Verwalten von Dateispeicherplatz für Datenbanken in Azure SQL-Datenbank
Gilt für:: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
In diesem Artikel werden verschiedene Arten von Speicherplatz für Datenbanken in Azure SQL-Datenbank sowie die Schritte beschrieben, die ausgeführt werden können, wenn der zugeordnete Speicherplatz explizit verwaltet werden muss.
Übersicht
Bei Azure SQL-Datenbank gibt es Workloadmuster, bei denen die Zuordnung von zugrunde liegenden Datendateien für Datenbanken größer als die Anzahl der verwendeten Datenseiten werden kann. Dieser Fall kann eintreten, wenn der belegte Platz zunimmt und Daten später gelöscht werden. Der Grund dafür ist, dass der zugeordnete Dateispeicherplatz nicht automatisch wieder freigegeben wird, wenn Daten gelöscht werden.
Die Überwachung der Dateispeicherplatzverwendung und die Verkleinerung von Datendateien können in folgenden Szenarien erforderlich sein:
- Ermöglichen von Datenwachstum in einem Pool für elastische Datenbanken, wenn der den Datenbanken zugeordnete Dateispeicherplatz die maximale Poolgröße erreicht
- Ermöglichen der Verringerung der maximalen Größe einer einzelnen Datenbank oder eines Pools für elastische Datenbanken
- Ermöglichen der Änderung einer einzelnen Datenbank oder eines Pools für elastische Datenbanken, um eine andere Dienstebene oder Leistungsstufe mit einer geringeren maximalen Größe zu verwenden
Hinweis
Die Verkleinerungsvorgänge sollten nicht als ein regulärer Wartungsvorgang betrachtet werden. Die Daten- und Protokolldateien, die aufgrund regelmäßiger, wiederkehrender Geschäftsvorgänge zunehmen, erfordern keine Verkleinerungsvorgänge.
Überwachen der Dateispeicherplatzverwendung
Bei den meisten Speicherplatzmetriken, die in den folgenden APIs angezeigt werden, wird lediglich die Größe der verwendeten Datenseiten ermittelt:
- Azure Resource Manager-basierte Metrik-APIs einschließlich PowerShell get-metrics
Bei den folgenden APIs wird jedoch auch die Größe des Speicherplatzes ermittelt, der Datenbanken und Pools für elastische Datenbanken zugeordnet ist:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
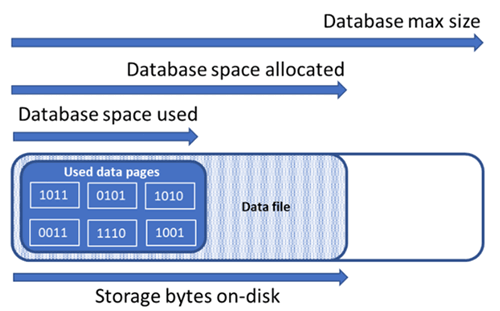
Grundlegendes zu den Arten von Speicherplatz für eine Datenbank
Es wichtig, dass Sie mit den folgenden Speicherplatzmengen vertraut sind, damit Sie den Dateispeicherplatz einer Datenbank verwalten können.
| Datenbankmenge | Definition | Kommentare |
|---|---|---|
| Genutzter Speicherplatz | Der Speicherplatz, der zum Speichern von Datenbankdaten verwendet wird. | In der Regel erhöht (verringert) sich der Platzbedarf bei eingefügten (gelöschten) Daten. In manchen Fällen ändert sich der genutzte Speicherplatz beim Einfügen oder Löschen von Daten nicht, je nach Menge und Muster der an dem Vorgang beteiligten Daten und einer eventuellen Fragmentierung. Beispielsweise wird der genutzte Speicherplatz durch Löschen einer Zeile auf jeder Datenseite nicht zwangsläufig gesenkt. |
| Zugeordneter Datenspeicherplatz | Die Menge an formatiertem Dateispeicherplatz zum Speichern von Daten. | Die Menge des zugeordneten Speicherplatzes wächst automatisch an, wird aber nach dem Löschen nicht kleiner. Dieses Verhalten stellt sicher, dass Daten später schneller eingefügt werden, da der Platz nicht neu formatiert werden muss. |
| Zugeordneter Datenspeicherplatz (ungenutzt) | Die Differenz zwischen der Menge des zugeordneten Datenspeicherplatzes und des genutzten Datenspeicherplatzes. | Diese Menge ist die maximale Menge des freien Speicherplatzes, die freigegeben werden kann, indem Datendateien von Datenbanken verkleinert werden. |
| Maximale Datengröße | Die maximale Speicherplatzmenge, die zum Speichern von Datenbankdaten verwendet werden kann. | Die Menge des zugeordneten Datenspeicherplatzes kann die maximale Datengröße nicht überschreiten. |
Das folgende Diagramm veranschaulicht die Beziehung zwischen den verschiedenen Arten von Speicherplatz für eine Datenbank.
Abfragen eines Singletons nach Dateispeicherplatzinformationen
Verwenden Sie die folgende Abfrage auf sys.database_files, um die Menge des zugewiesenen und des ungenutzten Speicherplatzes in der Datenbankdatei zu ermitteln. Als Einheit für das Abfrageergebnis wird MB verwendet.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Grundlegendes zu den Arten von Speicherplatz für einen Pool für elastische Datenbanken
Es wichtig, dass Sie mit den folgenden Speicherplatzmengen vertraut sind, damit Sie den Dateispeicherplatz eines Pools für elastische Datenbanken verwalten können.
| Menge des Pools für elastische Datenbanken | Definition | Kommentare |
|---|---|---|
| Genutzter Speicherplatz | Die Summierung des Datenspeicherplatzes, der von allen Datenbanken im Pool für elastische Datenbanken verwendet wird. | |
| Zugeordneter Datenspeicherplatz | Die Summierung des Datenspeicherplatzes, der von allen Datenbanken im Pool für elastische Datenbanken zugeordnet wird. | |
| Zugeordneter Datenspeicherplatz (ungenutzt) | Die Differenz zwischen der Menge an zugeordnetem Datenspeicherplatz und dem Datenspeicherplatz, der von allen Datenbanken im Pool für elastische Datenbanken verwendet wird. | Diese Menge gibt die maximale Menge von Speicherplatz an, der für den Pool für elastische Datenbanken zugeordnet wird und freigegeben werden kann, indem die Datenbank-Datendateien verkleinert werden. |
| Maximale Datengröße | Die maximale Menge an Datenspeicherplatz, der vom Pool für elastische Datenbanken für alle seine Datenbanken verwendet werden kann. | Der zugeordnete Speicherplatz des Pools für elastische Datenbanken darf die maximale Größe des Pools nicht überschreiten. In diesem Fall kann zugeordneter Speicherplatz, der nicht genutzt wird, freigegeben werden, indem Datenbank-Datendateien verkleinert werden. |
Hinweis
Die Fehlermeldung „Der Speichergrenzwert des Pools für elastische Datenbanken wurde erreicht“ ist ein Hinweis darauf, dass den Datenbankobjekten zwar genügend Speicherplatz zur Einhaltung des Speicherplatzlimits für Pools für elastische Datenbanken zugeteilt wurde, aber die Zuteilung ggf. ungenutzten Datenspeicherplatz aufweist. Erwägen Sie, das Speicherplatzlimit des Pools für elastische Datenbanken zu erhöhen. Eine alternative kurzfristige Lösung besteht darin, Speicherplatz für Daten freizugeben, indem Sie die Beispiele im Thema Freigeben von ungenutztem zugewiesenem Speicherplatz verwenden. Sie sollten sich auch der möglichen negativen Auswirkungen auf die Leistung bewusst sein, die das Verkleinern von Datenbankdateien hat, siehe das Thema Indexpflege nach dem Verkleinern.
Abfragen von Speicherplatzinformationen für einen Pools für elastische Datenbanken
Die folgenden Abfragen können verwendet werden, um die Speicherplatzmengen für einen Pool für elastische Datenbanken zu ermitteln.
Pool für elastische Datenbanken – ungenutzter Speicherplatz
Ändern Sie die folgende Abfrage, um den belegten Speicherplatz eines Pools für elastische Datenbanken zurückzugeben. Als Einheit für das Abfrageergebnis wird MB verwendet.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Zugeordneter Datenspeicherplatz für Pool für elastische Datenbanken und ungenutzter zugeordneter Speicherplatz
Ändern Sie die folgenden Beispiele, um eine Tabelle zurückzugeben, in der der zugeordnete Speicherplatz und der ungenutzte zugeordnete Speicherplatz für jede Datenbank eines Pools für elastische Datenbanken aufgeführt ist. Die Datenbanken in der Tabelle werden absteigend sortiert – von der größten Menge an ungenutztem zugeordnetem Speicherplatz zur geringsten Menge an ungenutztem zugeordnetem Speicherplatz. Als Einheit für das Abfrageergebnis wird MB verwendet.
Die Abfrageergebnisse zum Bestimmen des für jede Datenbank im Pool zugeordneten Speicherplatzes können addiert werden, um den gesamten Speicherplatz zu ermitteln, der für den Pool für elastische Datenbanken zugeordnet ist. Der zugewiesene Speicherplatz des Pools für elastische Datenbanken darf die maximale Größe des Pools nicht überschreiten.
Wichtig
Das PowerShell Azure Resource Manager-Modul wird von Azure SQL-Datenbank weiterhin unterstützt, aber alle zukünftigen Entwicklungen erfolgen für das Az.Sql-Modul. Das AzureRM-Modul erhält mindestens bis Dezember 2020 weiterhin Fehlerbehebungen. Die Argumente für die Befehle im Az-Modul und den AzureRm-Modulen sind im Wesentlichen identisch. Weitere Informationen zur Kompatibilität finden Sie in der Einführung in das neue Azure PowerShell Az-Modul.
Für die Installation des PowerShell-Skripts ist das SQL Server PowerShell-Modul erforderlich – Siehe Herunterladen des PowerShell-Moduls.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
Der folgende Screenshot zeigt ein Beispiel für die Ausgabe des Skripts:

Maximale Größe der Daten des Pools für elastische Datenbanken
Ändern Sie die folgende T-SQL-Abfrage, um die zuletzt aufgezeichnete maximale Größe der Daten des Pools für elastische Datenbanken zurückzugeben. Als Einheit für das Abfrageergebnis wird MB verwendet.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Freigeben von ungenutztem zugewiesenem Speicherplatz
Wichtig
Verkleinerungsbefehle können während der Ausführung der Datenbank zu einer Beeinträchtigung der Leistung führen und sollten daher nur zu Zeiten mit geringer Auslastung ausgeführt werden.
Verkleinern von Dateien
Aufgrund einer potenziellen Auswirkung auf die Datenbankleistung verkleinert die Azure SQL-Datenbank die Datendateien nicht automatisch. Kunden können jedoch jederzeit Ihre Dateien per Self-Service verkleinern. Dabei sollte es sich nicht um einen regelmäßig geplanten Vorgang, sondern um ein einmaliges Ereignis als Reaktion auf eine erhebliche Verringerung des Speicherplatzverbrauchs der Datendatei handeln.
Tipp
Es ist nicht empfehlenswert, Datendateien zu verkleinern, wenn die regelmäßige Arbeitslast der Anwendung dazu führt, dass die Dateien wieder auf die gleiche Größe anwachsen.
In Azure SQL Database können Sie zum Verkleinern von Dateien entweder die Befehle DBCC SHRINKDATABASE oder DBCC SHRINKFILE verwenden:
DBCC SHRINKDATABASEverkleinert alle Daten- und Protokolldateien in einer Datenbank mit einem einzigen Befehl. Der Befehl verkleinert eine Datendatei nach der anderen, was bei größeren Datenbanken sehr lange dauern kann. Außerdem wird die Protokolldatei geschrumpft, was in der Regel nicht notwendig ist, da Azure SQL Database Protokolldateien bei Bedarf automatisch schrumpft.- Der
DBCC SHRINKFILE-Befehl unterstützt fortgeschrittenere Szenarien:- Er kann je nach Bedarf einzelne Dateien verkleinern, anstatt alle Dateien in der Datenbank zu verkleinern.
- Jeder
DBCC SHRINKFILE-Befehl kann parallel zu anderenDBCC SHRINKFILE-Befehlen ausgeführt werden, um mehrere Dateien gleichzeitig zu verkleinern und die Gesamtzeit der Verkleinerung zu verkürzen, allerdings auf Kosten eines höheren Ressourcenverbrauchs und einer höheren Wahrscheinlichkeit, dass Benutzerabfragen blockiert werden, wenn sie während der Verkleinerung ausgeführt werden.- Durch gleichzeitiges Verkleinern mehrerer Datendateien können Sie den Verkleinerungsvorgang schneller abschließen. Wenn Sie die gleichzeitige Datendateiverkleinerung verwenden, können Sie ggf. das vorübergehende Blockieren einer Verkleinerungsanforderung durch eine andere beobachten.
- Wenn das Ende der Datei keine Daten enthält, kann die zugewiesene Dateigröße durch Angabe des Arguments
TRUNCATEONLYviel schneller reduziert werden. Das erfordert keine Datenverschiebung innerhalb der Datei.
- Weitere Informationen zu diesen Shrink-Befehlen finden Sie unter DBCC SHRINKDATABASE und DBCC SHRINKFILE.
- Datenbank- und Dateiverkleinerungsvorgänge werden in der Vorschau für Azure SQL-Datenbank Hyperscale unterstützt. Weitere Informationen finden Sie unter Verkleinern für Azure SQL Database Hyperscale.
Die folgenden Beispiele müssen ausgeführt werden, während eine Verbindung mit der Zielbenutzerdatenbank und nicht mit der master-Datenbank besteht.
So verwenden Sie DBCC SHRINKDATABASE, um alle Daten- und Protokolldateien in einer bestimmten Datenbank zu verkleinern:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
In Azure SQL Database kann eine Datenbank eine oder mehrere Datendateien haben, die automatisch erstellt werden, wenn die Daten wachsen. Um das Dateilayout Ihrer Datenbank zu ermitteln, einschließlich der verwendeten und zugewiesenen Größe jeder Datei, fragen Sie die Katalogansicht sys.database_files mit dem folgenden Beispielskript ab:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Mit dem Befehl DBCC SHRINKFILE können Sie z. B. einen Schrumpfvorgang für nur eine Datei durchführen:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Beachten Sie die möglichen negativen Auswirkungen des Verkleinerns von Datenbankdateien auf die Leistung, siehe das Thema Indexpflege nach dem Verkleinern.
Verkleinern der Transaktionsprotokolldatei
Im Gegensatz zu Datendateien verkleinert Azure SQL-Datenbank die Transaktionsprotokolldatei automatisch, um eine übermäßige Speicherplatznutzung zu vermeiden, die zu Fehlern führen kann, weil nicht genügend Speicherplatz verfügbar ist. In der Regel müssen Kunden die Transaktionsprotokolldatei nicht verkleinern.
Wenn das Transaktionsprotokoll in den Dienstebenen Premium und Unternehmenskritisch groß wird, kann es erheblich dazu beitragen, dass der Grenzwert für den maximalen lokalen Speicher erreicht wird. Wenn sich der lokale Speicherverbrauch dem Grenzwert nähert, können Kunden das Transaktionsprotokoll mithilfe des Befehls DBCC SHRINKFILE verkleinern, wie im folgenden Beispiel gezeigt. Dadurch wird lokaler Speicher freigegeben, nachdem der Befehl abgeschlossen wurde, ohne auf den regelmäßigen automatischen Verkleinerungsvorgang zu warten.
Die folgenden Beispiele müssen ausgeführt werden, während eine Verbindung mit der Zielbenutzerdatenbank und nicht mit der master-Datenbank besteht.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Automatisches Verkleinern
Als Alternative zum manuellen Schrumpfen von Datendateien kann das automatische Schrumpfen für eine Datenbank aktiviert werden. Verglichen mit DBCC SHRINKDATABASE und DBCC SHRINKFILE ist das automatische Verkleinern allerdings beim Freigeben von Dateispeicherplatz unter Umständen weniger effizient.
Das automatische Verkleinern ist standardmäßig deaktiviert. Dies ist für die meisten Datenbanken die empfohlene Einstellung. Wenn das automatische Verkleinern aktiviert werden muss, wird empfohlen, das automatische Verkleinern wieder zu deaktivieren, sobald die Ziele der Speicherplatzverwaltung erreicht wurden, anstatt das automatische Verkleinern dauerhaft aktiviert zu lassen. Weitere Informationen finden Sie im Abschnitt unter Überlegungen zu AUTO_SHRINK.
Die automatische Schrumpfung kann beispielsweise in dem speziellen Szenario hilfreich sein, in dem ein elastischer Pool viele Datenbanken enthält, die ein erhebliches Wachstum und eine erhebliche Verringerung des verwendeten Speicherplatzes erfahren, so dass sich der Pool seiner maximalen Größe nähert. Dieses Szenario tritt allerdings nur selten auf.
Um die automatische Verkleinerung zu aktivieren, führen Sie den folgenden Befehl aus, während Sie mit Ihrer Datenbank verbunden sind (nicht mit der master-Datenbank).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Weitere Informationen zu diesem Befehl finden Sie in den Optionen für DATABASE SET.
Indexpflege nach dem Schrumpfen
Nachdem ein Verkleinerungsvorgang für Datendateien abgeschlossen wurde, können Indizes fragmentiert werden. Dies verringert die Wirksamkeit der Leistungsoptimierung für bestimmte Arbeitslasten, z. B. für Abfragen mit großen Suchvorgängen. Wenn nach dem Abschluss des Verkleinerungsvorgang eine Leistungsbeeinträchtigung auftritt, sollten Sie eine Indexwartung in Betracht ziehen, um die Indizes neu zu erstellen. Denken Sie daran, dass der Neuaufbau von Indizes freien Speicherplatz in der Datenbank erfordert und daher zu einer Vergrößerung des zugewiesenen Speicherplatzes führen kann, was dem Effekt der Verkleinerung entgegenwirkt.
Weitere Informationen zur Indexpflege finden Sie unter Optimierung der Indexpflege zur Verbesserung der Abfrageleistung und Reduzierung des Ressourcenverbrauchs.
Große Datenbanken schrumpfen
Wenn der Datenbank zugewiesene Speicherplatz Hunderte von Gigabyte oder mehr beträgt, kann die Verkleinerung eine beträchtliche Zeit in Anspruch nehmen, die oft in Stunden oder bei Datenbanken mit mehreren Terabyte in Tagen gemessen wird. Es gibt Prozessoptimierungen und Best Practices, mit denen Sie diesen Prozess effizienter gestalten und die Anwendungs-Workloads weniger beeinträchtigen können.
Erfassen der Grundlinie der Raumnutzung
Bevor Sie mit der Verkleinerung beginnen, erfassen Sie den aktuell belegten und zugewiesenen Speicherplatz in jeder Datenbankdatei, indem Sie die folgende Abfrage zur Speicherplatznutzung ausführen:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Nach Abschluss der Schrumpfung können Sie diese Abfrage erneut ausführen und das Ergebnis mit der ursprünglichen Basislinie vergleichen.
Abschneiden von Datendateien
Es wird empfohlen, zunächst für jede Datendatei eine Schrumpfung mit dem Parameter TRUNCATEONLY durchzuführen. Auf diese Weise wird zugeteilter, aber ungenutzter Speicherplatz am Ende der Datei schnell und ohne Datenverschiebung entfernt. Der folgende Beispielbefehl schneidet die Datendatei mit der file_id 4 ab:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Sobald dieser Befehl für jede Datendatei ausgeführt wurde, können Sie die Abfrage zur Speicherplatznutzung erneut ausführen, um die Verringerung des zugewiesenen Speicherplatzes zu sehen, falls es eine gibt. Sie können den zugewiesenen Speicherplatz für die Datenbank auch im Azure-Portal einsehen.
Bewertung der Indexseitendichte
Wenn das Kürzen der Datendateien nicht zu einer ausreichenden Verringerung des zugewiesenen Speicherplatzes geführt hat, müssen Sie die Datendateien verkleinern. Als optionaler, aber empfohlener Schritt sollten Sie jedoch zunächst die durchschnittliche Seitendichte für die Indizes in der Datenbank ermitteln. Bei der gleichen Datenmenge ist das Schrumpfen schneller abgeschlossen, wenn die Seitendichte hoch ist, da weniger Seiten verschoben werden müssen. Wenn die Seitendichte für einige Indizes niedrig ist, sollten Sie eine Wartung dieser Indizes in Betracht ziehen, um die Seitendichte zu erhöhen, bevor Sie die Datendateien verkleinern. Auf diese Weise lässt sich auch der zugewiesene Speicherplatz stärker reduzieren.
Um die Seitendichte für alle Indizes in der Datenbank zu ermitteln, verwenden Sie die folgende Abfrage. Die Seitendichte wird in der Spalte avg_page_space_used_in_percent angegeben.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Wenn es Indizes mit einer hohen Seitenzahl und einer Seitendichte von weniger als 60-70 % gibt, sollten Sie in Erwägung ziehen, diese Indizes neu zu erstellen oder zu reorganisieren, bevor Sie die Datendateien verkleinern.
Hinweis
Bei größeren Datenbanken kann die Abfrage zur Bestimmung der Seitendichte sehr lange dauern (Stunden). Darüber hinaus erfordert der Neuaufbau oder die Reorganisation großer Indizes ebenfalls einen erheblichen Zeit- und Ressourcenaufwand. Es besteht ein Kompromiss zwischen dem zusätzlichen Zeitaufwand für die Erhöhung der Seitendichte einerseits und der Verringerung der Schrumpfdauer und der Erzielung einer höheren Platzeinsparung andererseits.
Wenn es mehrere Indizes mit geringer Seitendichte gibt, können Sie diese möglicherweise parallel in mehreren Datenbanksitzungen neu aufbauen, um den Prozess zu beschleunigen. Achten Sie jedoch darauf, dass Sie dabei nicht an die Grenzen der Datenbankressourcen stoßen, und lassen Sie genügend Spielraum für eventuell laufende Anwendungsworkloads. Überwachen Sie den Ressourcenverbrauch (CPU, Data IO, Log IO) im Azure-Portal oder mithilfe der Ansicht sys.dm_db_resource_stats und starten Sie zusätzliche parallele Rebuilds nur, wenn die Ressourcenauslastung in jeder dieser Dimensionen deutlich unter 100 % liegt. Wenn die CPU-, Daten-IO- oder Protokoll-IO-Auslastung bei 100 % liegt, können Sie die Datenbank skalieren, um mehr CPU-Kerne zu haben und den IO-Durchsatz zu erhöhen. Dies kann zusätzliche parallele Rebuilds ermöglichen, um den Prozess schneller abzuschließen.
Beispielbefehl zum Neuerstellen des Index
Es folgt ein Beispielbefehl zum Neuerstellen eines Index und zum Erhöhen seiner Seitendichte mithilfe der ALTER INDEX-Anweisung:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Dieser Befehl initiiert einen Online-Index-Neuaufbau mit Wiederaufnahmefunktion. Dadurch können gleichzeitige Arbeitslasten die Tabelle weiter verwenden, während der Neuaufbau läuft, und Sie können den Neuaufbau wieder aufnehmen, wenn er aus irgendeinem Grund unterbrochen wird. Diese Art des Rebuilds ist jedoch langsamer als ein Offline-Rebuild, bei dem der Zugriff auf die Tabelle blockiert wird. Wenn keine anderen Workloads während des Wiederaufbaus auf die Tabelle zugreifen müssen, setzen Sie die Optionen ONLINE und RESUMABLE auf OFF und entfernen Sie die Klausel WAIT_AT_LOW_PRIORITY.
Weitere Informationen zur Indexpflege finden Sie unter Optimierung der Indexpflege zur Verbesserung der Abfrageleistung und Reduzierung des Ressourcenverbrauchs.
Mehrere Datendateien schrumpfen
Wie bereits erwähnt, ist das Schrumpfen mit Datenverschiebung ein langwieriger Prozess. Wenn die Datenbank mehrere Datendateien enthält, können Sie den Vorgang beschleunigen, indem Sie mehrere Datendateien parallel verkleinern. Dazu öffnen Sie mehrere Datenbanksitzungen und verwenden DBCC SHRINKFILE in jeder Sitzung mit einem anderen file_id-Wert. Ähnlich wie bei der Wiederherstellung von Indizes sollten Sie vor jedem neuen parallelen Verkleinerungsbefehl sicherstellen, dass Sie über genügend Ressourcen verfügen (CPU, Data IO, Log IO).
Der folgende Beispielbefehl verkleinert die Datendatei mit der file_id 4 und versucht, die ihr zugeteilte Größe durch Verschieben von Seiten innerhalb der Datei auf 52.000 MB zu reduzieren:
DBCC SHRINKFILE (4, 52000);
Wenn Sie den zugewiesenen Speicherplatz für die Datei so weit wie möglich reduzieren wollen, führen Sie die Anweisung ohne Angabe der Zielgröße aus:
DBCC SHRINKFILE (4);
Wenn ein Workload gleichzeitig mit Shrink läuft, kann er beginnen, den von Shrink freigegebenen Speicherplatz zu verwenden, bevor Shrink abgeschlossen ist und die Datei abgeschnitten wird. In diesem Fall ist es nicht möglich, den zugewiesenen Speicherplatz auf das angegebene Ziel zu verkleinern.
Sie können dies abmildern, indem Sie jede Datei in kleineren Schritten verkleinern. Das bedeutet, dass Sie im Befehl DBCC SHRINKFILE ein Ziel festlegen, das etwas kleiner ist als der aktuell zugewiesene Speicherplatz für die Datei, wie in den Ergebnissen der Basisabfrage zur Speichernutzung zu sehen ist. Wenn der zugewiesene Speicherplatz für die Datei mit der Dateinummer 4 beispielsweise 200.000 MB beträgt und Sie auf 100.000 MB verkleinern möchten, können Sie das Ziel zunächst auf 170.000 MB setzen:
DBCC SHRINKFILE (4, 170000);
Nach Beendigung dieses Befehls wird die Datei abgeschnitten und ihre Größe auf 170.000 MB reduziert. Sie können dann diesen Befehl wiederholen, indem Sie das Ziel zuerst auf 140.000 MB, dann auf 110.000 MB usw. setzen, bis die Datei auf die gewünschte Größe geschrumpft ist. Wenn der Befehl ausgeführt wird, die Datei aber nicht abgeschnitten wird, verwenden Sie kleinere Schritte, z. B. 15.000 MB statt 30.000 MB.
Um den Fortschritt der Verkleinerung für alle gleichzeitig laufenden Verkleinerungssitzungen zu überwachen, können Sie die folgende Abfrage verwenden:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Hinweis
Der Schrumpfungsprozess kann nicht linear verlaufen, und der Wert in der Spalte percent_complete kann über lange Zeiträume praktisch unverändert bleiben, obwohl die Schrumpfung noch im Gange ist.
Sobald die Verkleinerung für alle Datendateien abgeschlossen ist, führen Sie erneut die Speicherplatzverwendungsabfrage (oder prüfen Sie im Azure-Portal), um die daraus resultierende Verringerung der zugewiesenen Speichergröße zu ermitteln. Wenn immer noch eine große Differenz zwischen dem belegten und dem zugeteilten Speicherplatz besteht, können Sie die Indizes wie oben beschrieben neu erstellen. Dadurch kann sich der zugewiesene Speicherplatz vorübergehend weiter erhöhen, aber ein erneutes Verkleinern der Datendateien nach dem Wiederaufbau der Indizes sollte zu einer stärkeren Reduzierung des zugewiesenen Speicherplatzes führen.
Vorübergehende Fehler beim Schrumpfen
Gelegentlich kann ein Befehl zum Verkleinern mit verschiedenen Fehlern wie Timeouts und Deadlocks fehlschlagen. Im Allgemeinen sind diese Fehler vorübergehend und treten nicht wieder auf, wenn derselbe Befehl wiederholt wird. Wenn shrink mit einem Fehler fehlschlägt, bleibt der bisherige Fortschritt beim Verschieben der Datenseiten erhalten, und derselbe shrink-Befehl kann erneut ausgeführt werden, um die Datei weiter zu verkleinern.
Das folgende Beispielskript zeigt, wie Sie shrink in einer Wiederholungsschleife ausführen können, um bei einem Timeout-Fehler oder einem Deadlock-Fehler automatisch eine konfigurierbare Anzahl von Wiederholungen durchzuführen. Dieser Ansatz der Wiederholung ist auf viele andere Fehler anwendbar, die beim Schrumpfen auftreten können.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Zusätzlich zu Timeouts und Deadlocks können beim Schrumpfen Fehler aufgrund bestimmter bekannter Probleme auftreten.
Die zurückgegebenen Fehler und Schritte zur Behebung sind wie folgt:
- Fehlernummer: 49503, Fehlermeldung: %.*ls: Die Seite %d:%d konnte nicht verschoben werden, da es sich um eine Seite handelt, die nicht in einer Zeile des persistenten Versionsspeichers liegt. Grund für das Zurückhalten der Seite: %ls. Zeitstempel der Seitenüberbrückung: %I64d.
Dieser Fehler tritt auf, wenn es zeitintensiv aktive Transaktionen gibt, die Zeilenversionen im persistenten Versionsspeicher (PVS) erzeugt haben. Die Seiten, die diese Zeilenversionen enthalten, können von shrink nicht verschoben werden, so dass es nicht vorankommt und mit diesem Fehler fehlschlägt.
Um dies abzumildern, müssen Sie warten, bis diese zeitintensiv Transaktionen abgeschlossen sind. Alternativ können Sie diese zeitintensiv Transaktionen identifizieren und beenden, aber dies kann sich auf Ihre Anwendung auswirken, wenn sie Transaktionsausfälle nicht ordnungsgemäß behandelt. Eine Möglichkeit, zeitintensiv Transaktionen zu finden, besteht darin, die folgende Abfrage in der Datenbank auszuführen, in der Sie den Befehl shrink ausgeführt haben:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
Sie können eine Transaktion beenden, indem Sie den Befehl KILL verwenden und den zugehörigen Wert session_id aus dem Abfrageergebnis angeben:
KILL 4242; -- replace 4242 with the session_id value from query results
Achtung
Der Abbruch einer Transaktion kann sich negativ auf die Arbeitslast auswirken.
Wenn zeitintensiv Transaktionen beendet wurden oder abgeschlossen sind, bereinigt eine interne Hintergrundaufgabe nach einiger Zeit nicht mehr benötigte Zeilenversionen. Sie können die PVS-Größe überwachen, um den Bereinigungsfortschritt zu messen, indem Sie die folgende Abfrage verwenden. Führen Sie die Abfrage in der Datenbank aus, in der Sie den Befehl shrink ausgeführt haben:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Sobald die in der Spalte persistent_version_store_size_gb gemeldete PVS-Größe im Vergleich zu ihrer ursprünglichen Größe erheblich reduziert ist, sollte ein erneuter Shrink-Vorgang erfolgreich sein.
- Fehlernummer: 5223, Fehlermeldung: %.*ls: Die leere Seite %d:%d konnte nicht freigegeben werden.
Dieser Fehler kann auftreten, wenn es laufende Indexpflegeoperationen wie ALTER INDEX gibt. Wiederholen Sie den Befehl zum Verkleinern, nachdem diese Vorgänge abgeschlossen sind.
Wenn dieser Fehler weiterhin besteht, muss der zugehörige Index möglicherweise neu erstellt werden. Um den neu zu erstellenden Index zu finden, führen Sie die folgende Abfrage in derselben Datenbank aus, in der Sie den Befehl shrink ausgeführt haben:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Ersetzen Sie vor dem Ausführen dieser Abfrage die Platzhalter <file_id> und <page_id> durch die tatsächlichen Werte aus der Fehlermeldung, die Sie erhalten haben. Wenn zum Beispiel die Meldung Leere Seite 1:62669 konnte nicht freigegeben werden lautet, dann ist <file_id>1 und <page_id>62669.
Bauen Sie den von der Abfrage identifizierten Index neu auf und wiederholen Sie den Shrink-Befehl.
- Fehlernummer: 5201, Fehlermeldung: DBCC SHRINKDATABASE: Die Datei-ID %d der Datenbank-ID %d wurde übersprungen, weil die Datei nicht genügend freien Speicherplatz hat, um ihn wiederzugewinnen.
Dieser Fehler bedeutet, dass die Datendatei nicht weiter verkleinert werden kann. Sie können mit der nächsten Datei fortfahren.
Zugehöriger Inhalt
Informationen zur maximalen Datenbankgröße finden Sie unter:
- Limits des vCore-basierten Kaufmodells für eine Einzeldatenbank in Azure SQL-Datenbank
- Ressourcenlimits für Einzeldatenbanken, die DTU-basierte Kaufmodell verwenden
- Limits des vCore-basierten Kaufmodells für Pools für elastische Datenbanken in Azure SQL-Datenbank
- Grenzwerte für Ressourcen für Pools für elastische Datenbanken, die das DTU-basierte Kaufmodell verwenden
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für