Allgemeines Dokumentmodell für Dokument Intelligenz
Wichtig
Ab Dokumentintelligenz 2024-02-29-preview, 2023-10-31-preview und zukünftig ist das allgemeine Dokumentmodell (vorkonfiguriertes Dokument) veraltet. Verwenden Sie die folgenden Modelle, um Schlüssel-Wert-Paare, Auswahlmarkierungen, Text, Tabellen und Strukturen aus Dokumenten zu extrahieren:
| Feature | version | Modell-ID |
|---|---|---|
Layout-Modell, bei dem der Abfragezeichenfolgenparameter features=keyValuePairs aktiviert ist. |
• v4:2024-02-29-preview • v3.1:2023-07-31 (GA) |
prebuilt-layout |
| Allgemeines Dokumentenmodell | • v3.1:2023-07-31 (allgemein verfügbar) • v3.0:2022-08-31 (allgemein verfügbar) • v2.1 (allgemein verfügbar) |
prebuilt-document |
Dieser Inhalt gilt für: ![]() Version 3.1 (GA) | Aktuelle Version:
Version 3.1 (GA) | Aktuelle Version: ![]() Version 4.0 (Vorschau) | Vorherige Version:
Version 4.0 (Vorschau) | Vorherige Version: ![]() Version 3.0
Version 3.0
Dieser Inhalt gilt für: ![]() Version 3.0 (GA) | Aktuelle Versionen:
Version 3.0 (GA) | Aktuelle Versionen: ![]() Version 4.0 (Vorschau)
Version 4.0 (Vorschau) ![]() Version 3.1
Version 3.1
Das allgemeine Dokumentmodell kombiniert leistungsstarke OCR-Funktionen (optische Zeichenerkennung) mit Deep Learning-Modellen zur Extraktion von Schlüssel-Wert-Paaren, Tabellen und Auswahlmarkierungen aus Dokumenten. Das allgemeine Dokument ist mit den APIs v3.1 und v3.0 verfügbar. Weitere Informationen finden Sie im Migrationshandbuch.
Allgemeine Dokumentfeatures
Das allgemeine Dokumentmodell ist ein vortrainiertes Modell, das weder Beschriftungen noch Training erfordert.
Eine einzelne API extrahiert Schlüssel-Wert-Paare, Auswahlmarkierungen, Text, Tabellen und Strukturen aus Dokumenten.
Das allgemeine Dokumentmodell unterstützt strukturierte, teilweise strukturierte und unstrukturierte Dokumente.
Auswahlmarkierungen sind als Felder mit dem Wert
:selected:oder:unselected:gekennzeichnet.
Beispieldokument verarbeitet in Dokument Intelligenz Studio
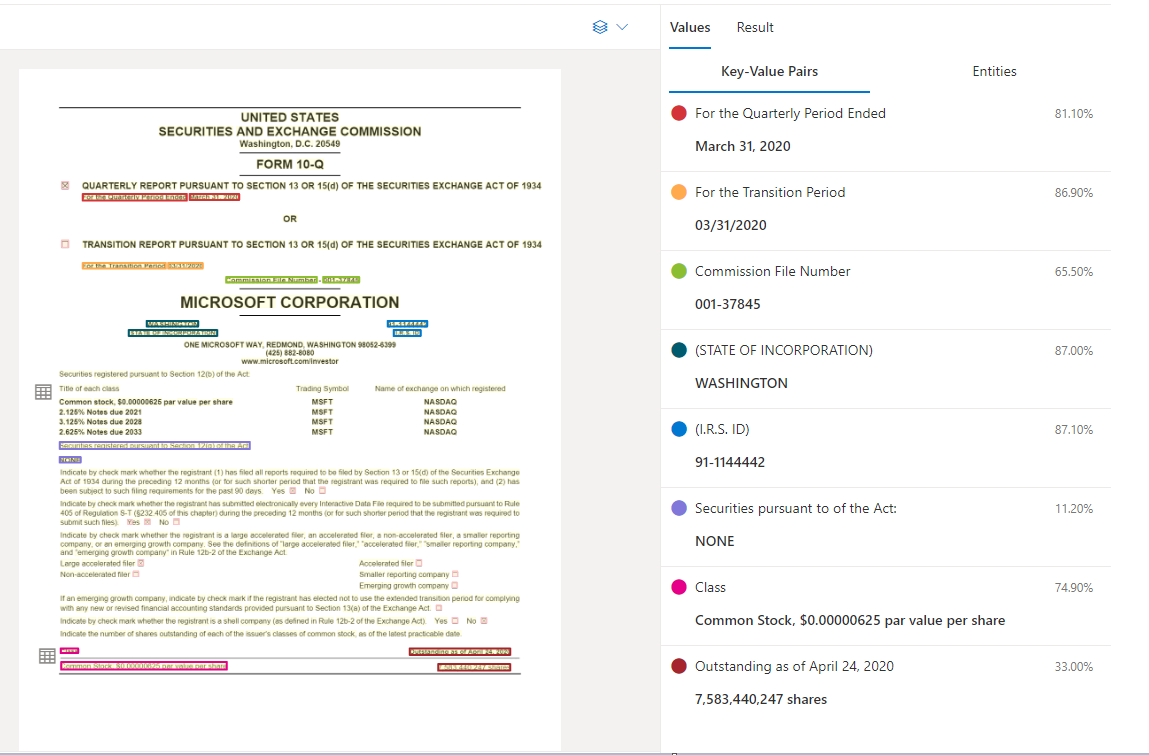
Schlüssel-Wert-Paar-Extraktion
Die API für allgemeine Dokumente unterstützt die meisten Formulartypen und analysiert Ihre Dokumente und extrahiert Schlüssel und zugehörige Werte. Sie eignet sich ideal für die Extraktion gängiger Schlüssel-Werte-Paare aus Dokumenten. Sie können das allgemeine Dokumentenmodell als Alternative zum Training eines benutzerdefinierten Modells ohne Labels verwenden.
Entwicklungsoptionen
Document Intelligence v3.1 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Allgemeines Dokumentenmodell | • Document Intelligence Studio • REST-API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-document |
Document Intelligence v3.0 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Allgemeines Dokumentenmodell | • Document Intelligence Studio • REST-API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-document |
Eingabeanforderungen
Unterstützte Dateiformate:
Modell PDF Abbildung: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLesen Sie ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für den kostenpflichtigen Tarif (S0) und
4MB für den kostenlosen Tarif (F0).Die Bildgröße muss zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkttext bei 150 Punkten pro Zoll (Dots Per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training benutzerdefinierter Extraktionsmodelle beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und
1GB für das neuronale Modell.Für das Training benutzerdefinierter Klassifizierungsmodelle beträgt die Gesamtgröße der Trainingsdaten
1GB bei maximal 10.000 Seiten. Für 2024-07-31-preview und höher beträgt die Gesamtgröße der Trainingsdaten2GB bei maximal 10.000 Seiten.
Datenextraktion für das allgemeine Dokumentmodell
Versuchen Sie, mithilfe von Dokument Intelligenz Studio Daten aus Formularen und Dokumenten zu extrahieren.
Sie benötigen die folgenden Ressourcen:
Ein Azure-Abonnement (Sie können ein kostenloses Abonnement erstellen).
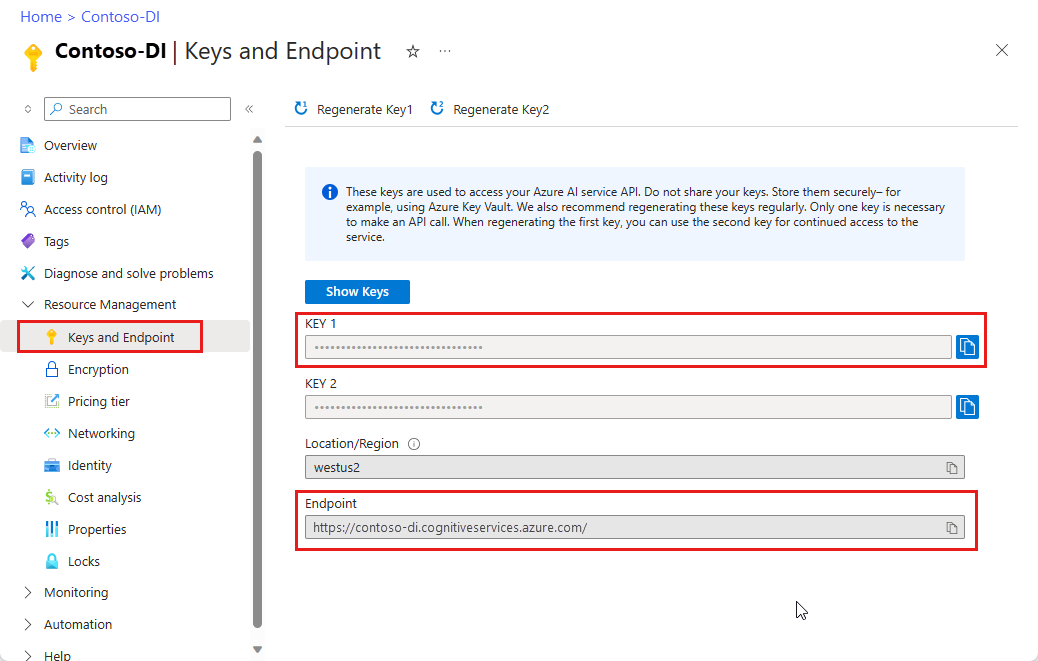
Eine Dokument Intelligenz-Instanz im Azure-Portal. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst auszuprobieren. Wählen Sie nach der Bereitstellung Ihrer Ressource Zu Ressource wechseln aus, um Ihren Schlüssel und Endpunkt abzurufen.
Hinweis
Dokument Intelligenz Studio und das allgemeine Dokumentmodell sind mit der API v3.0 verfügbar.
Wählen Sie auf der Startseite vom Document Intelligence Studio Allgemeine Dokumente aus.
Sie können das Musterdokument analysieren oder Ihre eigenen Dateien hochladen.
Wählen Sie die Schaltfläche Analyse ausführen aus, und konfigurieren Sie bei Bedarf die Analyseoptionen:

Schlüssel-Wert-Paare
Schlüssel-Wert-Paare sind bestimmte Bereiche innerhalb des Dokuments, die eine Beschriftung oder einen Schlüssel und die zugehörige Antwort oder den zugehörigen Wert identifizieren. In einem strukturierten Formular könnten diese Paare die Beschriftung und der Wert sein, die der Benutzer für dieses Feld eingegeben hat. In einem unstrukturierten Dokument kann es sich um das Datum handeln, an dem ein Vertrag basierend auf dem Text in einem Absatz erfüllt wurde. Das KI-Modell wird trainiert, um identifizierbare Schlüssel und Werte basierend auf einer Vielzahl von Dokumenttypen, Formaten und Strukturen zu extrahieren.
Schlüssel können auch isoliert existieren, wenn das Modell feststellt, dass ein Schlüssel ohne zugehörigen Wert vorhanden ist, oder wenn optionale Felder verarbeitet werden. Beispielsweise kann ein Feld für den zweiten Vornamen in einigen Fällen in einem Formular leer gelassen werden. Schlüssel-Wert-Paare sind Textabschnitte, die im Dokument enthalten sind. Bei Dokumenten, in denen derselbe Wert auf unterschiedliche Weise beschrieben wird, z. B. Kunde/Benutzer, ist der zugehörige Schlüssel entweder Kunde oder Benutzer (je nach Kontext).
Extrahieren von Daten
| Modell | Textextraktion | Schlüssel-Werte-Paare | Auswahlmarkierungen | Tabellen | Allgemeine Namen |
|---|---|---|---|---|---|
| Allgemeines Dokument | ✓ | ✓ | ✓ | ✓ | ✓* |
✓* – Nur in der 2023-07-31 API-Version (v3.1 GA) und mit späteren API-Versionen verfügbar.
Unterstützte Sprachen und Gebietsschemas
Eine vollständige Liste der unterstützten Sprachen finden Sie unter Sprachunterstützung – Dokumentanalysemodelle.
Überlegungen
Schlüssel sind Ausschnitte von Text, der aus dem Dokument extrahiert wurde. Für teilweise strukturierte Dokumente müssen Schlüssel möglicherweise einem vorhandenen Schlüsselwörterbuch zugeordnet werden.
Erwarten Sie, dass Schlüssel-Wert-Paare mit einem Schlüssel, aber ohne Wert angezeigt werden. Wenn ein Benutzer z. B. keine E-Mail-Adresse in das Formular eingeben möchte.
Nächste Schritte
Folgen Sie dem Migrationsleitfaden für Dokument Intelligenz 3.1, um zu erfahren, wie Sie die Version 3.1 in Ihren Anwendungen und Workflows verwenden können.
Erkunden Sie unsere REST API.