Erläuterungen zur Azure Monitor-Metrikaggregation und -anzeige
Dieser Artikel erläutert die Aggregation von Metriken in der Zeitreihendatenbank, die Plattformmetriken und benutzerdefinierte Metriken von Azure Monitor unterstützt. Der Artikel gilt auch für Application Insights-Standardmetriken.
Die Informationen in diesem Artikel sind komplex und werden für diejenigen bereitgestellt, die sich tiefer mit dem Metriksystem befassen möchten. Sie müssen diese Informationen nicht verstehen, um Azure Monitor-Metriken effektiv verwenden zu können.
Übersicht und Terminologie
Wenn Sie einem Diagramm eine Metrik hinzufügen, wählt der Metrik-Explorer automatisch deren Standardaggregation aus. In den grundlegenden Szenarien ist die Standardeinstellung sinnvoll, doch Sie können andere Aggregationen verwenden, um zusätzliche Einblicke in die Metrik zu erhalten. Wenn Sie verschiedene Aggregationen in einem Diagramm anzeigen möchten, müssen Sie verstehen, wie diese vom Metrik-Explorer verarbeitet werden.
Beginnen wir zunächst mit der Definition einiger Begriffe:
- Metrikwert: Ein einzelner Messwert, der für eine spezifische Ressource abgerufen wird.
- Zeitreihendatenbank - Eine Datenbank, die für das Speichern und Abrufen von Datenpunkten optimiert ist, die alle einen Wert und einen entsprechenden Zeitstempel enthalten.
- Zeitraum: Eine generische Zeitspanne.
- Zeitintervall: Der Zeitraum zwischen dem Abruf von zwei Metrikwerten.
- Zeitbereich: Der in einem Diagramm angezeigte Zeitraum. Die Standardeinstellung beträgt 24 Stunden. Es stehen nur bestimmte Bereiche zur Verfügung.
- Zeitgranularität oder Aggregationsintervall: Der Zeitraum für das Aggregieren von Werten für die Anzeige in einem Diagramm. Es stehen nur bestimmte Bereiche zur Verfügung. Der aktuelle Mindestwert beträgt 1 Minute. Ein sinnvoller Wert für die Zeitgranularität muss kleiner sein als der ausgewählte Zeitbereich, andernfalls wird für das gesamte Diagramm nur ein Wert angezeigt.
- Aggregationstyp: Ein Statistiktyp, der aus mehreren Metrikwerten berechnet wird.
- Aggregieren: Der Vorgang, bei dem mehrere Eingangswerte erfasst und dann anhand der durch den Aggregationstyp definierten Regeln zu einem einzigen Ausgabewert verarbeitet werden. Beispielsweise kann so ein Durchschnitt aus mehreren Werten ermittelt werden.
Zusammenfassung des Ablaufs
Metriken sind eine Serie von Werten, die mit einem Zeitstempel gespeichert werden. In Azure werden die meisten Metriken in der Zeitreihendatenbank Azure Metrics gespeichert. Wenn Sie ein Diagramm zeichnen, werden die Werte der ausgewählten Metriken aus der Datenbank abgerufen und dann basierend auf der Granularität der ausgewählten Zeit (auch als Zeit Korn bezeichnet) separat aggregiert. Sie wählen Sie Zeitgranularität über die Zeitauswahl im Metrik-Explorer aus. Wenn Sie keine explizite Auswahl treffen, wird die Zeitgranularität basierend auf dem aktuell ausgewählten Zeitraum automatisch ausgewählt. Sobald eine Auswahl getroffen wurde, werden die Metrikwerte, die in jedem Granularitätsintervall erfasst wurden, aggregiert und in das Diagramm eingefügt (jeweils ein Datenpunkt pro Intervall).
Aggregationstypen
Im Metrik-Explorer sind fünf grundlegende Aggregationstypen verfügbar: Der Metrik-Explorer blendet Aggregationen aus, die irrelevant sind und für eine Metrik nicht verwendet werden können.
- Sum: Die Summe aller Werte, die über das Aggregationsintervall erfasst wurden. Dieser Aggregationstyp wird gelegentlich auch als Gesamtaggregation bezeichnet.
- Count: Die Anzahl der Messwerte, die über das Aggregationsintervall erfasst wurden. Bei diesem Aggregationstyp wird nicht der Wert der Messung, sondern nur die Anzahl von Datensätzen betrachtet.
- Average: Der Durchschnitt der Metrikwerte, die über das Aggregationsintervall erfasst wurden. Für die meisten Metriken entspricht dies der Summe aller Werte geteilt durch die Anzahl aller Werte (Sum/Count).
- Min: Der niedrigste Wert, der über das Aggregationsintervall erfasst wurde.
- Max: Der höchste Wert, der über das Aggregationsintervall erfasst wurde.
Angenommen, ein Diagramm zeigt für eine VM die Metrik Ausgehender Netzwerkdatenverkehr gesamt unter Verwendung der Aggregation SUM über einen Zeitraum der letzten 24 Stunden an. Der Zeitbereich und die Zeitgranularität können oben rechts im Diagramm geändert werden, wie im folgenden Screenshot zu sehen ist.
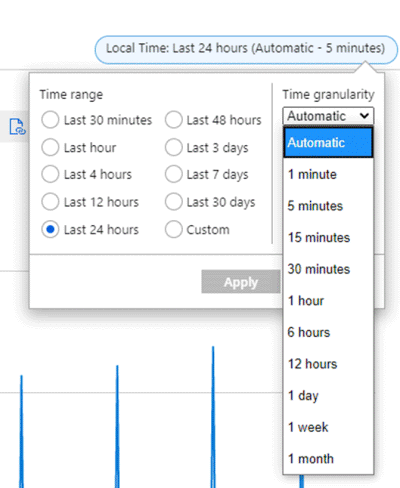
Bei einer Festlegung der Zeitgranularität auf 30 Minuten und Auswahl eines Zeitbereichs von 24 Stunden ergibt sich Folgendes:
- Im Diagramm werden 48 Datenpunkte gezeichnet. Dies entspricht 24 Stunden × 2 Datenpunkte pro Stunde (60 Minuten/30 Minuten), aggregiert zu 1-Minuten-Datenpunkten.
- Das Liniendiagramm verbindet 48 Punkte in der Zeichnungsfläche des Diagramms.
- Jeder Datenpunkt repräsentiert die Summe aller Bytes, die während der jeweiligen 30-minütigen Zeitspanne aus dem Netzwerk gesendet werden.

Klicken Sie auf die Abbildungen in diesem Abschnitt, um größere Versionen anzuzeigen.
Wenn Sie die Zeitgranularität stattdessen auf 15 Minuten festlegen, wird das Diagramm basierend auf 96 aggregierte Datenpunkten gezeichnet. Dies entspricht 60 Minuten/15 Minuten = 4 Datenpunkte pro Stunde × 24 Stunden.

Bei einer Zeitgranularität von 5 Minuten erhalten Sie 24 × (60/5) = 288 Punkte.
Bei einer Zeitgranularität von 1 Minute (dem kleinstmöglichen Wert im Diagramm) erhalten Sie 24 × 60/1 = 1.440 Punkte.

Die Diagramme für diese Summierungen sehen unterschiedlich aus, wie in den vorherigen Screenshots gezeigt wird. Wie Sie sehen, generiert diese VM innerhalb kurzer Zeit zahlreiche Ausgaben (im Verhältnis zum restlichen Zeitfenster).
Mithilfe der Zeitgranularität können Sie das „Signal-Rausch-Verhältnis“ für ein Diagramm anpassen. Höhere Aggregationswerte verringern Rauschen und glätten Spitzen. Beachten Sie die Abweichungen im unteren 1-Minuten-Diagramm und deren Glättung bei einer Festlegung höherer Granularitätswerte.
Dieses Glättungsverhalten ist wichtig, wenn Sie diese Daten an andere Systeme senden, beispielsweise in Form von Warnungen. In der Regel möchten Sie nicht über kurze Spitzen benachrichtigt werden, bei denen die CPU-Zeit mehr als 90 Prozent beträgt. Wenn die CPU-Auslastung jedoch für 5 Minuten bei 90 % liegt, ist dies wahrscheinlich wichtig. Wenn Sie eine Warnungsregel für die CPU (oder eine andere beliebige Metrik) festlegen, kann eine höhere Zeitgranularität die Anzahl falscher Warnungen verringern.
Es ist wichtig, den Normalzustand für Ihre Workload zu definieren, damit das optimale Zeitintervall bestimmt werden kann. Dies ist einer der Vorteile von dynamischen Warnungen. Hierbei handelt es sich jedoch um ein anderes Thema, das hier nicht behandelt wird.
Sammlung von Metriken durch das System
Die Datensammlung variiert je nach Metrik.
Hinweis
Die folgenden Beispiele wurden zur Veranschaulichung vereinfacht, und die tatsächlichen Metrikdaten, die in den einzelnen Aggregationen enthalten sind, werden durch die Daten beeinflusst, die zum Zeitpunkt der Auswertung verfügbar sind.
Sammlungshäufigkeit für Metriken
Es gibt zwei Arten von Sammlungszeiträumen.
Regulär: Die Metrik wird in einem festen Zeitintervall abgerufen, das nicht variiert.
Aktivitätsbasiert: Die Metrik wird basierend auf dem Auftreten einer Transaktion eines bestimmten Typs abgerufen. Jede Transaktion umfasst einen Metrikdatensatz und einen Zeitstempel. Sie werden nicht in regelmäßigen Intervallen abgerufen. Daher kann die Anzahl von Datensätzen in einem bestimmten Zeitraum variieren.
Granularität
Der Mindestwert für die Zeitgranularität beträgt 1 Minute, aber das zugrunde liegende System erfasst Daten je nach Metrik möglicherweise häufiger. Beispielsweise wird der CPU-Prozentsatz für eine Azure-VM in einem Zeitintervall von 15 Sekunden erfasst. Da HTTP-Fehler als Transaktionen nachverfolgt werden, können sie sehr viel häufiger als einmal pro Minute erfasst werden. Andere Metriken wie z. B. „SQL-Speicher“ werden in einem Zeitintervall von 20 Minuten erfasst. Diese Auswahl richtet sich nach dem jeweiligen Ressourcenanbieter und -typ. In den meisten Fällen wird versucht, das kleinstmögliche Zeitintervall bereitzustellen.
Dimensionen, Aufteilung und Filterung
Metriken werden für jede einzelne Ressource erfasst. Die Ebene, auf der die Metriken gesammelt, gespeichert und als Diagramm dargestellt werden können, kann jedoch variieren. Diese Ebene wird durch weitere Metriken dargestellt, die in Metrikdimensionen verfügbar sind. Jeder einzelne Ressourcenanbieter definiert, wie detailliert die gesammelten Daten erfasst werden. Azure Monitor definiert lediglich, wie diese Details präsentiert und gespeichert werden.
Wenn Sie eine Metrik im Metrik-Explorer als Diagramm darstellen, haben Sie die Option, das Diagramm nach einer Dimension aufzuteilen. Das Aufteilen eines Diagramms bedeutet, dass Sie sich die zugrunde liegenden Daten im Detail ansehen und diese Daten als Diagramm oder gefiltert im Metrik-Explorer angezeigt werden.
Beispiel: Microsoft.ApiManagement/service umfasst für viele Metriken die Dimension Standort.
Eine solche Metrik ist Kapazität. Die Dimension Standort impliziert, dass das zugrunde liegende System einen Metrikdatensatz für die Kapazität an jedem Standort und nicht lediglich einen Datensatz für die aggregierte Menge speichert. Sie können diese Informationen anschließend in einem Metrikdiagramm abrufen oder aufteilen.
Die Gesamtdauer von Gatewayanforderungen umfasst 2 Dimensionen: Standort und Hostname. Damit können Sie die Dauer für einen Standort ermitteln und wissen, durch welchen Hostnamen sie verursacht wurde.
Eine der flexibleren Metriken, Anforderungen, umfasst 7 verschiedene Dimensionen.
Weitere Informationen zu jeder Metrik und den verfügbaren Dimensionen finden Sie im Artikel zu den von Azure Monitor unterstützten Metriken. Zusätzlich werden in der Dokumentation zu jedem Ressourcenanbieter und -typ möglicherweise weitere Informationen zu den Dimensionen und deren Messung bereitgestellt.
Sie können Aufteilung und Filterung gemeinsam verwenden, um ein Problem zu untersuchen. Die nachfolgende Abbildung zeigt die Metrik Durchschnittliche Datenträgerschreibvorgänge in Bytes für eine Gruppe von VMs in einer Ressourcengruppe. Es ist ein Rollup aller VMs mit dieser Metrik vorhanden, aber wir möchten möglicherweise wissen, welche VMs für die Spitzen um etwa 6:00 Uhr morgens verantwortlich sind. Handelt es sich um ein und dieselbe VM? Wie viele VMs sind beteiligt?

Klicken Sie auf die Abbildungen in diesem Abschnitt, um größere Versionen anzuzeigen.
Bei Anwendung einer Aufteilung werden die zugrunde liegenden Daten angezeigt, aber diese sind sehr unübersichtlich. Es stellt sich heraus, dass im Diagramm oben 20 VMs aggregiert werden. In diesem Fall haben wir mit der Maus auf den Spitzenwert um 6:00 Uhr morgens gezeigt, um CH-DCVM11 als Quelle für die Spitze zu ermitteln. Es ist jedoch schwierig, die übrigen Daten für diese VM anzuzeigen, weil andere VMs das Diagramm unübersichtlich machen.

Mithilfe der Filterung können wir das Diagramm bereinigen und sehen, was tatsächlich passiert ist. Sie können die VMs aktivieren oder deaktivieren, die Sie anzeigen möchten. Beachten Sie die gepunktete Linien. Dieser werden in einem späteren Abschnitt besprochen.

Weitere Informationen zum Aufteilen von Dimensionsdaten für ein Metrik-Explorer-Diagramm finden Sie unter Erweiterte Funktionen von Azure Metrik-Explorer – Filter und Aufteilung.
NULL- und Nullwerte (0)
Wenn das System Metrikdaten von einer Ressource erwartet, aber nicht empfängt, wird ein NULL-Wert aufgezeichnet. Ein NULL-Wert unterscheidet sich von einem Nullwert (0), was bei der Berechnung von Aggregationen und der Diagrammerstellung zum Tragen kommt. NULL-Werte zählen nicht als gültige Messungen.
Sie werden in den verschiedenen Diagrammtypen unterschiedlich angezeigt. In einem Punktdiagramm wird ein Punkt im Diagramm übersprungen. Bei einem Balkendiagramm wird die Anzeige eines Balkens übersprungen. In Liniendiagrammen können NULL-Werte als gepunktete oder gestrichelte Linien angezeigt werden, ähnlich denen im Screenshot im vorherigen Abschnitt. Bei der Berechnung von Durchschnittswerten, die NULL-Werte enthalten, gibt es weniger Datenpunkte, aus denen der Durchschnitt gebildet werden kann. Dies kann gelegentlich zu einem unerwarteten Werteeinbruch in einem Diagramm führen. Die Auswirkung ist aber geringer als bei einer Konvertierung des Werts in den Wert 0, der anschließend als gültiger Datenpunkt verwendet wird.
Benutzerdefinierte Metriken verwenden immer NULL-Werte, wenn keine Daten empfangen werden. Bei Plattformmetriken entscheidet jeder Ressourcenanbieter abhängig davon, was für eine bestimmte Metrik am sinnvollsten ist, ob Nullwerte oder NULL-Werte verwendet werden.
Azure Monitor-Warnungen verwenden die Werte, die der Ressourcenanbieter in die Metrikdatenbank schreibt. Da es wichtig zu wissen ist, wie der Ressourcenanbieter NULL-Werte verarbeitet, sollten die Daten zunächst angezeigt werden.
Funktionsweise der Aggregation
Die Metrikdiagramme im vorherigen Abschnitt zeigen verschiedene Arten von aggregierten Daten. Das System aggregiert die Daten vorab, sodass die angeforderten Diagramme ohne zahlreiche wiederholte Berechnungen schnell angezeigt werden können.
In diesem Beispiel:
- Es wird eine fiktive Transaktionsmetrik namens HTTP-Fehler erfasst.
- Hierbei ist Server eine Dimension für die Metrik HTTP-Fehler.
- Wir verfügen über drei Server: Server A, Server B und Server C.
Zur Vereinfachung verwenden wir zunächst ausschließlich den SUM-Aggregationstyp.
Aggregation für einen Zeitraum von bis zu einer Minute
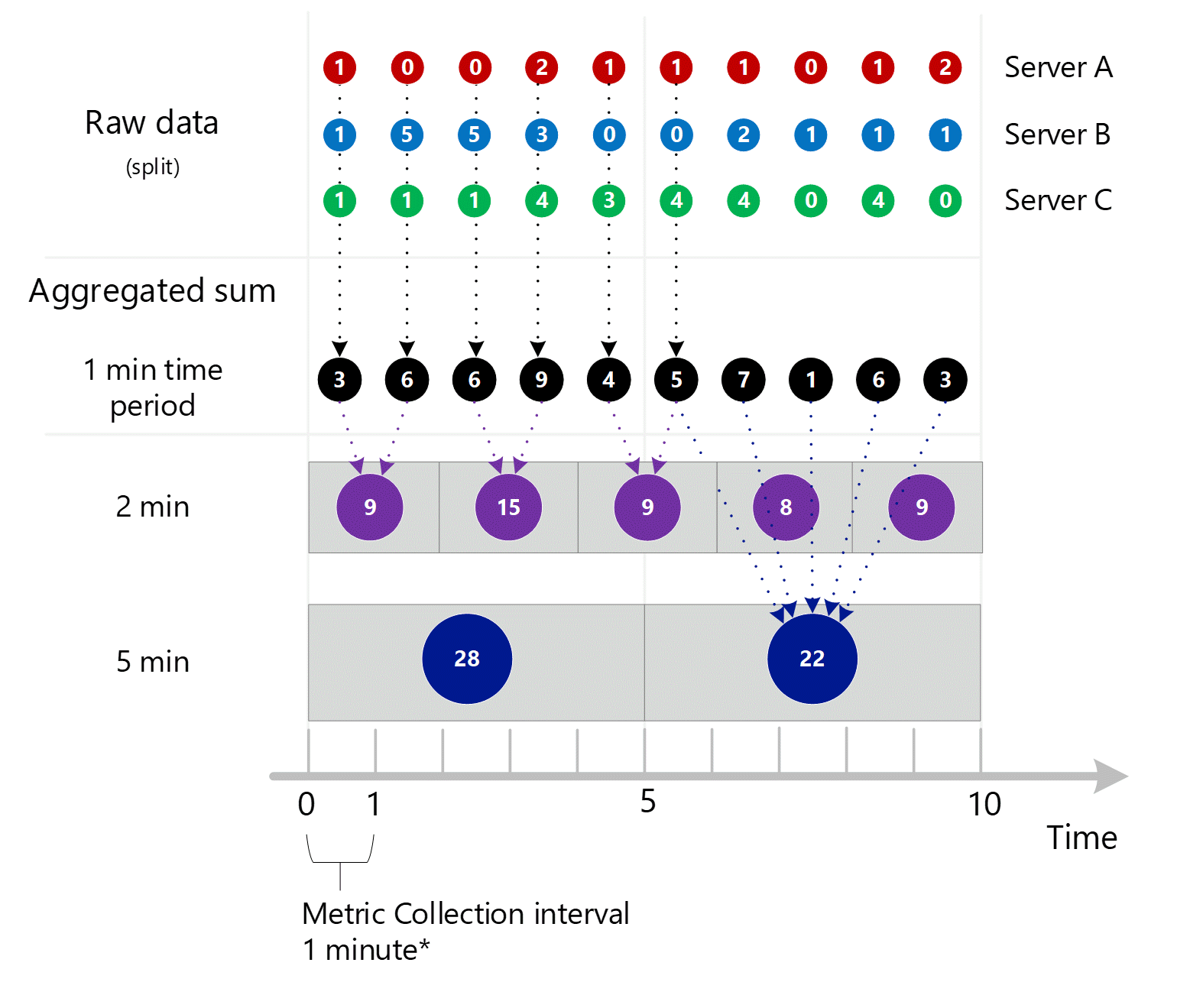
Zunächst werden Metrikrohdaten erfasst und in der Azure Monitor-Metrikdatenbank gespeichert. In diesem Fall speichert jeder Server Transaktionsdatensätze mit einem Zeitstempel, weil Server eine Dimension ist. Da der kleinste Zeitraum, den Sie als Kunde betrachten können, 1 Minute beträgt, werden diese Zeitstempel zunächst zu 1-Minuten-Metrikwerten für jeden einzelnen Server aggregiert. Der Aggregationsprozess für Server B wird in der nachstehenden Abbildung gezeigt. Die Server A und C arbeiten in gleicher Weise und umfassen andere Daten.
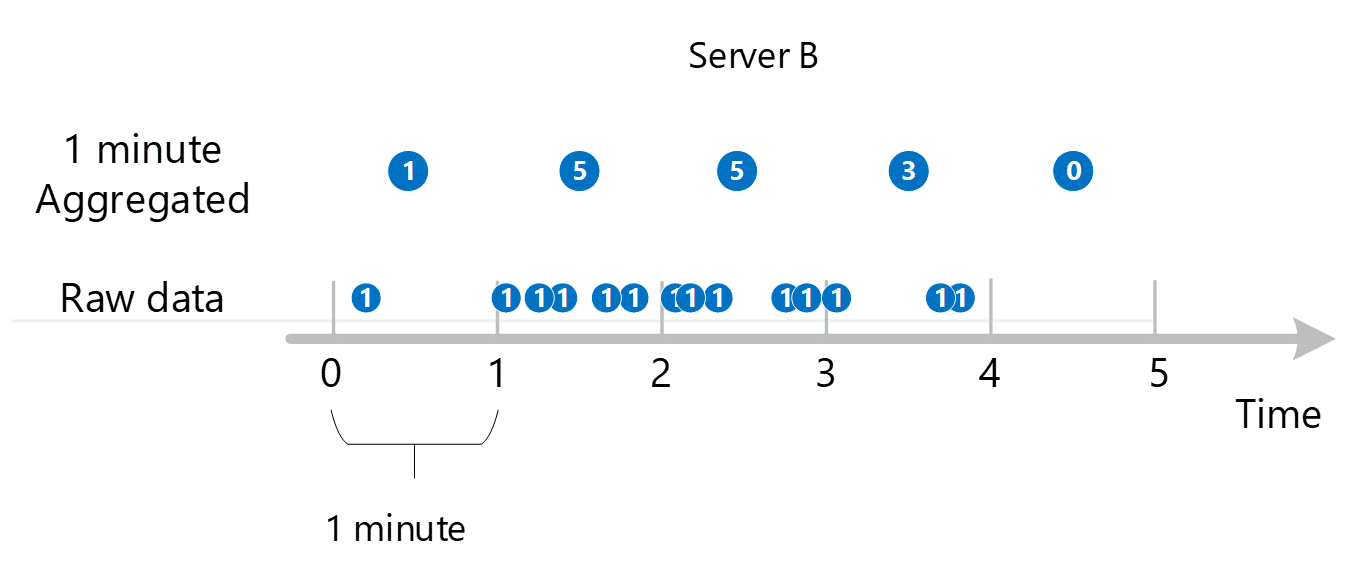
Die daraus resultierenden 1-Minuten-Aggregationswerte werden als neue Datensätze in der Metrikdatenbank gespeichert, damit sie für spätere Berechnungen herangezogen werden können.
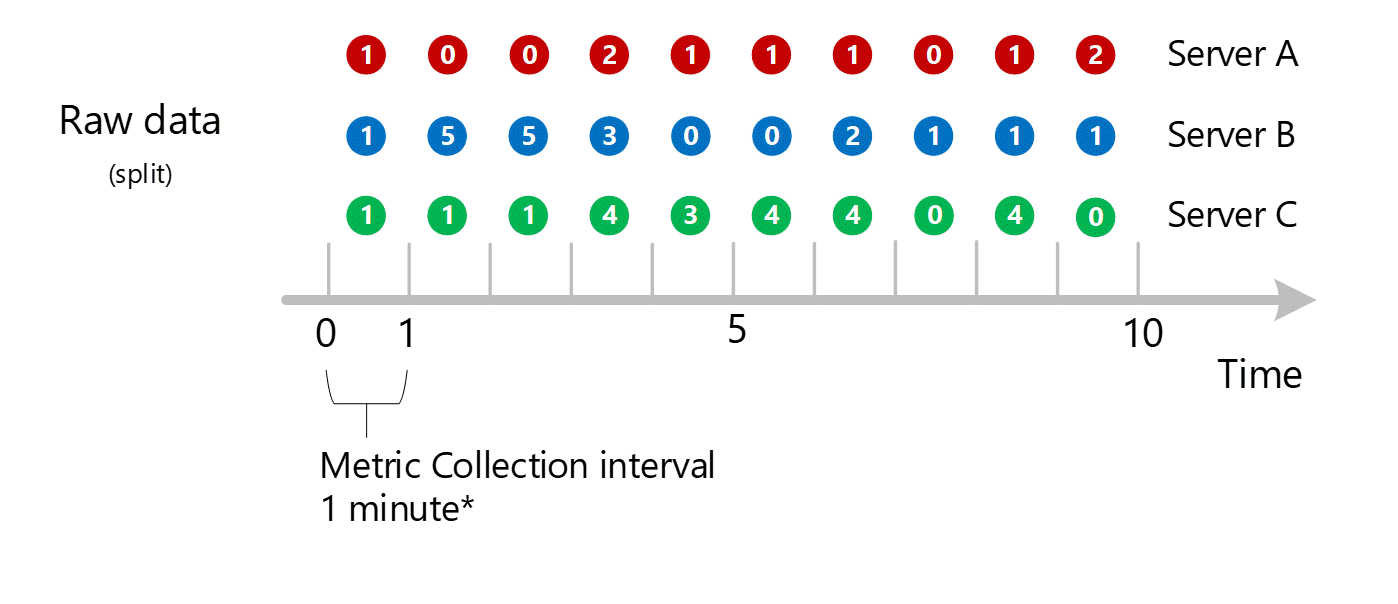
Dimensionsaggregation
Die 1-Minuten-Berechnungen werden anschließend nach Dimension zusammengefasst und wieder als einzelne Datensätze gespeichert. In diesem Fall werden alle Daten der einzelnen Server in einer Metrik mit 1-Minuten-Intervall aggregiert und für die Verwendung in späteren Aggregationen in der Metrikdatenbank gespeichert.

Zur Verdeutlichung zeigt die folgende Tabelle die Aggregationsmethode.
| Zeitraum | Server A | Server B | Server C | Sum (A+B+C) |
|---|---|---|---|---|
| Minute 1 | 1 | 1 | 1 | 3 |
| Minute 2 | 0 | 5 | 1 | 6 |
| Minute 3 | 0 | 5 | 1 | 6 |
| Minute 4 | 2 | 3 | 4 | 9 |
| Minute 5 | 1 | 0 | 3 | 4 |
| Minute 6 | 1 | 0 | 4 | 5 |
| Minute 7 | 1 | 2 | 4 | 7 |
| Minute 8 | 0 | 1 | 0 | 1 |
| Minute 9 | 1 | 1 | 4 | 6 |
| Minute 10 | 2 | 1 | 0 | 3 |
Oben wird nur eine Dimension angezeigt, aber dieselbe Aggregation und Speicherung findet für alle Dimensionen statt, die eine Metrik unterstützt.
- Sammeln von Werten in einem 1-Minuten-Aggregationswert gemäß dieser Dimension. Speichern dieser Werte.
- Zusammenfassen der Dimension in einem aggregierten 1-Minuten-Summenwert (SUM). Speichern dieser Werte.
Führen wir für „HTTP-Fehler“ eine weitere Dimension namens „Netzwerkadapter“ ein. Angenommen, pro Server liegt eine unterschiedliche Anzahl von Adaptern vor.
- Server A umfasst 1 Adapter
- Server B umfasst 2 Adapter
- Server C umfasst 3 Adapter
Daten für die folgenden Transaktionen werden separat erfasst. Sie werden markiert mit:
- Einer Uhrzeit
- Einem Wert
- Dem Server, von dem die Transaktion stammt
- Dem Adapter, von dem die Transaktion stammt
Jeder dieser Streams von unter einer Minute wird anschließend zu einem 1-Minuten-Zeitreihenwert aggregiert und in der Azure Monitor Metrik-Datenbank gespeichert:
- Server A, Adapter 1
- Server B, Adapter 1
- Server B, Adapter 2
- Server C, Adapter 1
- Server C, Adapter 2
- Server C, Adapter 3
Zusätzlich werden außerdem die folgenden zusammengefassten Aggregationen gespeichert:
- Server A, Adapter 1 (Da keine Daten für eine Zusammenfassung vorhanden sind, wird der Wert erneut gespeichert.)
- Server B, Adapter 1+2
- Server C, Adapter 1+2+3
- ALLE Server, ALLE Adapter
Dies zeigt, dass Metriken mit einer großen Anzahl von Dimensionen eine größere Anzahl von Aggregationen aufweisen. Sie müssen nicht unbedingt alle Permutationen kennen, sondern den Gedankengang verstehen. Das System strebt an, sowohl über die Einzeldaten als auch über die aggregierten Daten zu verfügen, um schnell beliebige Diagramme abrufen zu können. Das System wählt je nachdem, was Sie anzeigen möchten, entweder die gespeicherten Aggregationen mit der höchsten Relevanz oder die zugrunde liegenden Rohdaten aus.
Aggregation ohne Dimensionen
Da diese Metrik die Dimension Server aufweist, können Sie die zugrundeliegenden Daten für Server A, B und C oben per Teilung und Filterung abrufen, wie weiter oben in diesem Artikel erläutert. Wenn die Metrik keine Dimension Server aufweisen würde, können Sie als Kunde lediglich auf die aggregierten 1-Minuten-Summenwerte zugreifen, die im Diagramm in Schwarz angezeigt werden. Dies sind die Werte 3, 6, 6, 9 usw. Das System würde außerdem keine Teilungswerte aggregieren, diese nicht im Metrik-Explorer verwenden oder sie über die Metrik-REST-API senden.
Anzeigen von Zeitgranularitäten von mehr als 1 Minute
Wenn Sie eine Metrik mit einer größeren Granularität abfragen, verwendet das System die aggregierten 1-Minuten-Summenwerte, um die Summen für die größeren Zeitgranularitäten zu berechnen. Nachstehend zeigen die gepunkteten Linien die Summierungsmethode für die 2-Minuten- und 5-Minuten-Zeitgranularität. Zur besseren Übersichtlichkeit wird erneut nur der SUM-Aggregationstyp gezeigt.
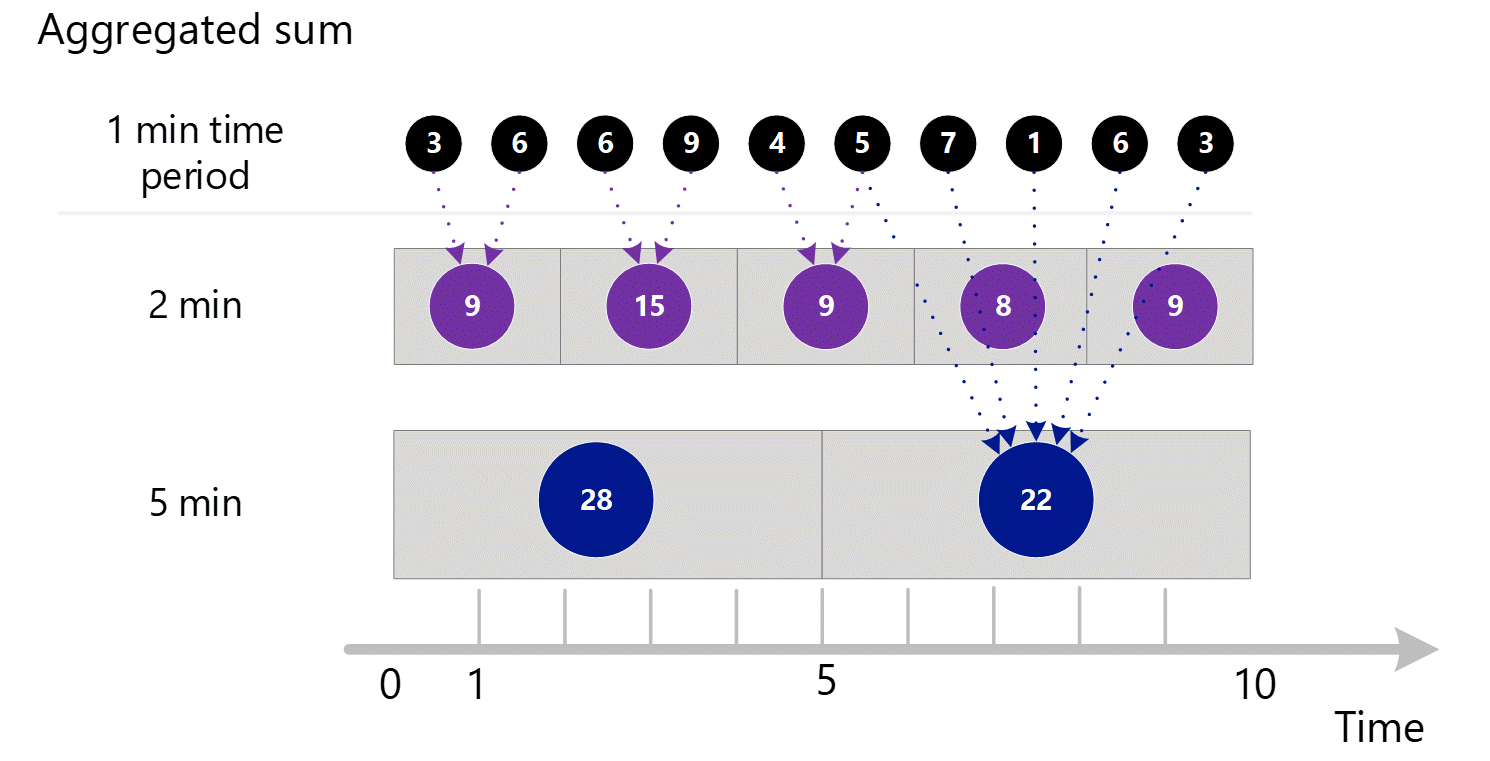
Für die 2-Minuten-Zeitgranularität:
| Zeitraum | Summen |
|---|---|
| Minute 1 und 2 | (3 + 6) = 9 |
| Minute 3 und 4 | (6 + 9) = 15 |
| Minute 4 und 5 | (4 + 5) = 9 |
| Minute 6 und 7 | (7 + 1) = 8 |
| Minute 8 und 9 | (6 + 3) = 9 |
Für die 5-Minuten-Zeitgranularität:
| Zeitraum | Summen |
|---|---|
| Minute 1 bis 5 | 3 + 6 + 6 + 9 + 4 = 28 |
| Minute 6 bis 10 | 5 + 7 + 1 + 6 + 3 = 22 |
Das System verwendet die gespeicherten Aggregationsdaten, die die beste Leistung liefern.
Nachstehend sehen Sie ein größeres Diagramm für den obigen 1-Minuten-Aggregationsprozess, wobei einige der Pfeile zur besseren Lesbarkeit weggelassen wurden.
Komplexeres Beispiel
Es folgt ein umfangreicheres Beispiel mit Werten für eine fiktive Metrik namens „HTTP-Antwortzeit in Millisekunden“. Hier werden weitere Komplexitätsebenen eingeführt.
- Es werden Aggregationen für Summe, Anzahl, Mindest- und Höchstwert sowie die Berechnung des Durchschnitts gezeigt.
- Wir zeigen NULL-Werte und deren Auswirkung auf die Berechnungen an.
Betrachten Sie das folgende Beispiel. Die Rechtecke und Pfeile zeigen Beispiele dafür, wie Werte aggregiert und berechnet werden.
Derselbe 1-Minuten-Prozess zur Vorabaggregation wie im vorherigen Abschnitt wird für Summen, Anzahl, Mindest- und Höchstwert verwendet. Der Durchschnittswert wird jedoch NICHT vorab aggregiert. Er wird anhand der aggregierten Daten neu berechnet, um Berechnungsfehler zu vermeiden.

Betrachten Sie Minute 6 für die 1-Minuten-Aggregation, wie oben hervorgehoben. An diesem Punkt ging Server B offline und hat keine Daten mehr gemeldet, möglicherweise aufgrund eines Neustarts.
Ab Minute 6 lauten die berechneten 1-Minuten-Aggregationstypen wie folgt:
| Aggregationstyp | Wert | Hinweise |
|---|---|---|
| SUM | 53 + 20 = 73 | |
| Anzahl | 2 | Zeigt die Auswirkung von NULL-Werten. Der Werte würde 3 lauten, wenn der Server online gewesen wäre. |
| Minimum | 20 | |
| Maximum | 53 | |
| Average | 73 / 2 | Dies ist immer die Summe geteilt durch die Anzahl. Dieser Wert wird nie gespeichert und für jede Zeitgranularität unter Verwendung der aggregierten Werte für diese Granularität neu berechnet. Beachten Sie die Neuberechnung für die 5-Minuten- und 10-Minuten-Zeitgranularitäten, wie oben hervorgehoben. |
Die rote Textfarbe kennzeichnet Werte, die als außerhalb des Normalbereichs betrachtet werden können, und zeigt, wie diese sich mit zunehmender Zeitgranularität ausbreiten (oder nicht). Beachten Sie, dass die Werte Min und Max auf zugrundeliegende Anomalien hinweisen, während diese Information bei den Werten Avg und Sum mit zunehmender Zeitgranularität verloren geht.
Sie können auch sehen, dass die NULL-Werte eine bessere Berechnung des Durchschnittswerts liefern als dies bei Verwendung von Nullwerten der Fall wäre.
Hinweis
Wenngleich dies in diesem Beispiel nicht zutrifft, stimmen Count und Sum überein, wenn eine Metrik immer mit dem Wert 1 erfasst wird. Dies ist gewöhnlich der Fall, wenn eine Metrik das Auftreten eines Transaktionsereignisses verfolgt – beispielsweise die Anzahl von HTTP-Fehlern, wie in einem vorherigen Beispiel in diesem Artikel.