Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Ein Projekt ist der Container auf oberster Ebene für Ihre Lakebase-Ressourcen, einschließlich Verzweigungen, Berechnungen, Datenbanken und Rollen. Auf dieser Seite wird erläutert, wie Sie Projekte erstellen, deren Struktur verstehen, Einstellungen konfigurieren und ihren Lebenszyklus verwalten.
Wenn Sie noch nicht mit Lakebase vertraut sind, beginnen Sie mit "Erste Schritte ", um Ihr erstes Projekt zu erstellen.
Grundlegendes zu Projekten
Projektstruktur
Das Verständnis der Lakebase-Projektstruktur hilft Ihnen, Ihre Ressourcen effektiv zu organisieren und zu verwalten. Ein Projekt ist der Container der obersten Ebene für Ihre Datenbanken, Branches, Rechenressourcen und zugehörigen Ressourcen. Jedes Projekt enthält Einstellungen für die Berechnung von Standardwerten, Wiederherstellen von Fenstern und Updates, die für alle Verzweigungen innerhalb des Projekts gelten.
Auf oberster Ebene enthält ein Projekt eine oder mehrere Verzweigungen. Innerhalb eines Projekts können Sie Verzweigungen für verschiedene Umgebungen wie Entwicklung, Tests, Staging und Produktion erstellen. Jede Niederlassung enthält eigene Rechenressourcen, Rollen und Datenbanken.
Project
└── Branches (main, development, staging, etc.)
├── Computes (R/W compute)
├── Roles (Postgres roles)
└── Databases (Postgres databases)
Zweige
Die Daten befinden sich in Niederlassungen. Jedes Lakebase-Projekt wird mit einem Stammzweig erstellt, der nicht productiongelöscht werden kann. Sie können zwar zusätzliche Verzweigungen erstellen und eine andere Verzweigung als Standardverzweigung festlegen, die Stammverzweigung kann jedoch nicht gelöscht werden.
Sie können aus jedem Branch in Ihrem Projekt ein Subbranch erstellen. Wenn Sie einen untergeordneten Branch erstellen, erbt dieser alle Datenbanken, Rollen und Daten von seinem übergeordneten Branch zum Zeitpunkt der Erstellung. Nachfolgende Änderungen in der übergeordneten Verzweigung werden nicht automatisch an die untergeordnete Verzweigung weitergegeben, wodurch isolierte Entwicklung, Tests oder Experimente ermöglicht werden.
Jeder Zweig kann mehrere Datenbanken und Rollen enthalten. Weitere Informationen: Verwalten von Filialen
Berechnet
Eine Berechnung ist eine virtualisierte Computerressource, die vCPU und Speicher für die Ausführung von Postgres enthält. Wenn Sie ein Projekt erstellen, wird für den Standardzweig des Projekts ein primäres R/W-Rechenelement (Lese-/Schreibzugriff) erstellt. Jede Verzweigung verfügt über eine einzelne primäre R/W-Berechnung. Um eine Verbindung mit einer Datenbank herzustellen, die sich in einer Verzweigung befindet, müssen Sie eine Verbindung über den R/W-Compute herstellen, der der Verzweigung zugeordnet ist.
Zusätzlich zur primären R/W-Berechnung können Sie jeder Verzweigung einen oder mehrere Read-Only-Computes hinzufügen. Mit Lesereplikaten können Sie schreibgeschützte Workloads von Ihrer primären Recheneinheit für Anwendungsfälle wie horizontale Leseskalierung, Abfragen für Analyse- und Berichtszwecke sowie schreibgeschützten Zugriff für Benutzer und Anwendungen auslagern. Weitere Informationen: Verwalten von Berechnungen, Lesen von Replikaten
Rollen
Rollen sind Postgres-Rollen. Zum Erstellen und Zugreifen auf eine Datenbank ist eine Rolle erforderlich. Eine Rolle gehört zu einem Branch. Wenn Sie ein Projekt erstellen, wird automatisch eine Postgres-Rolle für Ihre Databricks-Identität erstellt (z. B user@databricks.com. ), die der Besitzer der Standarddatenbank databricks_postgres ist. Jede in der Lakebase-Benutzeroberfläche erstellte Rolle wird mit databricks_superuser Berechtigungen erstellt. Es gibt ein Limit von 500 Rollen pro Branch. Weitere Informationen: Verwalten von Rollen
Datenbanken
Eine Datenbank ist ein Container für SQL-Objekte wie Schemas, Tabellen, Ansichten, Funktionen und Indizes. In Lakebase gehört eine Datenbank zu einem Zweig. Die Standardverzweigung des Projekts wird mit einer Datenbank mit dem Namen databricks_postgres erstellt. Es gibt eine Grenze von 500 Datenbanken pro Zweigstelle. Weitere Informationen: Verwalten von Datenbanken
Schemata
Alle Datenbanken in Lakebase werden mit einem public Schema erstellt, bei dem es sich um das Standardverhalten für jede standardmäßige Postgres-Instanz handelt. SQL-Objekte werden standardmäßig im public Schema erstellt.
Projektgrenzen
Lakebase Postgres erzwingt die folgenden Grenzwerte für Projekte:
| Resource | Limit |
|---|---|
| Maximale Anzahl der gleichzeitig aktiven Recheneinheiten | 20 |
| Maximale Anzahl von Lesereplikaten pro Zweig | 6 |
| Maximale Anzahl von Verzweigungen pro Projekt | 500 |
| Maximale Anzahl von Postgres-Rollen pro Branch | 500 |
| Maximale Anzahl von Postgres-Datenbanken pro Zweig | 500 |
| Datenbankspeicherkontingent (pro Branch) | 16 TB |
| Maximale Anzahl von Projekten pro Arbeitsbereich | 1.000 |
| Maximale Anzahl geschützter Verzweigungen | 1 |
| Maximale Anzahl von Stammzweigen | 3 |
| Maximale Anzahl nicht archivierter Verzweigungen | 10 |
| Maximale Anzahl manueller Momentaufnahmen | 10 |
| Maximale Aufbewahrungsfrist für Verlauf | 30 Tage |
| Minimale Skalierung auf Nullzeit | 60 Sekunden |
| Maximale Skalierung auf Nullzeit | 7 Tage |
Gleichzeitig aktive Berechnungsgrenze
Die gleichzeitig aktiven Berechnungsgrenzwerte begrenzen, wie viele Computes gleichzeitig ausgeführt werden können, um die Ressourcenauslastung zu verhindern. Dieser Grenzwert schützt vor versehentlichen Ressourcenfluten, z. B. gleichzeitiges Starten vieler Computeendpunkte. Der Standardgrenzwert ist 20 gleichzeitig aktive Berechnungen pro Projekt.
Wichtig: Die Standardverzweigung ist von diesem Grenzwert ausgenommen und stellt sicher, dass sie jederzeit verfügbar bleibt.
Wenn Sie den Grenzwert überschreiten, bleiben zusätzliche Berechnungen über den Grenzwert hinaus ausgesetzt, und beim Versuch, eine Verbindung mit diesen herzustellen, wird ein Fehler angezeigt. Problembehebung:
- Deaktivieren Sie andere aktive Computer und versuchen Sie es erneut.
- Wenn dieser Fehler häufig auftritt, wenden Sie sich an den Databricks-Support, um eine Grenzwerterhöhung anzufordern.
Hinweis
Instanzen mit aktivierter Skalierung auf Null werden nach einer Phase der Inaktivität automatisch ausgesetzt, um sicherzustellen, dass Sie innerhalb des gleichzeitig aktiven Berechnungslimits bleiben.
Datenbankspeicherkontingent
Jede Niederlassung verfügt über ein Speicherkontingent von 16 TB für Datenbanken.
Wenn eine Datenbank ihr Kontingent erreicht, fällt die Leistung ab, Sie können jedoch weiterhin Daten ablegen oder löschen, um Speicherplatz freizulegen. Wenden Sie sich an den Databricks-Support, wenn Sie ein größeres Kontingent benötigen.
Nur Ihre tatsächlichen Daten (Tabellen und Indizes, wie von Postgres gemeldet) zählt gegen das Kontingent. Der Verlauf, der für die Zeitpunktwiederherstellung beibehalten wird, wird nicht beibehalten.
Regionale Verfügbarkeit
Unterstützte Regionen:
-
eastus(Ost-USA) -
eastus2(Ost-USA 2) -
centralus(Zentral-USA) -
southcentralus(Süd-Zentral-USA) -
westus(West-USA) -
westus2(West-USA 2) -
canadacentral(Kanada Zentral) -
brazilsouth(Brasilien Süd) -
northeurope(Nordeuropa) -
uksouth(Vereinigtes Königreich Süd) -
westeurope(Westeuropa) -
australiaeast(Australien Ost) -
centralindia(Zentralindien) -
southeastasia(Südostasien)
Ihr Lakebase-Projekt wird in Ihrer Arbeitsbereichsregion Databricks erstellt.
Unterstützung für Postgres-Versionen
Lakebase Postgres Autoscaling unterstützt Postgres 16 und Postgres 17.
Erstellen und Verwalten von Projekten
Erstellen eines Projekts
Sie können mehrere Projekte in Lakebase Postgres erstellen, um Anwendungen oder Kunden vollständig isoliert zu halten und eine saubere Trennung von Daten und Ressourcen sicherzustellen.
So erstellen Sie ein Projekt:
Benutzeroberfläche
- Klicken Sie auf den App-Switcher in der oberen rechten Ecke, um die Lakebase-App zu öffnen.
- Klicke auf Neues Projekt.
- Konfigurieren Sie Ihre Projekteinstellungen:
-
Anzeigename: Geben Sie einen Namen für Ihr Projekt ein. Sie können beliebige Zeichen verwenden, einschließlich Leerzeichen und Sonderzeichen. Allgemeine Benennungsmuster umfassen die Benennung nach der Anwendung (z. B.
My Analytics App) oder nach dem Kunden oder Mandanten, dem das Projekt dient (z. B.Acme Corp DB). Ein Ressourcenname wird automatisch von Ihrem Anzeigenamen abgeleitet und wird verwendet, um das Projekt in API- und SDK-Aufrufen zu identifizieren. Das Dialogfeld zeigt den resultierenden Ressourcennamen (zum Beispielprojects/my-analytics-app), damit Sie ihn vor dem Erstellen des Projekts überprüfen können. - Postgres-Version: Wählen Sie die Postgres-Version aus, die Sie verwenden möchten.
- Serverlose Nutzungsrichtlinie (optional): Wählen Sie eine serverlose Nutzungsrichtlinie aus, um serverlose Berechnungskosten einer bestimmten Richtlinie zuzuordnen. Siehe Serverlose Nutzungsrichtlinien.
-
Anzeigename: Geben Sie einen Namen für Ihr Projekt ein. Sie können beliebige Zeichen verwenden, einschließlich Leerzeichen und Sonderzeichen. Allgemeine Benennungsmuster umfassen die Benennung nach der Anwendung (z. B.
Im Dialogfeld "Projekt erstellen " werden die Projektkonfigurationsoptionen angezeigt.
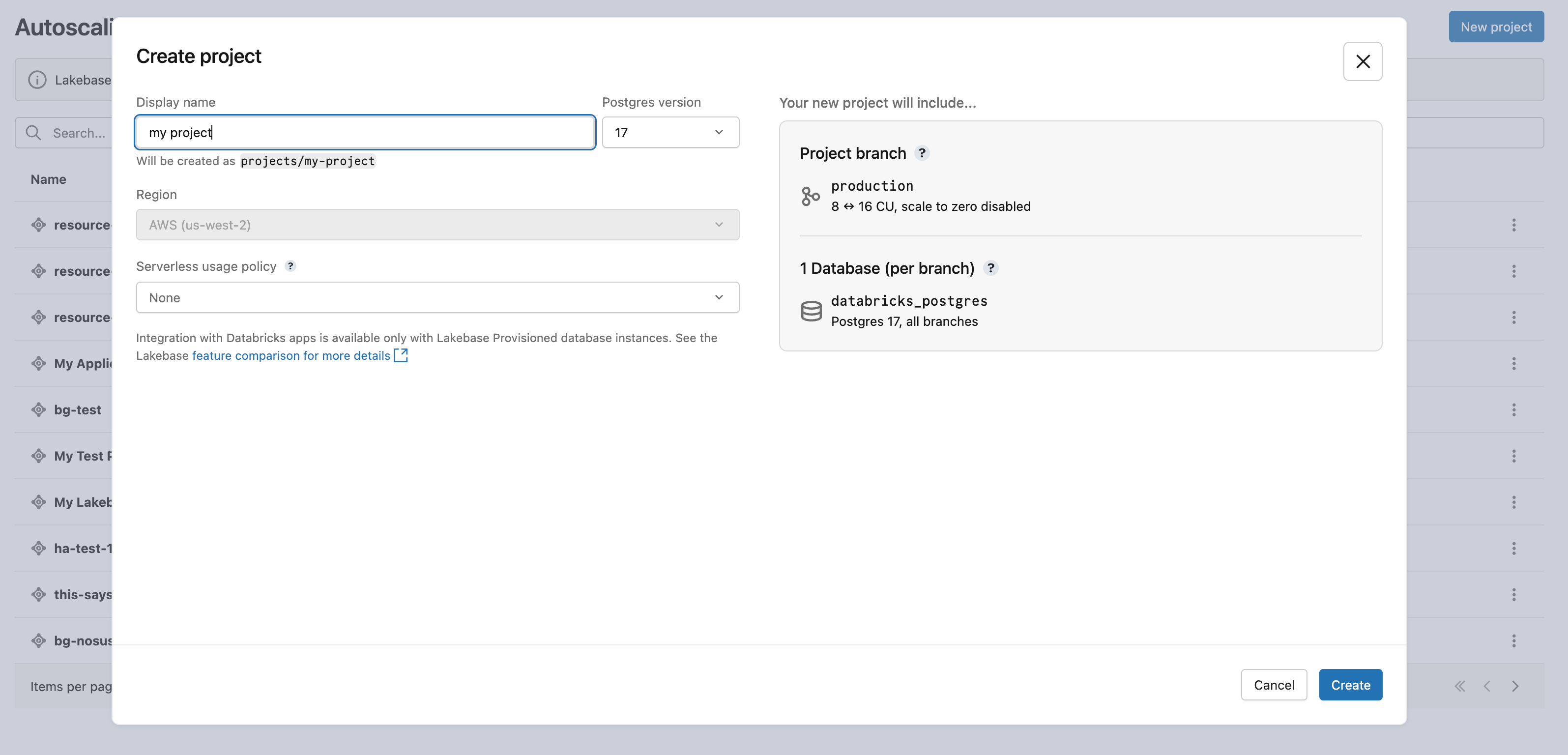
Die Region für Ihr Lakebase-Projekt ist auf Ihre Databricks-Arbeitsbereichsregion festgelegt und kann nicht geändert werden.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec
# Initialize the Workspace client
w = WorkspaceClient()
# Create a project with a custom project ID
operation = w.postgres.create_project(
project=Project(
spec=ProjectSpec(
display_name="My Application",
pg_version=17,
budget_policy_id="<policy-id>"
)
),
project_id="my-app"
)
# Wait for operation to complete
result = operation.wait()
print(f"Created project: {result.name}")
print(f"Display name: {result.status.display_name}")
print(f"Postgres version: {result.status.pg_version}")
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
// Initialize the Workspace client
WorkspaceClient w = new WorkspaceClient();
// Create a project with a custom project ID
CreateProjectOperation operation = w.postgres().createProject(
new CreateProjectRequest()
.setProjectId("my-app")
.setProject(new Project()
.setSpec(new ProjectSpec()
.setDisplayName("My Application")
.setPgVersion(17L)))
);
// Wait for operation to complete
Project result = operation.waitForCompletion();
System.out.println("Created project: " + result.getName());
System.out.println("Display name: " + result.getStatus().getDisplayName());
System.out.println("Postgres version: " + result.getStatus().getPgVersion());
Befehlszeilenschnittstelle (CLI)
# Create a project with a custom project ID
databricks postgres create-project my-app \
--json '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}'
cURL
Erstellen Sie ein Projekt mit einer benutzerdefinierten Projekt-ID. Der project_id Parameter wird als Abfrageparameter angegeben und wird Teil des Ressourcennamens des Projekts (z. B projects/my-app. ).
curl -X POST "$WORKSPACE/api/2.0/postgres/projects?project_id=my-app" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}' | jq
Dieser Vorgang läuft über einen längeren Zeitraum. Die Antwort enthält einen Vorgangsnamen, den Sie zum Überprüfen des Status verwenden können. Der Vorgang wird in der Regel innerhalb von Sekunden abgeschlossen.
Der project_id-Parameter ist erforderlich.
Hinweis
Wenn Sie ein Projekt mit derselben ID wie ein kürzlich gelöschtes Projekt erstellen, beachten Sie, dass gelöschte Projekt-IDs 7 Tage lang reserviert sind. Um die ID sofort wiederzuverwenden, löschen Sie zuerst das ursprüngliche Projekt endgültig.
Ein neues Projekt enthält standardmäßig die folgenden Ressourcen:
Eine einzelne
productionVerzweigung (Standardverzweigung)Eine einzelne primäre Lese-/Schreib-Computing-Einheit, die der Verzweigung zugeordnet ist, mit den folgenden Standardeinstellungen:
Branch Computeeinheiten (CU) Hochverfügbarkeit Automatische Skalierung Zu Null skalieren production8 - 16 CU Deaktiviert Aktiviert Aktiviert (24h) Wenn Sie ein Projekt erstellen, wird der
productionBranch mit einer Compute-Instanz erstellt, bei der standardmäßig Scale-to-Zero mit einem Inaktivitäts-Timeout von 24 Stunden aktiviert ist. Sie können das Timeout anpassen oder die Skalierung auf null für diese Compute-Ressource bei Bedarf deaktivieren.Eine Postgres-Datenbank (benannt
databricks_postgres)Eine Postgres-Rolle für Ihre Databricks-Identität (z. B
user@databricks.com. )
Informationen zum Ändern der Berechnungseinstellungen für ein vorhandenes Projekt finden Sie unter "Konfigurieren von Projekteinstellungen". Informationen zum Ändern der Standardeinstellungen für Berechnungen in neuen Projekten finden Sie unter Compute defaults in Konfigurieren von Projekteinstellungen.
Projektdetails abrufen
Rufen Sie Details für ein bestimmtes Projekt ab.
Benutzeroberfläche
- Klicken Sie auf den App-Switcher in der oberen rechten Ecke, um die Lakebase-App zu öffnen.
- Wählen Sie Ihr Projekt aus der Projektliste aus, um die Details anzuzeigen.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get project details
project = w.postgres.get_project(name="projects/my-project")
print(f"Project: {project.name}")
print(f"Display name: {project.status.display_name}")
print(f"Postgres version: {project.status.pg_version}")
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Project;
WorkspaceClient w = new WorkspaceClient();
// Get project details
Project project = w.postgres().getProject("projects/my-project");
System.out.println("Project: " + project.getName());
System.out.println("Display name: " + project.getStatus().getDisplayName());
System.out.println("Postgres version: " + project.getStatus().getPgVersion());
Befehlszeilenschnittstelle (CLI)
# Get project details
databricks postgres get-project projects/my-project
cURL
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Die Antwort umfasst:
-
name: Ressourcenname (projects/my-project) -
status: Projektkonfiguration und aktueller Zustand (display_name, pg_version usw.)
Hinweis: Das spec Feld wird für GET Vorgänge nicht aufgefüllt. Alle Ressourceneigenschaften werden im status Feld zurückgegeben.
Projekte auflisten
Listet alle Projekte in Ihrem Arbeitsbereich auf.
Benutzeroberfläche
- Klicken Sie auf den App-Switcher in der oberen rechten Ecke, um die Lakebase-App zu öffnen.
- In der Projektliste werden alle Projekte angezeigt, auf die Sie Zugriff haben.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all projects
projects = w.postgres.list_projects()
for project in projects:
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
print(f" Postgres version: {project.status.pg_version}")
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all projects
for (Project project : w.postgres().listProjects(new ListProjectsRequest())) {
System.out.println("Project: " + project.getName());
System.out.println(" Display name: " + project.getStatus().getDisplayName());
System.out.println(" Postgres version: " + project.getStatus().getPgVersion());
}
Befehlszeilenschnittstelle (CLI)
# List all projects
databricks postgres list-projects
cURL
curl -X GET "$WORKSPACE/api/2.0/postgres/projects" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Antwortformat:
{
"projects": [
{
"name": "projects/my-project",
"status": {
"display_name": "My Project",
"pg_version": 17
}
}
]
}
Konfigurieren von Projekteinstellungen
Nach dem Erstellen eines Projekts können Sie verschiedene Einstellungen aus dem Projektdashboard ändern, indem Sie zu "Einstellungen" navigieren:
Allgemeine Einstellungen
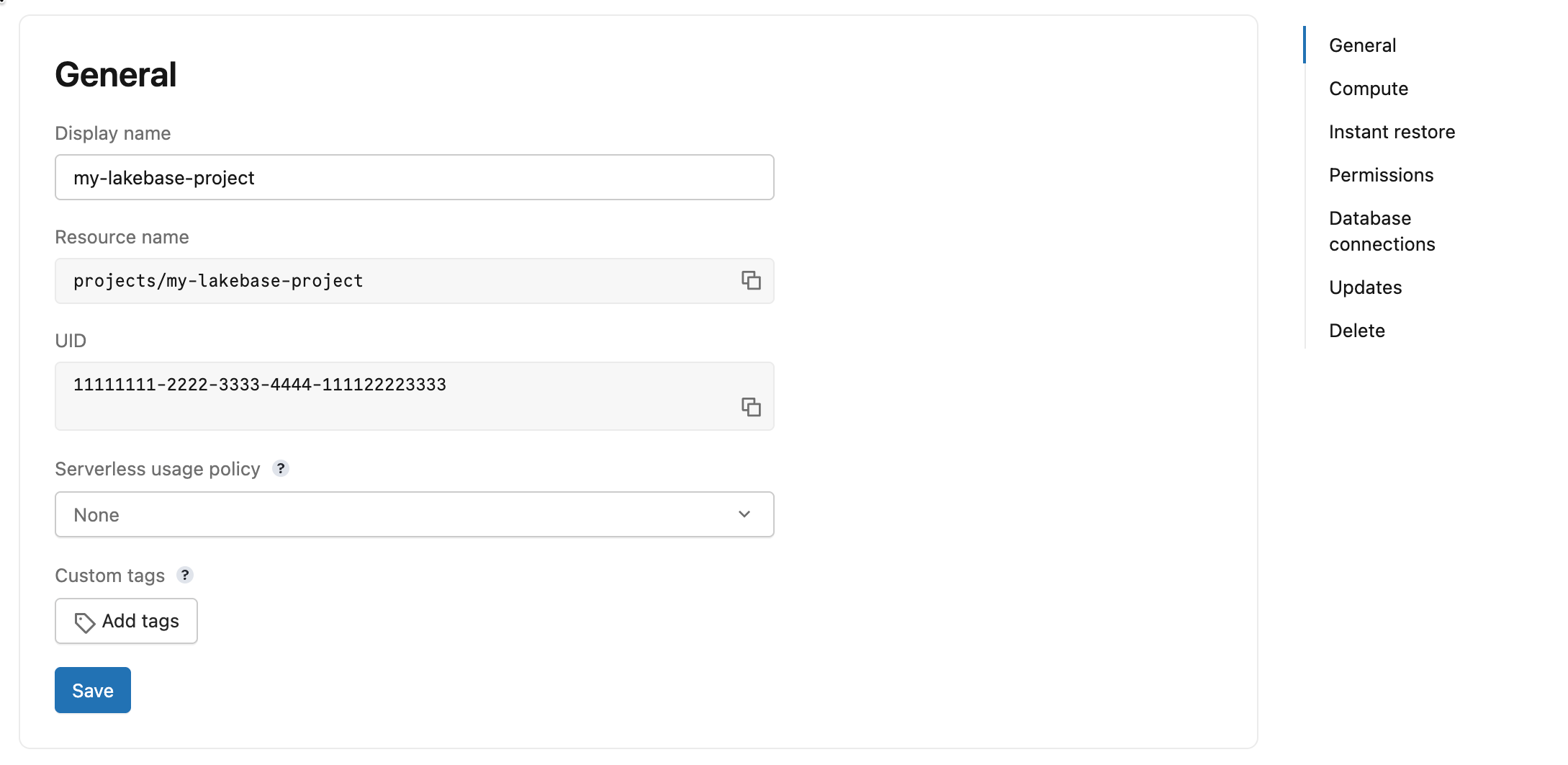
Auf der Seite "Allgemeine Einstellungen" werden die folgenden Felder angezeigt:
- Anzeigename: Der bearbeitbare Anzeigename für Ihr Projekt.
-
Ressourcenname: Schreibgeschützt. Der vollständige Ressourcenpfad für Ihr Projekt (Format:
projects/{project_id}). Verwenden Sie diesen Wert in API- und SDK-Aufrufen, um das Projekt zu identifizieren. - UID: Schreibgeschützt. Der vom System generierte eindeutige Bezeichner für Ihr Projekt.
- Serverlose Nutzungsrichtlinie: Ordnen Sie Ihrem Projekt eine serverlose Nutzungsrichtlinie zu, um serverlose Berechnungskosten einer bestimmten Richtlinie zuzuordnen. Siehe Serverlose Nutzungsrichtlinien.
-
Benutzerdefinierte Tags: Fügen Sie Ihrem Projekt Schlüsselwerttags hinzu. Tags werden in den abrechnungsfähigen Nutzungsdatensätzen (
system.billing.usage) Ihres Kontos protokolliert und können verwendet werden, um Kosten nach Team, Projekt oder Kostenstelle nachzuverfolgen. Siehe benutzerdefinierte Tags. Wenn Sie benutzerdefinierte Tags mithilfe der API oder CLI aktualisieren, ersetzt die neue Liste alle vorhandenen Tags.
Benutzeroberfläche
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec, ProjectCustomTag, FieldMask
w = WorkspaceClient()
# Update project display name
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.display_name"]),
project=Project(spec=ProjectSpec(display_name="My Updated Project Name"))
).wait()
# Update serverless usage policy
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.budget_policy_id"]),
project=Project(spec=ProjectSpec(budget_policy_id="<policy-id>"))
).wait()
# Update custom tags (replaces all existing tags)
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.custom_tags"]),
project=Project(spec=ProjectSpec(custom_tags=[
ProjectCustomTag(key="team", value="data-eng"),
ProjectCustomTag(key="cost-center", value="1234")
]))
).wait()
Befehlszeilenschnittstelle (CLI)
# Update project display name
databricks postgres update-project projects/my-project spec.display_name \
--json '{
"spec": {
"display_name": "My Updated Project Name"
}
}'
# Update serverless usage policy
databricks postgres update-project projects/my-project spec.budget_policy_id \
--json '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}'
# Update custom tags
databricks postgres update-project projects/my-project spec.custom_tags \
--json '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}'
cURL
# Update project display name
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.display_name" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Updated Project Name"
}
}' | jq
# Update serverless usage policy
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.budget_policy_id" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}' | jq
# Update custom tags
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.custom_tags" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}' | jq
Hierbei handelt es sich um lang andauernde Vorgänge. Die Antwort enthält einen Vorgangsnamen, den Sie zum Überprüfen des Status verwenden können.
Standardwerte für Berechnungen
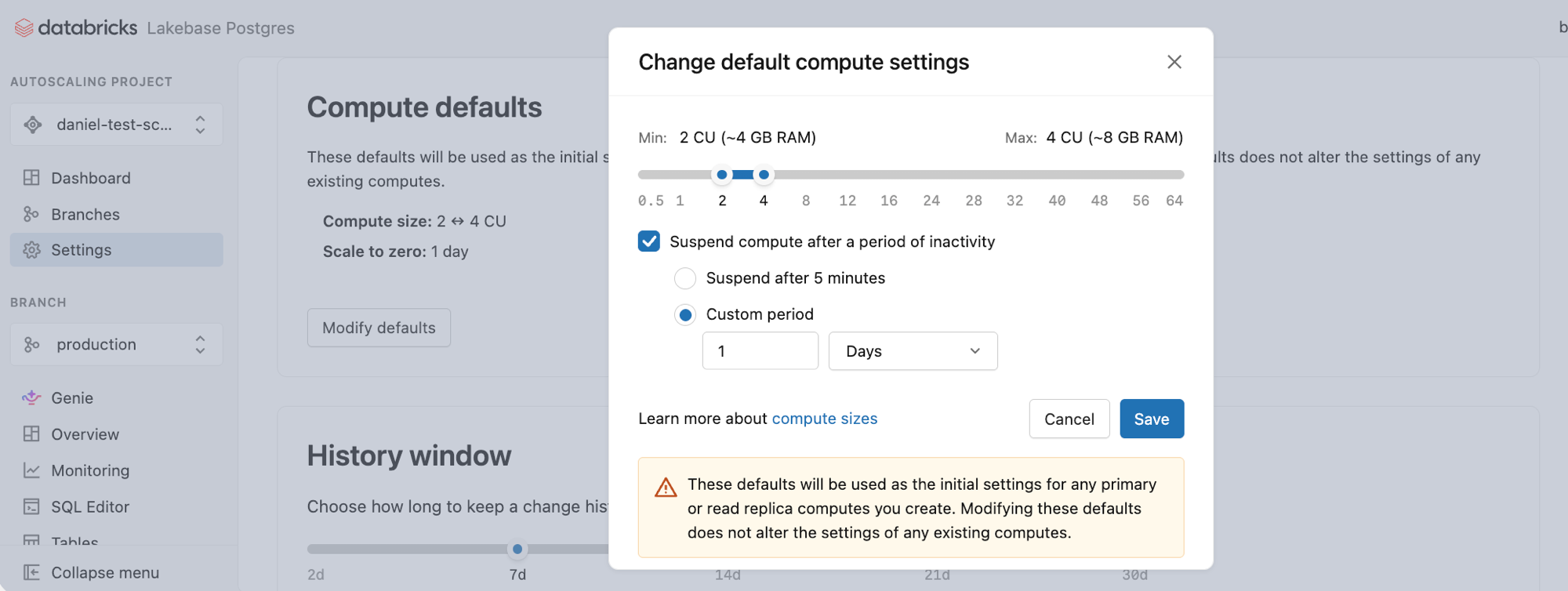
Diese Standardwerte werden als Anfangseinstellungen für jedes primäre oder Lesereplikat verwendet, das Sie erstellen. Durch das Ändern dieser Standardwerte werden die Einstellungen vorhandener Berechnungen nicht geändert.
Standardwerte:
- Berechnungsgröße: 2 ↔ 4 CU (automatischer Skalierungsbereich; ~4-8 GB RAM)
- Auf Null skalieren: Standardmäßig aktiviert – Rechenressourcen nach einer Zeit der Inaktivität anhalten ist aktiviert, wobei Nach 24 Stunden anhalten ausgewählt ist
Klicken Sie auf "Standardwerte ändern", um das Dialogfeld zu öffnen und diese Werte zu ändern.
Hinweis
Informationen zum Ändern von Einstellungen für eine vorhandene Berechnung finden Sie unter "Verwalten von Berechnungen".
Lakebase Postgres unterstützt Berechnungsgrößen von 0,5 CU bis 112 CU. Die automatische Skalierung ist für Berechnungen bis zu 64 CU (0,5, dann ganze Zahlen: 1, 2, 3... 64) verfügbar. Größere Recheninstanzen mit fester Größe sind bis zu 112 CU verfügbar. Jede Computeeinheit (CU) bietet 2 GB RAM.
Hinweis
Lakebase Provisioned vs Autoscaling: Bei Lakebase Provisioned wird jeder Compute-Einheit ungefähr 16 GB RAM zugeordnet. In Lakebase Autoscaling weist jedes CU 2 GB RAM zu. Diese Änderung bietet genauere Skalierungsoptionen und Kostenkontrolle.
Repräsentative Größen:
| Recheneinheiten | RAM |
|---|---|
| 0,5 CU | 1 GB |
| 1 Kapazitätseinheit | 2 GB |
| 4 Recheneinheiten (CU) | 8 GB |
| 8 CU | 16 GB |
| 16 Recheneinheiten (CU) | 32 GB |
| 32 CU | 64 GB |
| 64 CU | 128 GB |
| 112 CU | 224 GB |
- Um die automatische Skalierung zu aktivieren, legen Sie einen Berechnungsgrößenbereich mithilfe des Schiebereglers fest. Durch die automatische Skalierung werden Computeressourcen basierend auf der Auslastungsnachfrage dynamisch angepasst. Weitere Informationen: Automatische Skalierung
- Passen Sie die Einstellung für die Skalierung bis 0 an, um die Inaktive Berechnungszeit zu erhöhen oder zu verringern, bevor eine Berechnung angehalten wird (von 60 Sekunden bis zu 7 Tage, wenn dies aktiviert ist). Sie können auch die Skalierung auf Null für eine immer aktive Berechnung deaktivieren. Weitere Informationen: Skalieren auf Null
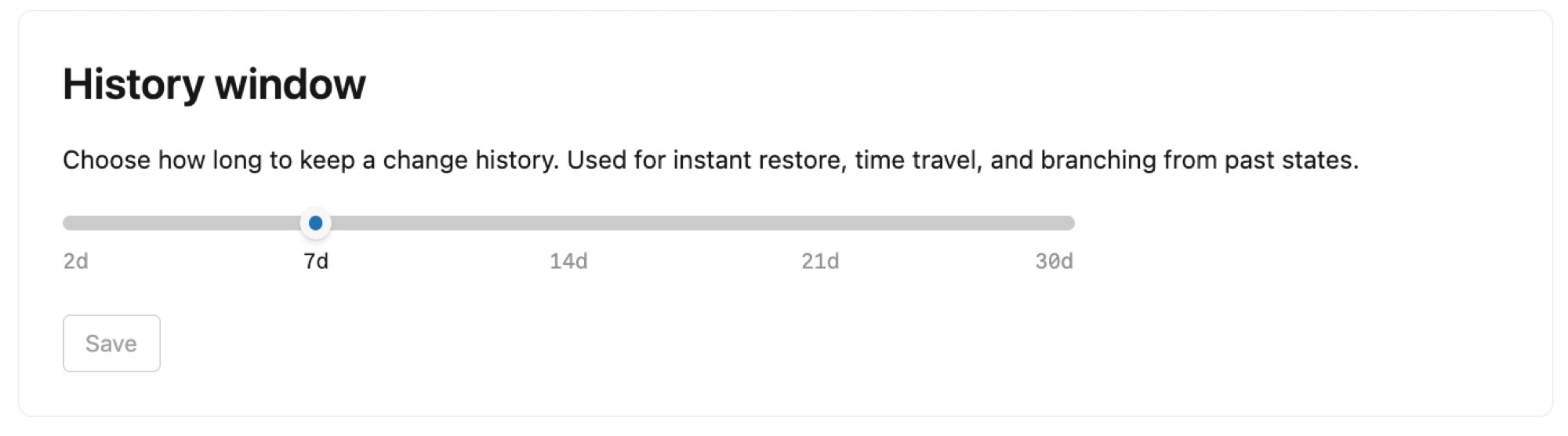
Verlaufsfenster
Konfigurieren Sie die Länge des Verlaufsfensters für Ihr Projekt. Standardmäßig behält Lakebase einen Verlauf von Änderungen für Stammverzweigungen in Ihrem Projekt bei, wodurch die Punkt-in-Zeit-Wiederherstellung zum Wiederherstellen verlorener Daten, das Abfragen von Daten zu einem bestimmten Zeitpunkt zum Untersuchen von Datenproblemen und Verzweigungen von früheren Zuständen für Entwicklungsworkflows aktiviert werden.
Sie können das Verlaufsfenster von 2 Tagen bis zu 30 Tage mit einer Standardeinstellung von 7 Tagen festlegen. Beachten Sie Folgendes:
- Das Erweitern des Verlaufsfensters erhöht Ihren Speicher.
- Die Einstellung für das Chronikfenster beeinflusst alle Branches in Ihrem Projekt.
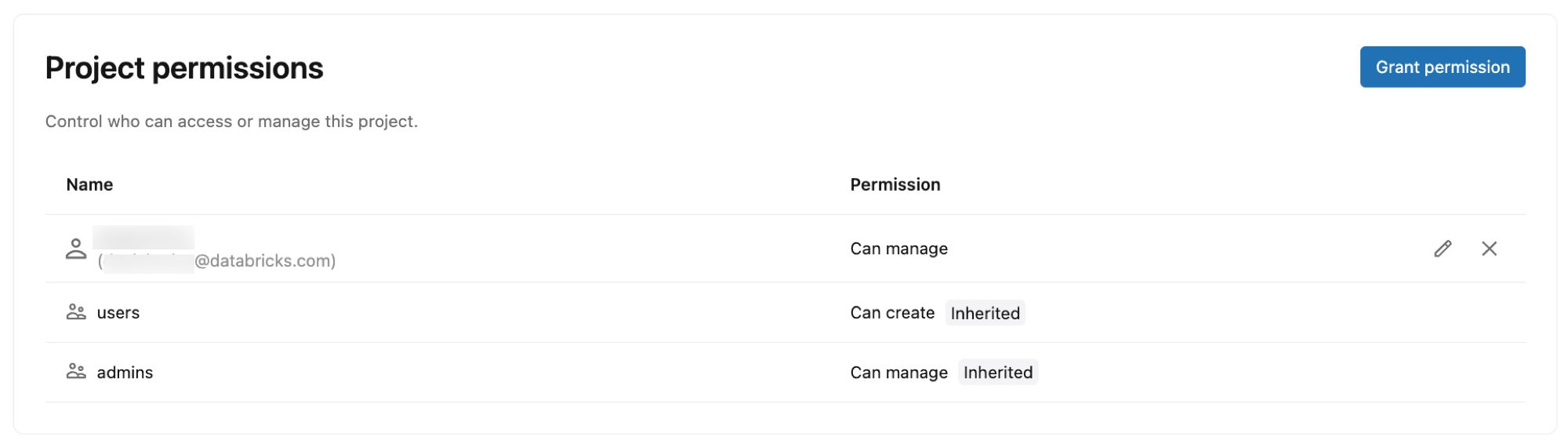
Projektberechtigungen
Steuern Sie, wer auf Ihr Lakebase-Projekt zugreifen und verwalten kann, indem Sie Berechtigungen für Azure Databricks Identitäten, Gruppen und Dienstprinzipale erteilen. Projektberechtigungen bestimmen, welche Aktionen Benutzer innerhalb des Projekts ausführen können, z. B. das Erstellen von Verzweigungen, das Verwalten von Rechenressourcen und das Anzeigen von Verbindungsdetails.
Berechtigungstypen:
- CAN CREATE: Anzeigen und Erstellen von Projektressourcen
- CAN USE: Anzeigen und Verwenden von Projektressourcen (auflisten, ansehen, verbinden und bestimmte Zweigoperationen ausführen) ohne Erstellen oder Löschen von Projekten oder Zweigen
- KANN VERWALTEN: Vollständige Kontrolle über die Projektkonfiguration und -ressourcen
Standardberechtigungen:
Wenn Sie ein Projekt erstellen, werden automatisch die folgenden Berechtigungen zugewiesen:
- Project Owner (der Benutzer, der das project erstellt hat): CAN MANAGE (Vollzugriff)
- Arbeitsbereichsbenutzer: CAN CREATE (kann Projekte anzeigen und erstellen)
- Arbeitsbereichsadministratoren: CAN MANAGE (Vollzugriff)
Informationen zum Gewähren des Zugriffs auf andere Benutzer finden Sie unter "Verwalten von Projektberechtigungen".
Hinweis
Projektberechtigungen und Datenbankzugriff sind getrennt
Projekt-Berechtigungen steuern die Lakebase-Plattform-Aktionen, während der Datenbankzugriff durch Postgres-Rollen und deren zugehörige Berechtigungen gesteuert wird. Siehe Erstellen von Postgres-Rollen und Verwalten von Datenbankberechtigungen.
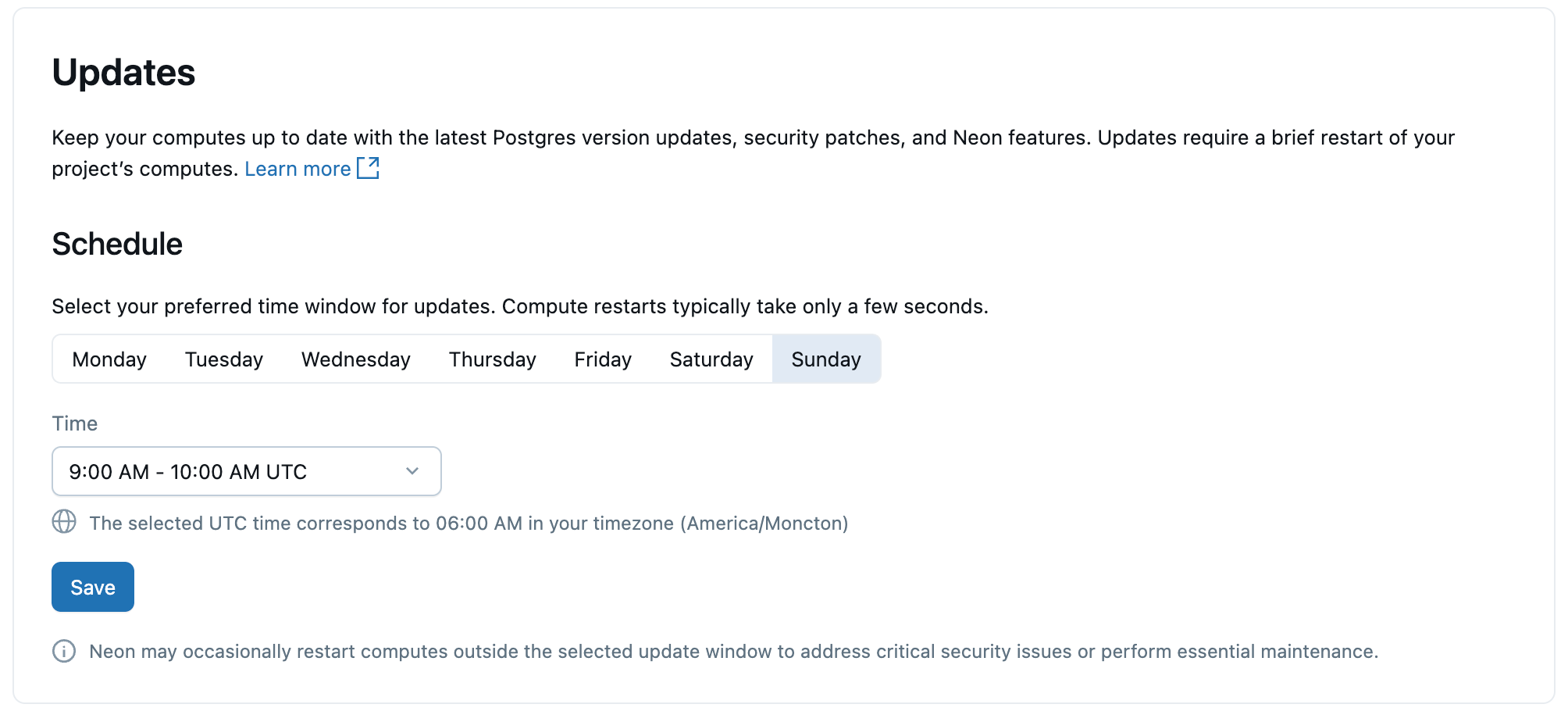
Aktualisierungen
Um Ihre Lakebase-Berechnungen und Postgres-Instanzen auf dem neuesten Stand zu halten, wendet Lakebase automatisch geplante Updates an, die Nebenversionsupgrades, Sicherheitspatches und Plattformfeatures enthalten. Aktualisierungen werden auf die Berechnungen in Ihrem Projekt angewendet und erfordern einen kurzen Computeneustart, der einige Sekunden dauert.
Updates werden automatisch angewendet, sie können jedoch einen bevorzugten Tag und eine bevorzugte Uhrzeit für Updates festlegen. Neustarts erfolgen innerhalb des von Ihnen gewählten Zeitfensters.
Ausführliche Informationen zu Updates finden Sie unter Verwalten von Updates.
Löschen eines Projekts
Wenn Sie ein Projekt löschen, wechselt es standardmäßig in einen vorläufig gelöschten Zustand und wird 7 Tage lang aufbewahrt, bevor es endgültig gelöscht wird. Während dieses Fensters können Sie das Projekt wiederherstellen und alle zugehörigen Daten wiederherstellen. Siehe "Wiederherstellen eines gelöschten Projekts". Wenn Sie den Aufbewahrungszeitraum überspringen und das Projekt sofort entfernen möchten, lesen Sie "Dauerhaftes Löschen eines Projekts".
Hinweis
Während ein Projekt vorläufig gelöscht wird, geben Versuche, eine Verbindung mit ihm herzustellen oder Datenbankanmeldeinformationen abzurufen, generische Fehler zurück (z. B. Endpunkt nicht gefunden oder Verbindung verweigert), anstatt einen Fehler anzugeben, der angibt, dass das Projekt gelöscht wurde. Wenn diese Fehler unerwartet auftreten, überprüfen Sie, ob das Projekt vorläufig gelöscht wurde, indem Sie Projekte auflisten.show_deleted=true Siehe "Vorläufig gelöschte Projekte suchen".
Vor dem Löschen
Databricks empfiehlt, alle zugeordneten Unity-Kataloge und synchronisierte Tabellen zu löschen, bevor das Projekt gelöscht wird. Andernfalls führt der Versuch, Kataloge anzuzeigen oder SQL-Abfragen auszuführen, die auf sie verweisen, zu Fehlern.
Wenn Sie nicht der Besitzer der Tabellen oder Kataloge sind, müssen Sie den Besitz vor dem Löschen an sich selbst erneut zuweisen.
Hinweis
Nur Benutzer mit CAN MANAGE-Berechtigung für das Lakebase-Projekt können sie löschen. Weitere Informationen finden Sie unter Project ACLs und Manage project Berechtigungen.
Löschen eines Projekts
So löschen Sie ein Projekt:
Benutzeroberfläche
- Navigieren Sie in der Lakebase-App zu den Einstellungen Ihres Projekts.
- Klicken Sie im Abschnitt "Projekt löschen " auf "Löschen ", und geben Sie den Projektnamen ein, um den Löschvorgang zu bestätigen.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete a project
operation = w.postgres.delete_project(name="projects/my-project")
print(f"Delete operation started: {operation.name()}")
Dieser Vorgang läuft über einen längeren Zeitraum. Das Projekt und alle zugehörigen Ressourcen (Verzweigungen, Endpunkte, Datenbanken, Rollen, Daten) werden gelöscht.
Java SDK
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete a project
w.postgres().deleteProject("projects/my-project");
System.out.println("Delete operation started");
Dieser Vorgang läuft über einen längeren Zeitraum. Das Projekt und alle zugehörigen Ressourcen (Verzweigungen, Endpunkte, Datenbanken, Rollen, Daten) werden gelöscht.
Befehlszeilenschnittstelle (CLI)
# Delete a project
databricks postgres delete-project projects/my-project
Dieser Befehl liefert sofort eine Rückmeldung. Das Projekt und alle zugehörigen Ressourcen werden gelöscht.
cURL
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Dieser Vorgang läuft über einen längeren Zeitraum. Die Antwort enthält einen Vorgangsnamen, den Sie verwenden können, um den Löschstatus zu überprüfen.
Dauerhaftes Löschen eines Projekts
So löschen Sie ein Lakebase-Projekt sofort, ohne auf den Ablauf des 7-tägigen Aufbewahrungszeitraums für vorläufiges Löschen zu warten:
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.delete_project(name="projects/my-project", purge=True)
operation.wait()
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.DeleteProjectRequest;
WorkspaceClient w = new WorkspaceClient();
w.postgres().deleteProject(
new DeleteProjectRequest()
.setName("projects/my-project")
.setPurge(true)
).waitForCompletion();
Befehlszeilenschnittstelle (CLI)
databricks postgres delete-project projects/my-project --purge
cURL
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project?purge=true" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Wiederherstellen eines gelöschten Projekts
Wenn Sie ein Lakebase-Projekt löschen, wechselt es in einen vorläufig gelöschten Zustand und wird 7 Tage lang aufbewahrt, bevor es endgültig gelöscht wird. Während dieses Fensters können Sie das Projekt wiederherstellen und alle zugehörigen Daten wiederherstellen.
Was wiederhergestellt wird
Durch das Wiederherstellen eines vorläufig gelöschten Projekts wird Folgendes wiederhergestellt:
- Alle Branches und ihre zugehörigen Daten
- Alle Postgres-Datenbanken und -Rollen
- Alle Computeendpunkte und deren Konfigurationen
- Projekteinstellungen, einschließlich Standardwerte für Rechenressourcen, Wiederherstellung von Fenstereinstellungen und Updateeinstellungen
- Projektberechtigungen
Hinweis
Einige Ressourcen erfordern möglicherweise eine Neukonfiguration nach der Wiederherstellung. Wenden Sie sich an den Databricks-Support , wenn nach dem Wiederherstellen eines Projekts Probleme auftreten.
Vorläufig gelöschte Projekte finden
Verwenden Sie den show_deleted Parameter, um alle Projekte einschließlich vorläufig gelöschter Projekte auflisten zu können. Dies ist nützlich, um den Ressourcennamen eines Projekts zu finden, das Sie wiederherstellen möchten.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
for project in w.postgres.list_projects(show_deleted=True):
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
if project.delete_time:
print(f" Deleted: {project.delete_time}")
print(f" Purge time: {project.purge_time}")
Befehlszeilenschnittstelle (CLI)
databricks postgres list-projects --show-deleted
cURL
curl -X GET "$WORKSPACE/api/2.0/postgres/projects?show_deleted=true" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Wiederherstellen eines Projekts
So stellen Sie ein vorläufig gelöschtes Lakebase-Projekt wieder her:
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.undelete_project(name="projects/my-project")
operation.wait()
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.UndeleteProjectRequest;
WorkspaceClient w = new WorkspaceClient();
w.postgres().undeleteProject(
new UndeleteProjectRequest().setName("projects/my-project")
).waitForCompletion();
Befehlszeilenschnittstelle (CLI)
databricks postgres undelete-project projects/my-project
cURL
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/undelete" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq