Kopieren und Transformieren von Daten in Azure Cosmos DB for NoSQL mithilfe von Azure Data Factory
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie Daten mithilfe der Kopieraktivität in Azure Data Factory aus und in Azure Cosmos DB for NoSQL kopieren sowie Daten mithilfe des Datenflusses in Azure Cosmos DB for NoSQL transformieren. Weitere Informationen finden Sie in dem Einführungsartikel zu Azure Data Factory oder Azure Synapse Analytics.
Hinweis
Dieser Connector unterstützt nur Azure Cosmos DB for NoSQL. Informationen zu Azure Cosmos DB for MongoDB finden Sie unter Connector für Azure Cosmos DB for MongoDB. Andere API-Typen werden derzeit nicht unterstützt.
Unterstützte Funktionen
Dieser Azure Cosmos DB for NoSQL-Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR | Verwalteter privater Endpunkt |
|---|---|---|
| Kopieraktivität (Quelle/Senke) | ① ② | ✓ |
| Zuordnungsdatenfluss (Quelle/Senke) | ① | ✓ |
| Lookup-Aktivität | ① ② | ✓ |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Im Rahmen der Kopieraktivität unterstützt dieser Azure Cosmos DB for NoSQL-Connector folgende Aktivitäten:
- Das Kopieren von Daten aus und in Azure Cosmos DB for NoSQL mithilfe von Schlüssel, Dienstprinzipal oder verwalteten Identitäten für die Azure-Ressourcenauthentifizierungen.
- Schreiben in Azure Cosmos DB als insert oder upsert.
- Importieren und Exportieren von JSON-Dokumenten in ihrem jeweiligen Zustand oder Kopieren von Daten aus einem tabellarischen Dataset oder in ein tabellarisches Dataset. Die Beispiele zeigen eine SQL-Datenbank und eine CSV-Datei. Informationen zum Kopieren von Dokumenten in ihrem jeweiligen Zustand in bzw. aus JSON-Dateien oder in eine andere bzw. aus einer anderen Azure Cosmos DB-Sammlung finden Sie unter Importieren und Exportieren von JSON-Dokumenten.
Data Factory- und Synapse Pipelines werden in die Azure Cosmos DB-BuklExecutor-Bibliothek integriert, um beim Schreiben in Azure Cosmos DB die beste Leistung zu erzielen.
Tipp
Das Video Datenmigration führt Sie schrittweise durch das Kopieren von Daten aus Azure Blob Storage in Azure Cosmos DB. Das Video beschreibt auch Überlegungen zur Leistungsoptimierung beim Erfassen von Daten in Azure Cosmos DB im Allgemeinen.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
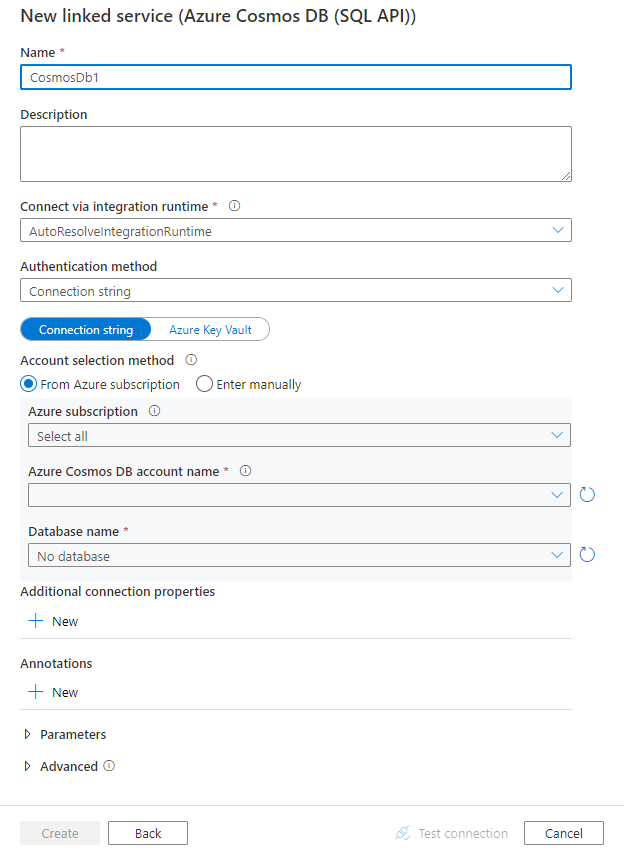
Erstellen eines verknüpften Diensts mit Azure Cosmos DB über die Benutzeroberfläche
Verwenden Sie die folgenden Schritte, um einen verknüpften Dienst für die Azure Cosmos DB auf der Azure-Portal-Benutzeroberfläche zu erstellen.
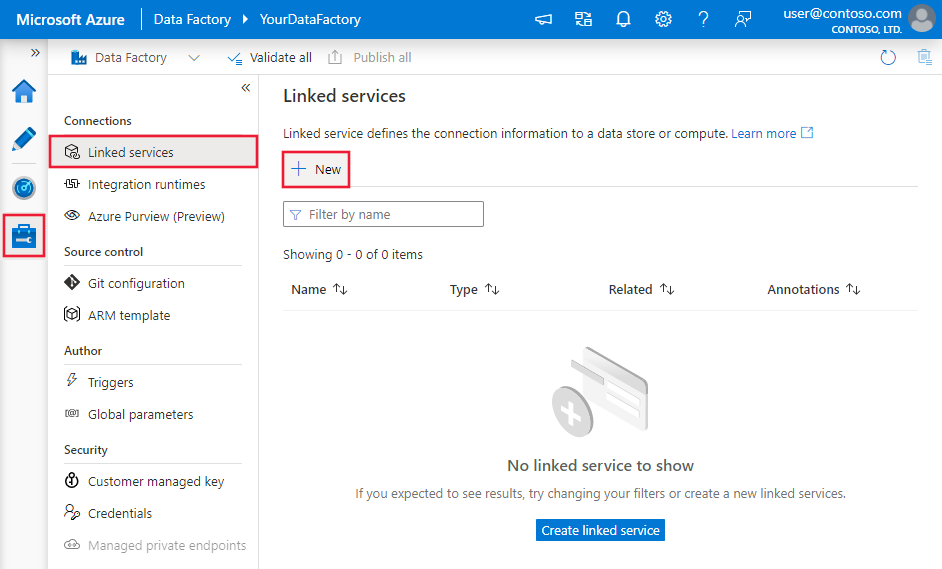
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus und klicken Sie dann auf „Neu“:
Suchen Sie nach Azure Cosmos DB for NoSQL, und wählen Sie den Azure Cosmos DB for NoSQL-Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die Sie zum Definieren von Entitäten verwenden können, die spezifisch für Azure Cosmos DB for NoSQL sind.
Eigenschaften des verknüpften Diensts
Der Azure Cosmos DB for NoSQL-Connector unterstützt die folgenden Authentifizierungstypen. Weitere Informationen finden Sie in den entsprechenden Abschnitten:
- Schlüsselauthentifizierung
- Dienstprinzipalauthentifizierung
- Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
- Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Schlüsselauthentifizierung
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf CosmosDb festgelegt werden. | Ja |
| connectionString | Geben Sie die zum Herstellen einer Verbinden mit der Azure Cosmos DB-Datenbank erforderlichen Informationen an. Hinweis: Sie müssen Datenbankinformationen in der Verbindungszeichenfolge angeben, wie in den folgenden Beispielen gezeigt. Sie können auch den Kontoschlüssel in Azure Key Vault speichern und die accountKey-Konfiguration aus der Verbindungszeichenfolge pullen. Ausführlichere Informationen finden Sie in den folgenden Beispielen und im Artikel Speichern von Anmeldeinformationen in Azure Key Vault. |
Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn diese Eigenschaft nicht angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;AccountKey=<AccessKey>;Database=<Database>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Speichern des Kontoschlüssels in Azure Key Vault
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;Database=<Database>",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dienstprinzipalauthentifizierung
Hinweis
Derzeit wird die Dienstprinzipalauthentifizierung im Datenfluss nicht unterstützt.
Zum Verwenden der Dienstprinzipalauthentifizierung führen Sie die folgenden Schritte aus.
Registrieren einer Anwendung bei der Microsoft Identity Platform. Eine Anleitung finden Sie unter Schnellstart: Registrieren einer Anwendung bei Microsoft Identity Platform. Notieren Sie sich die folgenden Werte, die Sie zum Definieren des verknüpften Diensts verwenden können:
- Anwendungs-ID
- Anwendungsschlüssel
- Mandanten-ID
Erteilen Sie dem Dienstprinzipal geeignete Berechtigungen. Beispiele zur Funktionsweise von Berechtigungen in Azure Cosmos DB finden Sie unter Zugriffssteuerungslisten für Dateien und Verzeichnisse. Genauer gesagt, erstellen Sie eine Rollendefinition, und weisen die Rolle über die Dienstprinzipalobjekt-ID dem Dienstprinzipal zu.
Diese Eigenschaften werden im verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf CosmosDb festgelegt werden. | Yes |
| accountEndpoint | Geben Sie die Kontoendpunkt-URL für die Azure Cosmos DB-Instanz an. | Ja |
| database | Geben Sie den Namen der Datenbank an. | Ja |
| servicePrincipalId | Geben Sie die Client-ID der Anwendung an. | Ja |
| servicePrincipalCredentialType | Die Art von Anmeldeinformationen, die für die Authentifizierung beim Dienstprinzipal verwendet werden. Gültige Werte sind ServicePrincipalKey und ServicePrincipalCert. | Ja |
| servicePrincipalCredential | Die Anmeldeinformationen für den Dienstprinzipal. Wenn Sie ServicePrincipalKey als Anmeldeinformationstyp verwenden, geben Sie den Schlüssel der Anwendung an. Markieren Sie dieses Feld als einen SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. Wenn Sie ServicePrincipalCert als Anmeldeinformationen verwenden, verweisen Sie auf ein Zertifikat in Azure Key Vault, und stellen Sie sicher, dass der Zertifikatsinhaltstyp PKCS #12 lautet. |
Ja |
| tenant | Geben Sie die Mandanteninformationen (Domänenname oder Mandanten-ID) für Ihre Anwendung an. Diese können Sie abrufen, indem Sie im Azure-Portal mit der Maus auf den Bereich oben rechts zeigen. | Ja |
| azureCloudType | Geben Sie für die Dienstprinzipalauthentifizierung die Art der Azure-Cloudumgebung an, bei der Ihre Microsoft Entra-Anwendung registriert ist. Zulässige Werte sind AzurePublic, AzureChina, AzureUsGovernment und AzureGermany. Standardmäßig wird die Cloudumgebung des Diensts verwendet. |
Nein |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel: Verwenden der Dienstprinzipal-Schlüsselauthentifizierung
Sie können den Dienstprinzipalschlüssel auch in Azure Key Vault speichern.
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Verwenden der Dienstprinzipal-Zertifikatauthentifizierung
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalCredential": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<AKV reference>",
"type": "LinkedServiceReference"
},
"secretName": "<certificate name in AKV>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
Hinweis
Derzeit wird die Authentifizierung mit systemseitig zugewiesenen verwalteten Identitäten in Datenflüssen mithilfe erweiterter Eigenschaften im JSON-Format unterstützt.
Eine Data Factory- oder Synapse-Pipeline kann einer verwalteten Identität für Azure-Ressourcen zugeordnet werden, die diese spezielle Data Factory darstellt. Sie können diese verwaltete Identität ähnlich wie Ihren eigenen Dienstprinzipal direkt für die Azure Cosmos DB-Authentifizierung verwenden. Sie erlaubt dieser bestimmten Ressource den Zugriff und das Kopieren von Daten in oder aus Ihrer Azure Cosmos DB-Instanz.
Wenn Sie verwaltete Identitäten für die Azure-Ressourcenauthentifizierung verwenden möchten, gehen Sie folgendermaßen vor.
Rufen Sie die Informationen zur verwalteten Identität ab, indem Sie den Wert von Objekt-ID der verwalteten Identität kopieren, der zusammen mit Ihrem Dienst generiert wurde.
Erteilen Sie der systemseitig zugewiesenen verwalteten Identität geeignete Berechtigungen. Beispiele zur Funktionsweise von Berechtigungen in Azure Cosmos DB finden Sie unter Zugriffssteuerungslisten für Dateien und Verzeichnisse. Genauer gesagt, erstellen Sie eine Rollendefinition, und weisen die Rolle der verwalteten Identität zu.
Diese Eigenschaften werden im verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf CosmosDb festgelegt werden. | Yes |
| accountEndpoint | Geben Sie die Kontoendpunkt-URL für die Azure Cosmos DB-Instanz an. | Ja |
| database | Geben Sie den Namen der Datenbank an. | Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | No |
| subscriptionId | Angeben der Abonnement-ID für die Azure Cosmos DB-Instanz | Nein für Kopieraktivität, Ja für den Zuordnungsdatenfluss |
| tenantId | Angeben der Mandanten-ID für die Azure Cosmos DB-Instanz | Nein für Kopieraktivität, Ja für den Zuordnungsdatenfluss |
| resourceGroup | Angeben des Ressourcengruppennamens für die Azure Cosmos DB-Instanz | Nein für Kopieraktivität, Ja für den Zuordnungsdatenfluss |
Beispiel:
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"subscriptionId": "<subscription id>",
"tenantId": "<tenant id>",
"resourceGroup": "<resource group>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Hinweis
Derzeit wird die Authentifizierung mit benutzerseitig zugewiesenen Identitäten in Datenflüssen mithilfe erweiterter Eigenschaften im JSON-Format unterstützt.
Eine Datenfabrik oder Synapse-Pipeline kann mit einer benutzerzugeordneten verwalteten Identität verbunden werden, die diese spezifische Dienstinstanz darstellt. Sie können diese verwaltete Identität ähnlich wie Ihren eigenen Dienstprinzipal direkt für die Azure Cosmos DB-Authentifizierung verwenden. Sie erlaubt dieser bestimmten Ressource den Zugriff und das Kopieren von Daten in oder aus Ihrer Azure Cosmos DB-Instanz.
Führen Sie die folgenden Schritte aus, um vom Benutzer zugewiesene verwaltete Identitäten für die Authentifizierung von Azure-Ressourcen zu verwenden.
Erstellen Sie eine oder mehrere benutzerzugeordnete verwaltete Identitäten und erteilen Sie der benutzerzugeordneten verwalteten Identität die entsprechende Berechtigung. Beispiele zur Funktionsweise von Berechtigungen in Azure Cosmos DB finden Sie unter Zugriffssteuerungslisten für Dateien und Verzeichnisse. Genauer gesagt, erstellen Sie eine Rollendefinition, und weisen die Rolle der verwalteten Identität zu.
Weisen Sie Ihrer Data Factory eine oder mehrere benutzerseitig zugewiesene verwaltete Identitäten zu, und erstellen Sie Anmeldeinformationen für jede benutzerseitig zugewiesene verwaltete Identität.
Diese Eigenschaften werden im verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf CosmosDb festgelegt werden. | Yes |
| accountEndpoint | Geben Sie die Kontoendpunkt-URL für die Azure Cosmos DB-Instanz an. | Ja |
| database | Geben Sie den Namen der Datenbank an. | Ja |
| Anmeldeinformationen | Geben Sie die benutzerseitig zugewiesene verwaltete Identität als Anmeldeinformationsobjekt an. | Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | No |
| subscriptionId | Angeben der Abonnement-ID für die Azure Cosmos DB-Instanz | Nein für Kopieraktivität, Ja für den Zuordnungsdatenfluss |
| tenantId | Angeben der Mandanten-ID für die Azure Cosmos DB-Instanz | Nein für Kopieraktivität, Ja für den Zuordnungsdatenfluss |
| resourceGroup | Angeben des Ressourcengruppennamens für die Azure Cosmos DB-Instanz | Nein für Kopieraktivität, Ja für den Zuordnungsdatenfluss |
Beispiel:
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"subscriptionId": "<subscription id>",
"tenantId": "<tenant id>",
"resourceGroup": "<resource group>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie unter Datasets und verknüpfte Dienste.
Folgende Eigenschaften werden für das Azure Cosmos DB for NoSQL-Dataset unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die Eigenschaft type des Datasets muss auf CosmosDbSqlApiCollection festgelegt werden. | Ja |
| collectionName | Der Name der Azure Cosmos DB-Dokumentsammlung. | Ja |
Wenn Sie ein Dataset vom Typ „DocumentDbCollection“ verwenden, wird es aus Gründen der Abwärtskompatibilität für die Kopier- und Lookup-Aktivität weiterhin unverändert unterstützt. Für Datenfluss wird es nicht unterstützt. Es wird jedoch empfohlen, in Zukunft das neue Modell zu verwenden.
Beispiel
{
"name": "CosmosDbSQLAPIDataset",
"properties": {
"type": "CosmosDbSqlApiCollection",
"linkedServiceName":{
"referenceName": "<Azure Cosmos DB linked service name>",
"type": "LinkedServiceReference"
},
"schema": [],
"typeProperties": {
"collectionName": "<collection name>"
}
}
}
Eigenschaften der Kopieraktivität
Dieser Abschnitt enthält eine Liste der Eigenschaften, die von Azure Cosmos DB for NoSQL als Quelle und Senke unterstützt werden. Eine vollständige Liste mit den verfügbaren Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie unter Pipelines.
Azure Cosmos DB for NoSQL als Quelle
Legen Sie zum Kopieren von Daten aus Azure Cosmos DB for NoSQL den Typ der Quelle in der Kopieraktivität auf DocumentDbCollectionSource fest.
Die folgenden Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die Eigenschaft type der Quelle für die Kopieraktivität muss auf CosmosDbSqlApiSource festgelegt werden. | Ja |
| Abfrage | Geben Sie die Azure Cosmos DB-Abfrage an, um Daten zu lesen. Beispiel: SELECT c.BusinessEntityID, c.Name.First AS FirstName, c.Name.Middle AS MiddleName, c.Name.Last AS LastName, c.Suffix, c.EmailPromotion FROM c WHERE c.ModifiedDate > \"2009-01-01T00:00:00\" |
Ohne Falls nicht angegeben, wird die folgende SQL-Anweisung ausgeführt: select <columns defined in structure> from mycollection |
| preferredRegions | Die bevorzugte Liste der Regionen, mit denen beim Abrufen von Daten aus Azure Cosmos DB eine Verbindung hergestellt werden soll. | Nein |
| pageSize | Die Anzahl der Dokumente pro Seite des Abfrageergebnisses. Der Standardwert ist „-1“. Dies bedeutet, dass im Ergebnis die dienstseitige dynamische Seitengröße bis zu 1000 verwendet wird. | Nein |
| detectDatetime | Legt fest, ob datetime aus den Zeichenfolgenwerten in den Dokumenten erkannt werden soll. Zulässige Werte sind true (Standard) oder false | Nein |
Wenn Sie eine Quelle vom Typ „DocumentDbCollectionSource“ verwenden, wird sie aus Gründen der Abwärtskompatibilität weiterhin unverändert unterstützt. Es wird empfohlen, in Zukunft das neue Modell zu verwenden, das umfangreichere Funktionen zum Kopieren von Daten aus Azure Cosmos DB enthält.
Beispiel
"activities":[
{
"name": "CopyFromCosmosDBSQLAPI",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cosmos DB for NoSQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CosmosDbSqlApiSource",
"query": "SELECT c.BusinessEntityID, c.Name.First AS FirstName, c.Name.Middle AS MiddleName, c.Name.Last AS LastName, c.Suffix, c.EmailPromotion FROM c WHERE c.ModifiedDate > \"2009-01-01T00:00:00\"",
"preferredRegions": [
"East US"
]
},
"sink": {
"type": "<sink type>"
}
}
}
]
Als Methode beim Kopieren von Daten aus Azure Cosmos DB hat es sich bewährt, in der Kopieraktivität die Zuordnung anzugeben, sofern Sie nicht JSON-Dokumente im aktuellen Zustand exportieren möchten. Der Dienst Factory beachtet die Zuordnung, die Sie für die Aktivität angegeben haben. Wenn eine Zeile einen Wert für eine Spalte nicht enthält, wird für die Spalte ein NULL-Wert zurückgegeben. Wenn Sie keine Zuordnung angeben, leitet der Dienst das Schema anhand der ersten Zeile in den Daten ab. Wenn die erste Zeile nicht das vollständige Schema enthält, fehlen im Ergebnis der Aktivität einige Spalten.
Azure Cosmos DB for NoSQL als Senke
Legen Sie zum Kopieren von Daten in Azure Cosmos DB for NoSQL den Typ der Senke in der Kopieraktivität auf DocumentDbCollectionSink fest.
Die folgenden Eigenschaften werden im Abschnitt sink der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die Eigenschaft typeder Senke für die Kopieraktivität muss auf CosmosDbSqlApiSink festgelegt werden. | Ja |
| writeBehavior | Beschreibt, wie Daten in Azure Cosmos DB geschrieben werden. Zulässige Werte: insert und upsert. Das Verhalten von upsert besteht darin, das Dokument zu ersetzen, wenn ein Dokument mit der gleichen ID bereits vorhanden ist. Andernfalls wird das Dokument eingefügt. Hinweis: Der Dienst generiert automatisch eine ID für ein Dokument, wenn eine ID weder im Originaldokument noch durch eine Spaltenzuordnung angegeben wird. Dies bedeutet, dass Sie sicherstellen müssen, dass Ihr Dokument eine ID besitzt, damit upsert wie erwartet funktioniert. |
Nein (der Standardwert ist insert) |
| writeBatchSize | Der Dienst verwendet die Azure Cosmos DB-BulkExecutor-Bibliothek zum Schreiben von Daten in Azure Cosmos DB. Die Eigenschaft writeBatchSize steuert die Größe der von dem Dienst in der Bibliothek bereitgestellten Dokumente. Sie können versuchen, den Wert für writeBatchSize zu erhöhen, um die Leistung zu verbessern, oder den Wert verringern, falls Ihre Dokumente groß sind. Weitere Tipps finden Sie weiter unten. | Nein (der Standardwert ist 10.000) |
| disableMetricsCollection | Der Dienst sammelt Metriken wie Azure Cosmos DB-Anforderungseinheiten (RUs) für die Leistungsoptimierung von Kopiervorgängen und Empfehlungen. Wenn Sie sich wegen dieses Verhaltens Gedanken machen, geben Sie true an, um es zu deaktivieren. |
Nein (Standard = false) |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Ohne |
Tipp
Informationen zum Importieren von JSON-Dokumenten im aktuellen Zustand finden Sie unter Importieren oder Exportieren von JSON-Dokumenten. Informationen zum Kopieren aus tabellarisch strukturierten Daten finden Sie unter Migrieren von relationalen Datenbanken in Azure Cosmos DB.
Tipp
Azure Cosmos DB begrenzt die Größe der einzelnen Anforderungen auf 2 MB. Die Formel lautet: Anforderungsgröße = Einzeldokumentgröße * Schreibbatchgröße. Sollte ein Fehler mit dem Hinweis auftreten, dass die Anforderung zu groß ist, verringern Sie den writeBatchSize-Wert in der Kopiersenkenkonfiguration.
Wenn Sie eine Quelle vom Typ „DocumentDbCollectionSink“ verwenden, wird sie aus Gründen der Abwärtskompatibilität weiterhin unverändert unterstützt. Es wird empfohlen, in Zukunft das neue Modell zu verwenden, das umfangreichere Funktionen zum Kopieren von Daten aus Azure Cosmos DB enthält.
Beispiel
"activities":[
{
"name": "CopyToCosmosDBSQLAPI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "CosmosDbSqlApiSink",
"writeBehavior": "upsert"
}
}
}
]
Schemazuordnung
Informationen zum Kopieren von Daten aus Azure Cosmos DB in eine tabellarische Senke oder umgekehrt finden Sie unter Schemazuordnung.
Eigenschaften von Mapping Data Flow
Beim Transformieren von Daten im Zuordnungsdatenfluss können Sie Sammlungen in Azure Cosmos DB lesen und in diese schreiben. Weitere Informationen finden Sie unter Quellentransformation und Senkentransformation in Zuordnungsdatenflüssen.
Hinweis
Die serverlose Azure Cosmos DB-Instanz wird im Zuordnungsdatenfluss nicht unterstützt.
Quellentransformation
Spezifische Einstellungen für Azure Cosmos DB sind auf der Registerkarte Quellenoptionen der Quellentransformation verfügbar.
Systemspalten einschließen: Wenn für diese Einstellung TRUE gilt, werden id, _ts und andere Systemspalten in die Datenflussmetadaten von Azure Cosmos DB einbezogen. Beim Aktualisieren von Sammlungen ist es wichtig, dass diese eingeschlossen sind, damit Sie die vorhandene Zeilen-ID erfassen können.
Seitengröße: Die Anzahl der Dokumente pro Seite des Abfrageergebnisses. Der Standardwert ist „-1“, bei dem die dynamische Seite des Diensts mit bis zu 1000 verwendet wird.
Durchsatz: Legen Sie einen optionalen Wert für die Anzahl von RUs fest, die Sie für jede Ausführung dieses Datenflusses während des Lesevorgangs auf die Azure Cosmos DB-Sammlung anwenden möchten. Der Mindestwert ist 400.
Bevorzugte Region: Sie können die bevorzugten Leseregionen für diesen Prozess auswählen.
Änderungsfeed: Bei „true“ erhalten Sie Daten aus dem Azure Cosmos DB-Änderungsfeed. Hierbei handelt es sich um einen persistenten Datensatz von Änderungen an einem Container in der Reihenfolge, in der sie nach der letzten Ausführung automatisch vorgenommen wurden. Wenn Sie TRUE festlegen, legen Sie nicht gleichzeitig Abweichende Spaltentypen ableiten und Schemaabweichung zulassen auf TRUE fest. Weitere Informationen finden Sie unter Azure Cosmos DB-Änderungsfeed.
Von Anfang an beginnen: Bei „true“ erhalten Sie bei der ersten Ausführung die vollständigen Momentaufnahmedaten, gefolgt von der Erfassung geänderter Daten in den nächsten Ausführungen. Wenn FALSE, wird das anfängliche Laden bei der ersten Ausführung übersprungen, gefolgt von der Erfassung geänderter Daten in den nächsten Ausführungen. Die Einstellung wird an die Einstellung gleichen Namens in der Azure Cosmos DB-Referenz angepasst. Weitere Informationen finden Sie unter Azure Cosmos DB-Änderungsfeed.
Senkentransformation
Spezifische Einstellungen für Azure Cosmos DB sind auf der Registerkarte Einstellungen der Senkentransformation verfügbar.
Updatemethode: Bestimmt, welche Vorgänge für das Datenbankziel zulässig sind. Standardmäßig sind lediglich Einfügevorgänge zulässig. Wenn Sie für Zeilen Update-, Upsert- oder Löschvorgänge verwenden möchten, fügen Sie zunächst eine Transformation zur Änderung von Zeilen hinzu, um Zeilen für diese Aktionen zu kennzeichnen. Für Update-, Upsert- und Löschvorgänge muss mindestens eine Schlüsselspalte festgelegt werden, um die Zeile zu bestimmen, die geändert werden soll.
Collection action (Aktion für die Sammlung): Bestimmt, ob die Zielsammlung vor dem Schreibvorgang neu erstellt werden soll.
- Keine: Es wird keine Aktion an der Sammlung vorgenommen.
- Neu erstellen: Die Sammlung wird gelöscht und neu erstellt.
Batchgröße: Eine Ganzzahl zur Angabe der Anzahl der Objekte, die in jedem Batch in die Azure Cosmos DB-Sammlung geschrieben werden. Normalerweise reicht die Batchgröße als Startwert aus. Wenn Sie diesen Wert weiter optimieren möchten, beachten Sie Folgendes:
- Azure Cosmos DB begrenzt die Größe der einzelnen Anforderungen auf 2 MB. Die Formel lautet: „Anforderungsgröße = Einzeldokumentgröße * Batchgröße“. Wenn die Fehlermeldung „Anforderung ist zu groß“ angezeigt wird, verkleinern Sie den Wert für die Batchgröße.
- Je größer die Batchgröße, desto besser ist der Durchsatz von dem Dienst. Außerdem können Sie gleichzeitig sicherstellen, dass Sie genügend Anforderungseinheiten zuweisen, um ihre Arbeitsauslastung zu verbessern.
Partitionsschlüssel: Geben Sie eine Zeichenfolge ein, die den Partitionsschlüssel für Ihre Sammlung darstellt. Beispiel: /movies/title
Durchsatz: Legen Sie einen optionalen Wert für die Anzahl von RUs fest, die Sie für jede Ausführung dieses Datenflusses auf die Azure Cosmos DB-Sammlung anwenden möchten. Der Mindestwert ist 400.
Write throughput budget (Schreibdurchsatz): Eine ganze Zahl zur Darstellung der RUs, die Sie für diesen Datenfluss-Schreibvorgang zuordnen möchten, und nicht nur des Gesamtdurchsatzes, der der Sammlung zugeordnet wurde.
Hinweis
Um die RU-Nutzung einzuschränken, legen Sie den Durchsatz (autoscale) von Cosmos DB auf Manuell fest.
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Importieren und Exportieren von JSON-Dokumenten
Sie können diesen Azure Cosmos DB for NoSQL-Connector verwenden, um die folgenden Aufgaben auf einfache Weise zu erledigen:
- Kopieren von Dokumenten in ihrem jeweiligen Zustand zwischen zwei Azure Cosmos DB-Sammlungen.
- Importieren von JSON-Dokumenten aus verschiedenen Quellen in Azure Cosmos DB, z.B. aus Azure Blob Storage, Azure Data Lake Storage und anderen dateibasierten Speichern, die von dem Dienst unterstützt werden.
- Exportieren von JSON-Dokumenten aus einer Azure Cosmos DB-Sammlung in verschiedene dateibasierte Speicher.
So erhalten Sie eine vom Schema unabhängige Kopie:
- Aktivieren Sie bei Verwendung des Tools zum Kopieren von Daten die Option Unverändert in JSON-Dateien oder Azure Cosmos DB-Sammlung exportieren.
- Wenn Sie die Aktivität „Dokumenterstellung“ verwenden, wählen Sie das JSON-Format mit dem entsprechenden Dateispeicher für Quelle oder Senke aus.
Migrieren aus relationalen Datenbanken in Azure Cosmos DB
Beim Migrieren aus einer relationalen Datenbank (z. B. von SQL Server zu Azure Cosmos DB) kann die Kopieraktivität Tabellendaten aus der Quelle einfach zuordnen, um JSON-Dokumente in Azure Cosmos DB zu vereinfachen. In manchen Fällen sollten Sie das Datenmodell umgestalten, um es für Anwendungsfälle außerhalb von NoSQL zu optimieren. Weitere Informationen dazu finden Sie im Artikel Datenmodellierung in Azure Cosmos DB. Sie können die Daten beispielsweise denormalisieren, indem Sie alle verbundenen untergeordneten Elemente innerhalb eines JSON-Dokuments einbetten. In diesem Artikel finden Sie weitere Informationen für so einen Fall sowie eine exemplarische Vorgehensweise, wie Sie dieses Szenario mithilfe der Kopieraktivität umsetzen.
Azure Cosmos DB-Änderungsfeed
Azure Data Factory können Daten aus dem Azure Cosmos DB-Änderungsfeed durch Aktivieren in der Transformation für Zuordnungsdatenflussquellen erhalten. Mit dieser Connectoroption können Sie Änderungsfeeds lesen und Transformationen anwenden, bevor Sie transformierte Daten in Zieldatensets Ihrer Wahl laden. Sie müssen Azure-Funktionen nicht verwenden, um den Änderungsfeed zu lesen und dann benutzerdefinierte Transformationen zu schreiben. Sie können diese Option verwenden, um Daten aus einem Container in einen anderen zu verschieben, Änderungsfeed-gesteuerte Materialsichten für den Zweck vorzubereiten oder die Containersicherung oder -wiederherstellung basierend auf dem Änderungsfeed zu automatisieren und viele weitere Anwendungsfälle mithilfe der visuellen Drag & Drop-Funktion von Azure Data Factory.
Stellen Sie sicher, dass Sie die Pipeline und den Aktivitätsnamen unverändert lassen, damit der Prüfpunkt von ADF aufgezeichnet werden kann, damit Sie geänderte Daten aus der letzten Ausführung automatisch erhalten. Wenn Sie ihren Pipelinenamen oder Aktivitätsnamen ändern, wird der Prüfpunkt zurückgesetzt, was dazu führt, dass Sie bei der nächsten Ausführung von Anfang an beginnen oder Änderungen von jetzt erhalten.
Wenn Sie die Pipeline debuggen, funktioniert dieses Feature genauso. Beachten Sie, dass der Prüfpunkt zurückgesetzt wird, wenn Sie Ihren Browser während der Debug-Ausfürung aktualisieren. Wenn Sie mit dem Pipelineergebnis der Debug-Ausführung zufrieden sind, können Sie die Pipeline veröffentlichen und auslösen. Wenn Sie ihre veröffentlichte Pipeline zum ersten Mal auslösen, wird sie automatisch von Anfang an neu gestartet oder erhält von nun an Änderungen.
Im Abschnitt „Überwachung“ haben Sie immer die Möglichkeit, eine Pipeline erneut ausführen. Dabei werden die geänderten Daten immer vom vorherigen Prüfpunkt des ausgewählten Pipelinelaufs erfasst.
Darüber hinaus unterstützt der Azure Cosmos DB-Analysespeicher jetzt Change Data Capture (CDC) für die Azure Cosmos DB-API für NoSQL und die Azure Cosmos DB-API für Mongo DB (öffentliche Vorschau). Mit dem Azure Cosmos DB-Analysespeicher können Sie einen kontinuierlichen und inkrementellen Feed geänderter (eingefügter, aktualisierter und gelöschter) Daten aus dem Analysespeicher effizient nutzen.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die diese Kopieraktivität als Quellen und Senken unterstützt, finden Sie unter Unterstützte Datenspeicher.