Mapping Data Flow – Debugmodus
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Übersicht
Mit dem Debugmodus für Azure Data Factory- und Synapse Analytics-Zuordnungsdatenflüsse können Sie die Transformation der Datenform interaktiv beobachten, während Sie Datenflüsse erstellen und debuggen. Die Debugsitzung kann sowohl in Datenfluss-Entwurfssitzungen sowie während der Ausführung der Pipeline zum Debuggen von Datenflüssen verwendet werden. Verwenden Sie zum Aktivieren des Debugging-Modus auf der oberen Leiste der Datenfluss- oder Pipelinecanvas die Schaltfläche Datenflüsse debuggen, wenn Datenflussaktivitäten vorhanden sind.


Nachdem Sie den Schieberegler aktiviert haben, werden Sie aufgefordert, die Integration Runtime-Konfiguration auszuwählen, die Sie verwenden möchten. Wird „AutoResolveIntegrationRuntime“ ausgewählt, wird ein Cluster mit acht allgemeinen Compute-Kernen und einer Standarddauer von 60 Minuten gestartet. Wenn Sie vor dem Timeout Ihrer Sitzung eine längere Leerlaufzeit zulassen möchten, können Sie eine höhere TTL-Einstellung wählen. Weitere Informationen zu Datenfluss-Integration Runtimes finden Sie unter Integration Runtime-Leistung.

Wenn der Debugmodus eingeschaltet ist, erstellen Sie Ihren Datenfluss mit einem aktiven Spark-Cluster. Die Sitzung wird beendet, sobald Sie den Debugmodus deaktivieren. Beachten Sie, dass stündlich Gebühren durch Data Factory anfallen, solange die Debugsitzung aktiviert ist.
In den meisten Fällen ist es eine gute Vorgehensweise, Ihre Datenflüsse im Debugmodus zu erstellen, sodass Sie Ihre Geschäftslogik validieren und Ihre Datentransformationen anzeigen können, bevor Sie Ihre Arbeit veröffentlichen. Verwenden Sie im Bereich „Pipeline“ die Schaltfläche „Debuggen“, um Ihren Datenfluss in einer Pipeline zu testen.
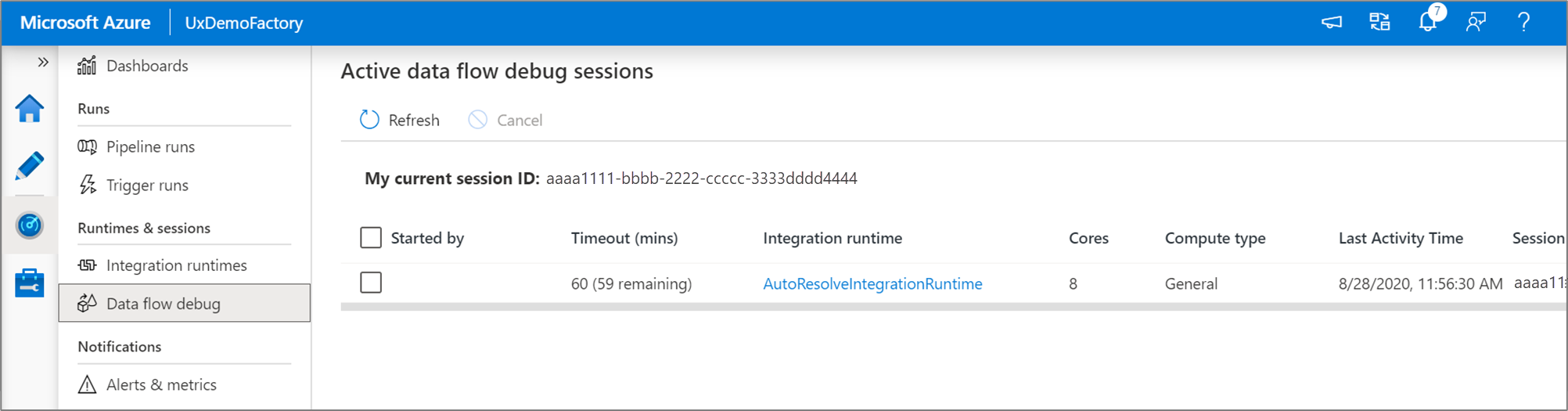
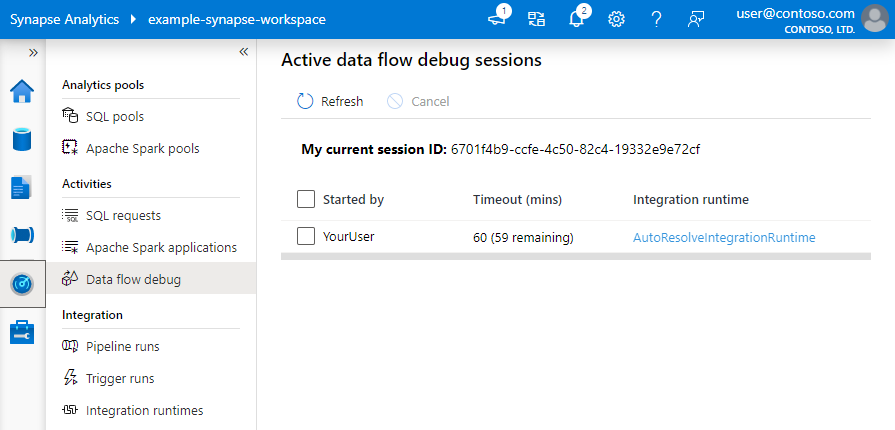
Hinweis
Jede Debugsitzung, die ein Benutzer über die Browserbenutzeroberfläche startet, stellt eine neue Sitzung mit einem eigenen Spark-Cluster dar. Mithilfe der Überwachungsansicht für Debugsitzungen der vorherigen Bilder können Sie Debugsitzungen anzeigen und verwalten. Ihnen wird jede Stunde in Rechnung gestellt, in der die einzelnen Debugsitzungen ausgeführt werden, einschließlich der Gültigkeitsdauer (TTL).
In diesem Videoclip werden Tipps, Tricks und bewährte Methoden für den Debugmodus für Datenflüsse erläutert.
Clusterstatus
Die Clusterstatusanzeige im oberen Bereich der Entwurfsoberfläche wird grün, wenn der Cluster zum Debuggen bereit ist. Wenn Ihr Cluster bereits betriebsbereiten ist, wird die Anzeige nahezu sofort grün. Wenn der Cluster nicht bereits im Debugmodus ausgeführt wurde, führt der Spark-Cluster einen Kaltstart aus. Der Indikator dreht sich, bis die Umgebung für das interaktive Debuggen bereit ist.
Wenn Sie mit dem Debuggen fertig sind, deaktivieren Sie den Debugmodus, damit der Spark-Cluster beendet werden kann. Danach werden Ihnen keine Debugaktivitäten mehr in Rechnung gestellt.
Debug-Einstellungen
Wenn Sie den Debugmodus aktivieren, können Sie bearbeiten, wie ein Datenfluss Daten in der Vorschau anzeigt. Debugeinstellungen können bearbeitet werden, indem Sie auf „Debugeinstellungen“ in der Symbolleiste der Datenflusscanvas klicken. Hier können Sie den Zeilengrenzwert oder die Dateiquelle auswählen, der/die für jede Ihrer Quelltransformationen verwendet werden soll. Die Zeilengrenzwerte in dieser Einstellung gelten nur für die aktuelle Debugsitzung. Sie können außerdem den verknüpften Stagingdienst auswählen, der für eine Azure Synapse Analytics-Quelle verwendet werden soll.

Wenn Sie in Ihrem Datenfluss oder in einem der referenzierten Datasets Parameter verwenden, können Sie angeben, welche Werte beim Debuggen verwendet werden sollen, indem Sie die Registerkarte Parameter auswählen.
Verwenden Sie die hier verfügbaren Einstellungen für Stichproben, um auf Beispieldateien oder Beispieltabellen von Daten zu verweisen, sodass Sie die Quelldatasets nicht ändern müssen. Wenn Sie hier eine Beispieldatei oder -tabelle verwenden, können Sie die Logik- und Eigenschafteneinstellungen im Datenfluss beibehalten, wenn Sie eine Teilmenge der Daten testen.
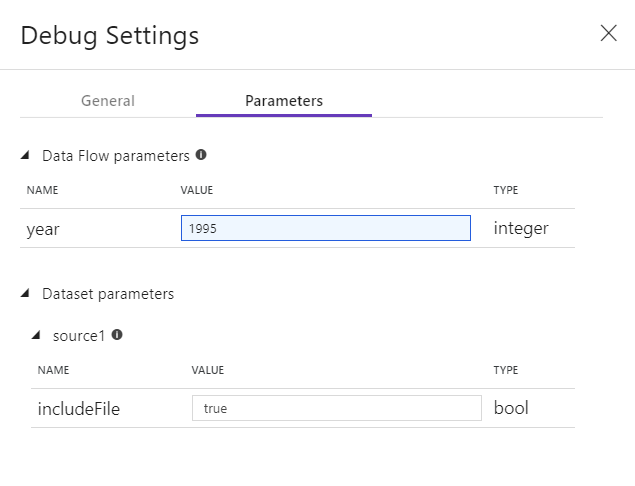
Die standardmäßig für den Debugmodus in Datenflüssen verwendete Integration Runtime ist ein kleiner einzelner Workerknoten mit vier Kernen und einem einzelnen Treiberknoten mit vier Kernen. Dies funktioniert problemlos mit kleineren Datenstichproben beim Testen Ihrer Datenflusslogik. Wenn Sie die Zeilenlimits in den Debugeinstellungen während der Datenvorschau erweitern oder während des Pipelinedebuggens eine höhere Anzahl von Samplingzeilen in der Quelle festlegen, sollten Sie ggf. eine größere Computeumgebung in einer neuen Azure Integration Runtime-Instanz in Betracht ziehen. Anschließend können Sie Ihre Debugsitzung mit der größeren Computeumgebung neu starten.
Datenvorschau
Wenn das Debuggen aktiviert ist, wird im unteren Bereich die Registerkarte „Datenvorschau“ angezeigt. Wenn der Debugmodus deaktiviert ist, werden im Datenfluss auf der Registerkarte „Überprüfen“ nur die für Ihre Transformationen eingehenden und ausgehenden Metadaten angezeigt. Die Datenvorschau fragt nur die Anzahl der Zeilen ab, die Sie in Ihren Debugeinstellungen als Grenzwert festgelegt haben. Wählen Sie Aktualisieren aus, um die Datenvorschau basierend auf Ihren aktuellen Transformationen zu aktualisieren. Wenn sich Ihre Quelldaten geändert haben, wählen Sie > Refetch aktualisieren aus der Quelle.

Sie können die Spalten in der Datenvorschau sortieren und per Drag & Drop neu anordnen. Darüber hinaus gibt es eine Exportschaltfläche oben im Datenvorschaubereich, mit der Sie die Vorschaudaten für die Offlinedatensuche in eine CSV-Datei exportieren können. Sie können mit diesem Feature bis zu 1.000 Zeilen mit Vorschaudaten exportieren.
Hinweis
Durch Dateiquellen wird nur die Anzahl der angezeigten Zeilen eingeschränkt, aber nicht die Anzahl der gelesenen Zeilen. Für sehr große Datasets empfiehlt es sich, einen kleinen Teil der Datei auszuwählen und zu Testzwecken zu verwenden. Sie können unter „Debugeinstellungen“ eine temporäre Datei für jede Quelle auswählen, die den Dataset-Dateityp aufweist.
Wenn der Datenfluss im Debugmodus ausgeführt wird, werden Ihre Daten nicht in die Senkentransformation geschrieben. Eine Debugsitzung soll als Testumgebung für Ihre Transformationen dienen. Senken sind während des Debuggens nicht erforderlich und werden in Ihrem Datenfluss ignoriert. Wenn Sie das Schreiben der Daten in Ihre Senke testen möchten, führen Sie den Datenfluss in einer Pipeline aus, und verwenden Sie die Debugausführung in einer Pipeline.
Die Datenvorschau ist eine Momentaufnahme Ihrer Daten, die mithilfe von Zeilenlimits und Datensampling aus Datenrahmen im Spark-Speicher transformiert wurden. Daher werden die Senkentreiber in diesem Szenario weder verwendet noch getestet.
Hinweis
In der Datenvorschau wird die Uhrzeit gemäß der Gebietsschemaeinstellung des Browsers angezeigt.
Testen der Join-Bedingungen
Stellen Sie beim Ausführen von Komponententests für Joins-, Exists- oder Lookup-Transformationen sicher, dass Sie eine kleine Menge bekannter Daten für den Test verwenden. Mithilfe der zuvor beschriebenen Option „Debugeinstellungen“ können Sie eine temporäre Datei für den Test festlegen. Dies ist erforderlich, da Sie beim Einschränken oder Sampling von Zeilen aus einem großen Dataset nicht vorhersagen können, welche Zeilen und welche Schlüssel zu Testzwecken in den Flow eingelesen werden. Das Ergebnis ist nicht deterministisch. Das bedeutet, dass die Verknüpfungsbedingungen Fehler verursachen können.
Schnelle Aktionen
Sobald die Datenvorschau angezeigt wird, können Sie eine schnelle Transformation generieren, um eine Spalte zu typisieren, zu entfernen oder zu ändern. Wählen Sie die Spaltenüberschrift aus und wählen Sie dann auf der Symbolleiste der Datenvorschau eine der Optionen aus.

Nach Auswahl einer Änderung wird die Datenvorschau sofort aktualisiert. Wählen Sie in der oberen rechten Ecke Bestätigen aus, um eine neue Transformation zu generieren.

Beim Typisieren und Ändern wird eine Transformation für abgeleitete Spalten generiert, und bei Auswahl von Entfernen wird eine Auswahltransformation generiert.

Hinweis
Wenn Sie Ihren Datenfluss bearbeiten, müssen Sie die Datenvorschau erneut abrufen, bevor Sie eine schnelle Transformation hinzufügen.
Datenprofilerstellung
Wenn Sie auf der Registerkarte „Datenvorschau“ eine Spalte auswählen und auf der Symbolleiste der Datenvorschau auf Statistik klicken, wird ganz rechts in Ihrem Datenraster ein Diagramm mit detaillierten Statistiken zu jedem Feld angezeigt. Der Dienst bestimmt basierend auf dem Datensampling, welche Art von Diagramm für die Anzeige verwendet wird. Felder mit hoher Kardinalität werden standardmäßig mit NULL/NOT NULL-Diagrammen angezeigt, kategorische und numerische Daten mit niedriger Kardinalität werden in Balkendiagrammen mit Datenwerthäufigkeit dargestellt. Außerdem wird die maximale Länge der Zeichenkettenfelder, Min/Max-Werte in numerischen Feldern, Standardabweichung, Perzentile, Anzahl und Mittelwert angezeigt.

Zugehöriger Inhalt
- Sobald Sie mit dem Erstellen und Debuggen Ihres Datenflusses fertig sind, führen Sie ihn in einer Pipeline aus.
- Wenn Sie Ihre Pipeline mit einem Datenfluss testen, verwenden Sie die Option zum Ausführen des Debuggens für die Pipeline.