Tutorial: Implementieren einer geografisch verteilten Datenbank (Azure SQL-Datenbank)
Gilt für:: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Konfigurieren Sie eine Datenbank in Azure SQL-Datenbank und eine Clientanwendung für das Failover zu einer Remoteregion, und testen Sie dann Ihren Failoverplan. Folgendes wird vermittelt:
- Erstellen einer Failovergruppe
- Ausführen einer Java-Anwendung zum Abfragen einer Datenbank in SQL-Datenbank
- Testfailover
Wenn Sie keine Azure-Subscription besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Hinweis
In diesem Artikel wird das Azure Az PowerShell-Modul verwendet. Dieses PowerShell-Modul wird für die Interaktion mit Azure empfohlen. Informationen zu den ersten Schritten mit dem Az PowerShell-Modul finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Wichtig
Das PowerShell Azure Resource Manager-Modul wird von Azure SQL-Datenbank weiterhin unterstützt, aber alle zukünftigen Entwicklungen erfolgen für das Az.Sql-Modul. Informationen zu diesen Cmdlets finden Sie unter AzureRM.Sql. Die Argumente für die Befehle im Az-Modul und den AzureRm-Modulen sind im Wesentlichen identisch.
Für dieses Tutorial muss Folgendes installiert sein:
Eine Einzeldatenbank in einer Azure SQL-Datenbank. Verwenden Sie für die Erstellung Folgendes:
Hinweis
In diesem Tutorial wird die Beispieldatenbank AdventureWorksLT verwendet.
Wichtig
Richten Sie auf dem Computer, auf dem Sie die Schritte des Tutorials ausführen, Firewallregeln für die öffentliche IP-Adresse des Computers ein. Firewallregeln auf Datenbankebene werden automatisch auf den sekundären Server repliziert.
Weitere Informationen finden Sie unter Erstellen einer Firewallregel auf Datenbankebene. Eine Beschreibung, wie Sie die IP-Adresse für die Firewallregel auf Serverebene für Ihren Computer ermitteln, finden Sie unter Erstellen einer Firewall auf Serverebene.
Erstellen einer Failovergruppe
Erstellen Sie mit Azure PowerShell Failovergruppen zwischen einem vorhandenen Server und einem neuen Server in einer anderen Region. Fügen Sie dann der Failovergruppe die Beispieldatenbank hinzu.
Wichtig
Für dieses Beispiel ist mindestens Azure PowerShell Az 1.0 erforderlich. Führen Sie Get-Module -ListAvailable Az aus, um die installierten Versionen zu ermitteln.
Wenn Sie die Installation ausführen müssen, finden Sie unter Installieren des Azure PowerShell-Moduls Informationen dazu.
Führen Sie zum Anmelden bei Azure Connect-AzAccount aus.
Führen Sie das folgende Skript aus, um eine Failovergruppe zu erstellen:
$admin = "<adminName>"
$password = "<password>"
$resourceGroup = "<resourceGroupName>"
$location = "<resourceGroupLocation>"
$server = "<serverName>"
$database = "<databaseName>"
$drLocation = "<disasterRecoveryLocation>"
$drServer = "<disasterRecoveryServerName>"
$failoverGroup = "<globallyUniqueFailoverGroupName>"
# create a backup server in the failover region
New-AzSqlServer -ResourceGroupName $resourceGroup -ServerName $drServer `
-Location $drLocation -SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential `
-ArgumentList $admin, $(ConvertTo-SecureString -String $password -AsPlainText -Force))
# create a failover group between the servers
New-AzSqlDatabaseFailoverGroup –ResourceGroupName $resourceGroup -ServerName $server `
-PartnerServerName $drServer –FailoverGroupName $failoverGroup –FailoverPolicy Automatic -GracePeriodWithDataLossHours 2
# add the database to the failover group
Get-AzSqlDatabase -ResourceGroupName $resourceGroup -ServerName $server -DatabaseName $database | `
Add-AzSqlDatabaseToFailoverGroup -ResourceGroupName $resourceGroup -ServerName $server -FailoverGroupName $failoverGroup
Einstellungen für die Georeplikation können auch im Azure-Portal geändert werden. Wählen Sie dazu Ihre Datenbank und dann Einstellungen>Georeplikation aus.
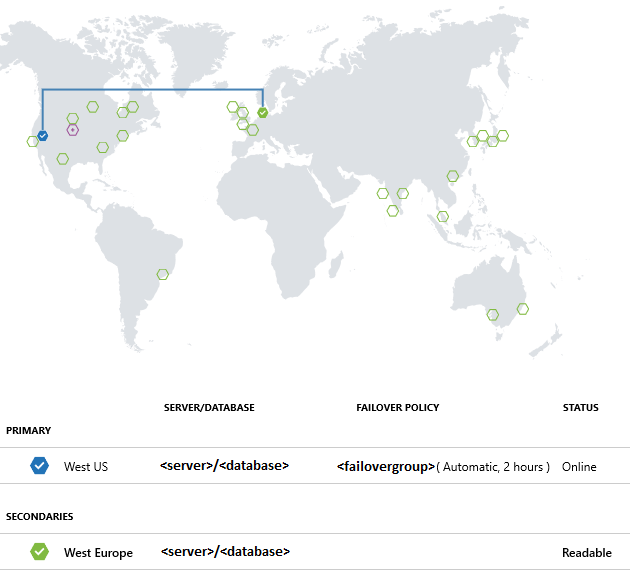
Ausführen des Beispielprojekts
Erstellen Sie in der Konsole mit dem folgenden Befehl ein Maven-Projekt:
mvn archetype:generate "-DgroupId=com.sqldbsamples" "-DartifactId=SqlDbSample" "-DarchetypeArtifactId=maven-archetype-quickstart" "-Dversion=1.0.0"Geben Sie Y ein, und drücken Sie die EINGABETASTE.
Wechseln Sie zum Verzeichnis des neuen Projekts.
cd SqlDbSampleÖffnen Sie die Datei pom.xml im Projektordner in Ihrem bevorzugten Editor.
Fügen Sie SQL Server den Microsoft JDBC-Treiber als Abhängigkeit hinzu. Verwenden Sie dazu den folgenden Abschnitt
dependency. Die Abhängigkeit muss innerhalb des größeren Abschnittsdependencieseingefügt werden.<dependency> <groupId>com.microsoft.sqlserver</groupId> <artifactId>mssql-jdbc</artifactId> <version>6.1.0.jre8</version> </dependency>Geben Sie die Java-Version an, indem Sie den Abschnitt
propertieshinter dem Abschnittdependencieshinzufügen:<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties>Fügen Sie Unterstützung von Manifestdateien hinzu, indem Sie den Abschnitt
buildhinter dem Abschnittpropertieshinzufügen:<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>3.0.0</version> <configuration> <archive> <manifest> <mainClass>com.sqldbsamples.App</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build>Speichern und schließen Sie die Datei pom.xml.
Öffnen Sie die Datei App.java in „..\SqlDbSample\src\main\java\com\sqldbsamples“, und ersetzen Sie ihren Inhalt durch folgenden Code:
package com.sqldbsamples; import java.sql.Connection; import java.sql.Statement; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.Timestamp; import java.sql.DriverManager; import java.util.Date; import java.util.concurrent.TimeUnit; public class App { private static final String FAILOVER_GROUP_NAME = "<your failover group name>"; // add failover group name private static final String DB_NAME = "<your database>"; // add database name private static final String USER = "<your admin>"; // add database user private static final String PASSWORD = "<your password>"; // add database password private static final String READ_WRITE_URL = String.format("jdbc:" + "sqlserver://%s.database.windows.net:1433;database=%s;user=%s;password=%s;encrypt=true;" + "hostNameInCertificate=*.database.windows.net;loginTimeout=30;", FAILOVER_GROUP_NAME, DB_NAME, USER, PASSWORD); private static final String READ_ONLY_URL = String.format("jdbc:" + "sqlserver://%s.secondary.database.windows.net:1433;database=%s;user=%s;password=%s;encrypt=true;" + "hostNameInCertificate=*.database.windows.net;loginTimeout=30;", FAILOVER_GROUP_NAME, DB_NAME, USER, PASSWORD); public static void main(String[] args) { System.out.println("#######################################"); System.out.println("## GEO DISTRIBUTED DATABASE TUTORIAL ##"); System.out.println("#######################################"); System.out.println(""); int highWaterMark = getHighWaterMarkId(); try { for(int i = 1; i < 1000; i++) { // loop will run for about 1 hour System.out.print(i + ": insert on primary " + (insertData((highWaterMark + i)) ? "successful" : "failed")); TimeUnit.SECONDS.sleep(1); System.out.print(", read from secondary " + (selectData((highWaterMark + i)) ? "successful" : "failed") + "\n"); TimeUnit.SECONDS.sleep(3); } } catch(Exception e) { e.printStackTrace(); } } private static boolean insertData(int id) { // Insert data into the product table with a unique product name so we can find the product again String sql = "INSERT INTO SalesLT.Product " + "(Name, ProductNumber, Color, StandardCost, ListPrice, SellStartDate) VALUES (?,?,?,?,?,?);"; try (Connection connection = DriverManager.getConnection(READ_WRITE_URL); PreparedStatement pstmt = connection.prepareStatement(sql)) { pstmt.setString(1, "BrandNewProduct" + id); pstmt.setInt(2, 200989 + id + 10000); pstmt.setString(3, "Blue"); pstmt.setDouble(4, 75.00); pstmt.setDouble(5, 89.99); pstmt.setTimestamp(6, new Timestamp(new Date().getTime())); return (1 == pstmt.executeUpdate()); } catch (Exception e) { return false; } } private static boolean selectData(int id) { // Query the data previously inserted into the primary database from the geo replicated database String sql = "SELECT Name, Color, ListPrice FROM SalesLT.Product WHERE Name = ?"; try (Connection connection = DriverManager.getConnection(READ_ONLY_URL); PreparedStatement pstmt = connection.prepareStatement(sql)) { pstmt.setString(1, "BrandNewProduct" + id); try (ResultSet resultSet = pstmt.executeQuery()) { return resultSet.next(); } } catch (Exception e) { return false; } } private static int getHighWaterMarkId() { // Query the high water mark id stored in the table to be able to make unique inserts String sql = "SELECT MAX(ProductId) FROM SalesLT.Product"; int result = 1; try (Connection connection = DriverManager.getConnection(READ_WRITE_URL); Statement stmt = connection.createStatement(); ResultSet resultSet = stmt.executeQuery(sql)) { if (resultSet.next()) { result = resultSet.getInt(1); } } catch (Exception e) { e.printStackTrace(); } return result; } }Speichern und schließen Sie die Datei App.java.
Führen Sie den folgenden Befehl an der Befehlskonsole aus:
mvn packageStarten Sie die Anwendung. Sie wird ca. 1 Stunde lang ausgeführt, bis sie manuell beendet wird. In dieser Zeit können Sie den Failovertest ausführen.
mvn -q -e exec:java "-Dexec.mainClass=com.sqldbsamples.App"####################################### ## GEO DISTRIBUTED DATABASE TUTORIAL ## ####################################### 1. insert on primary successful, read from secondary successful 2. insert on primary successful, read from secondary successful 3. insert on primary successful, read from secondary successful ...
Testfailover
Führen Sie die folgenden Skripts aus, um ein Failover zu simulieren und die Anwendungsergebnisse zu beobachten. Beachten Sie, wie einige Einfüge- und Auswahlvorgänge während der Datenbankmigration zu Fehlern führen.
Sie können während des Tests mit dem folgenden Befehl die Rolle des Notfallwiederherstellungsservers überprüfen:
(Get-AzSqlDatabaseFailoverGroup -FailoverGroupName $failoverGroup `
-ResourceGroupName $resourceGroup -ServerName $drServer).ReplicationRole
So testen Sie ein Failover:
Starten Sie das manuelle Failover der Failovergruppe:
Switch-AzSqlDatabaseFailoverGroup -ResourceGroupName $resourceGroup ` -ServerName $drServer -FailoverGroupName $failoverGroupStellen Sie die Failovergruppe auf dem primären Server wieder her:
Switch-AzSqlDatabaseFailoverGroup -ResourceGroupName $resourceGroup ` -ServerName $server -FailoverGroupName $failoverGroup
Nächste Schritte
Prüfen Sie die Checkliste für Hochverfügbarkeit und Notfallwiederherstellung.
Verwandte Azure SQL-Datenbank Inhalte: