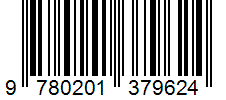Public Preview-Releases von Dokument Intelligenz bieten frühzeitigen Zugriff auf Features, die sich in der aktiven Entwicklung befinden. Features, Ansätze und Prozesse können sich aufgrund von Benutzerfeedback vor der allgemeinen Verfügbarkeit (General Availability, GA) ändern.
Die Public Preview von Dokument Intelligenz-Clientbibliotheken verwendet standardmäßig Version 2024-07-31-preview der REST-API.
Die Public Preview 2024-07-31-preview ist derzeit lediglich in den folgenden Azure-Regionen verfügbar. Beachten Sie, dass das benutzerdefinierte generative Modell (Dokumentfeldextraktion) in KI Studio nur in der Region „USA, Norden-Mitte“ verfügbar ist:
USA, Osten
USA, Westen 2
Europa, Westen
USA Nord Mitte
Dieser Inhalt gilt für:Version 4.0 (Vorschau) | Vorherige Versionen:Version 3.1 (GA)
Document Intelligence unterstützt auch anspruchsvollere und modulare Analysefunktionen. Verwenden Sie die Add-on-Funktionen, um die Ergebnisse um weitere Features aus Ihren Dokumenten zu erweitern. Einige Add-On-Features verursachen zusätzliche Kosten. Diese optionalen Funktionen können je nach Szenario der Dokumentextrahierung aktiviert und deaktiviert werden. Um ein Feature zu aktivieren, fügen Sie der Abfragezeichenfolgeneigenschaft features den zugehörigen Featurenamen hinzu. Sie können mehr als ein Add-On-Feature auf einer Anforderung aktivieren, indem Sie eine durch Trennzeichen getrennte Liste der Features bereitstellen. Die folgenden Add-On-Funktionen sind für 2023-07-31 (GA) und höhere Versionen verfügbar:
Nicht alle Add-On-Funktionen werden von allen Modellen unterstützt. Weitere Informationen finden Sie unterExtrahieren von Modelldaten.
Add-On-Funktionen werden derzeit nicht für Microsoft Office-Dateitypen unterstützt.
Document Intelligence unterstützt optionale Features, die je nach Szenario der Dokumentextrahierung aktiviert und deaktiviert werden können. Die folgenden Add-On-Funktionen sind für 2023-10-31-preview und höhere Versionen verfügbar:
Die Implementierung von Abfragefeldern in der 2023-10-30-Vorschau-API unterscheidet sich von der letzten Vorschauversion. Die neue Implementierung ist kostengünstiger und funktioniert gut mit strukturierten Dokumenten.
✱ Add-On: Die Preise für Abfragefelder unterscheiden sich von denen der anderen Add-on-Funktionen. Weitere Informationen finden Sie unter Preise.
Unterstützte Dateiformate
PDF
Bilder: JPEG/JPG, PNG, BMP, TIFF, HEIF
✱ Microsoft Office-Dateien werden derzeit nicht unterstützt.
Hochauflösende Extraktion
Die Aufgabe, kleine Texte in großformatigen Dokumenten wie technischen Zeichnungen zu erkennen, ist eine Herausforderung. Häufig ist der Text mit anderen grafischen Elementen gemischt und weist unterschiedliche Schriftarten, Größen und Ausrichtungen auf. Darüber hinaus kann der Text in separate Teile unterteilt oder mit anderen Symbolen verbunden sein. Dokument Intelligenz unterstützt jetzt das Extrahieren von Inhalten aus diesen Dokumenttypen mit der ocr.highResolution-Funktion. Sie erhalten eine verbesserte Qualität der Inhaltsextraktion aus A1/A2/A3-Dokumenten, wenn Sie diese Add-On-Funktion aktivieren.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.OCR_HIGH_RESOLUTION], # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_with_highres]
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
# Analyze a document at a URL:
url = "(https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.OCR_HIGH_RESOLUTION] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_with_highres]
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Die Funktion ocr.formula extrahiert alle identifizierten Formeln, z. B. mathematische Formeln, in der Auflistung formulas als Objekt der obersten Ebene unter content. In content werden erkannte Formeln als :formula: dargestellt. Jeder Eintrag in dieser Auflistung stellt eine Formel dar, die den Formeltyp als inline oder display und seine LaTeX-Darstellung als value zusammen mit seinen polygon-Koordinaten enthält. Anfangs werden am Ende jeder Seite Formeln angezeigt.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.FORMULAS], # Specify which add-on capabilities to enable
)
result: AnalyzeResult = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
if page.formulas:
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
# To learn the detailed concept of "polygon" in the following content, visit: https://aka.ms/bounding-region
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.FORMULAS] # Specify which add-on capabilities to enable
)
result = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
Extraktion von Schrifteigenschaften
Die Funktion ocr.font extrahiert alle Schrifteigenschaften des in der Auflistung styles extrahierten Texts als Objekt der obersten Ebene unter content. Jedes Stilobjekt gibt eine einzelne Schrifteigenschaft, die Textspanne, für die es gilt, und die entsprechende Konfidenzbewertung an. Die vorhandene Stileigenschaft wird um weitere Schrifteigenschaften erweitert, z. B. similarFontFamily für die Schriftart des Texts, fontStyle für Stile wie kursiv und normal, fontWeight für fett oder normal, color für die Farbe des Texts und backgroundColor für die Farbe des Textbegrenzungsrahmens.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
return
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
Die Funktion ocr.barcode extrahiert alle identifizierten Barcodes in der Sammlung barcodes als Objekt der obersten Ebene unter content. Innerhalb von content werden erkannte Barcodes als :barcode: dargestellt. Jeder Eintrag in dieser Sammlung stellt einen Barcode dar und enthält den Barcodetyp als kind und den eingebetteten Barcodeinhalt als value zusammen mit seinen polygon-Koordinaten. Anfangs werden am Ende jeder Seite Barcodes angezeigt. confidence ist als 1 hartcodiert.
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {format_polygon(barcode.polygon)}")
Durch Hinzufügen des languages-Features an die analyzeResult-Anforderung wird die primäre Sprachen für jede Textzeile vorher, zusammen mit dem confidence-Wert in der languages-Sammlung unter analyzeResult.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
if result.languages:
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(
f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'"
)
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'")
Mit der durchsuchbaren PDF-Funktion können Sie eine analoge PDF-Datei, wie eine gescannte PDF-Datei, in eine PDF-Datei mit eingebettetem Text konvertieren. Der eingebettete Text ermöglicht die Deep-Text-Suche innerhalb des extrahierten PDF-Inhalts, indem die erkannten Textentitäten über die Bilddateien überlagert werden.
Wichtig
Derzeit wird die durchsuchbare PDF-Funktion nur vom Read OCR-Modell prebuilt-read unterstützt. Wenn Sie dieses Feature verwenden, geben Sie die modelId als prebuilt-read an, da andere Modelltypen für diese Vorschauversion einen Fehler zurückgeben.
Durchsuchbare PDF ist im 2024-07-31-Vorschaumodell prebuilt-read ohne Nutzungskosten für die allgemeine PDF-Nutzung enthalten.
Verwenden der durchsuchbaren PDF
Um durchsuchbare PDF-Dateien zu verwenden, stellen Sie eine POST-Anforderung mithilfe des Analyze-Vorgangs, und legen Sie das Ausgabeformat auf pdf fest:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Sobald der Analyze-Vorgang abgeschlossen ist, stellen Sie eine GET-Anforderung zum Abrufen der Analyze-Vorgangsergebnisse.
Nach erfolgreichem Abschluss kann die PDF abgerufen und als application/pdf heruntergeladen werden. Dieser Vorgang ermöglicht das direkte Herunterladen der eingebetteten Textform der PDF anstelle von Base64-codiertem JSON.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Schlüssel-Werte-Paare
In früheren API-Versionen hat das prebuilt-document-Modell Schlüssel-Wert-Paare aus Formularen und Dokumenten extrahiert. Mit dem Hinzufügen des keyValuePairs-Features zum vordefinierten Layout erzeugt das Layoutmodell jetzt dieselben Ergebnisse.
Schlüssel-Wert-Paare sind bestimmte Bereiche innerhalb des Dokuments, die eine Beschriftung oder einen Schlüssel und die zugehörige Antwort oder den zugehörigen Wert identifizieren. In einem strukturierten Formular könnten diese Paare die Beschriftung und der Wert sein, die der Benutzer für dieses Feld eingegeben hat. In einem unstrukturierten Dokument kann es sich um das Datum handeln, an dem ein Vertrag basierend auf dem Text in einem Absatz erfüllt wurde. Das KI-Modell wird trainiert, um identifizierbare Schlüssel und Werte basierend auf einer Vielzahl von Dokumenttypen, Formaten und Strukturen zu extrahieren.
Schlüssel können auch isoliert existieren, wenn das Modell feststellt, dass ein Schlüssel ohne zugehörigen Wert vorhanden ist, oder wenn optionale Felder verarbeitet werden. Beispielsweise kann ein Feld für den zweiten Vornamen in einigen Fällen in einem Formular leer gelassen werden. Schlüssel-Wert-Paare sind Textabschnitte, die im Dokument enthalten sind. Bei Dokumenten, in denen derselbe Wert auf unterschiedliche Weise beschrieben wird, z. B. Kunde/Benutzer, ist der zugehörige Schlüssel entweder Kunde oder Benutzer (je nach Kontext).
Abfragefelder sind eine Add-On-Funktion, um das Schema zu erweitern, das aus einem vordefinierten Modell extrahiert wurde, oder um einen bestimmten Schlüsselnamen zu definieren, wenn der Schlüsselname variable ist. Wenn Sie Abfragefelder verwenden möchten, legen Sie die Features auf queryFields fest, und stellen Sie eine durch Trennzeichen getrennte Liste von Feldnamen in der Eigenschaft queryFields bereit.
Document Intelligence unterstützt jetzt Abfragefeldextraktionen. Mit der Abfragefeldextraktion können Sie dem Extraktionsprozess Felder mithilfe einer Abfrageanforderung hinzufügen, ohne dass ein zusätzliches Training erforderlich ist.
Verwenden Sie Abfragefelder, wenn Sie das Schema eines vordefinierten oder benutzerdefinierten Modells erweitern oder einige Felder mit der Ausgabe des Layouts extrahieren müssen.
Abfragefelder sind eine Premium-Add-On-Funktion. Die besten Ergebnisse erzielen Sie, wenn Sie die Felder, die Sie extrahieren möchten, unter Verwendung von Feldnamen in Camel-Case- oder Pascal-Schreibweise für Feldnamen mit mehreren Wörtern definieren.
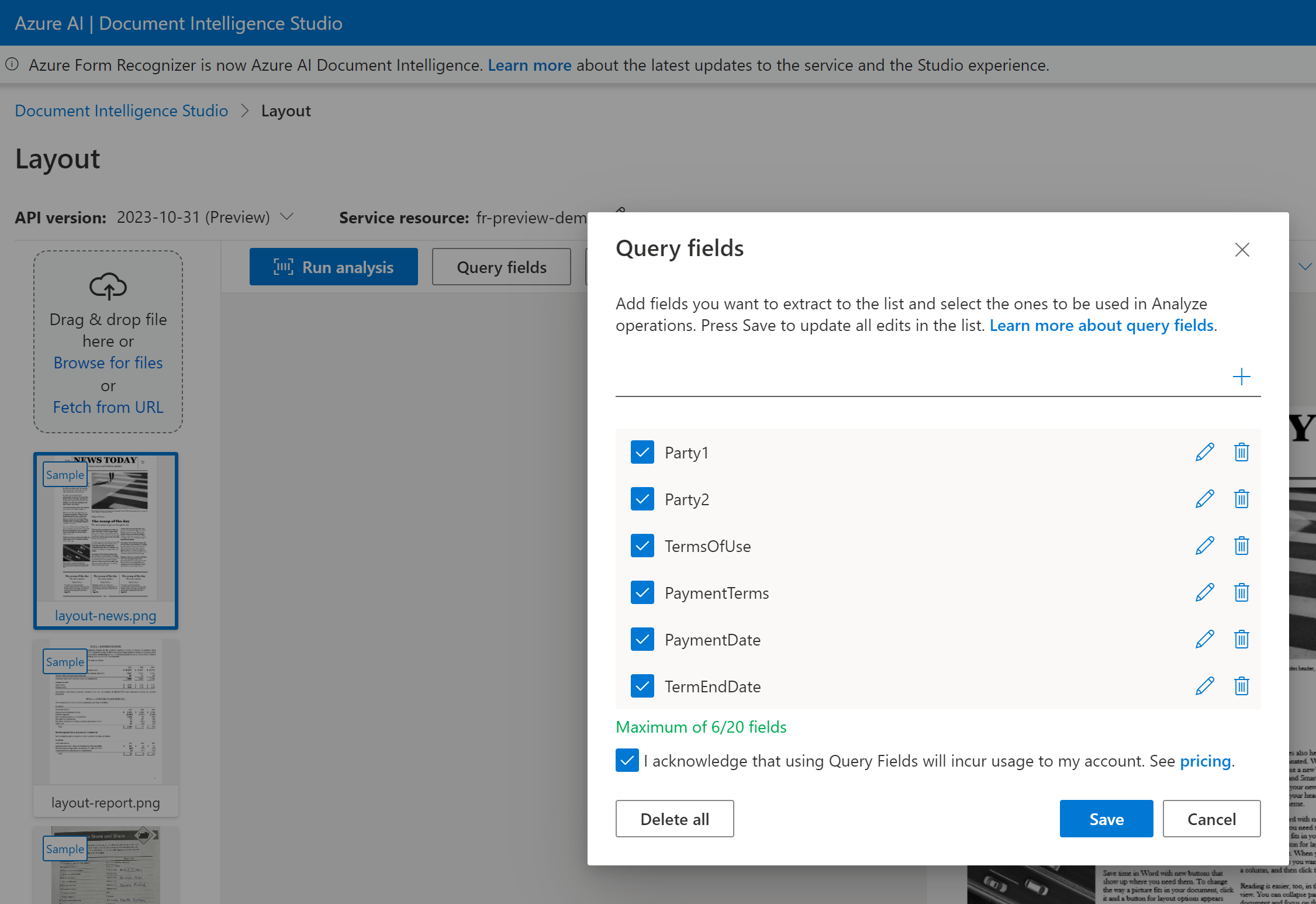
Abfragefelder unterstützen maximal 20 Felder pro Anforderung. Wenn das Dokument einen Wert für das Feld enthält, werden das Feld und der Wert zurückgegeben.
Diese Version enthält eine neue Implementierung der Abfragefeldfunktion, die preisgünstiger ist als die frühere Implementierung und validiert werden sollte.
Hinweis
Die Abfragefeldextraktion von Dokument Intelligenz Studio ist derzeit mit den Modellen „Layout“ und „Prebuilt“ verfügbar, beginnend mit der 2024-02-29-preview2023-10-31-preview-API und späteren Releases mit Ausnahme der US tax-Modelle (W2-, 1098er- und 1099er-Modelle).
Extraktion von Abfragefeldern
Geben Sie für die Abfragefeldextraktion die Felder an, die Sie extrahieren möchten, und Dokument Intelligenz analysiert das Dokument entsprechend. Ein Beispiel:
Wenn Sie einen Vertrag in Dokument Intelligenz Studio verarbeiten, verwenden Sie Version 2024-02-29-preview oder 2023-10-31-preview:
Sie können im Rahmen der analyze document-Anforderung eine Liste von Feldbezeichnungen wie z. B. Party1, Party2, TermsOfUse, PaymentTerms, PaymentDate und TermEndDate übergeben.
Dokument Intelligenz kann die Felddaten analysieren und extrahieren und die Werte in einer strukturierten JSON-Ausgabe zurückgeben.
Zusätzlich zu den Abfragefeldern enthält die Antwort Text, Tabellen, Auswahlzeichen und andere relevante Daten.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/invoice/simple-invoice.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.QUERY_FIELDS], # Specify which add-on capabilities to enable.
query_fields=["Address", "InvoiceNumber"], # Set the features and provide a comma-separated list of field names.
)
result: AnalyzeResult = poller.result()
print("Here are extra fields in result:\n")
if result.documents:
for doc in result.documents:
if doc.fields and doc.fields["Address"]:
print(f"Address: {doc.fields['Address'].value_string}")
if doc.fields and doc.fields["InvoiceNumber"]:
print(f"Invoice number: {doc.fields['InvoiceNumber'].value_string}")