Spracherkennung in Xamarin.iOS
In diesem Artikel wird die neue Spracherkennungs-API vorgestellt und gezeigt, wie Sie sie in einer Xamarin.iOS-App implementieren, um die kontinuierliche Spracherkennung und das Transkribieren von Sprache (aus Live- oder aufgezeichneten Audiodatenströmen) in Text zu unterstützen.
Apple hat neu in iOS 10 die Spracherkennungs-API veröffentlicht, die es einer iOS-App ermöglicht, die kontinuierliche Spracherkennung und Das Transkribieren von Sprache (aus Live- oder aufgezeichneten Audiodatenströmen) in Text zu unterstützen.
Laut Apple bietet die Spracherkennungs-API die folgenden Features und Vorteile:
- Hochgenau
- Stand der Technik
- Benutzerfreundlich
- Schnell
- Unterstützt mehrere Sprachen
- Respektiert die Privatsphäre der Benutzer
Funktionsweise der Spracherkennung
Die Spracherkennung wird in einer iOS-App implementiert, indem entweder Live- oder vorab aufgezeichnete Audiodaten (in einer der von der API unterstützten Sprachen) erfasst und an eine Spracherkennung übergeben werden, die eine Nur-Text-Transkription der gesprochenen Wörter zurückgibt.

Tastaturdiktatur
Wenn die meisten Benutzer an die Spracherkennung auf einem iOS-Gerät denken, denken sie an die integrierte Siri-Sprachausgabe Assistent, die zusammen mit dem Tastaturdiktat in iOS 5 mit dem iPhone 4S veröffentlicht wurde.
Tastaturdiktatur wird von jedem Schnittstellenelement unterstützt, das TextKit unterstützt (z UITextField . B. oder UITextArea), und wird aktiviert, indem der Benutzer auf die Diktierschaltfläche (direkt links von der Leertaste) auf der virtuellen iOS-Tastatur klickt.
Apple hat die folgenden Tastatur-Diktierstatistiken veröffentlicht (gesammelt seit 2011):
- Tastaturdiktatur ist seit der Veröffentlichung in iOS 5 weit verbreitet.
- Etwa 65.000 Apps verwenden es pro Tag.
- Etwa ein Drittel aller iOS-Diktats erfolgt in einer Drittanbieter-App.
Tastaturdiktatur ist äußerst einfach zu verwenden, da es keinen Aufwand seitens des Entwicklers erfordert, abgesehen von der Verwendung eines TextKit-Schnittstellenelements im UI-Design der App. Tastaturdiktatur hat auch den Vorteil, dass keine speziellen Berechtigungsanforderungen von der App erforderlich sind, bevor es verwendet werden kann.
Apps, die die neuen Spracherkennungs-APIs verwenden, erfordern spezielle Berechtigungen, die vom Benutzer erteilt werden müssen, da die Spracherkennung die Übertragung und temporäre Speicherung von Daten auf apple-Servern erfordert. Weitere Informationen finden Sie in unserer Dokumentation zu Sicherheits- und Datenschutzverbesserungen .
Die Tastaturdiktatur ist zwar einfach zu implementieren, hat jedoch mehrere Einschränkungen und Nachteile:
- Es erfordert die Verwendung eines Texteingabefelds und die Anzeige einer Tastatur.
- Es funktioniert nur mit Live-Audioeingaben, und die App hat keine Kontrolle über den Audioaufzeichnungsprozess.
- Es bietet keine Kontrolle über die Sprache, die zum Interpretieren der Sprache des Benutzers verwendet wird.
- Es gibt keine Möglichkeit für die App zu wissen, ob die Diktierschaltfläche für den Benutzer überhaupt verfügbar ist.
- Die App kann den Audioaufzeichnungsprozess nicht anpassen.
- Es bietet eine sehr flache Reihe von Ergebnissen, denen Informationen wie Timing und Konfidenz fehlen.
Spracherkennungs-API
Apple hat neu in iOS 10 die Spracherkennungs-API veröffentlicht, die eine leistungsfähigere Möglichkeit für eine iOS-App zum Implementieren der Spracherkennung bietet. Diese API ist die gleiche, die Apple verwendet, um Siri und Tastaturdiktate zu versorgen, und sie ist in der Lage, eine schnelle Transkription mit modernster Genauigkeit bereitzustellen.
Die von der Spracherkennungs-API bereitgestellten Ergebnisse werden transparent an die einzelnen Benutzer angepasst, ohne dass die App private Benutzerdaten sammeln oder darauf zugreifen muss.
Die Spracherkennungs-API stellt ergebnisse nahezu in Echtzeit an die aufrufende App zurück, während der Benutzer spricht, und bietet mehr Informationen zu den Ergebnissen der Übersetzung als nur Text. Dazu zählen unter anderem folgende Einstellungen:
- Mehrere Interpretationen der Aussagen des Benutzers.
- Konfidenzstufen für die einzelnen Übersetzungen.
- Zeitsteuerungsinformationen.
Wie bereits erwähnt, können Audiodaten für die Übersetzung entweder durch einen Livefeed oder von einer vorab aufgezeichneten Quelle und in einer der über 50 Sprachen und Dialekte bereitgestellt werden, die von iOS 10 unterstützt werden.
Die Spracherkennungs-API kann auf jedem iOS-Gerät mit iOS 10 verwendet werden und erfordert in den meisten Fällen eine Live-Internetverbindung, da der Großteil der Übersetzungen auf apple-Servern erfolgt. Das heißt, einige neuere iOS-Geräte unterstützen always On-On-Device-Übersetzungen bestimmter Sprachen.
Apple hat eine Verfügbarkeits-API hinzugefügt, um zu ermitteln, ob eine bestimmte Sprache zum aktuellen Zeitpunkt für die Übersetzung verfügbar ist. Die App sollte diese API verwenden, anstatt die Internetverbindung selbst direkt zu testen.
Wie oben im Abschnitt Tastaturdiktatur erwähnt, erfordert die Spracherkennung die Übertragung und temporäre Speicherung von Daten auf Apple-Servern über das Internet. Daher muss die App die Berechtigung des Benutzers anfordern, die Erkennung durchzuführen, indem sie den Schlüssel in die NSSpeechRecognitionUsageDescriptionInfo.plist Datei einschließt und die SFSpeechRecognizer.RequestAuthorization -Methode aufruft.
Basierend auf der Quelle des Audios, das für die Spracherkennung verwendet wird, können andere Änderungen an der Datei der App Info.plist erforderlich sein. Weitere Informationen finden Sie in unserer Dokumentation zu Sicherheits- und Datenschutzverbesserungen .
Einführen der Spracherkennung in einer App
Es gibt vier wichtige Schritte, die der Entwickler ausführen muss, um die Spracherkennung in einer iOS-App zu übernehmen:
- Geben Sie mithilfe des Schlüssels eine Nutzungsbeschreibung
Info.plistin der Datei der App anNSSpeechRecognitionUsageDescription. Eine Kamera-App könnte beispielsweise die folgende Beschreibung enthalten: "Dies ermöglicht es Ihnen, ein Foto zu machen, indem Sie nur das Wort "Käse" sagen." - Fordern Sie die Autorisierung an, indem Sie die
SFSpeechRecognizer.RequestAuthorization-Methode aufrufen, um eine (imNSSpeechRecognitionUsageDescriptionobigen Schlüssel bereitgestellte) Erklärung zu präsentieren, warum die App spracherkennungszugriff für den Benutzer in einem Dialogfeld verwenden möchte, und den Benutzern das Akzeptieren oder Ablehnen zu gestatten. - Erstellen Sie eine Spracherkennungsanforderung:
- Verwenden Sie für vorab aufgezeichnete Audiodaten auf dem Datenträger die
SFSpeechURLRecognitionRequest-Klasse. - Verwenden Sie für Liveaudio (oder Audio aus dem Arbeitsspeicher) die
SFSPeechAudioBufferRecognitionRequest-Klasse.
- Verwenden Sie für vorab aufgezeichnete Audiodaten auf dem Datenträger die
- Übergeben Sie die Spracherkennungsanforderung an eine Spracherkennung (
SFSpeechRecognizer), um mit der Erkennung zu beginnen. Die App kann optional die zurückgegebeneSFSpeechRecognitionTaskhalten, um die Erkennungsergebnisse zu überwachen und nachzuverfolgen.
Diese Schritte werden unten ausführlich behandelt.
Bereitstellen einer Nutzungsbeschreibung
Gehen Sie wie folgt vor, um den erforderlichen NSSpeechRecognitionUsageDescription Schlüssel in der Info.plist Datei anzugeben:
Doppelklicken Sie auf die
Info.plistDatei, um sie zur Bearbeitung zu öffnen.Wechseln Sie zur Quellansicht :
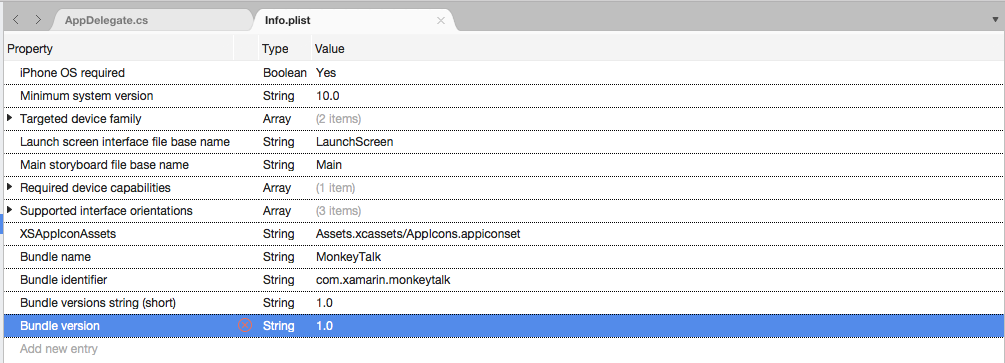
Klicken Sie auf Neuen Eintrag hinzufügen, und geben Sie
NSSpeechRecognitionUsageDescriptionfür die Eigenschaft alsStringTyp und eine Verwendungsbeschreibung als Wert ein. Beispiel:
Wenn die App die Live-Audiotranskription verarbeitet, ist auch eine Beschreibung der Mikrofonnutzung erforderlich. Klicken Sie auf Neuen Eintrag hinzufügen, und geben Sie
NSMicrophoneUsageDescriptionfür die Eigenschaft alsStringTyp und eine Verwendungsbeschreibung als Wert ein. Beispiel:
Speichern Sie die Änderungen in der Datei.





Wichtig
Wenn keine der oben genannten Info.plist Tasten (NSSpeechRecognitionUsageDescription oder NSMicrophoneUsageDescription) bereitgestellt wird, kann die App ohne Warnung fehlschlagen, wenn versucht wird, entweder auf die Spracherkennung oder das Mikrofon für Liveaudio zuzugreifen.
Anfordern der Autorisierung
Um die erforderliche Benutzerautorisierung anzufordern, die der App den Zugriff auf die Spracherkennung ermöglicht, bearbeiten Sie die Standard View Controller-Klasse, und fügen Sie den folgenden Code hinzu:
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
Die RequestAuthorization -Methode der SFSpeechRecognizer -Klasse fordert vom Benutzer die Berechtigung für den Zugriff auf die Spracherkennung an, indem der Grund verwendet wird, den der Entwickler im NSSpeechRecognitionUsageDescription Schlüssel der Info.plist Datei angegeben hat.
Ein SFSpeechRecognizerAuthorizationStatus Ergebnis wird an die Rückrufroutine der RequestAuthorization Methode zurückgegeben, die verwendet werden kann, um aktionen basierend auf der Berechtigung des Benutzers auszuführen.
Wichtig
Apple schlägt vor, zu warten, bis der Benutzer eine Aktion in der App gestartet hat, die Spracherkennung erfordert, bevor diese Berechtigung angefordert wird.
Erkennen von vorab aufgezeichneter Sprache
Wenn die App Sprache aus einer vorab aufgezeichneten WAV- oder MP3-Datei erkennen möchte, kann sie den folgenden Code verwenden:
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
Wenn Sie sich diesen Code im Detail ansehen, wird zunächst versucht, eine SpracherkennungSFSpeechRecognizer () zu erstellen. Wenn die Standardsprache für die Spracherkennung nicht unterstützt wird, wird zurückgegeben, null und die Funktionen werden beendet.
Wenn die Spracherkennung für die Standardsprache verfügbar ist, überprüft die App mithilfe der -Eigenschaft, ob sie derzeit für die Available Erkennung verfügbar ist. Beispielsweise ist die Erkennung möglicherweise nicht verfügbar, wenn das Gerät nicht über eine aktive Internetverbindung verfügt.
Ein SFSpeechUrlRecognitionRequest wird aus dem NSUrl Speicherort der vorab aufgezeichneten Datei auf dem iOS-Gerät erstellt und zur Verarbeitung mit einer Rückrufroutine an die Spracherkennung übergeben.
Wenn der Rückruf aufgerufen wird, ist ein Fehler aufgetreten, der NSErrornull behandelt werden muss. Da die Spracherkennung inkrementell erfolgt, kann die Rückrufroutine mehrmals aufgerufen werden, sodass die SFSpeechRecognitionResult.Final Eigenschaft getestet wird, um festzustellen, ob die Übersetzung abgeschlossen ist und die beste Version der Übersetzung geschrieben wird (BestTranscription).
Erkennen von Live Speech
Wenn die App Live-Sprache erkennen möchte, ist der Prozess dem Erkennen vorab aufgezeichneter Sprache sehr ähnlich. Beispiel:
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
Wenn Sie sich diesen Code im Detail ansehen, werden mehrere private Variablen erstellt, um den Erkennungsprozess zu verarbeiten:
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
Es verwendet AV Foundation zum Aufzeichnen von Audio, das an ein SFSpeechAudioBufferRecognitionRequest übergeben wird, um die Erkennungsanforderung zu verarbeiten:
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
Die App versucht, die Aufzeichnung zu starten, und alle Fehler werden behandelt, wenn die Aufzeichnung nicht gestartet werden kann:
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
Die Erkennungsaufgabe wird gestartet, und ein Handle wird für die Erkennungsaufgabe (SFSpeechRecognitionTask) beibehalten:
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
Der Rückruf wird auf ähnliche Weise wie der oben für die vorab aufgezeichnete Sprache verwendet.
Wenn die Aufzeichnung vom Benutzer beendet wird, werden sowohl die Audio-Engine als auch die Spracherkennungsanforderung informiert:
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
Wenn der Benutzer die Erkennung abbricht, werden die Audio-Engine und die Erkennungsaufgabe informiert:
AudioEngine.Stop ();
RecognitionTask.Cancel ();
Es ist wichtig, aufzurufen RecognitionTask.Cancel , wenn der Benutzer die Übersetzung abbricht, um sowohl Arbeitsspeicher als auch den Prozessor des Geräts freizugeben.
Wichtig
Wenn Sie die NSSpeechRecognitionUsageDescription -Taste oder NSMicrophoneUsageDescriptionInfo.plist nicht angeben, kann die App ohne Warnung fehlschlagen, wenn Sie versuchen, entweder auf die Spracherkennung oder das Mikrofon für Liveaudio (var node = AudioEngine.InputNode;) zuzugreifen. Weitere Informationen finden Sie im Abschnitt Bereitstellen einer Nutzungsbeschreibung oben.
Spracherkennungsgrenzwerte
Apple erzwingt die folgenden Einschränkungen bei der Arbeit mit der Spracherkennung in einer iOS-App:
- Die Spracherkennung ist für alle Apps kostenlos, aber die Nutzung ist nicht unbegrenzt:
- Einzelne iOS-Geräte verfügen über eine begrenzte Anzahl von Erkennungen, die pro Tag ausgeführt werden können.
- Apps werden global auf Anforderungsbasis pro Tag gedrosselt.
- Die App muss darauf vorbereitet sein, Fehler beim Netzwerkverbindungs- und Nutzungslimit der Spracherkennung zu behandeln.
- Die Spracherkennung kann sowohl beim Akkuverbrauch als auch beim hohen Netzwerkdatenverkehr auf dem iOS-Gerät des Benutzers zu hohen Kosten führen. Aus diesem Hintergrund erzwingt Apple eine strikte Audiodauerbegrenzung von etwa einer Minute.
Wenn eine App routinemäßig die Grenzwerte für die Ratendrosselung erreicht, bittet Apple den Entwickler, sie zu kontaktieren.
Überlegungen zu Datenschutz und Benutzerfreundlichkeit
Apple hat den folgenden Vorschlag, um transparent zu sein und die Privatsphäre des Benutzers zu respektieren, wenn die Spracherkennung in eine iOS-App eingeschlossen wird:
- Stellen Sie beim Aufzeichnen der Sprache des Benutzers sicher, dass die Aufzeichnung in der Benutzeroberfläche der App erfolgt. Beispielsweise kann die App einen Aufzeichnungssound wiedergeben und eine Aufzeichnungsanzeige anzeigen.
- Verwenden Sie die Spracherkennung nicht für vertrauliche Benutzerinformationen wie Kennwörter, Integritätsdaten oder Finanzinformationen.
- Zeigen Sie die Erkennungsergebnisse an, bevor Sie darauf reagieren. Dies gibt nicht nur Feedback zur Funktionsweise der App, sondern ermöglicht es dem Benutzer, Erkennungsfehler zu behandeln, während sie auftreten.
Zusammenfassung
In diesem Artikel wurde die neue Speech-API vorgestellt und gezeigt, wie Sie sie in einer Xamarin.iOS-App implementieren, um die kontinuierliche Spracherkennung und das Transkribieren von Sprache (aus Live- oder aufgezeichneten Audiodatenströmen) in Text zu unterstützen.