Was ist Custom Speech?
Custom Speech ermöglicht es Ihnen, die Genauigkeit der Spracherkennung für Ihre Anwendungen und Produkte zu bewerten und zu verbessern. Ein benutzerdefiniertes Sprachmodell kann für Spracherkennung in Echtzeit, Sprachübersetzung und Batchtranskription verwendet werden.
Ohne weitere Konfiguration verwendet die Spracherkennung ein universelles Sprachmodell als Basismodell, das mit Microsoft-eigenen Daten trainiert wird und häufig verwendete gesprochene Sprache widerspiegelt. Das Basismodell wird mit Dialekten und Phonemen vortrainiert, die verschiedene gängige Fachgebiete abbilden. Wenn Sie eine Anforderung zur Spracherkennung ausführen, wird standardmäßig das aktuelle Basismodell für jede unterstützte Sprache verwendet. Das Basismodell funktioniert in den meisten Spracherkennungsszenarien gut.
Ein benutzerdefiniertes Modell kann verwendet werden, um das Basismodell mit dem Ziel zu erweitern, die Erkennung von Fachvokabular zu verbessern, das für die Anwendung spezifisch ist, indem Textdaten zum Trainieren des Modells bereitgestellt werden. Es kann außerdem verwendet werden, um die Erkennung basierend auf den spezifischen Audiobedingungen der Anwendung zu verbessern, indem Audiodaten mit Referenztranskriptionen bereitgestellt werden.
Sie können auch ein Modell mit strukturiertem Text trainieren, wenn die Daten einem Muster folgen, benutzerdefinierte Aussprachen festlegen und die Formatierung des Anzeigetextes mit benutzerdefinierter inverser Textnormalisierung, benutzerdefinierter Neuschreibung und benutzerdefinierter Filterung von Schimpfwörtern anpassen.
Wie funktioniert dies?
Mit Custom Speech können Sie eigene Daten hochladen, ein benutzerdefiniertes Modell testen und trainieren, die Genauigkeit zwischen Modellen vergleichen und ein Modell auf einem benutzerdefinierten Endpunkt bereitstellen.
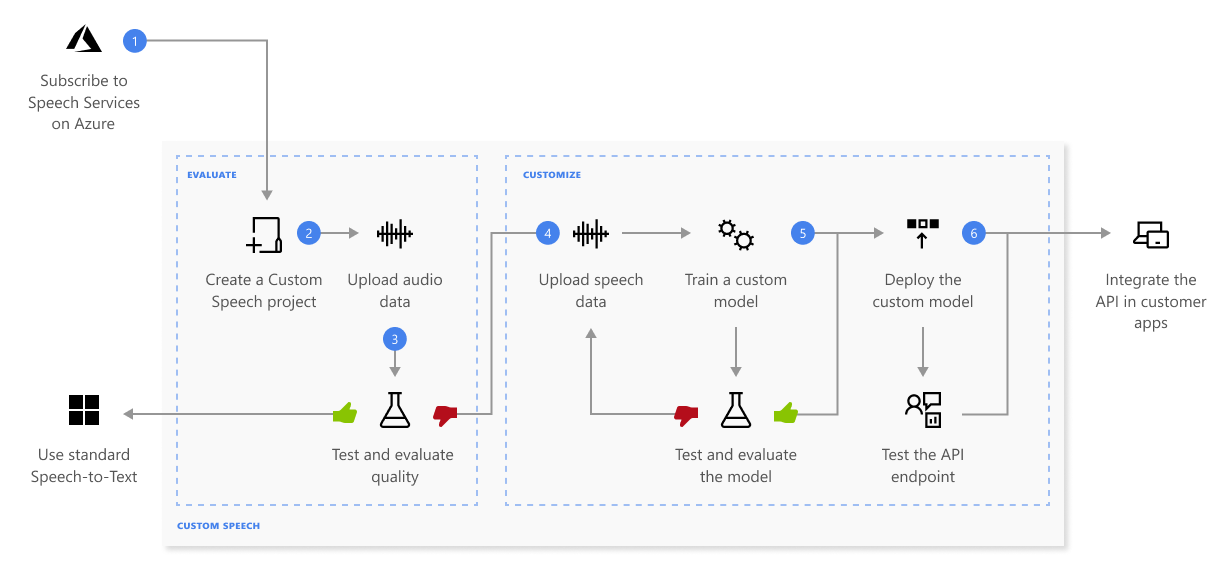
Hier finden Sie weitere Informationen zur Abfolge der Schritte, die im vorstehenden Diagramm dargestellt sind:
- Erstellen Sie ein Projekt, und wählen Sie ein Modell aus. Verwenden Sie eine Speech-Ressource, die Sie im Azure-Portal erstellen. Wenn Sie ein benutzerdefiniertes Modell mit Audiodaten trainieren, wählen Sie eine Region für eine KI Services-Ressource für Sprache mit dedizierter Hardware zum Trainieren mit Audiodaten aus. Weitere Informationen finden Sie in den Fußnoten der Tabelle Regionen.
- Hochladen von Testdaten: Laden Sie Testdaten hoch, um das Spracherkennungsangebot für Ihre Anwendungen, Tools und Produkte zu bewerten.
- Testen der Erkennungsqualität. Verwenden Sie Speech Studio zur Wiedergabe hochgeladener Audiodateien, und überprüfen Sie die Qualität der Spracherkennung Ihrer Testdaten.
- Quantitatives Testen des Modells. Bewerten und verbessern Sie die Genauigkeit des Spracherkennungsmodells. Der Speech-Dienst stellt eine quantitative Wortfehlerrate (Word Error Rate, WER) zur Verfügung, mit der Sie bestimmen können, ob weiteres Training erforderlich ist.
-
Trainieren eines Modells. Stellen Sie schriftliche Transkriptionen und verwandten Text zusammen mit den entsprechenden Audiodaten bereit. Das Testen eines Modells vor und nach dem Training ist optional, wird aber empfohlen.
Hinweis
Sie bezahlen für die Nutzung des benutzerdefinierten Sprachmodells und das Endpunkthosting. Ihnen werden zudem Gebühren für das Training des benutzerdefinierten Sprachmodells in Rechnung gestellt, wenn das Basismodell am 1. Oktober 2023 oder nach diesem Datum erstellt wurde. Wenn das Basismodell vor Oktober 2023 erstellt wurde, fallen keine Kosten für das Training an. Weitere Informationen finden Sie unter Azure KI Speech – Preise und im Abschnitt „Gebühren für die Anpassung“ im Migrationsleitfaden zu Version 3.2 der Spracherkennungs-API.
-
Bereitstellen eines Modells Sobald Sie mit den Testergebnissen zufrieden sind, stellen Sie das Modell auf einem benutzerdefinierten Endpunkt bereit. Mit Ausnahme der Batchtranskription müssen Sie einen benutzerdefinierten Endpunkt bereitstellen, um ein Custom Speech-Modell zu verwenden.
Tipp
Ein gehosteter Bereitstellungsendpunkt ist nicht erforderlich, um Custom Speech mit der Batchtranskriptions-API zu verwenden. Sie können Ressourcen sparen, wenn das Custom Speech-Modell nur für die Batchtranskription verwendet wird. Weitere Informationen finden Sie unter Preise für den Speech-Dienst.
Verantwortungsbewusste künstliche Intelligenz
Zu einem KI-System gehört nicht nur die Technologie, sondern auch die Personen, die das System verwenden, sowie die davon betroffenen Personen und die Umgebung, in der es bereitgestellt wird. Lesen Sie die Transparenzhinweise, um mehr über die verantwortungsvolle Nutzung und den Einsatz von KI in Ihren Systemen zu erfahren.
- Transparenzhinweis und Anwendungsfälle
- Merkmale und Einschränkungen
- Integration und verantwortungsvolle Verwendung
- Daten, Datenschutz und Sicherheit