Kopieren von Daten aus Amazon RDS für SQL Server mithilfe von Azure Data Factory oder Azure Synapse Analytics
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- und Azure Synapse-Pipelines verwenden, um Daten aus Amazon RDS for SQL Server zu kopieren. Weitere Informationen finden Sie im Einführungsartikel zu Azure Data Factory oder Azure Synapse Analytics.
Unterstützte Funktionen
Dieser Amazon RDS für SQL Server-Konnektor wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/-) | ① ② |
| Lookup-Aktivität | ① ② |
| GetMetadata-Aktivität | ① ② |
| Aktivität „Gespeicherte Prozedur“ | ① ② |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Insbesondere unterstützt dieser Amazon RDS for SQL Server-Connector:
- SQL Server, Version 2005 und höher.
- Kopieren von Daten unter Verwendung der SQL- oder Windows-Authentifizierung
- Als Quelle das Abrufen von Daten mithilfe einer SQL-Abfrage oder gespeicherten Prozedur Sie können sich auch für das parallele Kopieren aus der Amazon RDS for SQL Server-Quelle entscheiden. Einzelheiten finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank.
SQL Server Express LocalDB wird nicht unterstützt.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in einer virtuellen privaten Amazon-Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Amazon RDS for SQL Server-Diensts über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um über die Benutzeroberfläche des Azure-Portals einen verknüpften Amazon RDS for SQL Server-Dienst zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus, und klicken Sie dann auf „Neu“:
Suchen Sie Amazon RDS for SQL Server, und wählen Sie den Amazon RDS for SQL Server-Connector aus.
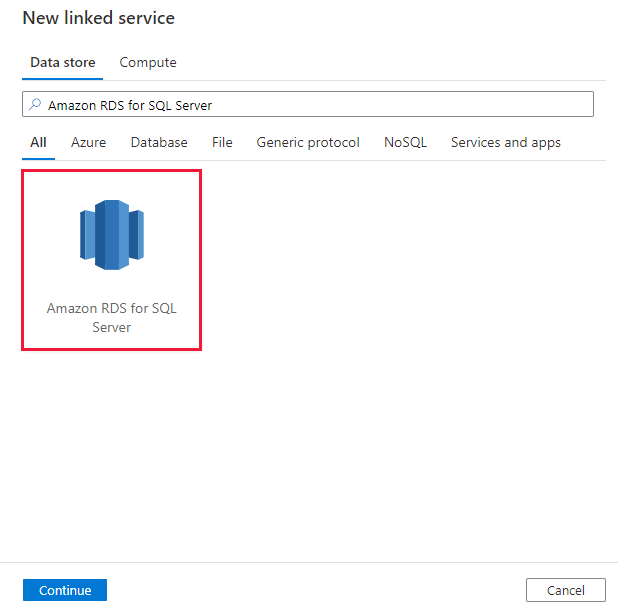
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
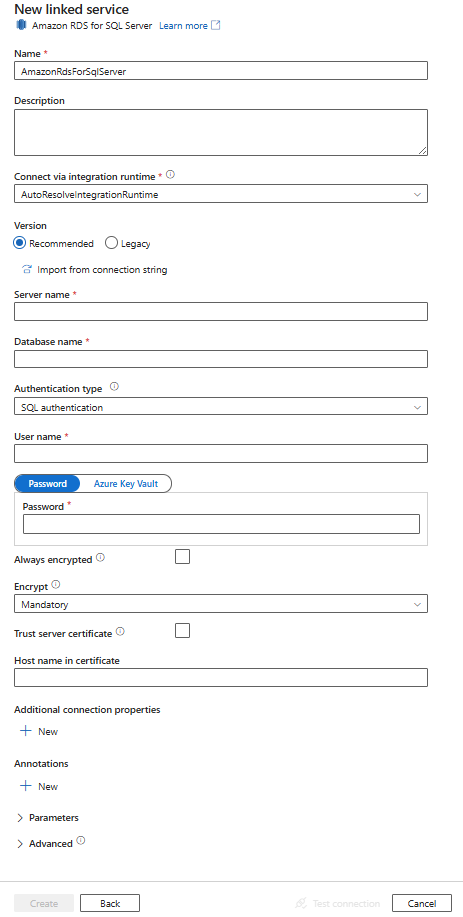
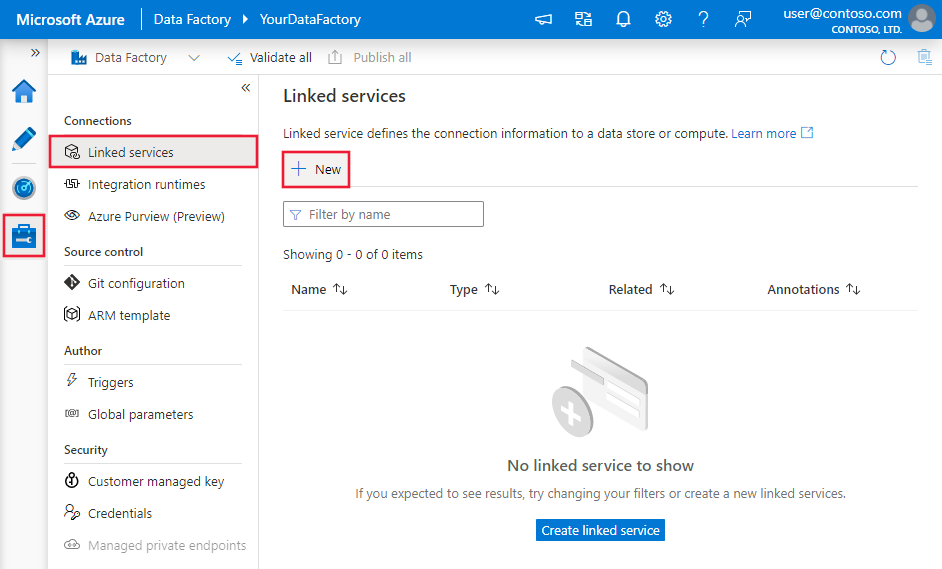
Details zur Connectorkonfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Entitäten in Data Factory- und Synapse-Pipelines speziell für den Amazon RDS for SQL Server-Datenbankconnector verwendet werden.
Eigenschaften des verknüpften Diensts
Die empfohlene Version des Konnektors „Amazon RDS für SQL Server“ unterstützt TLS 1.3. In diesem Abschnitt erfahren Sie, wie Sie die Version des Konnektors „Amazon RDS für SQL Server“ von der Legacy-Version aktualisieren. Einzelheiten zu den Eigenschaften finden Sie in den entsprechenden Abschnitten.
Hinweis
Amazon RDS for SQL Server Always Encrypted wird in Datenflüssen nicht unterstützt.
Tipp
Wenn ein Fehler mit dem Fehlercode „UserErrorFailedToConnectToSqlServer“ auftritt und eine Meldung wie „Das Sitzungslimit für die Datenbank ist XXX und wurde erreicht“ angezeigt wird, fügen Sie Pooling=false zu Ihrer Verbindungszeichenfolge hinzu, und versuchen Sie es erneut.
Empfohlene Version
Diese generischen Eigenschaften werden für einen mit „Amazon RDS für SQL Server“ verknüpften Dienst unterstützt, wenn Sie die empfohlene Version anwenden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Eigenschaft „Typ“ muss auf AmazonRdsForSqlServer festgelegt werden. | Ja |
| server | Name oder Netzwerkadresse der SQL Server-Instanz, mit der Sie eine Verbindung herstellen möchten | Ja |
| database | Der Name der Datenbank. | Ja |
| authenticationType | Der Typ, der für die Authentifizierung verwendet wird. Zulässige Werte sind SQL (Standard) und Windows. Einzelheiten zu bestimmten Eigenschaften und Voraussetzungen finden Sie im entsprechenden Authentifizierungsabschnitt. | Ja |
| Always Encrypted-Einstellungen | Geben Sie die erforderlichen alwaysEncryptedSettings-Informationen an, damit Always Encrypted vertrauliche Daten schützen kann, die in Amazon RDS for SQL Server mithilfe der verwalteten Identität oder des Dienstprinzipals gespeichert sind. Weitere Informationen finden Sie im JSON-Beispiel unter der Tabelle sowie in dem Bereich Verwenden von Always Encrypted. Wenn keine Angabe erfolgt, ist die standardmäßige Always Encrypted-Einstellung deaktiviert. | No |
| encrypt | Geben Sie an, ob die TLS-Verschlüsselung für alle Daten erforderlich ist, die zwischen dem Client und dem Server gesendet werden. Optionen: obligatorisch (für TRUE, Standard)/optional (für FALSE)/streng | No |
| trustServerCertificate | Geben Sie an, ob der Kanal verschlüsselt wird, während die Zertifikatskette zum Überprüfen der Vertrauensstellung umgangen wird. | No |
| hostNameInCertificate | Hostname, der beim Validieren des Serverzertifikats für die Verbindung verwendet werden soll. Falls nicht angegeben, wird der Servername für die Zertifikatvalidierung verwendet | No |
| connectVia | Diese Integration Runtime wird zum Herstellen einer Verbindung mit dem Datenspeicher verwendet. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | No |
Weitere Verbindungseigenschaften finden Sie in der folgenden Tabelle:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| applicationIntent | Workloadtyp der Anwendung beim Herstellen einer Verbindung mit einem Server. Zulässige Werte sind ReadOnly und ReadWrite. |
No |
| connectTimeout | Dauer (in Sekunden), die auf eine Verbindung mit dem Server gewartet wird, bevor der Versuch abgebrochen wird und ein Fehler generiert wird | No |
| connectRetryCount | Anzahl der Neuverbindungsversuche, nachdem ein Leerlaufverbindungsfehler erkannt wurde. Der Wert sollte eine ganze Zahl zwischen 0 und 255 sein. | No |
| connectRetryInterval | Dauer (in Sekunden) zwischen jedem Neuverbindungsversuch, nachdem ein Leerlaufverbindungsfehler erkannt wurde. Der Wert sollte eine ganze Zahl zwischen 1 und 60 sein. | No |
| loadBalanceTimeout | Mindestdauer (in Sekunden), die eine Verbindung im Verbindungspool verbleiben soll, bevor die Verbindung abgebrochen wird. | No |
| commandTimeout | Standardwartezeit (in Sekunden), die gewartet werden soll, bis der Versuch einer Befehlsausführung beendet und ein Fehler generiert wird | No |
| integratedSecurity | Die zulässigen Werte lauten true oder false. Geben Sie beim Wert false an, ob „userName“ und „password“ in der Verbindung angegeben werden. Geben Sie beim Wert true an, ob die aktuellen Anmeldeinformationen für das Windows-Konto für die Authentifizierung verwendet werden. |
No |
| failoverPartner | Name oder Adresse des Partnerservers, mit dem eine Verbindung hergestellt werden soll, wenn der primäre Server ausgefallen ist | No |
| maxPoolSize | Im Verbindungspool zulässige Höchstanzahl der Verbindungen für die angegebene Verbindung | No |
| minPoolSize | Im Verbindungspool zulässige Mindestanzahl der Verbindungen für die angegebene Verbindung. | No |
| multipleActiveResultSets | Die zulässigen Werte lauten true oder false. Wenn Sie true angeben, kann eine Anwendung mehrere aktive Resultsets (MARS) verwalten. Wenn Sie false angeben, muss die Anwendung alle Resultsets aus einem Batch verarbeiten oder abbrechen, bevor andere Batches über diese Verbindung ausgeführt werden können. |
No |
| multiSubnetFailover | Die zulässigen Werte lauten true oder false. Wenn Ihre Anwendung eine Verbindung mit einer AlwaysOn-Verfügbarkeitsgruppe in unterschiedlichen Subnetzen herstellt, ermöglicht das Festlegen dieser Eigenschaft auf true eine schnellere Erkennung des derzeit aktiven Servers und eine schnellere Verbindung mit dem Server. |
No |
| packetSize | Größe der Netzwerkpakete (in Byte), die bei der Kommunikation mit einer Instanz des Servers verwendet werden | No |
| pooling | Die zulässigen Werte lauten true oder false. Wenn Sie true angeben, wird die Verbindung gepoolt. Wenn Sie false angeben, wird die Verbindung bei jeder Anforderung der Verbindung explizit geöffnet. |
No |
SQL-Authentifizierung
Um die SQL-Standardauthentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| userName | Benutzername, der zum Herstellen einer Verbindung mit dem Server verwendet wird. | Ja |
| Kennwort | Das Kennwort für den Benutzernamen. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern. Alternativ können Sie auf ein in Azure Key Vault gespeichertes Geheimnis verweisen. | Ja |
Beispiel 1: Verwenden der SQL-Authentifizierung
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel 2: Verwenden der SQL-Authentifizierung mit einem Kennwort in Azure Key Vault
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Verwenden von Always Encrypted
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Windows-Authentifizierung
Um die Windows-Authentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| userName | Geben Sie einen Benutzernamen an. Ein Beispiel lautet domainname\username. | Ja |
| password | Geben Sie das Kennwort für das Benutzerkonto an, das Sie für den Benutzernamen angegeben haben. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern. Alternativ können Sie auf ein in Azure Key Vault gespeichertes Geheimnis verweisen. | Ja |
Beispiel: Verwenden der Windows-Authentifizierung
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Legacy-Version
Diese generischen Eigenschaften werden für einen mit „Amazon RDS für SQL Server“ verknüpften Dienst unterstützt, wenn Sie die Legacy- Version anwenden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Eigenschaft „Typ“ muss auf AmazonRdsForSqlServer festgelegt werden. | Ja |
| Always Encrypted-Einstellungen | Geben Sie die erforderlichen alwaysEncryptedSettings-Informationen an, damit Always Encrypted vertrauliche Daten schützen kann, die in Amazon RDS for SQL Server mithilfe der verwalteten Identität oder des Dienstprinzipals gespeichert sind. Weitere Informationen finden Sie im Abschnitt Verwenden von Always Encrypted. Wenn keine Angabe erfolgt, ist die standardmäßige Always Encrypted-Einstellung deaktiviert. | Nein |
| connectVia | Diese Integration Runtime wird zum Herstellen einer Verbindung mit dem Datenspeicher verwendet. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | No |
Dieser Konnektor für „Amazon RDS für SQL Server“ unterstützt die folgenden Authentifizierungstypen. Weitere Informationen finden Sie in den entsprechenden Abschnitten.
SQL-Authentifizierung für die Legacy-Version
Um die SQL-Standardauthentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| connectionString | Geben Sie unter connectionString die Verbindungszeichenfolge an, die zum Herstellen einer Verbindung mit der Datenbank von „Amazon RDS für SQL Server“ erforderlich ist. Geben Sie einen Anmeldenamen als Ihren Benutzernamen an, und stellen Sie sicher, dass die Datenbank, die Sie verbinden möchten, dieser Anmeldung zugeordnet ist. | Ja |
| password | Wenn Sie ein Kennwort in Azure Key Vault speichern möchten, rufen Sie mithilfe von Pull die password-Konfiguration aus der Verbindungszeichenfolge ab. Weitere Informationen finden Sie unter Speichern von Anmeldeinformationen in Azure Key Vault. |
No |
Windows-Authentifizierung für die Legacy-Version
Um die Windows-Authentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| connectionString | Geben Sie unter connectionString die Verbindungszeichenfolge an, die zum Herstellen einer Verbindung mit der Datenbank von „Amazon RDS für SQL Server“ erforderlich ist. | Ja |
| userName | Geben Sie einen Benutzernamen an. Ein Beispiel lautet domainname\username. | Ja |
| password | Geben Sie das Kennwort für das Benutzerkonto an, das Sie für den Benutzernamen angegeben haben. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern. Alternativ können Sie auf ein in Azure Key Vault gespeichertes Geheimnis verweisen. | Ja |
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom Amazon RDS for SQL Server-Dataset unterstützt werden.
Zum Kopieren von Daten aus einer Amazon RDS for SQL Server-Datenbank werden die folgenden Eigenschaften unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft des Datasets muss auf AmazonRdsForSqlServerTable festgelegt werden. | Ja |
| schema | Name des Schemas. | Nein |
| table | Name der Tabelle/Ansicht. | Nein |
| tableName | Name der Tabelle/Ansicht mit Schema. Diese Eigenschaft wird aus Gründen der Abwärtskompatibilität weiterhin unterstützt. Verwenden Sie für eine neue Workload schema und table. |
Nein |
Beispiel
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Amazon RDS for SQL Server-Quelle unterstützt werden.
Amazon RDS for SQL Server als Quelle
Tipp
Weitere Informationen zum effizienten Laden von Daten aus Amazon RDS for SQL Server mittels Datenpartitionierung finden Sie unter Paralleles Kopieren aus SQL-Datenbank.
Legen Sie zum Kopieren von Daten aus Amazon RDS for SQL Server den Quelltyp in der Copy-Aktivität auf AmazonRdsForSqlServerSource fest. Die folgenden Eigenschaften werden im Abschnitt „source“ der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Quelle der Copy-Aktivität muss auf AmazonRdsForSqlServerSource festgelegt werden. | Ja |
| sqlReaderQuery | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. z. B. select * from MyTable. |
Nein |
| sqlReaderStoredProcedureName | Diese Eigenschaft ist der Name der gespeicherten Prozedur, die Daten aus der Quelltabelle liest. Die letzte SQL-Anweisung muss eine SELECT-Anweisung in der gespeicherten Prozedur sein. | Nein |
| storedProcedureParameters | Diese Parameter werden für die gespeicherte Prozedur verwendet. Zulässige Werte sind Namen oder Name-Wert-Paare. Die Namen und die Groß-/Kleinschreibung von Parametern müssen den Namen und der Groß-/Kleinschreibung der Parameter der gespeicherten Prozedur entsprechen. |
Nein |
| isolationLevel | Gibt das Sperrverhalten für Transaktionen für die SQL-Quelle an. Zulässige Werte sind: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Ohne Angabe wird die Standardisolationsstufe der Datenbank verwendet. Weitere Informationen finden Sie in dieser Dokumentation. | Nein |
| partitionOptions | Gibt die Datenpartitionierungsoptionen an, die zum Laden von Daten aus Amazon RDS for SQL Server verwendet werden. Zulässige Werte sind: None (Standardwert), PhysicalPartitionsOfTable und DynamicRange. Wenn eine Partitionsoption aktiviert ist (nicht None), wird der Grad an Parallelität zum gleichzeitigen Laden von Daten aus Amazon RDS for SQL Server durch die Einstellung parallelCopies für die Copy-Aktivität gesteuert. |
Nein |
| partitionSettings | Geben Sie die Gruppe der Einstellungen für die Datenpartitionierung an. Verwenden Sie diese Option, wenn die Partitionsoption nicht None lautet. |
Nein |
Unter partitionSettings: |
||
| partitionColumnName | Geben Sie den Namen der Quellspalte als „integer“ oder „date/datetime“ (int, smallint, bigint, date, smalldatetime, datetime, datetime2 oder datetimeoffset) an, der von der Bereichspartitionierung für das parallele Kopieren verwendet wird. Ohne Angabe wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet.Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?DfDynamicRangePartitionCondition in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank. |
Nein |
| partitionUpperBound | Der maximale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank. |
Nein |
| partitionLowerBound | Der minimale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank. |
Nein |
Beachten Sie folgende Punkte:
- Wenn sqlReaderQuery für AmazonRdsForSqlServerSource angegeben ist, führt die Copy-Aktivität diese Abfrage für die Amazon RDS for SQL Server-Quelle aus, um die Daten abzurufen. Sie können auch eine gespeicherte Prozedur angeben, indem Sie sqlReaderStoredProcedureName und storedProcedureParameters angeben, sofern die gespeicherten Prozeduren Parameter verwenden.
- Wenn Sie eine gespeicherte Prozedur in der Quelle zum Abrufen von Daten verwenden und die gespeicherte Prozedur so konzipiert ist, dass beim Übergeben eines anderen Parameterwerts ein anderes Schema zurückgegeben wird, tritt möglicherweise ein Fehler oder ein unerwartetes Ergebnis auf, wenn Sie ein Schema von der Benutzeroberfläche importieren oder Daten in SQL-Datenbank mit automatischer Tabellenerstellung kopieren.
Beispiel: Verwenden einer SQL-Abfrage
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Beispiel: Verwenden einer gespeicherten Prozedur
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definition der gespeicherten Prozedur
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Paralleles Kopieren aus SQL-Datenbank
Der Amazon RDS for SQL Server-Connector in der Copy-Aktivität verfügt über eine integrierte Datenpartitionierung zum parallelen Kopieren von Daten. Die Datenpartitionierungsoptionen befinden sich auf der Registerkarte Quelle der Kopieraktivität.
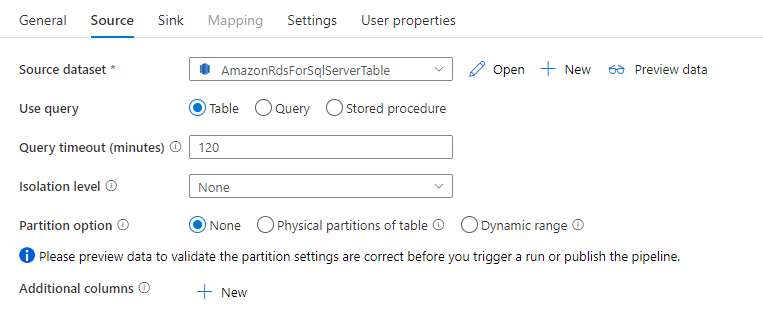
Wenn Sie partitioniertes Kopieren aktivieren, führt die Copy-Aktivität parallele Abfragen für Ihre Amazon RDS for SQL Server-Quelle aus, um Daten partitionsweise zu laden. Der Parallelitätsgrad wird über die Einstellung parallelCopies der Kopieraktivität gesteuert. Wenn Sie z. B. parallelCopies auf vier einstellen, generiert der Dienst gleichzeitig vier Abfragen, die auf der von Ihnen angegebenen Partitionsoption und den Einstellungen basieren, und führt sie aus, wobei jede Abfrage einen Teil der Daten aus Ihrer Amazon RDS for SQL Server-Datenbank abruft.
Es wird empfohlen, das parallele Kopieren mit Datenpartitionierung vor allem dann zu aktivieren, wenn Sie große Datenmengen aus Amazon RDS for SQL Server laden. Im Anschluss finden Sie empfohlene Konfigurationen für verschiedene Szenarien. Beim Kopieren von Daten in einen dateibasierten Datenspeicher wird empfohlen, mehrere Dateien in einen Ordner zu schreiben (nur den Ordnernamen anzugeben). In diesem Fall ist die Leistung besser als beim Schreiben in eine einzelne Datei.
| Szenario | Empfohlene Einstellungen |
|---|---|
| Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen | Partitionsoption: Physische Partitionen der Tabelle. Während der Ausführung erkennt der Dienst automatisch die physischen Partitionen und kopiert Daten nach Partitionen. Um zu überprüfen, ob Ihre Tabelle eine physische Partition besitzt oder nicht, können Sie auf diese Abfrage verweisen. |
| Vollständiges Laden aus einer großen Tabelle ohne physische Partitionen, aber mit einer integer- oder datetime-Spalte für die Datenpartitionierung. | Partitionsoptionen: Dynamische Bereichspartitionierung Partitionsspalte (optional): Geben Sie die Spalte für die Datenpartitionierung an. Ohne Angabe wird die Primärschlüsselspalte verwendet. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle; alle Zeilen in der Tabelle werden partitioniert und kopiert. Wenn keine Angabe erfolgt, erkennt die Copy-Aktivität die Werte automatisch und kann je nach MIN- und MAX-Werten lange dauern. Es wird empfohlen, Ober- und Untergrenzen anzugeben. Wenn Ihre Partitionsspalte "ID" beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20 und die obere Grenze auf 80 und die Parallelkopie auf 4 setzen, ruft der Dienst Daten nach 4 Partitionen ab - IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage ohne physische Partitionen, aber mit einer integer- oder date/datetime-Spalte für die Datenpartitionierung. | Partitionsoptionen: Dynamische Bereichspartitionierung Abfrage: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte für die Datenpartitionierung an. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle; alle Zeilen im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Wenn Ihre Partitionsspalte „ID“ beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20, die obere Grenze auf 80 und die Parallelkopie auf 4 festlegen, ruft der Dienst Daten nach 4 Partitionen ab – IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. Hier finden Sie weitere Beispiele für verschiedene Szenarien: 1. Abfrage der gesamten Tabelle: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Abfrage aus einer Tabelle mit Spaltenauswahl und zusätzlichen Where-Klausel-Filtern: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Abfragen mit Unterabfragen: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Abfrage mit Partition in Unterabfrage: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Bewährte Methoden zum Laden von Daten mit Partitionierungsoption:
- Wählen Sie eine aussagekräftige Spalte als Partitionsspalte (wie Primärschlüssel oder eindeutiger Schlüssel), um Datenabweichungen zu vermeiden.
- Wenn die Tabelle eine integrierte Partition aufweist, verwenden Sie die Partitionsoption „Physikalische Partitionen der Tabelle“, um eine bessere Leistung zu erzielen.
- Wenn Sie Azure Integration Runtime zum Kopieren von Daten verwenden, können Sie größere „Datenintegrationseinheiten (Data Integration Units, DIU)“ festlegen (> 4), um mehr Computingressourcen zu nutzen. Prüfen Sie dort die anwendbaren Szenarien.
- „Grad der Kopierparallelität“ steuert die Partitionsnummern. Ein zu großer Wert schadet manchmal der Leistung. Deshalb wird empfohlen, diesen Wert wie folgt festzulegen: (DIU oder Anzahl der selbstgehosteten IR-Knoten) × (2 bis 4).
Beispiel: Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Beispiel: Abfrage mit dynamischer Bereichspartition
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Beispielabfrage zur Überprüfung der physischen Partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Wenn die Tabelle eine physische Partition besitzt, würde „HasPartition“ wie folgt als „Yes“ (Ja) angezeigt werden.

Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Eigenschaften der GetMetadata-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter GetMetadata-Aktivität.
Verwenden von Always Encrypted
Führen Sie beim Kopieren von Daten aus bzw. nach Amazon RDS for SQL Server mit Always Encrypted die folgenden Schritte aus:
Speichern Sie den Spalten-Hauptschlüssel (Column Master Key, CMK) in einem Azure Key Vault. Weitere Informationen: Konfigurieren von Always Encrypted mithilfe von Azure Key Vault
Stellen Sie sicher, dass der Zugriff auf den Schlüsseltresor gewährt wird, in dem der Spaltenhauptschlüssel (Column Master Key, CMK) gespeichert ist. Die erforderlichen Berechtigungen finden Sie in diesem Artikel.
Erstellen Sie einen verknüpften Dienst, um eine Verbindung mit der SQL-Datenbank herzustellen und aktivieren Sie die „Always Encrypted“-Funktion mithilfe einer verwalteten Identität oder eines Dienstprinzipals.
Beheben von Verbindungsproblemen
Konfigurieren Sie Ihre Amazon RDS for SQL Server-Instanz so, dass Remoteverbindungen zulässig sind. Starten Sie Amazon RDS for SQL Server Management Studio, klicken Sie mit der rechten Maustaste auf Server, und wählen Sie Eigenschaften aus. Wählen Sie in der Liste den Eintrag Verbindungen aus, und aktivieren Sie das Kontrollkästchen Remoteverbindungen mit diesem Server zulassen.
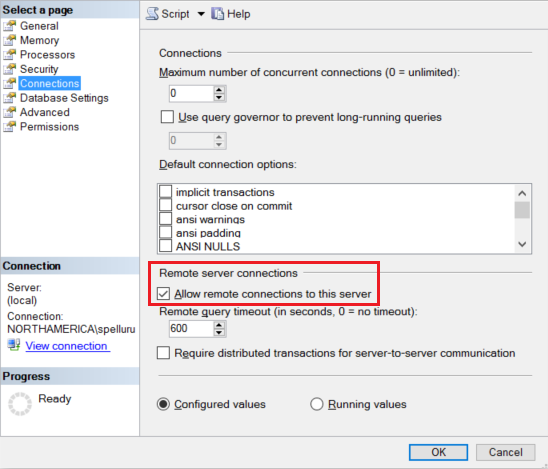
Ausführliche Schritte finden Sie unter Konfigurieren der Serverkonfigurationsoption „Remotezugriff“.
Starten Sie den Amazon RDS for SQL Server-Konfigurations-Manager. Erweitern Sie Amazon RDS for SQL Server-Netzwerkkonfiguration für die gewünschte Instanz, und wählen Sie Protokolle für MSSQLSERVER aus. Die Protokolle werden im rechten Bereich angezeigt. Aktivieren Sie TCP/IP, indem Sie mit der rechten Maustaste auf TCP/IP klicken und Aktivieren auswählen.
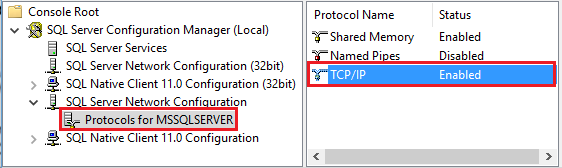
Weitere Informationen und alternative Methoden zum Aktivieren von TCP/IP finden Sie unter Aktivieren oder Deaktivieren eines Servernetzwerkprotokolls.
Doppelklicken Sie im gleichen Fenster auf TCP/IP, um das Fenster TCP/IP-Eigenschaften zu öffnen.
Wechseln Sie zur Registerkarte IP-Adressen . Scrollen Sie nach unten zum Abschnitt IPAll. Notieren Sie sich den TCP-Port. Der Standardport ist 1433.
Erstellen Sie auf dem Computer eine Regel für die Windows-Firewall , um eingehenden Datenverkehr über diesen Port zuzulassen.
Verbindung überprüfen: Verwenden Sie Amazon RDS for SQL Server Management Studio auf einem anderen Computer, um mit dem vollqualifizierten Namen eine Verbindung zu Amazon RDS for SQL Server herzustellen. z. B.
"<machine>.<domain>.corp.<company>.com,1433".
Upgrade der Version von „Amazon RDS für SQL Server“
Zum Upgrade der Version von „Amazon RDS für SQL Server“ wählen Sie auf der Seite Verknüpften Dienst bearbeiten unter Version die Option Empfohlen aus, und konfigurieren Sie den verknüpften Dienst. Beziehen Sie sich dabei auf Eigenschaften des verknüpften Diensts für die empfohlene Version.
Unterschiede zwischen der empfohlenen Version und der Legacyversion
In der nachstehenden Tabelle sind die Unterschiede zwischen Amazon RDS für SQL Server unter Verwendung der empfohlenen Version und der Legacyversion dargestellt.
| Empfohlene Version | Legacyversion |
|---|---|
Unterstützung von TLS 1.3 über encrypt als strict. |
TLS 1.3 wird nicht unterstützt. |
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in Unterstützte Datenspeicher.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für