim Ausführen der CREATE EXTERNAL TABLE-Anweisung versucht PolyBase, eine Verbindung mit der externen Datenquelle herzustellen. Tritt bei der Verbindung ein Fehler auf, schlägt die Anweisung fehl. Die externe Tabelle wird nicht erstellt. Da PolyBase erneut versucht, die Verbindung aufzubauen, bevor die Abfrage endgültig fehlschlägt, kann es eine Minute oder länger dauern, bis der Befehl fehlschlägt.
Bemerkungen
In Szenarien mit Ad-hoc-Abfragen, z. B. SELECT FROM EXTERNAL TABLE, speichert PolyBase die aus der externen Datenquelle abgerufenen Zeilen in einer temporären Tabelle. Nachdem die Abfrage abgeschlossen ist, entfernt und löscht PolyBase die temporäre Tabelle. Es werden keine permanenten Daten in SQL-Tabellen gespeichert.
Im Gegensatz dazu speichert PolyBase die aus der externen Datenquelle abgerufenen Zeilen in Importszenarios, z.B. bei SELECT INTO FROM EXTERNAL TABLE, permanent in einer SQL-Tabelle. Die neue Tabelle wird beim Ausführen der Abfrage erstellt, wenn PolyBase die externen Daten abruft.
PolyBase kann einen Teil der Abfrageberechnung an Hadoop übertragen, um die Abfrageleistung zu verbessern. Diese Aktion wird als Prädikatweitergabe bezeichnet. Um sie zu aktivieren, geben Sie die Option „Resource Manager Location“ von Hadoop in CREATE EXTERNAL DATA SOURCE an.
Sie können zahlreiche externe Tabellen erstellen, die auf die gleichen oder andere externe Datenquellen verweisen.
Einschränkungen
Da die Daten für eine externe Tabelle nicht direkt von SQL Server verwaltet und gesteuert werden, können die Daten jederzeit von einem externen Prozess geändert oder entfernt werden. Aus diesem Grund sind Abfrageergebnisse für eine externe Tabelle nicht garantiert deterministisch. Die gleiche Abfrage kann bei jeder Ausführung für eine externe Tabelle unterschiedliche Ergebnisse zurückgeben. Auf ähnliche Weise kann eine Abfrage fehlschlagen, wenn die externen Daten verschoben oder entfernt werden.
Sie können zahlreiche externe Tabellen erstellen, die alle auf unterschiedliche externe Datenquellen verweisen. Wenn Sie Abfragen für verschiedene Hadoop-Datenquellen gleichzeitig ausführen, muss jede Hadoop-Datenquelle die gleiche „Hadoop Connectivity“-Serverkonfigurationseinstellung verwenden. Beispielsweise können Sie nicht gleichzeitig eine Abfrage für einen Cloudera Hadoop-Cluster und einen Hortonworks Hadoop-Cluster ausführen, da diese unterschiedliche Konfigurationseinstellungen verwenden. Weitere Informationen zu den Konfigurationseinstellungen und den unterstützten Kombinationen finden Sie unter Konfiguration der PolyBase-Netzwerkkonnektivität.
Wenn die externe Tabelle DELIMITEDTEXT, CSV, PARQUET oder DELTA als Datentypen verwendet, unterstützt externe Tabellen nur Statistiken für eine Spalte pro CREATE STATISTICS-Befehl.
Nur diese DDL-Anweisungen (Data Definition Language) sind in externen Tabellen zulässig:
- CREATE TABLE und DROP TABLE
- CREATE STATISTICS und DROP STATISTICS
- CREATE VIEW und DROP VIEW
Nicht unterstützte Konstruktionen und Operationen:
- Die DEFAULT-Einschränkung auf externen Tabellenspalten
- DML-Vorgänge (Data Manipulation Language): DELETE, INSERT und UPDATE
Abfrageeinschränkungen
PolyBase kann bei 32 gleichzeitigen PolyBase-Abfragen maximal 33.000 Dateien pro Ordner verarbeiten. Diese maximale Anzahl schließt sowohl Dateien als auch Unterordner im jeweiligen HDFS-Ordner ein. Werden weniger als 32 Abfragen gleichzeitig ausgeführt, können auch PolyBase-Abfragen für Ordner in HDFS ausgeführt werden, die mehr als 33.000 Dateien enthalten. Es wird empfohlen, dass Sie externe Dateipfade kurz halten und nicht mehr als 30.000 Dateien pro HDFS-Ordner verwenden. Wenn auf zu viele Dateien verwiesen wird, kann eine Out-of-Memory-Ausnahme von Java Virtual Machine (JVM) auftreten.
Einschränkungen der Tabellenbreite
PolyBase in SQL Server 2016 verfügt über eine Begrenzung für die Zeilenbreite von 32 KB, basierend auf der Maximalgröße einer einzelnen gültigen Zeile je Tabellendefinition. Wenn die Summe des Spaltenschemas größer als 32 KB ist, kann PolyBase die Daten nicht abfragen.
Einschränkungen für Datentypen
Die folgenden Datentypen können nicht in externen PolyBase-Tabellen verwendet werden:
geographygeometryhierarchyidimagetextnTextxml- Jeder benutzerdefinierte Typ
Datenquellenspezifische Einschränkungen
Oracle
Oracle-Synonyme werden für die Verwendung mit PolyBase nicht unterstützt.
Externe Tabellen zu MongoDB-Sammlungen, die Arrays enthalten
Um externe Tabellen für MongoDB-Sammlungen zu erstellen, die Arrays enthalten, sollten Sie die Datenvirtualisierungserweiterung für Azure Data Studio verwenden, um eine CREATE EXTERNAL TABLE-Anweisung basierend auf dem Schema zu erstellen, das vom ODBC-Treiber in PolyBase für MongoDB erkannt wurde. Die Aktionen zur Vereinfachung werden automatisch vom Treiber ausgeführt. Alternativ können Sie sp_data_source_objects (Transact-SQL) verwenden, um das Sammlungsschema (Spalten) zu erkennen und die externe Tabelle manuell zu erstellen. Die gespeicherte Prozedur sp_data_source_table_columns führt auch automatisch die Vereinfachung über den ODBC-Treiber in PolyBase für MongoDB-Treiber aus. Die Datenvirtualisierungserweiterung für Azure Data Studio und sp_data_source_table_columns verwenden dieselben internen gespeicherten Prozeduren, um das externe Schema abzufragen.
Sperren
Freigegebene Sperre für das SCHEMARESOLUTION-Objekt.
Sicherheit
Die Datendateien für eine externe Tabelle werden in Hadoop oder Azure Blob Storage gespeichert. Diese Datendateien werden von Ihrem eigenen Prozess erstellt und verwaltet. Die Sicherheit der externen Daten liegt in Ihrer Verantwortung.
Beispiele
A. Erstellen einer externen Tabelle mit Daten im Texttrennzeichenformat
Dieses Beispiel zeigt die erforderlichen Schritte zur Erstellung einer externen Tabelle, die Daten in Texttrennzeichendateien formatiert. Es definiert eine externe Datenquelle mydatasource und ein externes Dateiformat myfileformat. In der CREATE EXTERNAL TABLE-Anweisung wird dann auf diese Objekte auf Datenbankebene verwiesen. Weitere Informationen finden Sie unter CREATE EXTERNAL DATA SOURCE und unter CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. Erstellen einer externen Tabelle mit Daten im RCFile-Format
Dieses Beispiel zeigt die erforderlichen Schritte zur Erstellung einer externen Tabelle, die Daten als RCFiles formatiert. Es definiert eine externe Datenquelle mydatasource_rc und ein externes Dateiformat mfileformat_rc. In der CREATE EXTERNAL TABLE-Anweisung wird dann auf diese Objekte auf Datenbankebene verwiesen. Weitere Informationen finden Sie unter CREATE EXTERNAL DATA SOURCE und unter CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. Erstellen einer externen Tabelle mit Daten im ORC-Format
Dieses Beispiel zeigt die erforderlichen Schritte zur Erstellung einer externen Tabelle, die Daten als ORC-Dateien formatiert. Es definiert die externe Datenquelle mydatasource_orc und das externe Dateiformat myfileformat_orc. In der CREATE EXTERNAL TABLE-Anweisung wird dann auf diese Objekte auf Datenbankebene verwiesen. Weitere Informationen finden Sie unter CREATE EXTERNAL DATA SOURCE und unter CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D: Abfragen von Hadoop-Daten
ClickStream ist eine externe Tabelle, die mit der durch Tabstopps getrennten Textdatei employee.tbl in einem Hadoop-Cluster verbunden ist. Die folgende Abfrage sieht wie eine Abfrage für eine Standardtabelle aus. Allerdings ruft diese Abfrage Daten aus Hadoop ab und berechnet dann die Ergebnisse.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Verknüpfen von Hadoop-Daten mit SQL-Daten
Diese Abfrage sieht wie ein Standard-JOIN für zwei SQL-Tabellen aus. Der Unterschied besteht darin, dass PolyBase die Clickstream-Daten aus Hadoop abruft und sie dann mit der UrlDescription-Tabelle verknüpft. Eine Tabelle ist eine externe Tabelle, und die andere ist eine standardmäßige SQL-Tabelle.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Importieren Sie Daten aus Hadoop in eine SQL-Tabelle
Dieses Beispiel erstellt die neue SQL-Tabelle ms_user, die das Ergebnis eines Joins zwischen der SQL-Standardtabelle user und der externen Tabelle ClickStream dauerhaft speichert.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Erstellen einer externen Tabelle für SQL Server
Vor dem Erstellen von datenbankweit gültigen Anmeldeinformationen muss die Benutzerdatenbank über einen Hauptschlüssel zum Schützen der Anmeldeinformationen verfügen. Weitere Informationen finden Sie unter CREATE MASTER KEY sowie unter CREATE DATABASE SCOPED CREDENTIAL.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
Erstellen Sie eine neue externe Datenquelle namens SQLServerInstance und eine externe Tabelle namens sqlserver.customer:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
I. Erstellen einer externen Tabelle für Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Erstellen einer externen Tabelle für Teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Erstellen einer externen Tabelle für MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. Abfragen von S3-kompatiblen Objektspeichern über eine externe Tabelle
Gilt für: SQL Server 2022 (16.x) und höher
Das folgende Beispiel zeigt, wie mithilfe von T-SQL eine in einem S3-kompatiblen Objektspeicher gespeicherte Parquet-Datei durch Abfragen einer externen Tabelle abgefragt wird. In dem Beispiel wird ein relativer Pfad innerhalb der externen Datenquelle verwendet.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
Nächste Schritte
Weitere Informationen zu verwandten Konzepten finden Sie in den folgenden Artikeln:
* Azure SQL Datenbank*
Übersicht: Azure SQL-Datenbank
Erstellt in Azure SQL-Datenbank eine externe Tabelle für elastische Abfragen (in der Vorschau).
Siehe auch ERSTELLEN EINER EXTERNEN DATENQUELLE.
Syntax
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
Argumente
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Ein- bis dreiteiliger Name der Tabelle, die erstellt werden soll. Für eine externe Tabelle speichert SQL nur die Metadaten der Tabelle mit den grundlegenden Statistiken über die Datei oder den Ordner, auf die in Azure SQL-Datenbank verwiesen wird. Es werden keine tatsächlichen Daten in Azure SQL-Datenbank verschoben oder gespeichert.
Wichtig
Wenn der externe Datenquellentreiber einen dreiteiligen Namen unterstützt, wird dringend empfohlen, diesen dreiteiligen Namen anzugeben, um eine optimale Leistung zu erzielen.
<column_definition> [ ,...n ]
„CREATE EXTERNAL TABLE“ unterstützt das Konfigurieren von Spaltenname, Datentyp, NULL-Zulässigkeit und Sortierung. Sie können DEFAULT CONSTRAINT nicht für externe Tabellen verwenden.
Hinweis
Text, nText und XML sind keine unterstützten Datentypen für Spalten in externen Tabellen für Azure SQL-Datenbank.
Die Spaltendefinitionen, einschließlich der Datentypen und der Anzahl der Spalten, müssen mit den Daten in den externen Dateien übereinstimmen. Wenn ein Konflikt besteht, werden die Zeilen der Datei beim Abfragen der tatsächlichen Daten zurückgewiesen.
Externe Shardtabellenoptionen
Hiermit wird die externe Datenquelle (eine nicht-SQL Server-Datenquelle) und eine Verteilungsmethode für die elastische Datenbankabfrage angegeben.
DATA_SOURCE
Die DATA_SOURCE-Klausel definiert die externe Datenquelle (eine Shardzuordnung), die für die externe Tabelle verwendet wird. Ein Beispiel finden Sie unter Erstellen externer Tabellen.
Wichtig
Azure SQL-Datenbank unterstützt das Erstellen externer Tabellen für die EXTERNAL DATA SOURCE-Typen RDMS und SHARD_MAP_MANAGER. Azure SQL-Datenbank unterstützt das Erstellen externer Tabellen in Azure Blob Storage nicht.
SCHEMA_NAME und OBJECT_NAME
Die Klauseln SCHEMA_NAME und OBJECT_NAME ordnen die Definition der externen Tabelle einer Tabelle in einem anderen Schema zu. Falls nicht angegeben, wird davon ausgegangen, dass das Schema des Remoteobjekts „dbo“ und sein Name mit dem definierten Namen der externen Tabelle identisch ist. Dies ist nützlich, wenn der Name der Remotetabelle bereits in der Datenbank verwendet wird, in der Sie die externe Tabelle erstellen möchten. Sie möchten z. B. eine externe Tabelle zum Abrufen einer aggregierten Sicht von Katalogsichten oder DMVs für Ihre horizontal hochskalierte Datenebene definieren. Da Katalogsichten und DMVs bereits lokal vorhanden sind, können Sie ihre Namen nicht für die Definition der externen Tabelle verwenden. Verwenden Sie stattdessen in den Klauseln SCHEMA_NAME und/oder OBJECT_NAME einen anderen Namen und den Namen der Katalogsicht oder DMV. Ein Beispiel finden Sie unter Erstellen externer Tabellen.
DISTRIBUTION
Optional. Dieses Argument ist für Datenbanken des Typs SHARD_MAP_MANAGER erforderlich. Dieses Argument steuert, ob eine Tabelle wie eine Tabelle mit Shards oder replizierte Tabelle behandelt wird. Mit Tabellen des Typs SHARDED (Spaltenname) überlappen die Daten aus verschiedenen Tabellen nicht. REPLICATED gibt an, dass Tabellen dieselben Daten auf jeder Shard enthalten. ROUND_ROBIN gibt an, dass eine anwendungsspezifische Methode zum Verteilen von Daten verwendet wird.
Die DISTRIBUTION-Klausel gibt die Datenverteilung für diese Tabelle an: Der Abfrageprozessor nutzt die Informationen in der DISTRIBUTION-Klausel, um die effizientesten Abfragepläne zu erstellen.
- SHARDED bedeutet, dass Daten datenbankübergreifend horizontal partitioniert werden. Der Partitionierungsschlüssel für die Datenverteilung ist der Parameter
sharding_column_name. - REPLICATED bedeutet, dass identische Kopien der Tabelle in jeder Datenbank vorhanden sind. Sie müssen sicherstellen, dass die Replikate in allen Datenbanken identisch sind.
- ROUND_ROBIN bedeutet, dass die Tabelle mit einer anwendungsabhängigen Verteilungsmethode horizontal partitioniert wird.
Berechtigungen
Benutzer mit Zugriff auf die externe Tabelle erhalten automatisch Zugriff auf die zugrunde liegenden Remotetabellen gemäß den Anmeldeinformationen, die in der externen Datenquellendefinition angegeben sind. Vermeiden Sie eine unerwünschte Erhöhung von Berechtigungen durch die Anmeldeinformationen der externen Datenquelle. Verwenden Sie GRANT oder REVOKE für eine externe Tabelle, als handele es sich um eine normale Tabelle. Nachdem Sie die externe Datenquelle und die externen Tabellen definiert haben, können Sie jetzt vollständiges T-SQL in den externen Tabellen verwenden.
Fehlerbehandlung
Wenn während der Ausführung der CREATE EXTERNAL TABLE-Anweisung beim Verbindungsversuch ein Fehler auftritt, schlägt die Anweisung fehl. Die externe Tabelle wird nicht erstellt. Da SQL-Datenbank erneut versucht, die Verbindung aufzubauen, bevor die Abfrage endgültig fehlschlägt, kann es eine Minute oder länger dauern, bis der Befehl fehlschlägt.
Bemerkungen
In Szenarien mit Ad-hoc-Abfragen, z. B. SELECT FROM EXTERNAL TABLE, speichert SQL-Datenbank die aus der externen Datenquelle abgerufenen Zeilen in einer temporären Tabelle. Nachdem die Abfrage abgeschlossen ist, entfernt und löscht SQL-Datenbank die temporäre Tabelle. Es werden keine permanenten Daten in SQL-Tabellen gespeichert.
Im Gegensatz dazu speichert SQL-Datenbank die aus der externen Datenquelle abgerufenen Zeilen in Importszenarien, z.B. bei SELECT INTO FROM EXTERNAL TABLE, permanent in einer SQL-Tabelle. Die neue Tabelle wird beim Ausführen der Abfrage erstellt, wenn SQL-Datenbank die externen Daten abruft.
Sie können zahlreiche externe Tabellen erstellen, die auf die gleichen oder andere externe Datenquellen verweisen.
Einschränkungen
Der Zugriff auf Daten über eine externe Tabelle entspricht nicht der Isolationssemantik in SQL Server. Das bedeutet, dass beim Abfragen einer externen Tabelle keine Sperren oder Momentaufnahmeisolation erzwungen werden und sich daher zurückgegebene Daten ändern können, wenn die Daten in der externen Datenquelle geändert werden. Die gleiche Abfrage kann bei jeder Ausführung für eine externe Tabelle unterschiedliche Ergebnisse zurückgeben. Auf ähnliche Weise kann eine Abfrage fehlschlagen, wenn die externen Daten verschoben oder entfernt werden.
Sie können zahlreiche externe Tabellen erstellen, die alle auf unterschiedliche externe Datenquellen verweisen.
Nur diese DDL-Anweisungen (Data Definition Language) sind in externen Tabellen zulässig:
- CREATE TABLE und DROP TABLE
- CREATE VIEW und DROP VIEW
Nicht unterstützte Konstruktionen und Operationen:
- Die DEFAULT-Einschränkung auf externen Tabellenspalten
- DML-Vorgänge (Data Manipulation Language): DELETE, INSERT und UPDATE
- Dynamische Datenmaskierung in Spalten der externen Tabelle
- Cursor werden für externe Tabellen in Azure SQL-Datenbank nicht unterstützt.
Nur die in einer Abfrage definierten Literalprädikate können per Push an die externe Datenquelle übertragen werden. Darin unterscheiden sie sich von verknüpften Servern und dem Zugriff darauf. Dort können Prädikate verwendet werden, die während der Abfrageausführung bestimmt wurden. Ein Beispiel hierfür ist die Verwendung in Verbindung mit einer geschachtelten Schleife in einem Abfrageplan. Dadurch wird häufig die gesamte externe Tabelle lokal kopiert und anschließend verknüpft.
-- Assuming External.Orders is an external table and Customer is a local table.
-- This query will copy the whole of the external locally as the predicate needed
-- to filter isn't known at compile time. Its only known during execution of the query
SELECT Orders.OrderId, Orders.OrderTotal
FROM External.Orders
WHERE CustomerId IN (
SELECT TOP 1 CustomerId
FROM Customer
WHERE CustomerName = 'MyCompany'
);
Mit externen Tabellen kann die Verwendung von Parallelität im Abfrageplan verhindert werden.
Externe Tabellen werden als Remoteabfrage implementiert, wodurch die geschätzte Anzahl der zurückgegebenen Zeilen in der Regel 1.000 beträgt. Weitere Regeln basierend auf dem Prädikatstyp können zum Filtern der externen Tabelle verwendet werden. Dabei handelt es sich um regelbasierte Schätzungen und nicht um Schätzwerte, die auf den tatsächlichen Daten der externen Tabelle beruhen. Der Optimierer greift nicht auf die Remotedatenquelle zu, um genauere Schätzungen zu erhalten.
Einschränkungen für Datentypen
Die folgenden Datentypen können nicht in externen PolyBase-Tabellen verwendet werden:
geographygeometryhierarchyidimagetextnTextxml- Jeder benutzerdefinierte Typ
Sperren
Freigegebene Sperre für das SCHEMARESOLUTION-Objekt.
Beispiele
A. Erstellen einer externen Tabelle für Azure SQL-Datenbank
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. Erstellen einer externen Tabelle für eine Datenquelle mit Shards
In diesem Beispiel wird eine Remote-DMV mithilfe der Klauseln SCHEMA_NAME und OBJECT_NAME einer externen Tabelle zugeordnet.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
Nächste Schritte
Weitere Informationen zu externen Tabellen in Azure SQL-Datenbank finden Sie in den folgenden Artikeln:
* Azure Synapse
Analytics *
Übersicht: Azure Synapse Analytics
Verwenden Sie eine externe Tabelle, um:
- Dedizierte SQL-Pools können Daten aus Hadoop, Azure Blob Storage sowie Azure Data Lake Storage Gen1 und Gen2 abfragen, importieren und speichern.
- Serverlose SQL-Pools können Daten aus Azure Blob Storage sowie Azure Data Lake Storage Gen1 und Gen2 abfragen, importieren und speichern. Serverlose SQL-Pools unterstützen
TYPE=Hadoopnicht.
Siehe auch CREATE EXTERNAL DATA SOURCE und DROP EXTERNAL TABLE.
Weitere Anleitungen und Beispiele zur Verwendung externer Tabellen mit Azure Synapse finden Sie unter Verwenden externer Tabellen mit Synapse SQL.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Argumente
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Ein- bis dreiteiliger Name der Tabelle, die erstellt werden soll. Für eine externe Tabelle werden nur die Metadaten der Tabelle mit den grundlegenden Statistiken über die Datei oder den Ordner gespeichert, auf die in Azure Data Lake, Hadoop oder Azure Blob Storage verwiesen wird. Bei der Erstellung externer Tabellen werden keine tatsächlichen Daten verschoben oder gespeichert.
Wichtig
Wenn der externe Datenquellentreiber einen dreiteiligen Namen unterstützt, wird dringend empfohlen, diesen dreiteiligen Namen anzugeben, um eine optimale Leistung zu erzielen.
<column_definition> [ ,...n ]
„CREATE EXTERNAL TABLE“ unterstützt das Konfigurieren von Spaltenname, Datentyp, NULL-Zulässigkeit und Sortierung. Sie können DEFAULT CONSTRAINT nicht für externe Tabellen verwenden.
Hinweis
Die veralteten Datentypen text, ntext und XML werden nicht für Spalten in externen Tabellen für Synapse Analytics unterstützt.
- Beim Lesen von durch Trennzeichen getrennte Dateien müssen Spaltendefinitionen, einschließlich Datentypen und Anzahl der Spalten, mit den Daten in den externen Dateien übereinstimmen. Wenn ein Konflikt besteht, werden die Zeilen der Datei beim Abfragen der tatsächlichen Daten zurückgewiesen.
- Beim Lesen aus Parquet-Dateien können Sie die zu lesenden Spalten angeben und die übrigen Spalten überspringen.
LOCATION = 'folder_or_filepath'
Diese Anweisung gibt den Ordner oder den Dateipfad und Dateinamen für die tatsächlichen Daten in Azure Data Lake, Hadoop oder Azure Blob Storage an. Der Speicherort beginnt im Stammordner. Der Stammordner ist der in der externen Datenquelle angegebene Datenspeicherort. Die Anweisung CREATE EXTERNAL TABLE AS SELECT erstellt den Pfad und den Ordner, wenn diese noch nicht vorhanden sind. CREATE EXTERNAL TABLE erstellt den Pfad und den Ordner nicht.
Wenn LOCATION als Ordner angegeben wird, ruft eine PolyBase-Abfrage, die aus der externen Tabelle auswählt, Dateien aus dem Ordner und allen Unterordnern ab. PolyBase gibt wie Hadoop keine ausgeblendeten Ordner zurück. Es werden auch keine Dateien zurückgegeben, deren Dateiname mit einem Unterstrich (_) oder einem Punkt (.) beginnt.
Wenn LOCATION='/webdata/', gibt eine PolyBase-Abfrage im folgenden Beispielbild Zeilen aus mydata.txt und mydata2.txt zurück. mydata3.txt wird nicht zurückgegeben, da es sich um einen Unterordner eines ausgeblendeten Ordners handelt. Und _hidden.txt wird nicht zurückgegeben, da es sich um eine ausgeblendete Datei handelt.
Im Gegensatz zu externen Hadoop-Tabellen geben native externe Tabellen keine Unterordner zurück, es sei denn, Sie geben /** am Ende des Pfads an. In diesem Beispiel werden von einer Abfrage des serverlosen SQL-Pools Zeilen aus „mydata.txt“ zurückgegeben, wenn LOCATION='/webdata/' angegeben wird. „mydata2.txt“ und „mydata3.txt“ werden nicht zurückgegeben, da sie sich in einem Unterordner befinden. Von Hadoop-Tabellen werden alle Dateien in einem beliebigen Unterordner zurückgegeben.
Dateien, deren Name mit einem Unterstrich (_) oder Punkt (.) beginnt, werden sowohl bei externen Hadoop-Tabellen als auch bei nativen externen Tabellen übersprungen.
DATA_SOURCE = external_data_source_name
Gibt den Namen der externen Datenquelle an, die den Speicherort der externen Daten enthält. Dieser Speicherort befindet sich in Azure Data Lake. Verwenden Sie zum Erstellen einer externen Datenquelle CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Gibt den Namen des externen Dateiformatobjekts an, das den Dateityp und die Komprimierungsmethode der externen Daten speichert. Verwenden Sie zum Erstellen eines externen Dateiformats CREATE EXTERNAL FILE FORMAT.
TABLE_OPTIONS
Gibt die Optionen an, die beschreiben, wie die zugrunde liegenden Dateien gelesen werden sollen. Derzeit ist nur die Option {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]} verfügbar. Durch diese Option wird die externe Tabelle angewiesen, Aktualisierungen der zugrunde liegenden Dateien zu ignorieren, auch wenn dies unter Umständen zu inkonsistenten Lesevorgängen führt. Verwenden Sie diese Option nur in Sonderfällen, in denen Sie häufig Dateien angefügt haben. Diese Option steht im serverlosen SQL-Pool für das CSV-Format zur Verfügung.
REJECT-Optionen
Ablehnungsoptionen befinden sich für serverlose SQL-Pools in Azure Synapse Analytics in der Vorschau.
Diese Option kann nur mit externen Datenquellen verwendet werden, die den Typ Hadoop aufweisen.
Sie können Reject-Parameter angeben, die bestimmen, wie PolyBase modifizierte Datensätze behandelt, die aus der externen Datenquelle abgerufen werden. Ein Datensatz gilt als „dirty“ (modifiziert), wenn die tatsächlichen Datentypen oder die Anzahl der Spalten nicht den Spaltendefinitionen der externen Tabelle entsprechen.
Wenn Sie die Reject-Werte nicht angeben oder ändern, verwendet PolyBase Standardwerte. Diese Informationen über die Reject-Parameter werden als zusätzliche Metadaten gespeichert, wenn Sie eine externe Tabelle mit der CREATE EXTERNAL TABLE-Anweisung erstellen. Wenn eine zukünftige SELECT- oder SELECT INTO SELECT-Anweisung Daten aus der externen Tabelle auswählt, wird PolyBase die Reject-Optionen verwenden, um die Anzahl oder den Prozentsatz der Zeilen zu bestimmen, die zurückgewiesen werden können, bevor die tatsächliche Abfrage fehlschlägt. Die Abfrage gibt (Teil-) Ergebnisse zurück, bis der Reject-Schwellenwert überschritten wird. Daraufhin wird eine entsprechende Fehlermeldung ausgelöst.
Die Formatoption PARSER_VERSION wird nur in serverlosen SQL-Pools unterstützt.
REJECT_TYPE = value | percentage
Gibt an, ob die Option „REJECT_VALUE“ als Literalwert oder als Prozentsatz angegeben wird.
value
REJECT_VALUE ist ein Literalwert und kein Prozentsatz. Die PolyBase-Abfrage schlägt fehl, wenn die Anzahl der abgelehnten Zeilen reject_value überschreitet.
Die SELECT-Abfrage von PolyBase schlägt beispielsweise bei „REJECT_VALUE = 5“ und „REJECT_TYPE = value“ fehl, nachdem fünf Zeilen abgelehnt wurden.
Prozentwert
REJECT_VALUE ist ein Prozentsatz und kein Literalwert. Eine PolyBase-Abfrage schlägt fehl, wenn der Prozentsatz fehlerhafter Zeilen reject_value überschreitet. Der Prozentsatz der fehlerhaften Zeilen wird in Intervallen berechnet.
REJECT_VALUE = reject_value
Gibt den Wert oder den Prozentsatz der Zeilen an, die zurückgewiesen werden können, bevor die Abfrage fehlschlägt.
- Wenn REJECT_TYPE = Wert, muss reject_value eine ganze Zahl zwischen 0 und 2.147.483.647 sein.
- Wenn REJECT_TYPE = Prozentzahl, muss reject_value eine Gleitkommazahl zwischen 0 und 100 sein. „Prozentsatz“ gilt nur für dedizierte SQL-Pools, bei denen
TYPE=HADOOP.
Die Abfrage schlägt fehl, wenn die Anzahl der abgelehnten Zeilen reject_value überschreitet. Die SELECT-Abfrage schlägt beispielsweise bei „REJECT_VALUE = 5“ und „REJECT_TYPE = value“ fehl, nachdem fünf Zeilen abgelehnt wurden.
REJECT_SAMPLE_VALUE = reject_sample_value
Dieses Attribut ist erforderlich, wenn Sie REJECT_TYPE = Prozentsatz angeben. Bestimmt die Anzahl der Zeilen, bei denen versucht wird, sie abzurufen, bevor die PolyBase den Prozentsatz der abgelehnten Zeilen neu berechnet.
Der reject_sample_value-Parameter muss eine ganze Zahl zwischen 0 und 2.147.483.647 sein.
Ist beispielsweise REJECT_SAMPLE_VALUE = 1000, dann berechnet PolyBase den Prozentsatz von fehlerhaften Zeilen nach dem Importversuch von 1000 Zeilen aus der externen Datendatei. Ist der Prozentsatz von fehlerhaften Zeilen kleiner als reject_value, führt PolyBase einen erneuten Abrufversuch von 1000 Zeilen aus. Nach jedem weiteren Importversuch von 1000 Zeilen wird der Prozentsatz von fehlerhaften Zeilen weiterhin neu berechnet.
Hinweis
Da die Berechnung des Prozentsatzes von fehlerhaften Zeilen durch PolyBase in Intervallen erfolgt, kann der tatsächliche Prozentsatz fehlerhafter Zeilen reject_value überschreiten.
Beispiel:
In diesem Beispiel wird verdeutlicht, wie die drei REJECT-Optionen interagieren. Gilt beispielsweise REJECT_TYPE = Prozentsatz, REJECT_VALUE = 30 und REJECT_SAMPLE_VALUE = 100, dann könnte das folgende Szenario auftreten:
- PolyBase versucht, die ersten 100 Zeilen abzurufen. Davon sind 25 fehlerhaft und 75 erfolgreich.
- Der berechnete Prozentsatz fehlerhafter Zeilen ist mit 25 % kleiner als der REJECT-Wert von 30 %. Aus diesem Grund wird PolyBase weiterhin versuchen, Daten aus der externen Datenquelle abzurufen.
- PolyBase versucht, die nächsten 100 Zeilen zu laden. Dieses Mal sind 25 Zeilen erfolgreich und 75 Zeilen fehlerhaft.
- Der Prozentsatz fehlerhafter Zeilen wird mit 50 % neu berechnet. Der Prozentsatz fehlerhafter Zeilen hat den REJECT-Wert von 30 % überschritten.
- Die PolyBase-Abfrage schlägt fehl, da nach der Rückgabe der ersten 200 Zeilen 50 % der Zeilen abgelehnt werden. Beachten Sie, dass übereinstimmende Zeilen zurückgegeben wurden, bevor die PolyBase-Abfrage erkennt, dass der Schwellenwert zum Zurückweisen überschritten wurde.
REJECTED_ROW_LOCATION = Verzeichnis
Gibt das Verzeichnis in der externen Datenquelle an, in das die abgelehnten Zeilen und die entsprechende Fehlerdatei geschrieben werden sollen.
Wenn der angegebene Pfad nicht vorhanden ist, wird er erstellt. Es wird ein untergeordnetes Verzeichnis mit dem Namen _rejectedrows erstellt. Mit dem Zeichen _ wird sichergestellt, dass das Verzeichnis für andere Datenverarbeitungsprozesse nicht verwendet wird, es sei denn, es ist explizit im Parameter LOCATION angegeben.
- In serverlosen SQL-Pools ist der Pfad
YearMonthDay_HourMinuteSecond_StatementID. Sie können die Anweisungs-ID verwenden, um den Ordner mit der Abfrage zu korrelieren, von der er generiert wurde. - In dedizierten SQL-Pools basiert der erstellte Pfad auf dem Zeitpunkt der Lastübermittlung im Format
YearMonthDay -HourMinuteSecond, z. B20180330-173205.
In diesen Ordner werden zwei Arten von Dateien geschrieben: die Datei _reason und die Datendatei.
Weitere Informationen finden Sie unter CREATE EXTERNAL DATA SOURCE (CREATE EXTERNAL DATA SOURCE).
Sowohl die Ursachendateien als auch die Datendateien haben die „queryID“, die der CTAS-Anweisung zugeordnet ist. Da die Daten und die Ursachen in getrennten Dateien gespeichert sind, haben die zugehörigen Dateien ein entsprechendes Suffix.
In serverlosen SQL-Pools enthält die Datei error.json ein JSON-Array mit aufgetretenen Fehlern im Zusammenhang mit abgelehnten Zeilen. Jedes Element, das einen Fehler darstellt, enthält die folgenden Attribute:
| attribute | BESCHREIBUNG |
|---|---|
| Fehler | Der Grund, warum die Zeile abgelehnt wird. |
| Zeile | Die Ordinalzahl der abgelehnten Zeile in der Datei. |
| Column | Die Ordinalzahl der abgelehnten Spalte. |
| Wert | Der Wert der abgelehnten Spalte. Wenn der Wert größer als 100 Zeichen ist, werden nur die ersten 100 Zeichen angezeigt. |
| Datei | Der Pfad zur Datei, zu der die Zeile gehört. |
Berechtigungen
Folgende Benutzerberechtigungen sind erforderlich:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Hinweis
CONTROL DATABASE-Berechtigungen sind nur zum Erstellen von MASTER KEY, DATABASE SCOPED CREDENTIAL und EXTERNAL DATA SOURCE erforderlich.
Beachten Sie, dass die Anmeldung, die die externe Datenquelle erstellt, die Berechtigung zum Lesen und Schreiben in der externen Datenquelle, die in Hadoop oder Azure Blob Storage gespeichert ist, benötigt.
Wichtig
Mit der Berechtigung ALTER ANY EXTERNAL DATA SOURCE besitzt jeder Prinzipal die Fähigkeit, beliebige externe Datenquellenobjekte zu erstellen und zu ändern. Damit ist auch der Zugriff auf alle datenbankweit gültigen Anmeldeinformationen der Datenbank möglich. Da es sich hierbei um eine weitreichende Berechtigung handelt, darf sie nur vertrauenswürdigen Prinzipalen innerhalb des Systems erteilt werden.
Fehlerbehandlung
Beim Ausführen der CREATE EXTERNAL TABLE-Anweisung versucht PolyBase, eine Verbindung mit der externen Datenquelle herzustellen. Tritt bei der Verbindung ein Fehler auf, schlägt die Anweisung fehl. Die externe Tabelle wird nicht erstellt. Da PolyBase erneut versucht, die Verbindung aufzubauen, bevor die Abfrage endgültig fehlschlägt, kann es eine Minute oder länger dauern, bis der Befehl fehlschlägt.
Bemerkungen
In Szenarien mit Ad-hoc-Abfragen, z. B. SELECT FROM EXTERNAL TABLE, speichert PolyBase die aus der externen Datenquelle abgerufenen Zeilen in einer temporären Tabelle. Nachdem die Abfrage abgeschlossen ist, entfernt und löscht PolyBase die temporäre Tabelle. Es werden keine permanenten Daten in SQL-Tabellen gespeichert.
Im Gegensatz dazu speichert PolyBase die aus der externen Datenquelle abgerufenen Zeilen in Importszenarios, z.B. bei SELECT INTO FROM EXTERNAL TABLE, permanent in einer SQL-Tabelle. Die neue Tabelle wird beim Ausführen der Abfrage erstellt, wenn PolyBase die externen Daten abruft.
PolyBase kann einen Teil der Abfrageberechnung an Hadoop übertragen, um die Abfrageleistung zu verbessern. Diese Aktion wird als Prädikatweitergabe bezeichnet. Um sie zu aktivieren, geben Sie die Option „Resource Manager Location“ von Hadoop in CREATE EXTERNAL DATA SOURCE an.
Sie können zahlreiche externe Tabellen erstellen, die auf die gleichen oder andere externe Datenquellen verweisen.
Achten Sie auf Quelldaten, die die UTF-8-Sortierung verwenden. Für alle Quelldaten, die die UTF-8-Sortierung verwenden, müssen Sie in jeder UTF-8-Spalte der CREATE EXTERNAL TABLE-Anweisung manuell eine Nicht-UTF-8-Sortierung bereitstellen. Dies liegt daran, dass die UTF-8-Unterstützung nicht für externe Tabellen gilt. Wenn Sie versuchen, eine externe Tabelle mit einer UTF-8-Sortierung zu erstellen, erhalten Sie eine Fehlermeldung des Typs Unsupported collation. Wenn die Datenbanksortierung der externen Tabelle einer UTF-8-Sortierung entspricht, schlägt die Erstellung einer externen Tabelle fehl, solange Sie keine explizite Nicht-UTF-8-Spaltensortierung wie [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL, angeben.
Serverlose und dedizierte SQL-Pools in Azure Synapse Analytics nutzen für die Datenvirtualisierung verschiedene Codebasen. Serverlose SQL-Pools unterstützen eine native Datenvirtualisierungstechnologie. Dedizierte SQL-Pools unterstützen sowohl die native als auch die PolyBase-Datenvirtualisierung. Die PolyBase-Datenvirtualisierung wird verwendet, wenn EXTERNAL DATA SOURCE mit TYPE=HADOOP erstellt wird.
Einschränkungen
Da die Verwaltung der Daten für eine externe Tabelle nicht direkt in Azure Synapse gesteuert werden kann, können die Daten jederzeit von einem externen Prozess geändert oder gelöscht werden. Aus diesem Grund sind Abfrageergebnisse für eine externe Tabelle nicht garantiert deterministisch. Die gleiche Abfrage kann bei jeder Ausführung für eine externe Tabelle unterschiedliche Ergebnisse zurückgeben. Auf ähnliche Weise kann eine Abfrage fehlschlagen, wenn die externen Daten verschoben oder entfernt werden.
Sie können zahlreiche externe Tabellen erstellen, die alle auf unterschiedliche externe Datenquellen verweisen.
Nur diese DDL-Anweisungen (Data Definition Language) sind in externen Tabellen zulässig:
- CREATE TABLE und DROP TABLE
- CREATE STATISTICS und DROP STATISTICS
- CREATE VIEW und DROP VIEW
Nicht unterstützte Konstruktionen und Operationen:
- Die DEFAULT-Einschränkung auf externen Tabellenspalten
- DML-Vorgänge (Data Manipulation Language): DELETE, INSERT und UPDATE
- Dynamische Datenmaskierung in Spalten der externen Tabelle
Abfrageeinschränkungen
Es wird davon abgeraten, mehr als 30.000 Dateien pro Ordner zu überschreiten. Wenn auf zu viele Dateien verwiesen wird, kann eine Ausnahme aufgrund ungenügenden Arbeitsspeichers von Java Virtual Machine (JVM) auftreten oder die Leistung kann beeinträchtigt werden.
Einschränkungen der Tabellenbreite
PolyBase in Azure Data Warehouse verfügt über eine Begrenzung für die Zeilenbreite von 1 MB, basierend auf der Maximalgröße einer einzelnen gültigen Zeile je Tabellendefinition. Wenn die Summe des Spaltenschemas größer als 1 MB ist, kann PolyBase die Daten nicht abfragen.
Einschränkungen für Datentypen
Die folgenden Datentypen können nicht in externen PolyBase-Tabellen verwendet werden:
geographygeometryhierarchyidimagetextnTextxml- Jeder benutzerdefinierte Typ
Sperren
Freigegebene Sperre für das SCHEMARESOLUTION-Objekt.
Beispiele
A. Importieren von Daten aus ADLS Gen 2 in Azure Synapse Analytics.
Beispiele für ADLS Gen 1 finden Sie unter Erstellen einer externen Datenquelle.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Importieren von Daten aus Parquet in Azure Synapse Analytics
Im folgenden Beispiel wird eine externe Tabelle erstellt Anschließend wird die erste Zeile zurückgegeben:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
Nächste Schritte
Weitere Informationen zu externen Tabellen und verwandten Konzepten finden Sie in den folgenden Artikeln:
* Analytics
Platform System (PDW) *
Übersicht: Analyseplattformsystem
Verwenden Sie eine externe Tabelle, um:
- Daten in Hadoop oder in Azure Blob Storage mit Transact-SQL-Anweisungen abzufragen.
- Daten aus Hadoop oder Azure Blob Storage in Analytics Platform System zu importieren und zu speichern.
Siehe auch CREATE EXTERNAL DATA SOURCE und DROP EXTERNAL TABLE.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
Argumente
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Ein- bis dreiteiliger Name der Tabelle, die erstellt werden soll. Für eine externe Tabelle speichert Analytics Platform System nur die Metadaten der Tabelle mit den grundlegenden Statistiken über die Datei oder den Ordner, auf die in Hadoop oder Azure Blob Storage verwiesen wird. Es werden keine tatsächlichen Daten verschoben oder in Analytics Platform System gespeichert.
Wichtig
Wenn der externe Datenquellentreiber einen dreiteiligen Namen unterstützt, wird dringend empfohlen, diesen dreiteiligen Namen anzugeben, um eine optimale Leistung zu erzielen.
<column_definition> [ ,...n ]
„CREATE EXTERNAL TABLE“ unterstützt das Konfigurieren von Spaltenname, Datentyp, NULL-Zulässigkeit und Sortierung. Sie können DEFAULT CONSTRAINT nicht für externe Tabellen verwenden.
Die Spaltendefinitionen, einschließlich der Datentypen und der Anzahl der Spalten, müssen mit den Daten in den externen Dateien übereinstimmen. Wenn ein Konflikt besteht, werden die Zeilen der Datei beim Abfragen der tatsächlichen Daten zurückgewiesen.
LOCATION = 'folder_or_filepath'
Gibt den Ordner oder den Dateipfad und Dateinamen für die tatsächlichen Daten in Hadoop oder Azure Blob Storage an. Der Speicherort beginnt im Stammordner. Der Stammordner ist der in der externen Datenquelle angegebene Datenspeicherort.
In Analytics Platform System erstellt die Anweisung CREATE EXTERNAL TABLE AS SELECT den Pfad und den Ordner, wenn diese noch nicht vorhanden sind. CREATE EXTERNAL TABLE erstellt den Pfad und den Ordner nicht.
Wenn LOCATION als Ordner angegeben wird, ruft eine PolyBase-Abfrage, die aus der externen Tabelle auswählt, Dateien aus dem Ordner und allen Unterordnern ab. PolyBase gibt wie Hadoop keine ausgeblendeten Ordner zurück. Es werden auch keine Dateien zurückgegeben, deren Dateiname mit einem Unterstrich (_) oder einem Punkt (.) beginnt.
Wenn LOCATION='/webdata/', gibt eine PolyBase-Abfrage im folgenden Beispielbild Zeilen aus mydata.txt und mydata2.txt zurück. mydata3.txt wird nicht zurückgegeben, da es sich um einen Unterordner eines ausgeblendeten Ordners handelt. Und _hidden.txt wird nicht zurückgegeben, da es sich um eine ausgeblendete Datei handelt.
Legen Sie das Attribut <polybase.recursive.traversal> in der Konfigurationsdatei core-site.xml auf „false“ fest, um den Standardordner zu ändern und nur aus dem Stammordner zu lesen. Diese Datei befindet sich unter <SqlBinRoot>\PolyBase\Hadoop\Conf\ unter dem bin-Stammverzeichnis von SQL Server. Beispielsweise C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Gibt den Namen der externen Datenquelle an, die den Speicherort der externen Daten enthält. Dieser Speicherort ist entweder ein Hadoop- oder Azure Blob Storage-Speicherort. Verwenden Sie zum Erstellen einer externen Datenquelle CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Gibt den Namen des externen Dateiformatobjekts an, das den Dateityp und die Komprimierungsmethode der externen Daten speichert. Verwenden Sie zum Erstellen eines externen Dateiformats CREATE EXTERNAL FILE FORMAT.
Reject-Optionen
Diese Option kann nur mit externen Datenquellen verwendet werden, die den Typ Hadoop aufweisen.
Sie können Reject-Parameter angeben, die bestimmen, wie PolyBase modifizierte Datensätze behandelt, die aus der externen Datenquelle abgerufen werden. Ein Datensatz gilt als „dirty“ (modifiziert), wenn die tatsächlichen Datentypen oder die Anzahl der Spalten nicht den Spaltendefinitionen der externen Tabelle entsprechen.
Wenn Sie die Reject-Werte nicht angeben oder ändern, verwendet PolyBase Standardwerte. Diese Informationen über die Reject-Parameter werden als zusätzliche Metadaten gespeichert, wenn Sie eine externe Tabelle mit der CREATE EXTERNAL TABLE-Anweisung erstellen. Wenn eine zukünftige SELECT- oder SELECT INTO SELECT-Anweisung Daten aus der externen Tabelle auswählt, wird PolyBase die Reject-Optionen verwenden, um die Anzahl oder den Prozentsatz der Zeilen zu bestimmen, die zurückgewiesen werden können, bevor die tatsächliche Abfrage fehlschlägt. Die Abfrage gibt (Teil-) Ergebnisse zurück, bis der Reject-Schwellenwert überschritten wird. Daraufhin wird eine entsprechende Fehlermeldung ausgelöst.
REJECT_TYPE = value | percentage
Gibt an, ob die Option „REJECT_VALUE“ als Literalwert oder als Prozentsatz angegeben wird.
value
REJECT_VALUE ist ein Literalwert und kein Prozentsatz. Die PolyBase-Abfrage schlägt fehl, wenn die Anzahl der abgelehnten Zeilen reject_value überschreitet.
Die SELECT-Abfrage von PolyBase schlägt beispielsweise bei „REJECT_VALUE = 5“ und „REJECT_TYPE = value“ fehl, nachdem fünf Zeilen abgelehnt wurden.
Prozentwert
REJECT_VALUE ist ein Prozentsatz und kein Literalwert. Eine PolyBase-Abfrage schlägt fehl, wenn der Prozentsatz fehlerhafter Zeilen reject_value überschreitet. Der Prozentsatz der fehlerhaften Zeilen wird in Intervallen berechnet.
REJECT_VALUE = reject_value
Gibt den Wert oder den Prozentsatz der Zeilen an, die zurückgewiesen werden können, bevor die Abfrage fehlschlägt.
Wenn REJECT_TYPE = Wert, muss reject_value eine ganze Zahl zwischen 0 und 2.147.483.647 sein.
Wenn REJECT_TYPE = Prozentzahl, muss reject_value eine Gleitkommazahl zwischen 0 und 100 sein.
REJECT_SAMPLE_VALUE = reject_sample_value
Dieses Attribut ist erforderlich, wenn Sie REJECT_TYPE = Prozentsatz angeben. Bestimmt die Anzahl der Zeilen, bei denen versucht wird, sie abzurufen, bevor die PolyBase den Prozentsatz der abgelehnten Zeilen neu berechnet.
Der reject_sample_value-Parameter muss eine ganze Zahl zwischen 0 und 2.147.483.647 sein.
Ist beispielsweise REJECT_SAMPLE_VALUE = 1000, dann berechnet PolyBase den Prozentsatz von fehlerhaften Zeilen nach dem Importversuch von 1000 Zeilen aus der externen Datendatei. Ist der Prozentsatz von fehlerhaften Zeilen kleiner als reject_value, führt PolyBase einen erneuten Abrufversuch von 1000 Zeilen aus. Nach jedem weiteren Importversuch von 1000 Zeilen wird der Prozentsatz von fehlerhaften Zeilen weiterhin neu berechnet.
Hinweis
Da die Berechnung des Prozentsatzes von fehlerhaften Zeilen durch PolyBase in Intervallen erfolgt, kann der tatsächliche Prozentsatz fehlerhafter Zeilen reject_value überschreiten.
Beispiel:
In diesem Beispiel wird verdeutlicht, wie die drei REJECT-Optionen interagieren. Gilt beispielsweise REJECT_TYPE = Prozentsatz, REJECT_VALUE = 30 und REJECT_SAMPLE_VALUE = 100, dann könnte das folgende Szenario auftreten:
- PolyBase versucht, die ersten 100 Zeilen abzurufen. Davon sind 25 fehlerhaft und 75 erfolgreich.
- Der berechnete Prozentsatz fehlerhafter Zeilen ist mit 25 % kleiner als der REJECT-Wert von 30 %. Aus diesem Grund wird PolyBase weiterhin versuchen, Daten aus der externen Datenquelle abzurufen.
- PolyBase versucht, die nächsten 100 Zeilen zu laden. Dieses Mal sind 25 Zeilen erfolgreich und 75 Zeilen fehlerhaft.
- Der Prozentsatz fehlerhafter Zeilen wird mit 50 % neu berechnet. Der Prozentsatz fehlerhafter Zeilen hat den REJECT-Wert von 30 % überschritten.
- Die PolyBase-Abfrage schlägt fehl, da nach der Rückgabe der ersten 200 Zeilen 50 % der Zeilen abgelehnt werden. Beachten Sie, dass übereinstimmende Zeilen zurückgegeben wurden, bevor die PolyBase-Abfrage erkennt, dass der Schwellenwert zum Zurückweisen überschritten wurde.
Berechtigungen
Folgende Benutzerberechtigungen sind erforderlich:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
- CONTROL DATABASE
Beachten Sie, dass die Anmeldung, die die externe Datenquelle erstellt, die Berechtigung zum Lesen und Schreiben in der externen Datenquelle, die in Hadoop oder Azure Blob Storage gespeichert ist, benötigt.
Wichtig
Mit der Berechtigung ALTER ANY EXTERNAL DATA SOURCE besitzt jeder Prinzipal die Fähigkeit, beliebige externe Datenquellenobjekte zu erstellen und zu ändern. Damit ist auch der Zugriff auf alle datenbankweit gültigen Anmeldeinformationen der Datenbank möglich. Da es sich hierbei um eine weitreichende Berechtigung handelt, darf sie nur vertrauenswürdigen Prinzipalen innerhalb des Systems erteilt werden.
Fehlerbehandlung
Beim Ausführen der CREATE EXTERNAL TABLE-Anweisung versucht PolyBase, eine Verbindung mit der externen Datenquelle herzustellen. Tritt bei der Verbindung ein Fehler auf, schlägt die Anweisung fehl. Die externe Tabelle wird nicht erstellt. Da PolyBase erneut versucht, die Verbindung aufzubauen, bevor die Abfrage endgültig fehlschlägt, kann es eine Minute oder länger dauern, bis der Befehl fehlschlägt.
Bemerkungen
In Szenarien mit Ad-hoc-Abfragen, z. B. SELECT FROM EXTERNAL TABLE, speichert PolyBase die aus der externen Datenquelle abgerufenen Zeilen in einer temporären Tabelle. Nachdem die Abfrage abgeschlossen ist, entfernt und löscht PolyBase die temporäre Tabelle. Es werden keine permanenten Daten in SQL-Tabellen gespeichert.
Im Gegensatz dazu speichert PolyBase die aus der externen Datenquelle abgerufenen Zeilen in Importszenarios, z.B. bei SELECT INTO FROM EXTERNAL TABLE, permanent in einer SQL-Tabelle. Die neue Tabelle wird beim Ausführen der Abfrage erstellt, wenn PolyBase die externen Daten abruft.
PolyBase kann einen Teil der Abfrageberechnung an Hadoop übertragen, um die Abfrageleistung zu verbessern. Diese Aktion wird als Prädikatweitergabe bezeichnet. Um sie zu aktivieren, geben Sie die Option „Resource Manager Location“ von Hadoop in CREATE EXTERNAL DATA SOURCE an.
Sie können zahlreiche externe Tabellen erstellen, die auf die gleichen oder andere externe Datenquellen verweisen.
Einschränkungen
Da die Verwaltung der Daten für eine externe Tabelle nicht direkt in der Appliance gesteuert werden kann, können die Daten jederzeit von einem externen Prozess geändert oder gelöscht werden. Aus diesem Grund sind Abfrageergebnisse für eine externe Tabelle nicht garantiert deterministisch. Die gleiche Abfrage kann bei jeder Ausführung für eine externe Tabelle unterschiedliche Ergebnisse zurückgeben. Auf ähnliche Weise kann eine Abfrage fehlschlagen, wenn die externen Daten verschoben oder entfernt werden.
Sie können zahlreiche externe Tabellen erstellen, die alle auf unterschiedliche externe Datenquellen verweisen. Wenn Sie Abfragen für verschiedene Hadoop-Datenquellen gleichzeitig ausführen, muss jede Hadoop-Datenquelle die gleiche „Hadoop Connectivity“-Serverkonfigurationseinstellung verwenden. Beispielsweise können Sie nicht gleichzeitig eine Abfrage für einen Cloudera Hadoop-Cluster und einen Hortonworks Hadoop-Cluster ausführen, da diese unterschiedliche Konfigurationseinstellungen verwenden. Weitere Informationen zu den Konfigurationseinstellungen und den unterstützten Kombinationen finden Sie unter Konfiguration der PolyBase-Netzwerkkonnektivität.
Nur diese DDL-Anweisungen (Data Definition Language) sind in externen Tabellen zulässig:
- CREATE TABLE und DROP TABLE
- CREATE STATISTICS und DROP STATISTICS
- CREATE VIEW und DROP VIEW
Nicht unterstützte Konstruktionen und Operationen:
- Die DEFAULT-Einschränkung auf externen Tabellenspalten
- DML-Vorgänge (Data Manipulation Language): DELETE, INSERT und UPDATE
- Dynamische Datenmaskierung in Spalten der externen Tabelle
Abfrageeinschränkungen
PolyBase kann bei 32 gleichzeitigen PolyBase-Abfragen maximal 33.000 Dateien pro Ordner verarbeiten. Diese maximale Anzahl schließt sowohl Dateien als auch Unterordner im jeweiligen HDFS-Ordner ein. Werden weniger als 32 Abfragen gleichzeitig ausgeführt, können auch PolyBase-Abfragen für Ordner in HDFS ausgeführt werden, die mehr als 33.000 Dateien enthalten. Es wird empfohlen, dass Sie externe Dateipfade kurz halten und nicht mehr als 30.000 Dateien pro HDFS-Ordner verwenden. Wenn auf zu viele Dateien verwiesen wird, kann eine Out-of-Memory-Ausnahme von Java Virtual Machine (JVM) auftreten.
Einschränkungen der Tabellenbreite
PolyBase in SQL Server 2016 verfügt über eine Begrenzung für die Zeilenbreite von 32 KB, basierend auf der Maximalgröße einer einzelnen gültigen Zeile je Tabellendefinition. Wenn die Summe des Spaltenschemas größer als 32 KB ist, kann PolyBase die Daten nicht abfragen.
In Azure Synapse Analytics wurde diese Begrenzung auf 1 MB erhöht.
Einschränkungen für Datentypen
Die folgenden Datentypen können nicht in externen PolyBase-Tabellen verwendet werden:
geographygeometryhierarchyidimagetextnTextxml- Jeder benutzerdefinierte Typ
Sperren
Freigegebene Sperre für das SCHEMARESOLUTION-Objekt.
Sicherheit
Die Datendateien für eine externe Tabelle werden in Hadoop oder Azure Blob Storage gespeichert. Diese Datendateien werden von Ihrem eigenen Prozess erstellt und verwaltet. Die Sicherheit der externen Daten liegt in Ihrer Verantwortung.
Beispiele
A. Verknüpfen von HDFS-Daten mit Analytics Platform System-Daten
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Importieren von Zeilendaten aus HDFS in eine verteilte Analytics Platform System-Tabelle
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. Importieren von Zeilendaten aus HDFS in eine replizierte Analytics Platform System-Tabelle
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
Nächste Schritte
Weitere Informationen zu externen Tabellen in Analytics Platform System finden Sie in den folgenden Artikeln:
* Azure SQL Managed Instance *
Übersicht: Verwaltete Azure SQL-Instanz
Erstellt eine externe Datenquelle in Azure SQL Managed Instance. Weitere Informationen finden Sie unter Datenvirtualisierung mit Azure SQL Managed Instance.
Die Datenvirtualisierung in Azure SQL Managed Instance bietet Zugriff auf externe Daten in einer Vielzahl von Dateiformaten in Azure Data Lake Storage Gen2 oder Azure Blob Storage, und um sie mit T-SQL-Abfragen abzufragen, auch Daten mit lokal gespeicherten relationalen Daten mithilfe von Verknüpfungen kombinieren.
Siehe auch CREATE EXTERNAL DATA SOURCE und DROP EXTERNAL TABLE.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumente
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Ein- bis dreiteiliger Name der Tabelle, die erstellt werden soll. Für eine externe Tabelle werden nur die Metadaten der Tabelle mit den grundlegenden Statistiken über die Datei oder den Ordner gespeichert, auf die in Azure Data Lake oder Azure Blob Storage verwiesen wird. Bei der Erstellung externer Tabellen werden keine tatsächlichen Daten verschoben oder gespeichert.
Wichtig
Wenn der externe Datenquellentreiber einen dreiteiligen Namen unterstützt, wird dringend empfohlen, diesen dreiteiligen Namen anzugeben, um eine optimale Leistung zu erzielen.
<column_definition> [ ,...n ]
„CREATE EXTERNAL TABLE“ unterstützt das Konfigurieren von Spaltenname, Datentyp, NULL-Zulässigkeit und Sortierung. Sie können DEFAULT CONSTRAINT nicht für externe Tabellen verwenden.
Die Spaltendefinitionen, einschließlich der Datentypen und der Anzahl der Spalten, müssen mit den Daten in den externen Dateien übereinstimmen. Wenn ein Konflikt besteht, werden die Zeilen der Datei beim Abfragen der tatsächlichen Daten zurückgewiesen.
LOCATION = 'folder_or_filepath'
Diese Anweisung gibt den Ordner oder den Dateipfad und Dateinamen für die tatsächlichen Daten in Azure Data Lake, Hadoop oder Azure Blob Storage an. Der Speicherort beginnt im Stammordner. Der Stammordner ist der in der externen Datenquelle angegebene Datenspeicherort. CREATE EXTERNAL TABLE erstellt den Pfad und den Ordner nicht.
Wenn Sie angeben, dass LOCATION ein Ordner ist, ruft die Abfrage von Azure SQL Managed Instance, die aus der externen Tabelle auswählt, Dateien aus dem Ordner ab, jedoch nicht alle Unterordner.
Azure SQL Managed Instance kann Dateien in Unterordnern oder ausgeblendeten Ordnern nicht finden. Es werden auch keine Dateien zurückgegeben, deren Dateiname mit einem Unterstrich (_) oder einem Punkt (.) beginnt.
Wenn LOCATION='/webdata/', gibt eine Abfrage im folgenden Beispielbild Zeilen aus mydata.txt zurück. mydata2.txt wird nicht zurückgegeben, da sich dieses Objekt in einem Unterordner befindet. Ebenfalls wird mydata3.txt nicht zurückgegeben, da sich dieses Objekt in einem ausgeblendeten Ordner befindet, und _hidden.txt wird nicht zurückgegeben, da es sich in einer ausgeblendeten Datei befindet.
DATA_SOURCE = external_data_source_name
Gibt den Namen der externen Datenquelle an, die den Speicherort der externen Daten enthält. Dieser Speicherort befindet sich in Azure Data Lake. Verwenden Sie zum Erstellen einer externen Datenquelle CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Gibt den Namen des externen Dateiformatobjekts an, das den Dateityp und die Komprimierungsmethode der externen Daten speichert. Verwenden Sie zum Erstellen eines externen Dateiformats CREATE EXTERNAL FILE FORMAT.
Berechtigungen
Folgende Benutzerberechtigungen sind erforderlich:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Hinweis
CONTROL DATABASE-Berechtigungen sind nur zum Erstellen von MASTER KEY, DATABASE SCOPED CREDENTIAL und EXTERNAL DATA SOURCE erforderlich.
Beachten Sie, dass die Anmeldung, die die externe Datenquelle erstellt, die Berechtigung zum Lesen und Schreiben in der externen Datenquelle, die in Hadoop oder Azure Blob Storage gespeichert ist, benötigt.
Wichtig
Mit der Berechtigung ALTER ANY EXTERNAL DATA SOURCE besitzt jeder Prinzipal die Fähigkeit, beliebige externe Datenquellenobjekte zu erstellen und zu ändern. Damit ist auch der Zugriff auf alle datenbankweit gültigen Anmeldeinformationen der Datenbank möglich. Da es sich hierbei um eine weitreichende Berechtigung handelt, darf sie nur vertrauenswürdigen Prinzipalen innerhalb des Systems erteilt werden.
Bemerkungen
In Szenarien mit Ad-hoc-Abfragen, z. B. SELECT FROM EXTERNAL TABLE, werden die aus der externen Datenquelle abgerufenen Zeilen in einer temporären Tabelle gespeichert. Nach Abschluss der Abfrage werden die Zeilen entfernt, und die temporäre Tabelle wird gelöscht. Es werden keine permanenten Daten in SQL-Tabellen gespeichert.
Im Gegensatz dazu werden die aus der externen Datenquelle abgerufenen Zeilen in Importszenarios, z. B. bei SELECT INTO FROM EXTERNAL TABLE, permanent in einer SQL-Tabelle gespeichert. Die neue Tabelle wird beim Ausführen der Abfrage erstellt, wenn die externen Daten abgerufen werden.
Derzeit ist die Datenvirtualisierung mit Azure SQL Managed Instance schreibgeschützt.
Sie können zahlreiche externe Tabellen erstellen, die auf die gleichen oder andere externe Datenquellen verweisen.
Einschränkungen
Da die Verwaltung der Daten für eine externe Tabelle nicht direkt in Azure SQL Managed Instance gesteuert werden kann, können die Daten jederzeit von einem externen Prozess geändert oder gelöscht werden. Aus diesem Grund sind Abfrageergebnisse für eine externe Tabelle nicht garantiert deterministisch. Die gleiche Abfrage kann bei jeder Ausführung für eine externe Tabelle unterschiedliche Ergebnisse zurückgeben. Auf ähnliche Weise kann eine Abfrage fehlschlagen, wenn die externen Daten verschoben oder entfernt werden.
Sie können zahlreiche externe Tabellen erstellen, die alle auf unterschiedliche externe Datenquellen verweisen.
Nur diese DDL-Anweisungen (Data Definition Language) sind in externen Tabellen zulässig:
- CREATE TABLE und DROP TABLE
- CREATE STATISTICS und DROP STATISTICS
- CREATE VIEW und DROP VIEW
Nicht unterstützte Konstruktionen und Operationen:
- Die DEFAULT-Einschränkung auf externen Tabellenspalten
- DML-Vorgänge (Data Manipulation Language): DELETE, INSERT und UPDATE
Einschränkungen der Tabellenbreite
Der Grenzwert für die Zeilenbreite von 1 MB basiert auf der maximalen Größe einer einzelnen gültigen Zeile nach Tabellendefinition. Wenn die Summe des Spaltenschemas größer als 1 MB ist, ist die Datenvirtualisierungsabfrage fehlerhaft.
Einschränkungen für Datentypen
Die folgenden Datentypen können in externen Tabellen in Azure SQL Managed Instance nicht verwendet werden:
geographygeometryhierarchyidimagetextnTextxml- Jeder benutzerdefinierte Typ
Sperren
Freigegebene Sperre für das SCHEMARESOLUTION-Objekt.
Beispiele
A. Abfragen externer Daten aus Azure SQL Managed Instance mit einer externen Tabelle
Weitere Beispiele finden Sie unter Erstellen externer Datenquellen oder unter Datenvirtualisierung mit Azure SQL Managed Instance.
Erstellen Sie den Datenbank-Hauptschlüssel, falls er nicht vorhanden ist.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOErstellen Sie die datenbankbezogenen Anmeldeinformationen mithilfe eines SAS-Tokens. Sie können auch eine verwaltete Identität verwenden.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GOErstellen Sie die externe Datenquelle mithilfe der Anmeldeinformationen.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOErstellen Sie ein EXTERNAL FILEFORMAT (externes Dateiformat) und eine EXTERNAL TABLE (externe Tabelle), um die Daten wie bei einer lokalen Tabelle abzufragen.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
Nächste Schritte
Weitere Informationen zu externen Tabellen und verwandten Konzepten finden Sie in den folgenden Artikeln:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für