Ereignisse
Erstellen von KI-Apps und Agents
17. März, 21 Uhr - 21. März, 10 Uhr
Nehmen Sie an der Meetup-Serie teil, um skalierbare KI-Lösungen basierend auf realen Anwendungsfällen mit Mitentwicklern und Experten zu erstellen.
Jetzt registrierenDieser Browser wird nicht mehr unterstützt.
Führen Sie ein Upgrade auf Microsoft Edge aus, um die neuesten Funktionen, Sicherheitsupdates und technischen Support zu nutzen.
Wichtig
Dieses Feature ist jetzt veraltet. Am 31. März 2025 wird die Preview-API für Azure KI-Bildanalyse 4.0 für die benutzerdefinierte Bildklassifizierung, benutzerdefinierte Objekterkennung und Produkterkennung eingestellt. Nach diesem Datum schlagen API-Aufrufe für diese Dienste fehl.
Um einen reibungslosen Betrieb Ihrer Modelle zu gewährleisten, wechseln Sie zu Azure KI Custom Vision (jetzt allgemein verfügbar). Custom Vision bietet ähnliche Funktionen wie die eingestellten Features.
Mit der Modellanpassung können Sie ein spezialisiertes Bildanalysemodell für Ihren eigenen Anwendungsfall trainieren. Benutzerdefinierte Modelle können entweder Bildklassifizieren (Tags gelten für das gesamte Bild) oder Objekterkennung (Tags gelten für bestimmte Bereiche des Bilds) durchführen. Nachdem Ihr benutzerdefiniertes Modell erstellt und trainiert wurde, gehört es zu Ihrer Vision-Ressource, und Sie können es mithilfe der Bildanalyse-API aufrufen.
Implementieren Sie Modellanpassungen schnell und einfach, indem Sie einen Schnellstart befolgen:
Wichtig
Sie können ein benutzerdefiniertes Modell entweder mit dem Custom Vision-Dienst oder dem Bildanalyse 4.0-Dienst mit Modellanpassung trainieren. In der folgenden Tabelle werden die zwei Dienste miteinander verglichen.
| Bereiche | Custom Vision Service | Bildanalyse 4.0-Dienst | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Aufgaben | Bildklassifizierung Objekterkennung |
Bildklassifizierung Objekterkennung |
||||||||||||||||||||||||||||||||||||
| Basismodell | CNN | Transformatormodell | ||||||||||||||||||||||||||||||||||||
| Bezeichnungen | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Web Portal (Webportal) | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Libraries | REST, SDK | REST, Python-Beispiel | ||||||||||||||||||||||||||||||||||||
| Mindestens erforderliche Trainingsdaten | 15 Bilder pro Kategorie | 2-5 Bilder pro Kategorie | ||||||||||||||||||||||||||||||||||||
| Speicherung von Trainingsdaten | Hochgeladen in den Dienst | Blob Storage-Kundenkonto | ||||||||||||||||||||||||||||||||||||
| Modellhosting | Cloud und Edge | Nur Cloudhosting, Edgecontainerhosting bald verfügbar | ||||||||||||||||||||||||||||||||||||
| KI-Qualität |
|
|
||||||||||||||||||||||||||||||||||||
| Preise | Custom Vision-Preise | Bildanalyse: Preise |
Die Hauptkomponenten eines Modellanpassungssystems sind die Trainingsbilder, die COCO-Datei, das Datasetobjekt und das Modellobjekt.
Ihr Satz an Trainingsbildern sollten mehrere Beispiele für jede der Bezeichnungen enthalten, die Sie erkennen möchten. Sie sollten auch einige zusätzliche Bilder sammeln, um Ihr Modell zu testen, nachdem es trainiert wurde. Die Images müssen in einem Azure Storage-Container gespeichert werden, um für das Modell zugänglich zu sein.
Verwenden Sie zum effektiven Trainieren Ihres Modells Bilder mit optischer Vielfalt. Wählen Sie Bilder aus, die sich nach folgenden Aspekten unterscheiden:
Stellen Sie außerdem sicher, dass alle Ihre Trainingsbilder die folgenden Kriterien erfüllen:
Die COCO-Datei verweist auf alle Trainingsbilder und ordnet sie ihren Bezeichnungsinformationen zu. Bei der Objekterkennung wurden die Begrenzungsrahmenkoordinaten jedes Tags für jedes Bild angegeben. Diese Datei muss im COCO-Format vorliegen, was ein spezieller Typ einer JSON-Datei ist. Die COCO-Datei sollte im gleichen Azure Storage-Container wie die Trainingsbilder gespeichert werden.
Tipp
COCO-Dateien sind JSON-Dateien mit bestimmten erforderlichen Feldern: "images", "annotations" und "categories". Eine COCO-Datei sieht beispielhaft wie folgt aus:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Wenn Sie Ihre eigene COCO-Datei von Grund auf neu generieren, stellen Sie sicher, dass alle erforderlichen Felder mit den richtigen Details gefüllt sind. In den folgenden Tabellen werden die einzelnen Felder in einer COCO-Datei beschrieben:
"images"
| Schlüssel | type | Description | Erforderlich? |
|---|---|---|---|
id |
integer | Eindeutige Bild-ID, beginnend bei 1 | Ja |
width |
integer | Breite des Bilds in Pixeln | Ja |
height |
integer | Höhe des Bilds in Pixeln | Ja |
file_name |
Zeichenfolge | Eindeutiger Name für das Bild | Ja |
absolute_url oder coco_url |
Zeichenfolge | Pfad zum Bild als absoluter URI zu einem Blob in einem Blobcontainer. Die Vision-Ressource muss über die Berechtigung zum Lesen der Anmerkungsdateien und aller Bilddateien verfügen, auf die verwiesen wird. | Ja |
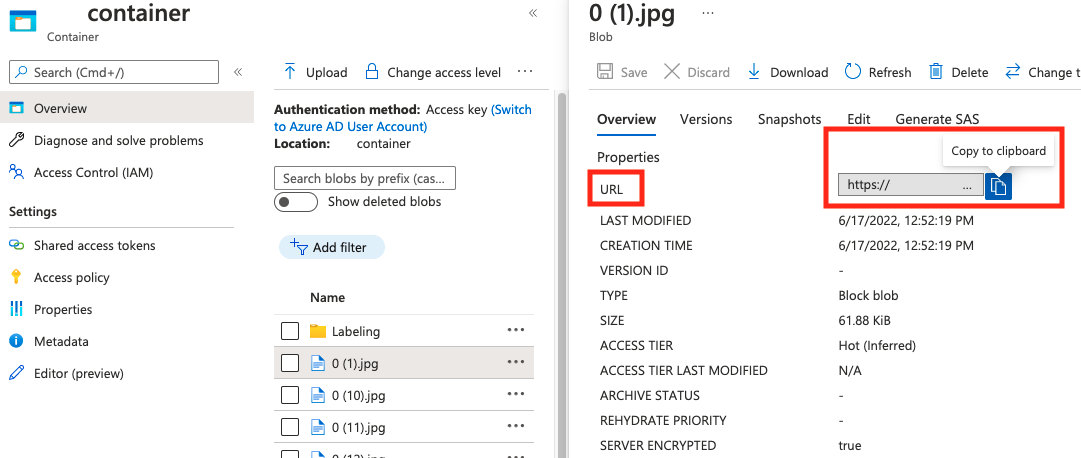
Den Wert für absolute_url finden Sie in den Eigenschaften Ihres Blobcontainers:
"annotations"
| Schlüssel | type | Description | Erforderlich? |
|---|---|---|---|
id |
integer | ID der Anmerkung | Ja |
category_id |
integer | ID der im Abschnitt categories definierten Kategorie |
Ja |
image_id |
integer | ID des Bilds | Ja |
area |
integer | Wert von „Breite“ x „Höhe“ (dritter und vierter Wert von bbox) |
No |
bbox |
list[float] | Relative Koordinaten des Begrenzungsrahmens (0 bis 1), in der Reihenfolge „Links“, „Oben“, „Breite“, „Höhe“ | Yes |
"categories"
| Schlüssel | type | Description | Erforderlich? |
|---|---|---|---|
id |
integer | Eindeutige ID jeder Kategorie (Beschriftungsklassifikation). Diese sollten im Abschnitt annotations vorhanden sein. |
Ja |
name |
Zeichenfolge | Name der Kategorie (Beschriftungsklassifikation) | Yes |
Sie können unseren Python-Beispielcode verwenden, um das Format einer COCO-Datei zu überprüfen.
Das Dataset-Objekt ist eine Datenstruktur, die vom Bildanalysedienst gespeichert wird und auf die Zuordnungsdatei verweist. Sie müssen ein Dataset-Objekt erstellen, bevor Sie ein Modell erstellen und trainieren können.
Das Modell-Objekt ist eine vom Bildanalysedienst gespeicherte Datenstruktur, die ein benutzerdefiniertes Modell darstellt. Es muss einem Dataset zugeordnet sein, um eine Ersttraining durchführen zu können. Nachdem es trainiert wurde, können Sie Ihr Modell abfragen, indem Sie seinen Namen in den model-name-Abfrageparameter des Bildanalyse-API-Aufrufs eingeben.
Die folgenden Tabellen beschreiben die Grenzwerte für die Skalierung Ihrer benutzerdefinierten Modellprojekte.
| Category | Generische Bildklassifizierung | Generische Objekterkennung |
|---|---|---|
| Max. Anz. Trainingsstunden | 288 (12 Tage) | 288 (12 Tage) |
| Max. Anz. Trainingsbilder | 1\.000.000 | 200.000 |
| Max. Anz. Auswertungsbilder | 100.000 | 100.000 |
| Min. Anz. Trainingsbildern pro Kategorie | 2 | 2 |
| Max. Anz. Tags pro Bild | 1 | N/V |
| Max. Anz. Regionen pro Bild | N/V | 1.000 |
| Max. Anz. Kategorien | 2\.500 | 1\.000 |
| Min. Anz. Kategorien | 2 | 1 |
| Max. Bildgröße (Training) | 20 MB | 20 MB |
| Max. Bildgröße (Vorhersage) | Synchronisierung: 6 MB, Batch: 20 MB | Synchronisierung: 6 MB, Batch: 20 MB |
| Max. Bildbreite/-höhe (Training) | 10.240 | 10.240 |
| Min. Bildbreite/-höhe (Vorhersage) | 50 | 50 |
| Verfügbare Regionen | „USA, Westen 2“, „USA, Osten“, „Europa, Westen“ | „USA, Westen 2“, „USA, Osten“, „Europa, Westen“ |
| Akzeptierte Bildtypen | JPG, PNG, BMP, GIF, JPEG | JPG, PNG, BMP, GIF, JPEG |
Derzeit behandelt Microsoft ein Problem, welches dazu führt, dass der COCO-Dateiimport bei großen Datasets fehlschlägt, wenn er in Vision Studio initiiert wird. Um mit einem großen Dataset zu trainieren, empfiehlt es sich, stattdessen die REST-API zu verwenden.
Das angegebene Trainingsbudget ist die kalibrierte Computezeit, nicht die Wanduhrzeit. Einige häufige Gründe für den Unterschied sind hier aufgeführt:
Länger als das angegebene Budget:
Kürzer als das angegebene Budget: Die folgenden Faktoren beschleunigen das Training auf Kosten eines größeren Budgetverbrauchs in einer bestimmten Wanduhrzeit.
Im Folgenden finden Sie einige häufige Gründe für Trainingsfehler:
diverged: Das Training kann keine sinnvollen Dinge aus Ihren Daten lernen. Einige häufige Ursachen sind: notEnoughBudget: Ihr angegebenes Budget reicht nicht für die Größe Ihres Datasets und den Modelltyp aus, den Sie trainieren. Geben Sie ein größeres Budget an.datasetCorrupt: In der Regel bedeutet dies, dass auf Ihre bereitgestellten Bilder nicht zugegriffen werden kann, oder dass die Anmerkungsdatei das falsche Format aufweist.datasetNotFound: Das Dataset kann nicht gefunden werdenunknown: Dies könnte ein Back-End-Problem sein. Wenden Sie sich an den Support zur Untersuchung.Die folgenden Metriken werden verwendet:
Die API-Antworten sollten informativ genug sein. Sie lauten wie folgt:
DatasetAlreadyExists: Ein Dataset mit diesem Namen ist vorhandenDatasetInvalidAnnotationUri: „Unter den Anmerkungs-URIs zum Zeitpunkt der Datasetregistrierung wurde ein ungültiger URI bereitgestellt.Obwohl Florenz-Modelle über eine hervorragende „Few-Shot“-Fähigkeit verfügen (sie erzielen eine hohe Modellleistung bei eingeschränkter Datenverfügbarkeit), machen mehr Daten ihr trainiertes Modell im Allgemeinen besser und robuster. Einige Szenarien erfordern wenig Daten (z. B. die Klassifizierung eines Apfels gegen eine Banane), andere erfordern jedoch mehr (z. B. das Erkennen von 200 Arten von Insekten in einem Regenwald). Dies erschwert es, eine einzelne Empfehlung zu geben.
Wenn Ihr Budget für die Datenbeschriftung eingeschränkt ist, ist unser empfohlener Workflow, die folgenden Schritte zu wiederholen:
Sammeln Sie N Bildern pro Klasse, wobei N Bilder für Sie einfach zu sammeln sind (z. B N=3)
Trainieren Sie ein Modell, und testen Sie es gegen Ihrem Auswertungssatz.
Wenn die Modellleistung wie folgt aussieht:
Sie sollten die Obergrenze des Budgets angeben, das Sie bereit sind zu verbrauchen. Die Bildanalyse verwendet ein automatisiertes ML-System im Back-End, um verschiedene Modelle und Trainingsrezepte auszuprobieren, um das beste Modell für Ihren Anwendungsfall zu finden. Je mehr Budget bereitgestellt wird, desto höher ist die Chance, ein besseres Modell zu finden.
Das automatisiertes ML-System wird auch automatisch beendet, wenn es zum Schluss kommt, dass keine weiteren Versuche mehr nötig sind, auch wenn noch ein verbleibendes Budget vorhanden ist. Es erschöpft also nicht immer Ihr angegebenes Budget. Sie haben die Garantie, dass Ihnen nicht mehr als das von Ihnen angegebene Budget in Rechnung gestellt wird.
Nein, der Modellanpassungsdienst für die Bildanalyse verwendet ein automatisiertes ML-Trainingssystem mit wenig Code, das die Hyperparametersuche und die Auswahl des Basismodells im Back-End verarbeitet.
Die Vorhersage-API wird nur über den Clouddienst unterstützt.
Unten sind die möglichen Gründe aufgeführt:
internalServerError: Ein unbekannter Fehler ist aufgetreten. Versuchen Sie es später noch mal.modelNotFound: Das angegebene Modell wurde nicht gefunden.datasetNotFound: Das angegebene Dataset wurde nicht gefunden.datasetAnnotationsInvalid: Beim Herunterladen oder Parsen der dem Testdataset zugeordneten Grundwahrheitsanmerkungen ist ein Fehler aufgetreten.datasetEmpty: Das Testdataset enthielt keine Anmerkungen zur „Grundwahrheit“.Aufgrund einer potenziell hohen Wartezeit wird nicht empfohlen, benutzerdefinierte Modelle für unternehmenskritische Umgebungen zu verwenden. Wenn Kunden benutzerdefinierte Modelle in Vision Studio trainieren, gehören diese Modelle zu der Azure KI Vision-Ressource, mit der sie trainiert wurden. Der Kunde kann diese Modelle mithilfe der API für die Bildanalyse aufrufen. Wenn sie diese Aufrufe tätigen, wird das benutzerdefinierte Modell in den Arbeitsspeicher geladen, und die Vorhersageinfrastruktur wird initialisiert. Während dies geschieht, kann es sein, dass die Kunden länger als erwartet auf die Vorhersageergebnisse warten müssen.
Wie bei allen Azure KI Services müssen Entwickler*innen, die die Anpassung für das Bildanalysemodell nutzen, die Microsoft-Richtlinien zu Kundendaten beachten. Weitere Informationen finden Sie im Microsoft Trust Center auf der Seite zu Azure KI Services.
Ereignisse
Erstellen von KI-Apps und Agents
17. März, 21 Uhr - 21. März, 10 Uhr
Nehmen Sie an der Meetup-Serie teil, um skalierbare KI-Lösungen basierend auf realen Anwendungsfällen mit Mitentwicklern und Experten zu erstellen.
Jetzt registrierenSchulung
Modul
Image classification with custom Azure AI Vision models - Training
Classify images with custom Azure AI Vision models
Zertifizierung
Microsoft Certified: Azure Data Scientist Associate - Certifications
Manage data ingestion and preparation, model training and deployment, and machine learning solution monitoring with Python, Azure Machine Learning and MLflow.