Beschriften Ihrer Äußerungen in Language Studio
Nachdem Sie für Ihr Projekt ein Schema erstellt haben, sollten Sie Ihrem Projekt Trainingsäußerungen hinzufügen. Die Äußerungen sollten denen ähnlich sein, die Ihre Benutzer bei der Interaktion mit dem Projekt verwenden. Wenn Sie eine Äußerung hinzufügen, müssen Sie zuweisen, zu welcher Absicht sie gehört. Beschriften Sie nach dem Hinzufügen der Äußerung die darin enthaltenen Wörter, die Sie als Entitäten extrahieren möchten.
Die Datenbeschriftung ist ein wichtiger Schritt im Entwicklungslebenszyklus. Diese Daten werden im nächsten Schritt verwendet, wenn Sie Ihr Modell trainieren, damit Ihr Modell aus den beschrifteten Daten lernen kann. Wenn Sie bereits über beschriftete Äußerungen verfügen, können Sie sie direkt in Ihr Projekt importieren. Achten Sie jedoch darauf, dass Ihre Daten dem akzeptierten Datenformat entsprechen. Weitere Informationen zum Importieren beschrifteter Daten in Ihr Projekt finden Sie unter Projekt erstellen. Anhand von beschrifteten Daten kann das Modell bestimmen, wie Text interpretiert werden soll. Auch werden sie zum Trainieren und zur Auswertung verwendet.
Voraussetzungen
Um Daten beschriften zu können, benötigen Sie Folgendes:
- Ein erfolgreich erstelltes Projekt.
Weitere Informationen finden Sie unter Lebenszyklus der Projektentwicklung.
Richtlinien für die Datenbeschriftung
Nach dem Erstellen Ihres Schemas und dem Erstellen Ihres Projekts müssen Sie Ihre Daten beschriften. Die Beschriftung Ihrer Daten ist wichtig, damit Ihr Modell erkennt, welche Wörter und Sätze den Absichten und Entitäten in Ihrem Projekt zugeordnet werden. Lassen Sie sich beim Beschriften Ihrer Äußerungen genügend Zeit, um die Daten, die zum Trainieren Ihrer Modelle verwendet werden, einzuführen und zu optimieren.
Beachten Sie folgende Punkte, wenn Sie Äußerungen hinzufügen und sie beschriften:
Die Machine Learning-Modelle führen auf Basis der beschrifteten Beispiele, die Sie bereitstellen, Generalisierungen durch. Je mehr Beispiele Sie bereitstellen, desto mehr Datenpunkte stehen dem Modell zur Verfügung, was bessere Generalisierungen ermöglicht.
Die Genauigkeit, Konsistenz und Vollständigkeit der beschrifteten Daten sind wichtige Faktoren bei der Bestimmung der Modellleistung.
- Präzise beschriften: Beschriften Sie jede Absicht und Entität immer mit ihrem richtigen Typ. Schließen Sie nur das ein, was klassifiziert und extrahiert werden soll, und vermeiden Sie unnötige Daten in Ihren Beschriftungen.
- Konsistente Bezeichnungen: Die gleiche Entität sollte in allen Äußerungen die gleiche Bezeichnung haben.
- Vollständig beschriften: Stellen Sie für jede Absicht unterschiedliche Äußerungen bereit. Beschriften Sie alle Instanzen der Entität in allen Äußerungen.
Eindeutige Beschriftung von Äußerungen
Stellen Sie sicher, dass die Konzepte, auf die sich Ihre Entitäten beziehen, klar definiert und trennbar sind. Überprüfen Sie, ob Sie die Unterschiede problemlos und zuverlässig ermitteln können. Wenn dies nicht möglich ist, kann diese fehlende Unterscheidung ein Hinweis darauf sein, dass auch die erlernte Komponente Schwierigkeiten hat.
Wenn eine Ähnlichkeit zwischen Entitäten besteht, stellen Sie sicher, dass es einen Aspekt Ihrer Daten gibt, der ein Hinweis auf den Unterschied zwischen ihnen liefert.
Wenn Sie beispielsweise ein Modell zum Buchen von Flügen erstellt haben, kann ein Benutzer eine Äußerung wie „Ich möchte einen Flug von Boston nach Seattle“ verwenden. Es würde erwartet, dass der Abflugort und der Zielort für solche Äußerungen ähnlich sind. Ein Hinweis zur Differenzierung des Abflugorts könnte sein, dass diesem Wort oft das Wort von vorangeht.
Stellen Sie sicher, dass Sie alle Instanzen jeder Entität in Ihren Trainings- und Testdaten beschriften. Ein Ansatz besteht darin, die Suchfunktion zu verwenden, um alle Instanzen eines Worts oder Ausdrucks in Ihren Daten zu finden, und dann zu überprüfen, ob sie richtig beschriftet sind.
Beschriften Sie Testdaten für Entitäten, die keine gelernte Komponente besitzen, und auch für solche, die über eine verfügen. Auf diese Weise können Sie sicherstellen, dass Ihre Auswertungsmetriken korrekt sind.
Wenn Sie bei mehrsprachigen Projekten Äußerungen in anderen Sprachen hinzufügen, verbessert sich dadurch die Leistung des Modells in diesen Sprachen. Vermeiden Sie es jedoch, Ihre Daten für die Sprachen, die Sie unterstützen möchten, zu duplizieren. Zum Verbessern der Leistung eines Kalenderbots mit Benutzern könnte ein Entwickler beispielsweise vorwiegend englischsprachige Beispiele hinzufügen und darüber hinaus einige weitere in Spanisch oder Französisch. Er könnte etwa Äußerungen wie diese hinzufügen:
- „Set a meeting with Matt and Kevintomorrow at 12 PM.“ (Englisch)
- „Reply as tentative to the weekly update meeting.“ (Englisch)
- „Cancelar mi próxima reunión.“ (Spanisch)
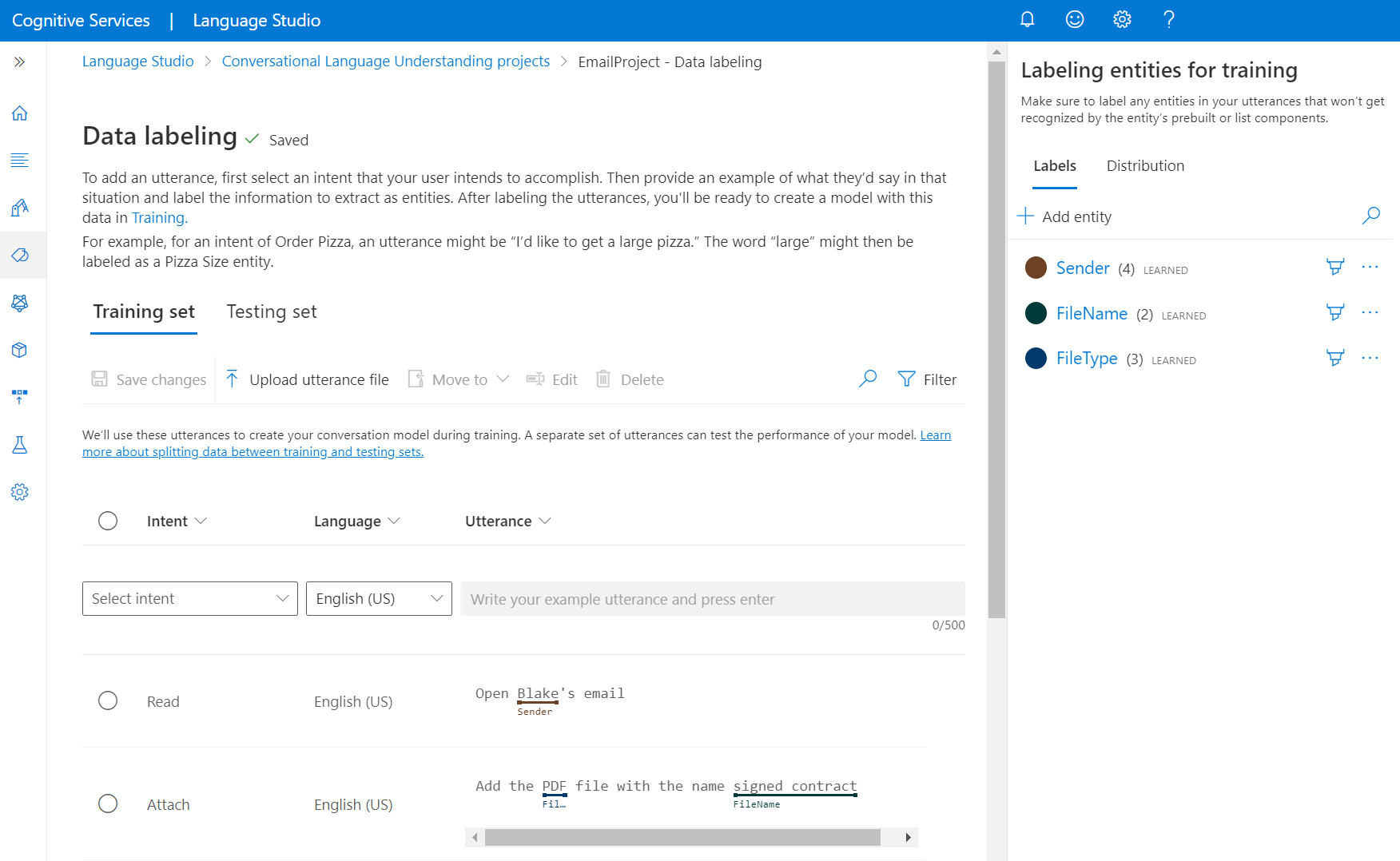
Beschriften Ihrer Äußerungen
Gehen Sie zur Beschriftung Ihrer Äußerungen wie folgt vor:
Wechseln Sie in Language Studio zu Ihrer Projektseite.
Wählen Sie im Menü auf der linken Seite die Option Datenbeschriftung aus. Auf dieser Seite können Sie damit beginnen, Ihre Äußerung hinzuzufügen und zu beschriften. Sie können Ihre Äußerung auch direkt hochladen, indem Sie im oberen Menü auf Hochladen der Äußerungsdatei klicken. Achten Sie darauf, dass sie dem akzeptierten Format entspricht.
Über die oberen Pivotelemente können Sie zwischen den Ansichten für Trainingssatz und Testsatz ändern. Weitere Informationen zu Trainings- und Testsätzen sowie zu ihrer Verwendung beim Trainieren und Auswerten von Modellen finden Sie hier.
Tipp
Wenn Sie die Aufteilung vom Typ Automatisches Aufteilen des Testsatzes aus Trainingsdaten verwenden möchten, fügen Sie alle Ihre Äußerungen dem Trainingssatz hinzu.
Wählen Sie im Dropdownmenü Absicht auswählen eine der Absichten, die Sprache der Äußerung (bei mehrsprachigen Projekten) und die eigentliche Äußerung aus. Drücken Sie die EINGABETASTE im Textfeld der Äußerung, um sie hinzuzufügen.
Für die Beschriftung von Entitäten in einer Äußerung stehen zwei Optionen zur Verfügung:
Option BESCHREIBUNG Beschriften mit einem Pinsel Wählen Sie neben einem Entitätstyp im rechten Bereich das Pinselsymbol aus, und markieren Sie dann den Text in der Äußerung, den Sie beschriften möchten. Beschriften über das Inlinemenü Markieren Sie das Wort, das Sie als Entität beschriften möchten, woraufhin ein Menü angezeigt wird. Wählen Sie die Entität aus, mit der Sie diese Wörter beschriften möchten. Im Bereich auf der rechten Seite finden Sie unter dem Pivotelement Bezeichnungen alle Entitätstypen in Ihrem Projekt sowie die jeweilige Anzahl beschrifteter Instanzen.
Unter dem Pivotelement Verteilung können Sie die Verteilung in den Schulungs- und Testsätzen anzeigen. Es gibt zwei Ansichtsoptionen:
- Gesamtinstanzen pro beschrifteter Entität: Diese Option ermöglicht die Betrachtung der Anzahl aller beschrifteten Instanzen einer bestimmten Entität.
- Eindeutige Äußerungen pro beschrifteter Entität: Bei dieser Option wird jede Äußerung gezählt, die mindestens eine beschriftete Instanz dieser Entität enthält.
- Äußerungen pro Absicht: Diese Option ermöglicht die Betrachtung der Anzahl von Äußerungen pro Absicht.


Hinweis
Listenkomponenten und vordefinierte Komponenten werden nicht auf der Seite für die Datenbeschriftung angezeigt, und alle hier verfügbaren Bezeichnungen gelten nur für die gelernte Komponente.
So entfernen Sie eine Bezeichnung:
- Wählen Sie in Ihrer Äußerung die Entität aus, für die Sie eine Bezeichnung entfernen möchten.
- Scrollen Sie durch das angezeigte Menü, und wählen Sie Bezeichnung entfernen aus.
So löschen Sie eine Entität
- Wählen Sie im rechten Seitenbereich die Entität aus, die Sie bearbeiten möchten.
- Klicken Sie auf die drei Punkte neben der Entität, und wählen Sie im Dropdownmenü die gewünschte Option aus.
Vorschlagen von Äußerungen mit Azure OpenAI
Verwenden Sie in CLU Azure OpenAI, um Äußerungen vorzuschlagen, die Ihrem Projekt mithilfe von GPT-Modellen hinzugefügt werden sollen. Sie müssen zunächst Zugriff erhalten und eine Ressource in Azure OpenAI erstellen. Anschließend müssen Sie eine Bereitstellung für die GPT-Modelle erstellen. Führen Sie die hier aufgeführten erforderlichen Schritte aus.
Bevor Sie beginnen, ist das Feature zum Vorschlagen von Äußerungen nur verfügbar, wenn sich Ihre Sprachressource in den folgenden Regionen befindet:
- East US
- USA Süd Mitte
- Europa, Westen
Auf der Seite „Datenbeschriftung“:
- Klicken Sie auf die Schaltfläche Äußerungen vorschlagen. Auf der rechten Seite wird ein Bereich geöffnet, in dem Sie aufgefordert werden, Ihre Azure OpenAI-Ressource und -Bereitstellung auszuwählen.
- Klicken Sie beim Auswählen einer Azure OpenAI-Ressource auf Verbinden, sodass Ihre Language-Ressource direkten Zugriff auf Ihre Azure OpenAI-Ressource erhält. Dabei wird Ihrer Sprachressource die Rolle
Cognitive Services Userfür Ihre Azure OpenAI-Ressource zugewiesen, was Ihrer aktuellen Sprachressource Zugriff auf den Azure OpenAI-Dienst gewährt. Bei einem Verbindungsfehler führen Sie die folgenden Schritte aus, um Ihrer Azure OpenAI-Ressource manuell die richtige Rolle hinzuzufügen. - Nachdem die Ressource verbunden wurde, wählen Sie die Bereitstellung aus. Das empfohlene Modell für die Azure OpenAI-Bereitstellung ist
text-davinci-002. - Wählen Sie die Absicht aus, für die Sie Vorschläge erhalten möchten. Stellen Sie sicher, dass für die ausgewählte Absicht mindestens 5 gespeicherte Äußerungen vorhanden sind, die für Äußerungsvorschläge aktiviert werden können. Die von Azure OpenAI bereitgestellten Vorschläge basieren auf den neuesten Äußerungen, die Sie für diese Absicht hinzugefügt haben.
- Wählen Sie Äußerungen generieren aus. Nach Abschluss des Vorgangs werden die vorgeschlagenen Äußerungen von einer gepunkteten Linie umschlossen mit dem Hinweis Generiert von KI angezeigt. Diese Vorschläge müssen akzeptiert oder abgelehnt werden. Wenn Sie einen Vorschlag akzeptieren, wird er einfach Ihrem Projekt hinzugefügt, als hätten Sie ihn selbst hinzugefügt. Durch eine Ablehnung wird der Vorschlag vollständig gelöscht. Nur akzeptierte Äußerungen werden Teil Ihres Projekts und für das Training oder Tests verwendet. Zum Akzeptieren oder Ablehnen klicken Sie neben jeder Äußerung auf die Schaltfläche mit dem grünen Häkchen oder die rote Abbrechen-Schaltfläche. Sie können auch die Schaltflächen
Accept allundReject allin der Symbolleiste verwenden.

Die Verwendung dieses Features geht mit einer Gebühr für Ihre Azure OpenAI-Ressource für eine ähnlich hohe Anzahl von Token wie die generierten vorgeschlagenen Äußerungen einher. Details zu den Preisen von Azure OpenAI finden Sie hier.
Hinzufügen erforderlicher Konfigurationen zur Azure OpenAI-Ressource
Wenn beim Verbinden Ihrer Sprachressource mit einer Azure OpenAI-Ressource ein Fehler auftritt, führen Sie die folgenden Schritte aus:
Aktivieren Sie die Identitätsverwaltung für Ihre Sprachressource mithilfe der folgenden Optionen:
Für Ihre Language-Ressource muss die Identitätsverwaltung aktiviert sein. Aktivieren Sie sie wie folgt über das Azure-Portal:
- Navigieren Sie zu Ihrer Sprachressource.
- Wählen Sie im Menü auf der linken Seite unter Ressourcenverwaltung die Option Identität aus.
- Legen Sie auf der Registerkarte Systemseitig zugewiesen die Option Status unbedingt auf Ein fest.
Nachdem Sie die verwaltete Identität aktiviert haben, weisen Sie Ihrer Azure OpenAI-Ressource mithilfe der verwalteten Identität Ihrer Sprachressource die Rolle Cognitive Services User zu.
- Navigieren Sie zum Azure-Portal und dann zu Ihrer Azure OpenAI-Ressource.
- Klicken Sie links auf die Registerkarte Access Control (IAM).
- Wählen Sie Hinzufügen > Rollenzuweisung hinzufügen aus.
- Wählen Sie „Auftragsfunktionsrollen“ aus, und klicken Sie auf „Weiter“.
- Wählen Sie in der Liste der Rollen
Cognitive Services Useraus, und klicken Sie auf „Weiter“. - Wählen Sie Zugriff zuweisen an "Verwaltete Identität" aus, und klicken Sie auf "Member auswählen".
- Wählen Sie unter „Verwaltete Identität“ die Option „Sprache“ aus.
- Suchen Sie nach Ihrer Ressource, und wählen Sie sie aus. Klicken Sie dann auf die Schaltfläche Auswählen darunter und dann auf Weiter, um den Vorgang abzuschließen.
- Überprüfen Sie die Details, und klicken Sie auf Überprüfen + Zuweisen.

Aktualisieren Sie Language Studio nach einigen Minuten, und dann können Sie erfolgreich eine Verbindung mit Azure OpenAI herstellen.
Nächste Schritte
- Train Model (Modell trainieren)