Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Important
Dieses Feature befindet sich in der Public Preview.
Mit Lakeflow Designer können Sie Datentransformationsworkflows auf einem visuellen, drag-and-drop-Canvas erstellen. Auf dieser Seite wird erläutert, wie Sie eine visuelle Datenvorbereitung erstellen – vom Hinzufügen einer Datenquelle und dem Verketten von Operatoren bis hin zur Vorschau von Ergebnissen und dem Schreiben in den Unity Catalog.
So erstellen Sie eine visuelle Datenvorbereitung:
- Überprüfen der Anforderungen
- Erstellen einer visuellen Datenvorbereitung
- Hinzufügen einer Datenquelle
- Hinzufügen und Konfigurieren von Operatoren
- Verbinden von Operatoren
- Vorschau der Ergebnisse
- Schreiben von Ergebnissen in den Unity-Katalog
- Planung oder Ausführung im Produktionsbetrieb
- Speichern und Verwalten in Git
Anforderungen
Um Lakeflow Designer zu verwenden, müssen Sie folgendes haben:
- Ein Azure Databricks-Arbeitsbereich mit aktiviertem Unity-Katalog.
-
CAN USEBerechtigung für mindestens eine allgemein nutzbare Compute-Ressource (Serverless oder Allzweck).
Erstellen einer neuen visuellen Datenvorbereitung
Um eine neue visuelle Datenvorbereitung zu erstellen, klicken Sie auf ![]() Neu in der Randleiste, und wählen Sie visual data prep aus.
Neu in der Randleiste, und wählen Sie visual data prep aus.
Der Designer wird mit einer Willkommensseite geöffnet, auf der Sie eine Datenquelle hinzufügen oder eine Beispielvorbereitung für visuelle Daten erkunden können.
Hinzufügen einer Datenquelle
Jeder Designerworkflow beginnt mit einer oder mehreren Datenquellen. Der Source-Operator stellt eine Datenquelle auf dem Zeichenbereich dar.
So fügen Sie eine Datenquelle hinzu:
- Fügen Sie einen Source-Operator hinzu. Klicken Sie auf der Willkommensseite auf den Quelloperator auswählen. Öffnen Sie in der Arbeitsfläche das Operatormenü und wählen Sie "Quelle" aus.
- Wählen Sie im Bereich "Quellkonfiguration" aus, wie Ihre Daten angezeigt werden sollen. Sie können nach einer vorhandenen Tabelle suchen, eine lokale CSV- oder Excel-Datei hochladen, eine Tabelle aus einer Datei erstellen oder aus Google Drive oder SharePoint importieren.
- Wählen Sie Ihre Datenquelle aus, oder konfigurieren Sie sie. Der Source-Operator erscheint auf der Leinwand.
Sie können auch eine CSV- oder Excel-Datei direkt auf den Zeichenbereich ziehen und ablegen, um schnell einen Quelloperator zu erstellen.
Um die Quelle später zu ändern, öffnen Sie den Source-Operator, und klicken Sie auf "Neue Datenquelle auswählen". Durch Das Ändern der Quelle wird der Ausgabecache für alle downstream-Operatoren ungültig.
Ausführliche Informationen zu den einzelnen Aufnahmeoptionen finden Sie unter "Daten aufnehmen" in Lakeflow Designer.
Hinzufügen und Konfigurieren von Operatoren
Um einen Operator hinzuzufügen, öffnen Sie das Operatormenü im Seitenbereich auf der linken Seite der Arbeitsfläche. Klicken Sie auf einen Operator, um ihn dem Zeichenbereich hinzuzufügen, oder ziehen Sie einen Operator aus dem Menü auf den Zeichenbereich. Sie können auch auf die + Schaltfläche neben einem beliebigen vorhandenen Operator klicken, um einen neuen Operator mit einer automatischen Verbindung hinzuzufügen.

Um einen Operator zu konfigurieren, doppelklicken Sie darauf, oder halten Sie den Mauszeiger darauf, und klicken Sie auf ![]() (Bearbeitungsoperator), um den Konfigurationsbereich zu öffnen. Legen Sie die Optionen für diesen Operatortyp fest, und klicken Sie dann auf Übernehmen.
(Bearbeitungsoperator), um den Konfigurationsbereich zu öffnen. Legen Sie die Optionen für diesen Operatortyp fest, und klicken Sie dann auf Übernehmen.
Ausführliche Informationen zu jedem verfügbaren Operator finden Sie unter integrierten Operatoren in Lakeflow Designer. Ausführliche Informationen zum Erstellen eigener benutzerdefinierter Operatoren finden Sie unter User-defined operators in Lakeflow Designer.
Verbinden von Operatoren
Um zwei Operatoren zu verbinden, klicken und ziehen Sie vom Ausgabepunkt (dem kleinen Kreis am rechten Rand eines Operators) zum Eingabepunkt (dem kleinen Kreis am linken Rand des nächsten Operators). Dies gibt an, dass Daten vom ersten Operator in die zweite fließen. Daten fließen von links nach rechts durch die visuelle Datenvorbereitung.
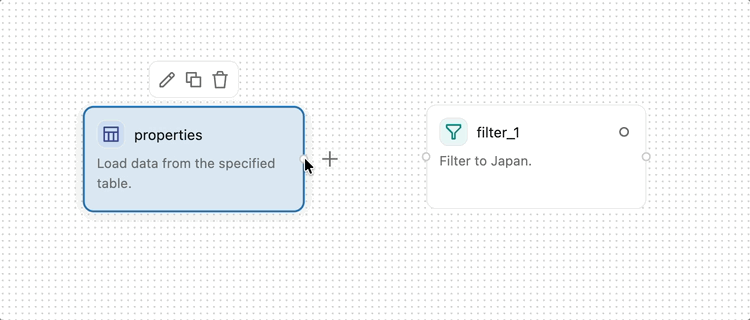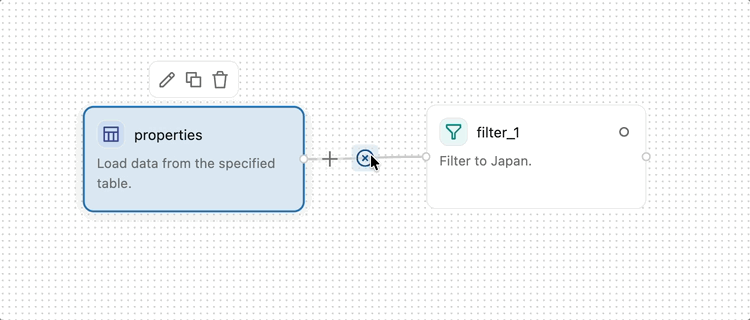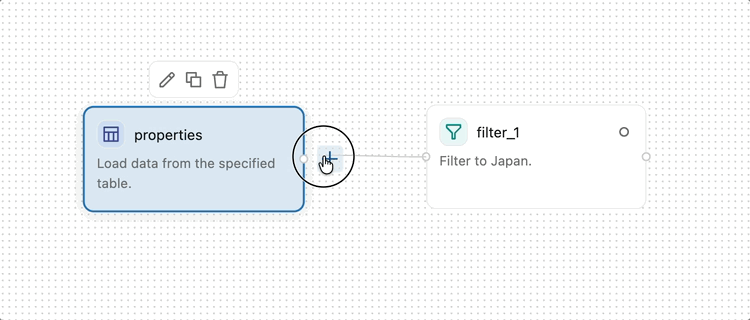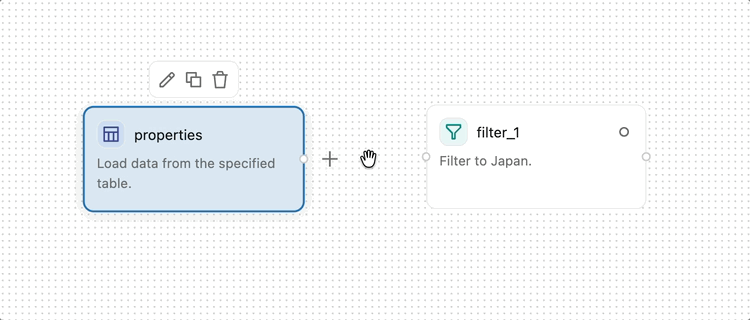
Einige Operatoren, z. B. Join und Combine, akzeptieren mehrere Eingaben.
Verwenden von Genie Code
Sie können jederzeit während der Bearbeitung im Lakeflow-Designer Aufforderungen zu Genie Code erstellen, um Hilfe zu erhalten.
Bei Verwendung von Genie Code bieten die folgenden Schaltflächen zusätzliche Funktionen:
-
 : Lädt ein Bild hoch, das als Teil der Eingabeaufforderung verwendet werden soll.
: Lädt ein Bild hoch, das als Teil der Eingabeaufforderung verwendet werden soll. -
 : Verwenden Sie, um Objekte wie Tabellen oder Dateien zu erwähnen, die als Teil der Eingabeaufforderung verwendet werden sollen.
: Verwenden Sie, um Objekte wie Tabellen oder Dateien zu erwähnen, die als Teil der Eingabeaufforderung verwendet werden sollen. -
 : Startet einen neuen Chatthread mit neuem Agentkontext.
: Startet einen neuen Chatthread mit neuem Agentkontext. -
 : Öffnet den seitlichen Bereich für den Gesprächsverlauf und bietet eine umfassendere Ansicht der Aktivitäten des Agents.
: Öffnet den seitlichen Bereich für den Gesprächsverlauf und bietet eine umfassendere Ansicht der Aktivitäten des Agents.
Genie Code zeigt eine einzeilige Zusammenfassung seiner letzten Bearbeitung über dem Eingabefeld.
Vorschau der Ergebnisse
Wählen Sie einen beliebigen Operator aus, um die Ergebnisse im Ausgabebereich am unteren Rand des Bildschirms anzuzeigen. Bei den meisten Operatortypen befindet sich die Eingabedaten auf der linken Seite, und die Ausgabedaten sind rechts. Operatoren, die Nichttabellenergebnisse erzeugen, z. B. Plots, HTML oder Bilder, rendern diese Ausgaben direkt im Ausgabebereich.
Verwenden Sie die Ansichtssteuerung im Ausgabefenster, um zwischen Eingabe und Ausgabe (Standard), nur Eingabe oder nur Ausgabe zu wechseln. Ziehen Sie in der kombinierten Ansicht die Trennlinie, um die Größe der Eingabe- und Ausgabebereiche zu ändern.
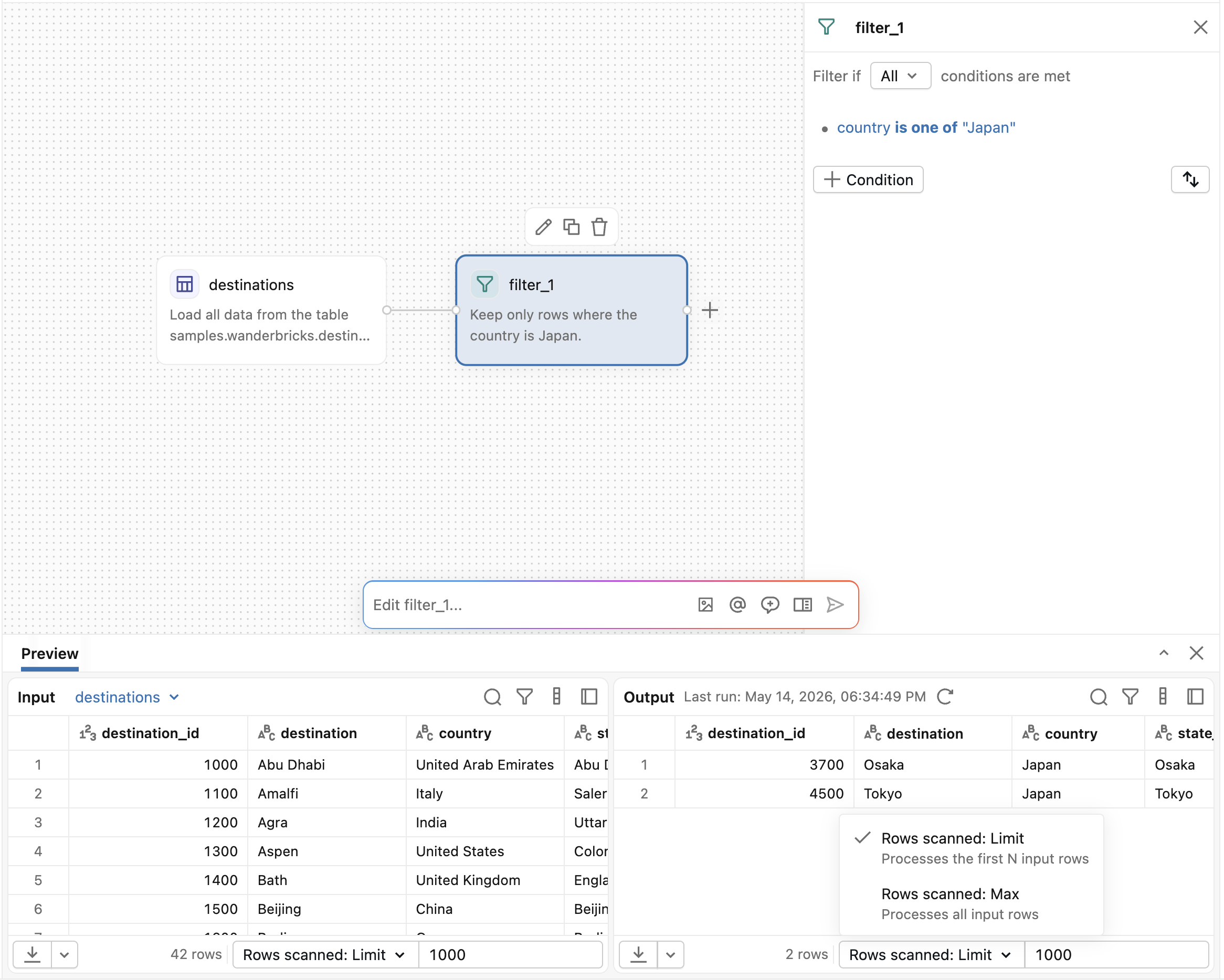
Standardmäßig verarbeiten Operatoren eine begrenzte Stichprobe von Daten. Verwenden Sie die Dropdownliste "Zeilen gescannt" im Ausgabebereich, um zu steuern, wie viele Zeilen verarbeitet werden sollen:
- Gescannte Zeilen: Limit: Verarbeitet die ersten N-Eingabezeilen. Geben Sie die Anzahl der Zeilen im Feld neben dem Dropdown an.
- Gescannte Zeilen: Max: Verarbeitet alle Eingabezeilen.
Warning
Wird mit gescannten Zeilen ausgeführt: Max führt alle Upstreamoperatoren mit dem vollständigen, ungebundenen Dataset erneut aus und kann eine lange Zeit in Anspruch nehmen.
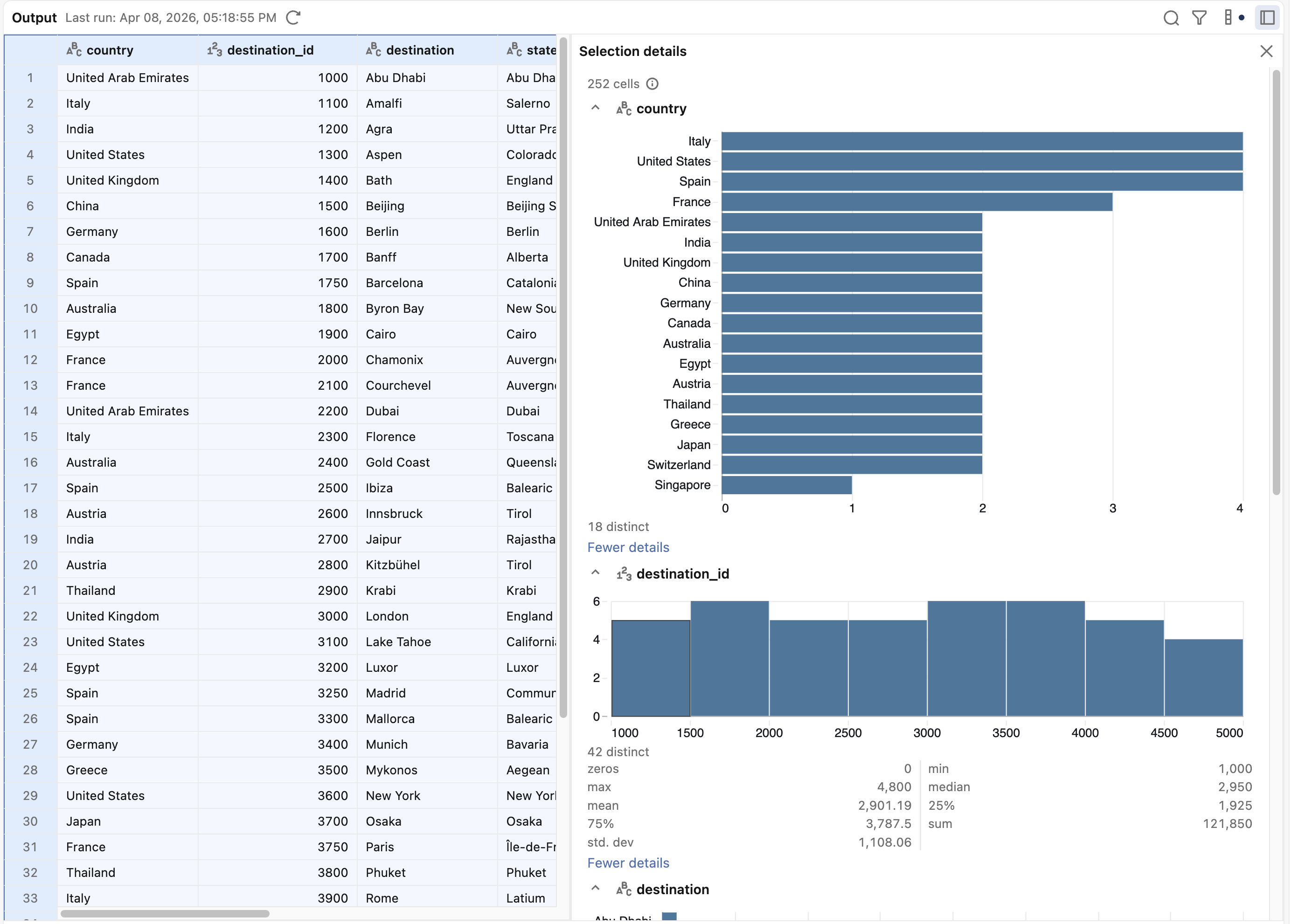
Datenprofilierung
Im Ausgabebereich können Sie auswählen, dass Details zu den Daten in der Ausgabe angezeigt werden. Wählen Sie in der oberen rechten Ecke des Ausgabebereichs das ![]() , um die Auswahldetails zu öffnen. Wählen Sie eine Teilmenge Ihrer Daten aus, um Details zur Auswahl anzuzeigen.
, um die Auswahldetails zu öffnen. Wählen Sie eine Teilmenge Ihrer Daten aus, um Details zur Auswahl anzuzeigen.
Schreiben von Ergebnissen in den Unity-Katalog
Fügen Sie einen Ausgabeoperator hinzu, um Ihre Ergebnisse in eine Tabelle im Unity-Katalog zu schreiben:
- Öffnen Sie das Operatormenü, wählen Sie "Ausgabe" aus, oder klicken Sie neben + dem letzten Operator, und wählen Sie "Ausgabe" aus.
- Verbinden Sie den Ausgabehandle Ihrer letzten Transformation mit dem Eingabehandle des Ausgabeoperators , wenn dies noch nicht verbunden ist.
- Doppelklicken Sie auf den Ausgabeoperator , um den Konfigurationsbereich zu öffnen.
- Geben Sie einen Tabellennamen ein, und wählen Sie den Ausgabespeicherort (Katalog und Schema) aus.
- Klicken Sie auf Ausführen.
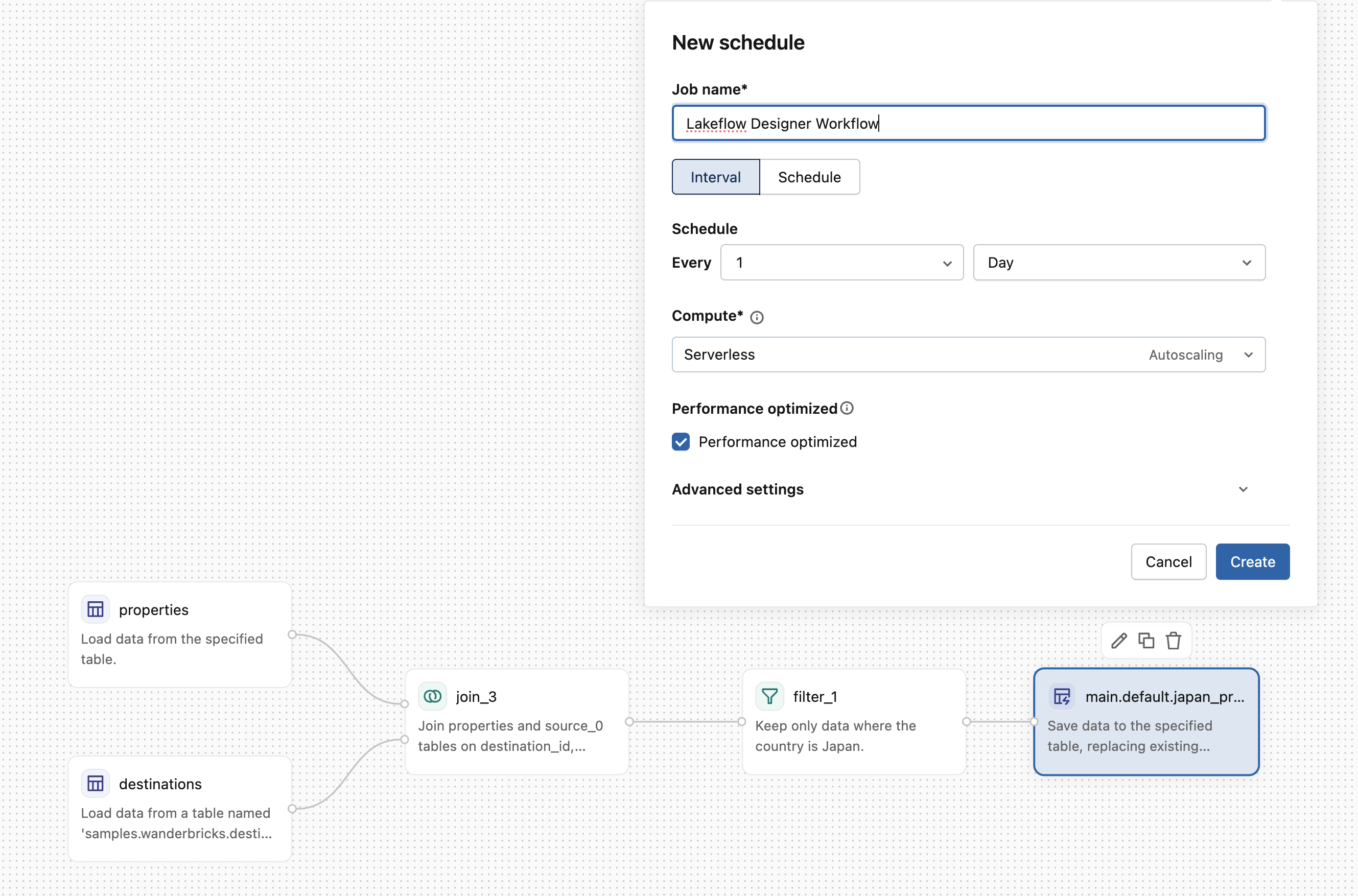
Planen oder in Produktion ausführen
Sie können Ihre Workflows automatisieren, indem Sie sie als Aufträge planen.
- Direkt planen: Klicken Sie im oberen Menü auf die Schaltfläche Zeitplan, um eine geplante Aufgabe für Ihre visuelle Datenaufbereitung zu erstellen.
- Einem Job hinzufügen: Erstellen Sie einen Azure Databricks-Job, und wählen Sie Ihre visuelle Datenaufbereitung als Task aus. Auf diese Weise können Sie diese visuelle Datenaufbereitung mit anderen Aufgaben zu einer größeren Pipeline kombinieren.
Speichern und Verwalten visueller Datenvorbereitungsdateien in Git
Visuelle Datenvorbereitungsdateien werden nativ im Arbeitsbereich gespeichert. Um sie mit Git zu verwenden, erstellen Sie einen Git-Ordner, und platzieren Sie die Datei dort. Wenn sich die Datei in einem Git-Ordner befindet, können Sie Git wie für jede normale Datei oder ein normales Notizbuch verwenden.
Die Datei wird in Git als Notizbuch mit dem Format file_name.designer.ipynbangezeigt.
Weitere Tipps beim Arbeiten im Zeichenbereich
Die folgenden Aktionen stehen auf der Arbeitsfläche zur Verfügung, um Sie beim Bearbeiten Ihrer visuellen Datenaufbereitung zu unterstützen.
- Benennen Sie einen Operator um: Klicken Sie oben im Konfigurationsbereich auf das Textfeld, um den Operator umzubenennen. Beschreibende Namen erleichtern das Verständnis Ihrer visuellen Datenaufbereitung auf einen Blick. Einige Operatoren, z. B. der SQL-Operator, können anhand des Namens auf die Ausgabe anderer Operatoren verweisen.
-
Kopieren Sie einen Operator: Halten Sie den Mauszeiger über einen Operator, und klicken Sie auf
 , oder wählen Sie einen Operator aus, und drücken Sie DANN CMD/STRG+V.
, oder wählen Sie einen Operator aus, und drücken Sie DANN CMD/STRG+V. -
Automatisches Layout: Klicken Sie auf
 In der Kopfzeilensymbolleiste werden alle Operatoren automatisch in einem kompakten Layout angeordnet.
In der Kopfzeilensymbolleiste werden alle Operatoren automatisch in einem kompakten Layout angeordnet. -
Ansicht anpassen: Klicken Sie auf
 In der Kopfzeilensymbolleiste werden alle Operatoren im aktuellen Viewport angezeigt.
In der Kopfzeilensymbolleiste werden alle Operatoren im aktuellen Viewport angezeigt. - Rückgängig machen und wiederholen: Drücken Sie Cmd/Strg+Z und Cmd/Strg+Umschalt+Z oder verwenden Sie die Schaltflächen zum Rückgängigmachen und Wiederholen in der Symbolleiste der Kopfzeile.
- Generierten Code anzeigen: Um den von Designer generierten PySpark-Code anzuzeigen, öffnen Sie den Versionsverlauf im rechten Bereich, verschieben Sie die Datei in einen Git-Ordner, und zeigen Sie ihn dort an, oder zeigen Sie den Code in den Auftragsausführungsdetails an.
Nächste Schritte
- Aufnehmen von Daten in Lakeflow Designer
- Integrierte Operatoren in Lakeflow Designer