Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Dieses Feature befindet sich in der Betaversion. Kontoadministratoren können den Zugriff auf dieses Feature über die Seite " Vorschau" der Kontokonsole steuern. Siehe Manage Azure Databricks Previews.
Auf dieser Seite wird beschrieben, wie Sie die Verwendung für Unity AI Gateway-Endpunkte mithilfe der Systemtabelle zur Nutzungsnachverfolgung überwachen.
In der Tabelle zur Verwendungsnachverfolgung werden Anforderungs- und Antwortdetails für einen Endpunkt automatisch erfasst, wobei wesentliche Metriken wie Tokennutzung und Latenz protokolliert werden. Sie können die Daten in dieser Tabelle verwenden, um die Nutzung zu überwachen, Kosten nachzuverfolgen und Einblicke in die Leistung und den Verbrauch von Endpunkten zu erhalten.
Die Verwendungsnachverfolgung ai_query erfasst auch Anforderungen an von Databricks bereitgestellte Endpunkte.
Anforderungen
- Unity AI Gateway Preview für Ihr Konto aktiviert. Siehe Manage Azure Databricks Previews.
- Ein Azure Databricks-Arbeitsbereich in einer von Unity AI Gateway unterstützten Region.
- Unity-Katalog für Ihren Arbeitsbereich aktiviert. Weitere Informationen finden Sie unter Aktivieren eines Arbeitsbereichs für Unity Catalog.
Nutzungstabelle abfragen
Unity AI Gateway protokolliert Nutzungsdaten in der system.ai_gateway.usage Systemtabelle. Sie können die Tabelle auf der Benutzeroberfläche anzeigen oder die Tabelle aus Databricks SQL oder einem Notizbuch abfragen.
Hinweis
Nur Kontoadministratoren verfügen über die Berechtigung zum Anzeigen oder Abfragen der system.ai_gateway.usage Tabelle.
Um die Tabelle auf der Benutzeroberfläche anzuzeigen, klicken Sie auf der Endpunktseite auf den Link zur Verwendungsnachverfolgungstabelle, um die Tabelle im Katalog-Explorer zu öffnen.
So fragen Sie die Tabelle aus Databricks SQL oder einem Notizbuch ab:
SELECT * FROM system.ai_gateway.usage;
Integriertes Verwendungsdashboard
Erstellen eines integrierten Verwendungsdashboards
Kontoadministratoren können auf der AI-Gateway-Seite durch Klicken auf Create Dashboard ein integriertes Unity AI Gateway-Nutzungsdashboard erstellen, um die Nutzung zu überwachen, Kosten zu verfolgen und Einblicke in die Leistung und Nutzung von Endpunkten zu gewinnen. Kontoadministratoren können auch das Lager aktualisieren, das zum Ausführen von Dashboardabfragen verwendet wird, was für alle nachfolgenden Abfragen gilt.
Hinweis
Die Dashboarderstellung ist auf Kontoadministratoren beschränkt, da sie Berechtigungen für die SELECT Tabelle erfordertsystem.ai_gateway.usage. Die Daten des Dashboards unterliegen den Aufbewahrungsrichtlinien der usage Tabelle. Siehe Welche Systemtabellen sind verfügbar?.
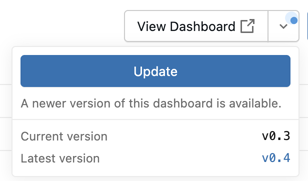
Wenn eine neuere Version des integrierten Nutzungsdashboards verfügbar ist, können Kontoadministratoren im Menü "Dashboardaktionen" auf der SEITE "AI-Gateway" auf " Aktualisieren" klicken.
Sie können die folgenden Dashboardkonfigurationsoptionen verwenden, um das Dashboard zu verwalten:
- Bereich: Wählen Sie aus, ob das Dashboard auf das Konto oder den Arbeitsbereich ausgerichtet werden soll.
- Berechtigungen: Wählen Sie aus, ob Abfragen mit den Berechtigungen des Dashboardbesitzers oder den Berechtigungen jedes Viewers ausgeführt werden. Siehe Freigegebene Datenberechtigungen.
- Automatische Updates: Wenn Sie diese Option aktivieren, wird das Dashboard automatisch aktualisiert, sobald eine neuere Version verfügbar ist, und ein Kontoadministrator besucht die AI Gateway-Seite.
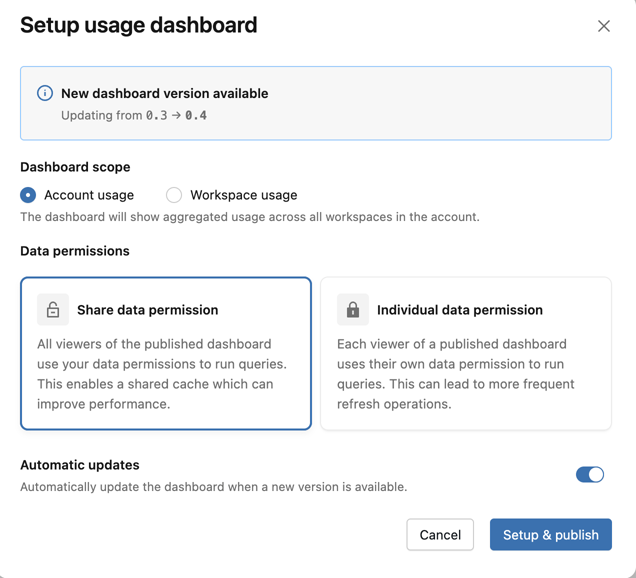
Wenn das Dashboard auf version 0.3 oder höher aktualisiert wird, wird automatisch ein Zeitplan erstellt, um das Dashboard alle 6 Stunden zu aktualisieren. Bei Bedarf kann dieser Zeitplan im Lakeview-Dashboard deaktiviert werden. Siehe Erstellen eines Zeitplans.
Anzeigen des Verwendungsdashboards
Um das Dashboard anzuzeigen, klicken Sie auf der SEITE "AI-Gateway" auf " Dashboard anzeigen ". Das integrierte Dashboard bietet umfassende Einblicke in die Nutzung, Leistung und Kosten von Unity AI Gateway-Endpunkten. Sie umfasst mehrere Seiten zur Nachverfolgung von Anfragen, Tokenverbrauch, Latenzmetriken, Fehlerraten, Kostenaufschlüsselungen, dem Datenverkehr externer MCP-Server und den Aktivitäten von Coding-Agenten.
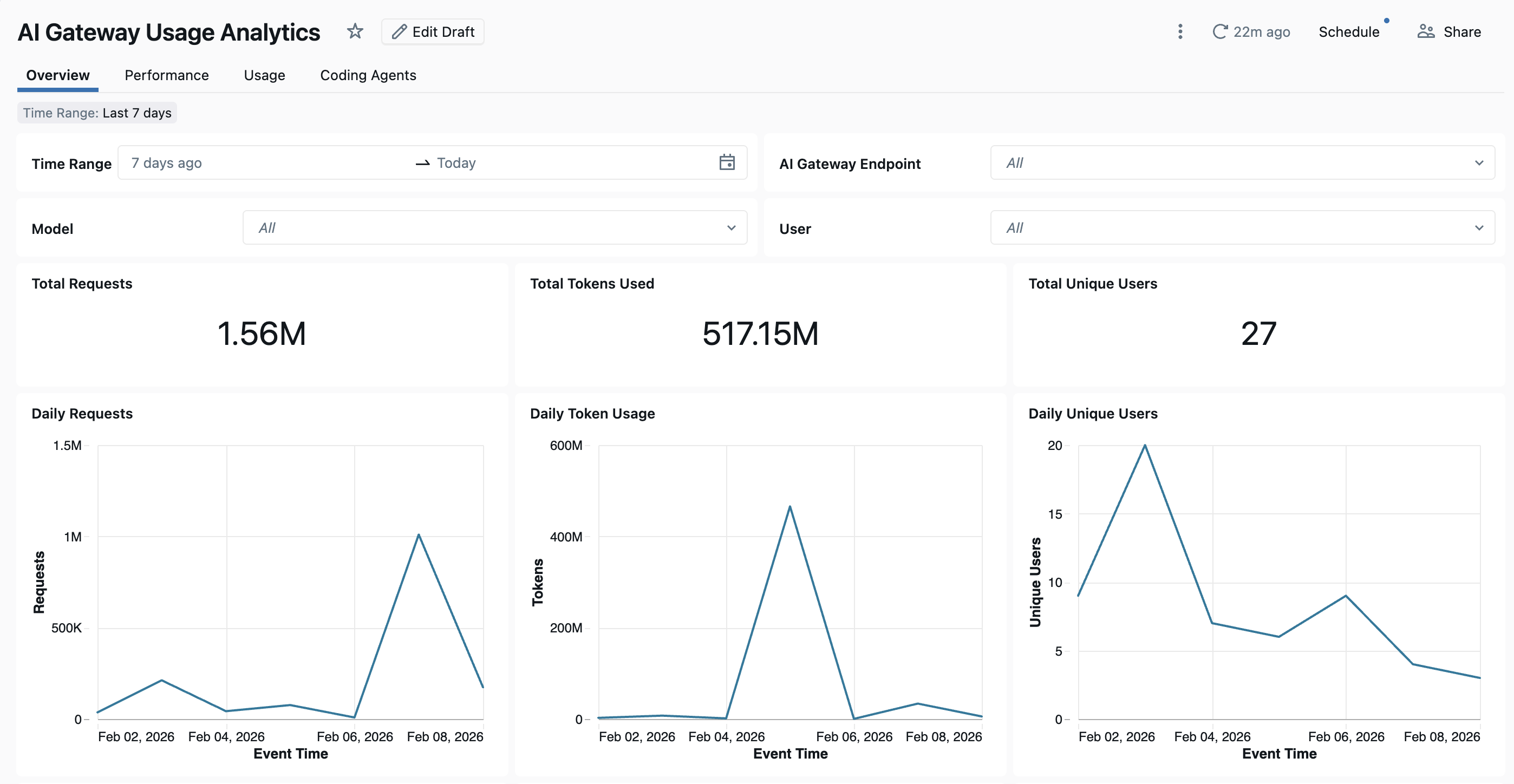
Das Dashboard bietet standardmäßig Arbeitsbereichsübergreifende Analysen. Alle Dashboardseiten können nach Datumsbereich und Arbeitsbereichs-ID gefiltert werden.
- Registerkarte "Übersicht": Zeigt allgemeine Nutzungsmetriken an, einschließlich täglicher Anforderungsvolumen, Tokenverwendungstrends im Laufe der Zeit, top-Benutzer nach Tokenverbrauch und Gesamtzahl eindeutiger Benutzer. Verwenden Sie diese Registerkarte, um eine schnelle Momentaufnahme der gesamten Unity AI Gateway-Aktivität zu erhalten und die aktivsten Benutzer und Modelle zu identifizieren.
- Registerkarte "Leistung": Verfolgt wichtige Leistungsmetriken, einschließlich Latenz-Quantils (P50, P90, P95, P99), Zeit für das erste Byte, Fehlerraten und HTTP-Statuscodeverteilungen. Verwenden Sie diese Registerkarte, um die Endpunktintegrität zu überwachen und Leistungsengpässe oder Zuverlässigkeitsprobleme zu identifizieren.
- Registerkarte "Verwendung": Zeigt detaillierte Verbrauchsaufschlüsselungen nach Endpunkt, Arbeitsbereich und Anforderer an. Auf dieser Registerkarte werden Tokenverwendungsmuster, Anforderungsverteilungen und Cachetrefferverhältnisse angezeigt.
- Registerkarte "Kostenbeobachtung": Zeigt Kostenaufschlüsselungen nach Endpunkt, Zielmodell, Benutzer, Endpunkttags und Anforderungstags an. Diese Registerkarte enthält auch geschätzte Kosten für externe Modelle. Siehe Überwachung der Kosten für Unity AI Gateway.
- Registerkarte "Externer MCP-Server": Zeigt Anforderungsvolumen, Fehlerraten, Benutzer und Verbindungen sowie tägliche Nutzungstrends für externen MCP-Serverdatenverkehr an.
- Registerkarte "Coding-Agenten": Verfolgt Aktivitäten von integrierten Coding-Agenten wie Cursor, Claude Code, Gemini CLI und Codex CLI. Diese Registerkarte zeigt Metriken wie aktive Tage, Codierungssitzungen, Commits und Codezeilen an, die hinzugefügt oder entfernt wurden, um die Verwendung des Entwicklertools zu überwachen. Weitere Details finden Sie im Codierungs-Agent-Dashboard .
Verwendungstabellenschema
Die system.ai_gateway.usage Tabelle weist das folgende Schema auf:
| Spaltenname | Typ | Description | Example |
|---|---|---|---|
account_id |
STRING | Die Konto-ID. | 11d77e21-5e05-4196-af72-423257f74974 |
workspace_id |
STRING | Die Arbeitsbereichs-ID. | 1653573648247579 |
request_id |
STRING | Ein eindeutiger Bezeichner für die Anforderung. | b4a47a30-0e18-4ae3-9a7f-29bcb07e0f00 |
schema_version |
INTEGER | Die Schemaversion des Verwendungsdatensatzes. | 1 |
endpoint_id |
STRING | Die eindeutige ID des Unity AI Gateway-Endpunkts. | 43addf89-d802-3ca2-bd54-fe4d2a60d58a |
endpoint_name |
STRING | Der Name des Unity AI Gateway-Endpunkts. | databricks-gpt-5-2 |
endpoint_tags |
MAP | Tags, die zum Zeitpunkt der Erstellung oder Aktualisierung auf dem Endpunkt konfiguriert sind. Endpunkttags gelten für alle Anforderungen am Endpunkt und eignen sich für die Kategorisierung von Endpunkten nach Team, Kostenstelle oder Projekt. Informationen zur Verwendungsnachverfolgung finden Sie unter Tag-Anforderungen und -Endpunkte. | {"team": "engineering"} |
endpoint_metadata |
STRUCT | Endpunktmetadaten, einschließlich creator, creation_time, last_updated_time, destinations, inference_tableund fallbacks. |
{"creator": "user.name@email.com", "creation_time": "2026-01-06T12:00:00.000Z", ...} |
event_time |
TIMESTAMP | Der Zeitstempel, zu dem die Anforderung empfangen wurde. | 2026-01-20T19:48:08.000+00:00 |
latency_ms |
LONG | Die Gesamtlatenz in Millisekunden. | 300 |
time_to_first_byte_ms |
LONG | Die Zeit für das erste Byte in Millisekunden. | 300 |
destination_type |
STRING | Der Zieltyp (z. B. externes Modell oder Foundation-Modell). | PAY_PER_TOKEN_FOUNDATION_MODEL |
destination_name |
STRING | Der Name des Zielmodells oder Anbieters. | databricks-gpt-5-2 |
destination_id |
STRING | Die eindeutige ID des Ziels. | 507e7456151b3cc89e05ff48161efb87 |
destination_model |
STRING | Das für die Anforderung verwendete spezifische Modell. | GPT-5.2 |
requester |
STRING | Die ID des Benutzers oder Dienstprinzipals, der die Anforderung gestellt hat. | user.name@email.com |
requester_type |
STRING | Der Typ des Anforderers (Benutzer, Dienstprinzipal oder Benutzergruppe). | USER |
ip_address |
STRING | Die IP-Adresse des Anforderers. | 1.2.3.4 |
url |
STRING | Die URL der Anforderung. | https://<workspace-url>/ai-gateway/mlflow/v1/chat/completions |
user_agent |
STRING | Der Benutzer-Agent des Anforderers. | OpenAI/Python 2.13.0 |
api_type |
STRING | Der Typ des API-Aufrufs (z. B. Chat, Fertigstellungen oder Einbettungen). | mlflow/v1/chat/completions |
request_tags |
MAP | Vom Benutzer bereitgestellte Tags, die mit einzelnen Anfragen über den HTTP-Header Databricks-Ai-Gateway-Request-Tags gesendet werden. Verwenden Sie Anforderungstags, um die Verwendung bestimmten Projekten, Teams, Umgebungen oder Endbenutzern zuzuordnen. Weitere Informationen finden Sie unter Tag-Anforderungen und -Endpunkte für die Verwendungsnachverfolgung und Tag-Anforderungen für die Verwendungsnachverfolgung. |
{"project": "chatbot", "team": "ml-platform"} |
input_tokens |
LONG | Die Anzahl der Eingabetoken. | 100 |
output_tokens |
LONG | Die Anzahl der Ausgabetoken. | 100 |
total_tokens |
LONG | Die Gesamtzahl der Token (Eingabe + Ausgabe). | 200 |
token_details |
STRUCT | Detaillierte Tokenaufschlüsselung einschließlich cache_read_input_tokens, cache_creation_input_tokensund output_reasoning_tokens. |
{"cache_read_input_tokens": 100, ...} |
response_content_type |
STRING | Der Inhaltstyp der Antwort. | application/json |
status_code |
INT | Der HTTP-Statuscode der Antwort. | 200 |
routing_information |
STRUCT | Routeninformationen für Fallback-Versuche. Enthält ein attempts Array mit priority, action, destinationdestination_idstatus_codeerror_code, latency_msund start_timeend_time für jedes Modell, das während der Anforderung versucht wurde. |
{"attempts": [{"priority": "1", ...}]} |
Kennzeichnen von Anfragen und Endpunkten zur Nutzungsverfolgung
AI-Gateway unterstützt zwei Arten von Tags für die Nachverfolgung und Attributierung der Verwendung:
- Anforderungstags: Benutzerdefinierte Schlüsselwertpaare, die der Aufrufer an einzelne Anforderungen anfügt. Verwenden Sie Anforderungstags, um die Verwendung nach Projekt, Team, Umgebung, Endbenutzer oder einer anderen Dimension zu attributieren, die für Ihre Organisation relevant ist.
- Endpunkttags: Schlüsselwertpaare, die auf dem Endpunkt selbst konfiguriert sind. Endpunkttags gelten für alle Anforderungen, die über den Endpunkt weitergeleitet werden, und eignen sich für die Kategorisierung von Endpunkten nach Team, Kostenstelle oder Anwendung.
Beide Tagtypen werden in der system.ai_gateway.usage Tabelle protokolliert und können verwendet werden, um Nutzungsdaten zu filtern, zu aggregieren und zu analysieren.
Anfrage-Tags
Um einzelne Anfragen zu kennzeichnen, fügen Sie den Databricks-Ai-Gateway-Request-Tags HTTP-Header mit einem JSON-Objekt hinzu, das Zeichenfolgenschlüssel Zeichenfolgenwerten zuordnet. Anfrage-Tags werden in der request_tags Spalte der Nutzungstabelle und in Inferenztabellen protokolliert.
Beispiele zum Festlegen von Anforderungstags mit REST-API, OpenAI SDK und Anthropic SDK finden Sie unter Tag-Anforderungen für die Verwendungsnachverfolgung.
Beispielsweise können Sie die Nutzung nach Projekt mithilfe von Anforderungstags aggregieren:
SELECT
request_tags['project'] AS project,
COUNT(*) AS request_count,
SUM(total_tokens) AS total_tokens
FROM system.ai_gateway.usage
WHERE request_tags['project'] IS NOT NULL
GROUP BY request_tags['project']
ORDER BY total_tokens DESC;
Endpunkt-Tags
Endpunkttags werden beim Erstellen oder Aktualisieren eines AI-Gateway-Endpunkts konfiguriert. Sie werden in der endpoint_tags Spalte der Verwendungstabelle für alle Anforderungen an diesen Endpunkt angezeigt.
Beispielsweise können Sie die Nutzung nach Team mithilfe von Endpunkttags aggregieren:
SELECT
endpoint_tags['team'] AS team,
endpoint_name,
COUNT(*) AS request_count,
SUM(total_tokens) AS total_tokens
FROM system.ai_gateway.usage
WHERE endpoint_tags['team'] IS NOT NULL
GROUP BY endpoint_tags['team'], endpoint_name
ORDER BY total_tokens DESC;