Kopieren von Daten aus Azure Data Lake Storage Gen1 in Gen2 mit Azure Data Factory
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Azure Data Lake Storage Gen2 bietet eine Reihe von Funktionen für die Big Data-Analyse, die auf Azure Blob Storage aufbaut. So haben Sie eine Schnittstelle zu Ihren Daten sowohl über das Dateisystem als auch den Objektspeicher.
Wenn Sie zurzeit Azure Data Lake Storage Gen1 verwenden, können Sie Azure Data Lake Storage Gen2 bewerten, indem Sie mithilfe von Azure Data Factory Daten aus Data Lake Storage Gen1 in Gen2 kopieren.
Azure Data Factory ist ein vollständig verwalteter, cloudbasierter Datenintegrationsdienst. Mithilfe dieses Diensts können Sie den Lake mit Daten aus zahlreichen lokalen und cloudbasierten Datenspeichern füllen und Zeit beim Erstellen von Analyselösungen sparen. Eine Liste der unterstützten Connectors finden Sie in der Tabelle Unterstützte Datenspeicher.
Azure Data Factory bietet eine Lösung zur horizontalen Skalierung und Verschiebung verwalteter Daten. Aufgrund der horizontal skalierbaren Architektur von Data Factory können Daten mit hohem Durchsatz erfasst werden. Weitere Informationen finden Sie unter Leistung der Kopieraktivität.
In diesem Artikel erfahren Sie, wie Sie das Tool zum Kopieren von Daten in Data Factory zum Kopieren von Daten aus Azure Data Lake Storage Gen1 in Azure Data Lake Storage Gen2 verwenden. Sie können ähnliche Schritte zum Kopieren von Daten aus anderen Typen von Datenspeichern ausführen.
Voraussetzungen
- Ein Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Sie müssen ein Azure Data Lake Storage Gen1-Konto auswählen, das Daten enthält.
- Azure Storage-Konto mit aktiviertem Data Lake Storage Gen2. Erstellen Sie ein Speicherkonto, wenn Sie noch keines besitzen.
Erstellen einer Data Factory
Wenn Sie Ihre Data Factory noch nicht erstellt haben, befolgen Sie die Schritte im Schnellstart: Erstellen einer Data Factory mithilfe des Azure-Portals und Azure Data Factory Studio, um eine zu erstellen. Navigieren Sie nach dem Erstellen zur Data Factory im Azure-Portal.

Klicken Sie auf der Kachel Open Azure Data Factory Studio auf Öffnen, um die Datenintegrationsanwendung in einer separaten Registerkarte zu starten.
Laden von Daten in Azure Data Lake Storage Gen2
Wählen Sie auf der Homepage die Kachel Erfassung aus, um das Tool zum Kopieren von Daten zu starten.
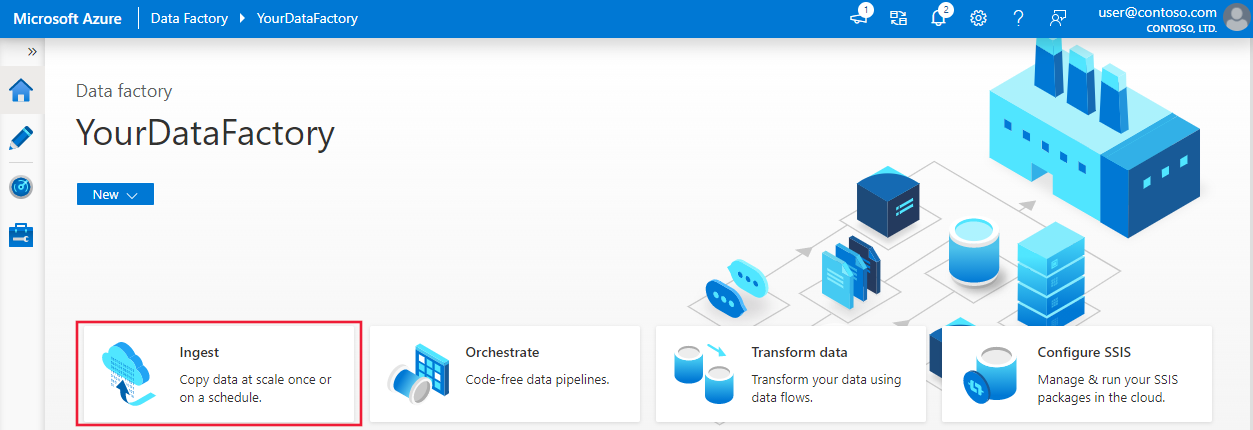
Wählen Sie auf der Seite Eigenschaften die Option Integrierte Kopieraufgabe unter dem Aufgabentyp aus. Wählen Sie nun unter Aufgabenintervall oder Aufgabenzeitplan die Option Jetzt einmal ausführen und dann Weiter aus.
Klicken Sie auf der Seite Quelldatenspeicher auf + Neue Verbindung.
Wählen Sie im Connectorkatalog Azure Data Lake Storage Gen1 aus, und klicken Sie auf Weiter.
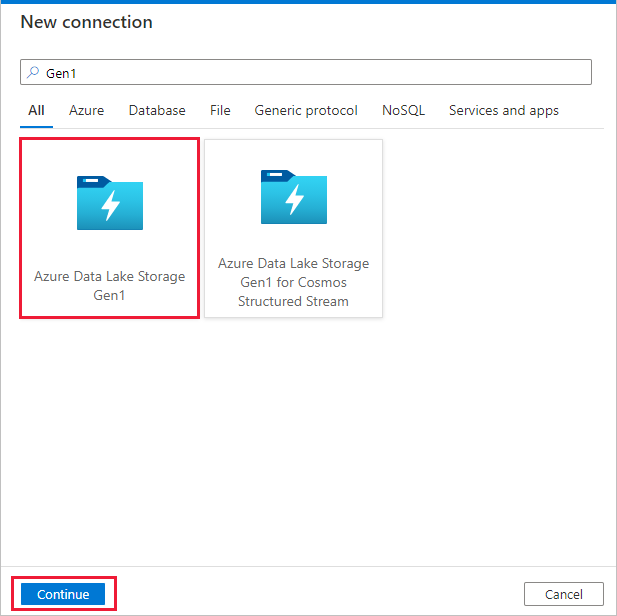
Führen Sie auf der Seite Neue Verbindung (Azure Data Lake Storage Gen1) die folgenden Schritte aus:
- Wählen Sie Ihr Data Lake Storage Gen1 für den Kontonamen aus, und geben Sie den Mandanten an oder überprüfen Sie den angegebenen Mandanten.
- Wählen Sie Verbindung testen aus, um die Einstellungen zu überprüfen. Klicken Sie anschließend auf Erstellen.
Wichtig
In dieser exemplarischen Vorgehensweise verwenden Sie eine verwaltete Identität für Azure-Ressourcen, um Azure Data Lake Storage Gen1 zu authentifizieren. Um der verwalteten Identität die entsprechenden Berechtigungen in Azure Data Lake Storage Gen1 zu erteilen, befolgen Sie diese Anweisungen.
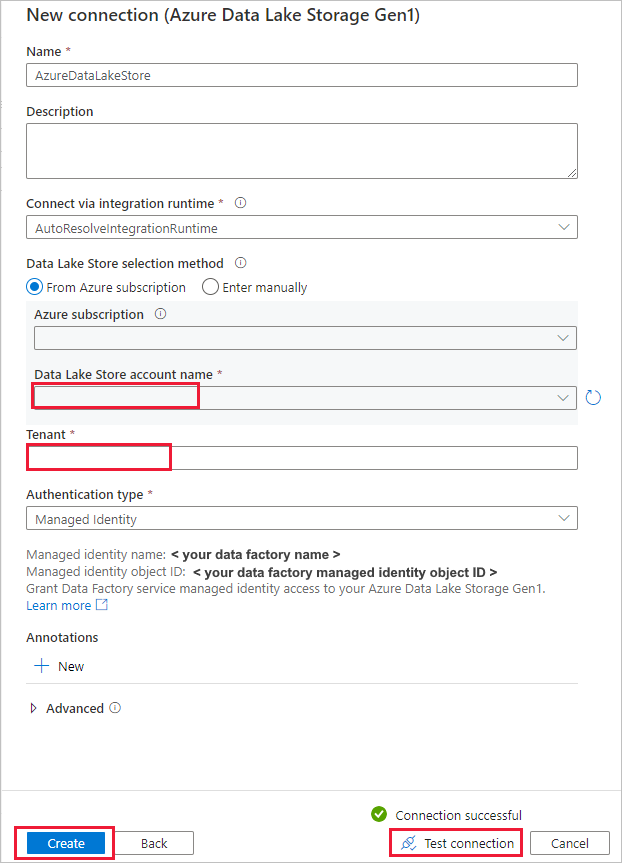
Führen Sie auf der Seite Quelldatenspeicher die folgenden Schritte aus.
- Wählen Sie im Abschnitt Verbindung die neu erstellte Verbindung aus.
- Navigieren Sie unter Datei oder Ordner zu dem Ordner und der Datei, die Sie kopieren möchten. Wählen Sie den Ordner oder die Datei und dann OK aus.
- Geben Sie das Kopierverhalten an, indem Sie die Optionen Rekursiv und Binärkopie auswählen. Wählen Sie Weiter aus.
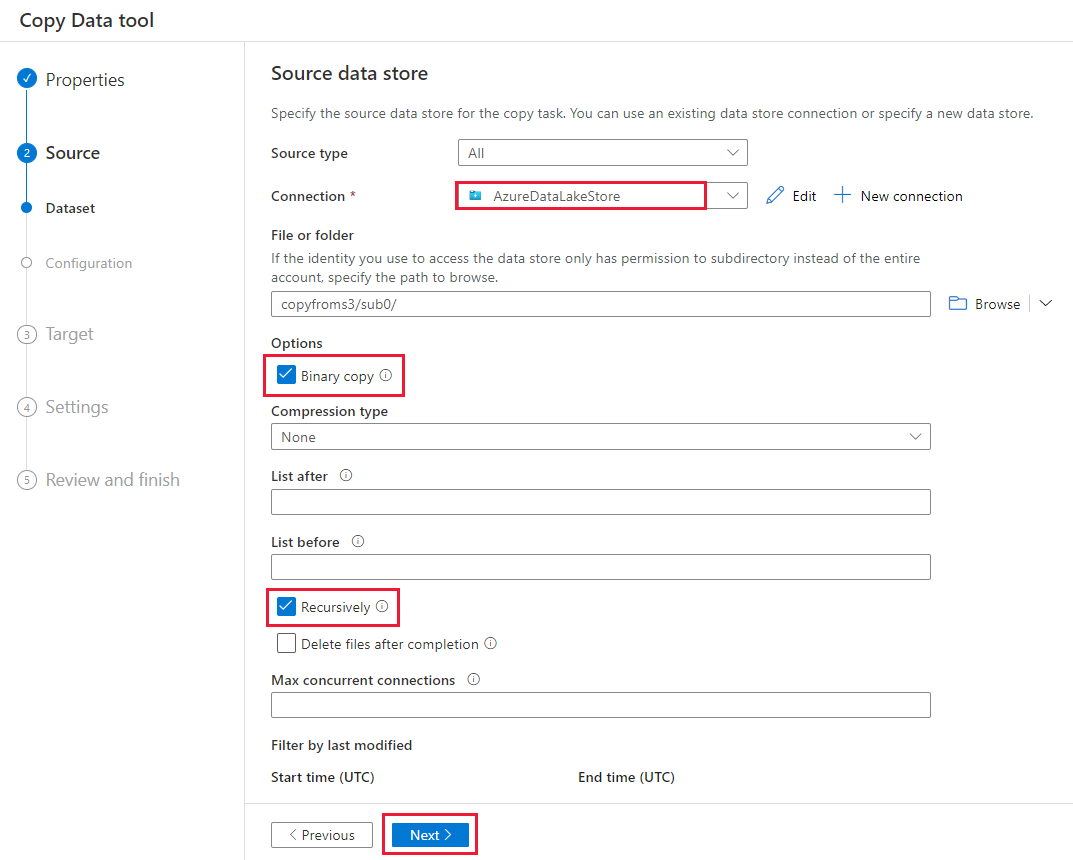
Wählen Sie auf der Seite Zieldatenspeicher die Optionen + Neue Verbindung>Azure Data Lake Storage Gen2>Weiter aus.
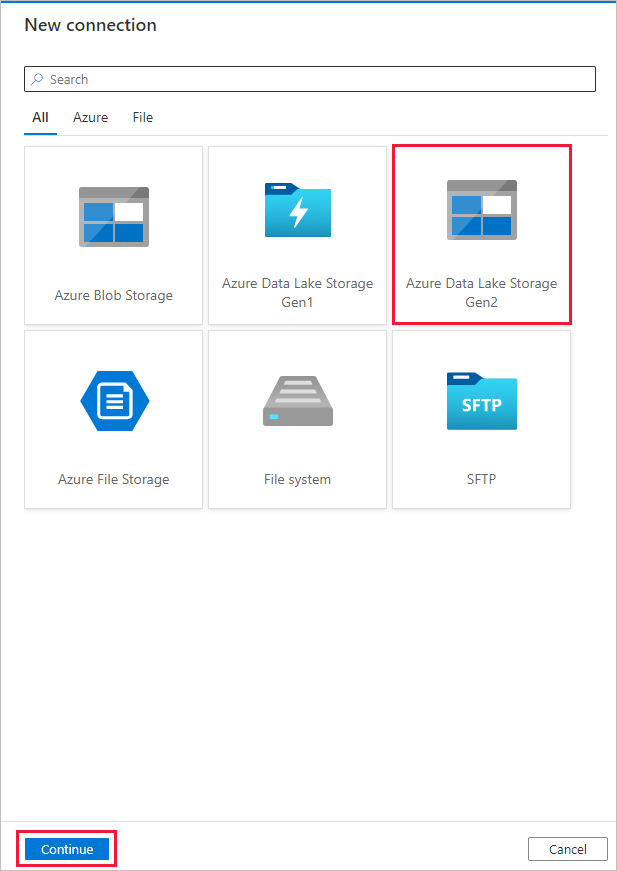
Führen Sie auf der Seite Neue Verbindung (Azure Data Lake Storage Gen2) die folgenden Schritte aus:
- Wählen Sie in der Dropdownliste Speicherkontoname das Data Lake Storage Gen2-fähige Konto aus.
- Wählen Sie Erstellen aus, um die Verbindung zu erstellen.
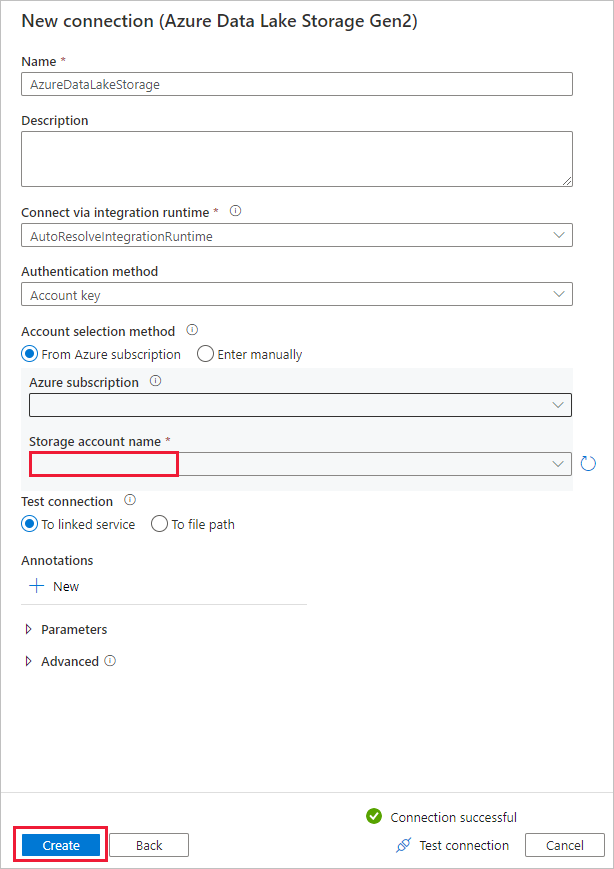
Führen Sie auf der Seite Zieldatenspeicher die folgenden Schritte aus.
- Wählen Sie im Block Verbindung die neu erstellte Verbindung aus.
- Geben Sie dann unter Ordnerpfad die Zeichenfolge copyfromadlsgen1 als Namen für den Ausgabeordner ein, und wählen Sie dann Weiter aus. Data Factory erstellt während des Kopiervorgangs das entsprechende Dateisystem und die Unterordner für Azure Data Lake Storage Gen2, wenn diese noch nicht vorhanden sind.
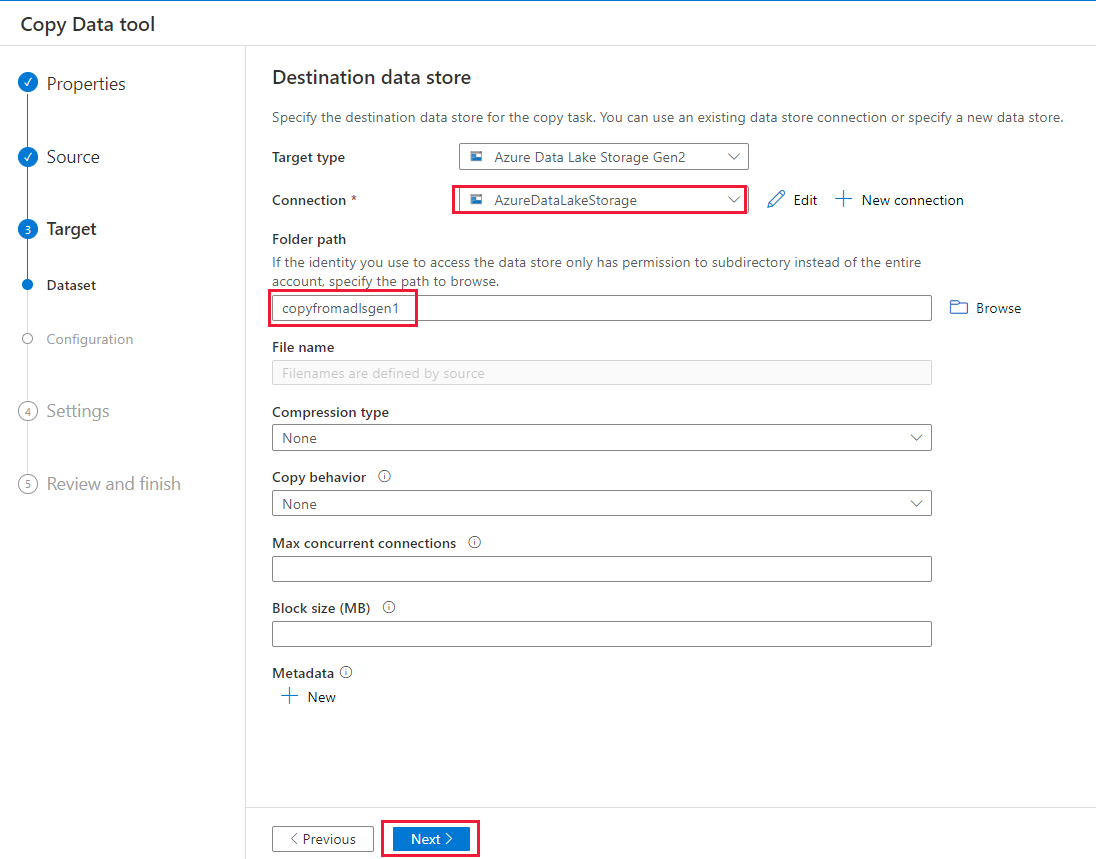
Geben Sie auf der Seite Einstellungen im Feld Aufgabenname den Namen CopyFromADLSGen1ToGen2 ein und wählen Sie dann Weiter aus, um die Standardeinstellungen zu übernehmen.
Überprüfen Sie auf der Seite Zusammenfassung die Einstellungen, und klicken Sie dann auf Weiter.
Klicken Sie auf der Seite Bereitstellung auf Überwachen, um die Pipeline zu überwachen.
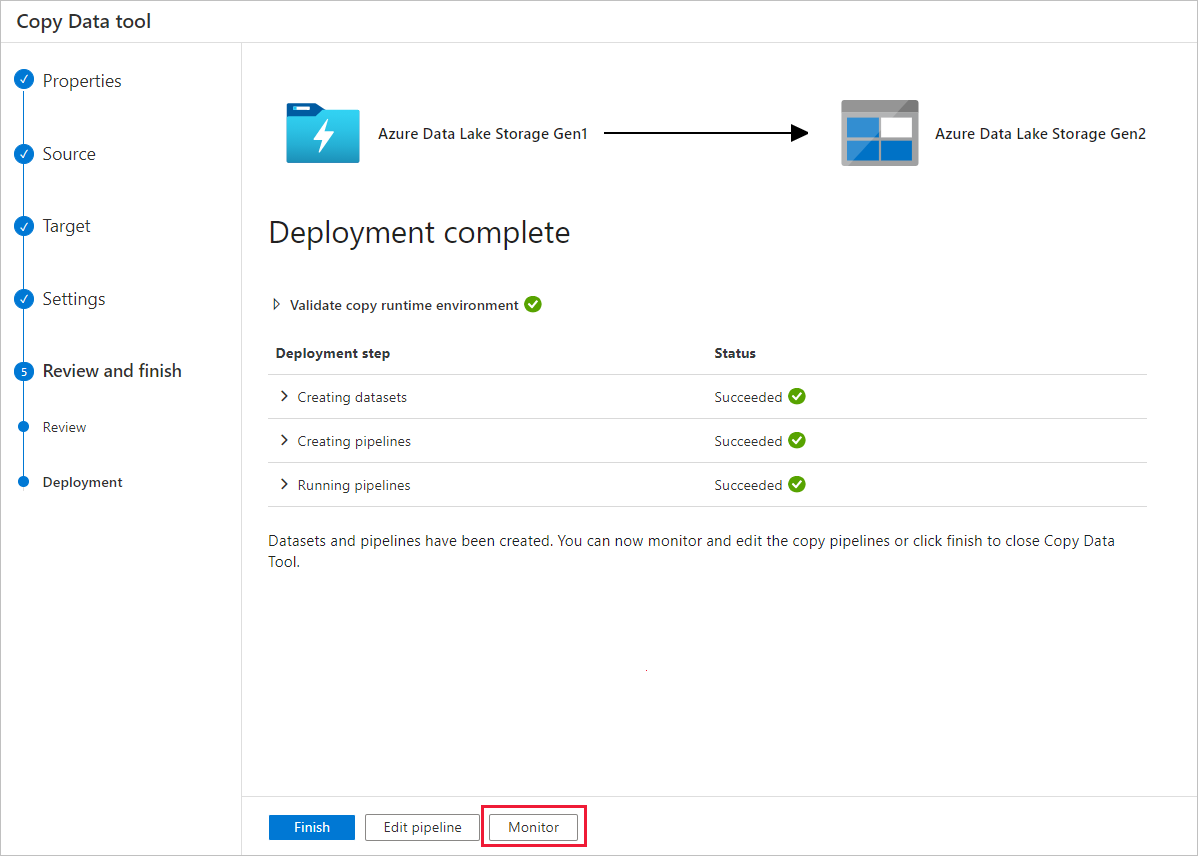
Beachten Sie, dass die Registerkarte Überwachen auf der linken Seite automatisch ausgewählt ist. In der Spalte Pipelinename werden Links zum Anzeigen von Aktivitätsausführungsdetails und zum erneuten Ausführen der Pipeline angezeigt.
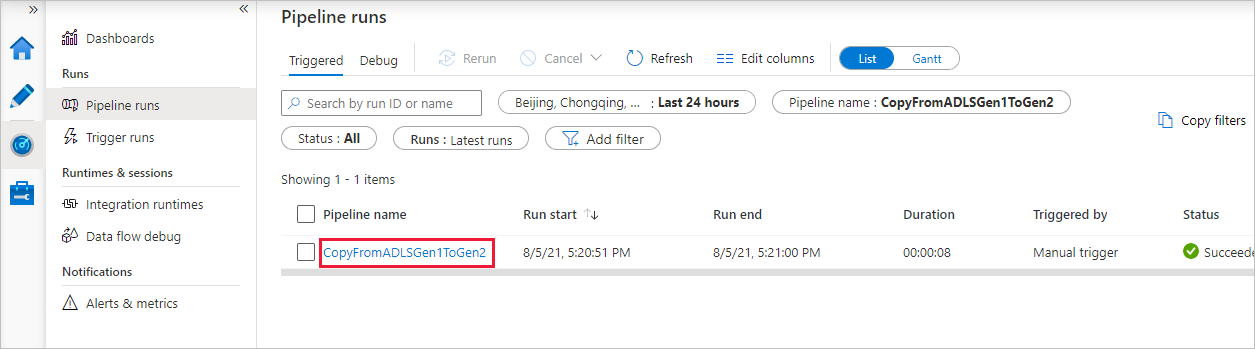
Wenn Sie die der Pipelineausführung zugeordneten Aktivitätsausführungen anzeigen möchten, wählen Sie den Link in der Spalte Pipelinename aus. Da die Pipeline nur eine Aktivität (Copy-Aktivität) enthält, wird nur ein Eintrag angezeigt. Wählen Sie im Breadcrumbmenü oben den Link Alle Pipelineausführungen aus, um zur Ansicht „Pipelineausführungen“ zurückzukehren. Klicken Sie zum Aktualisieren der Liste auf Aktualisieren.
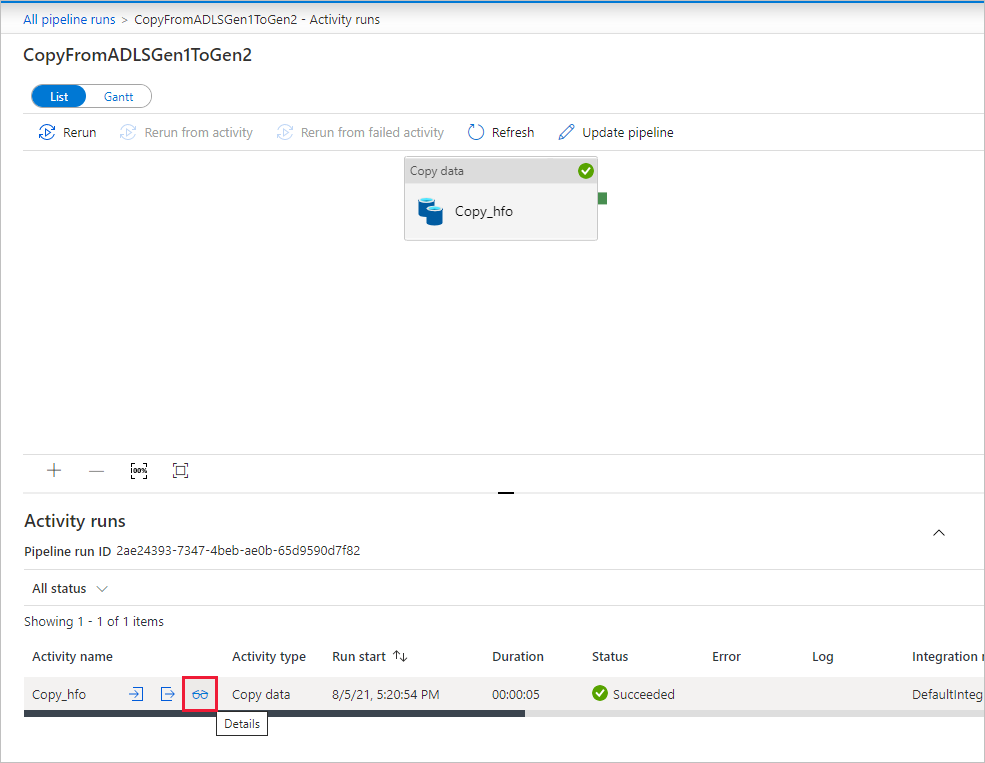
Zum Überwachen der Ausführungsdetails jeder Kopieraktivität klicken Sie in der Aktivitätsüberwachungsansicht unter der Spalte Aktivitätsname auf den Link Details (Brillensymbol). Sie können Details wie die Menge der Daten, die aus der Quelle in die Senke kopiert wurden, den Datendurchsatz, die Ausführungsschritte mit entsprechender Dauer sowie die verwendeten Konfigurationen überwachen.
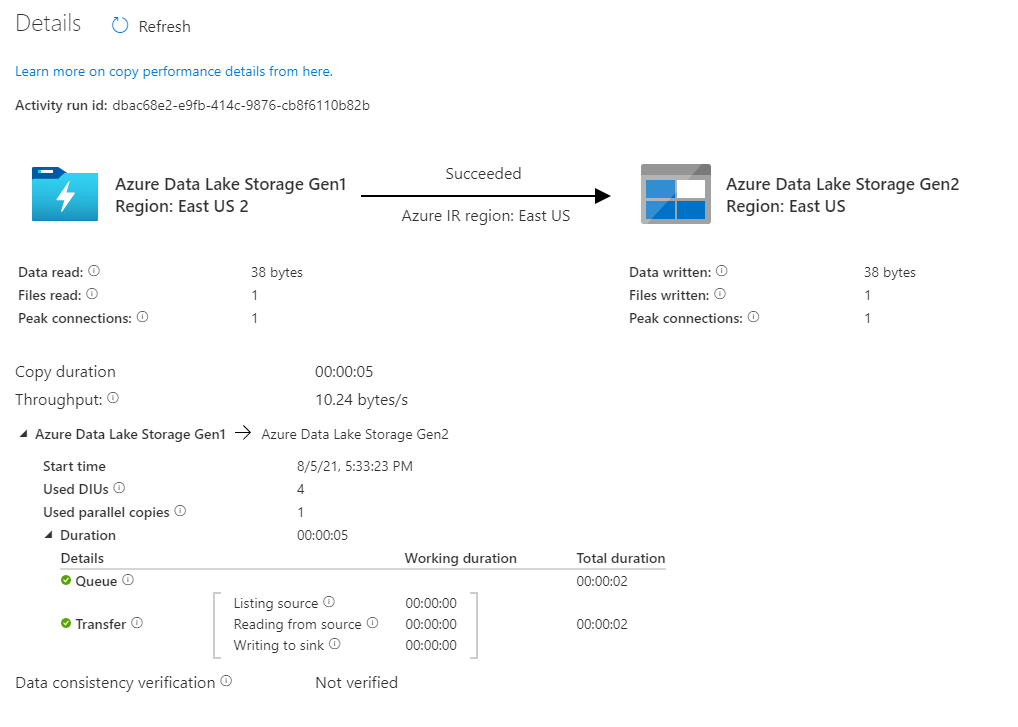
Stellen Sie sicher, dass die Daten in Ihr Azure Data Lake Storage Gen2-Konto kopiert werden.
Bewährte Methoden
Informationen zum allgemeinen Upgrade von Azure Data Lake Storage Gen1 auf Azure Data Lake Storage Gen2 finden Sie unter Upgrade von Big Data-Analyselösungen von Azure Data Lake Storage Gen1 auf Azure Data Lake Storage Gen2. In den folgenden Abschnitten werden bewährte Methoden für die Verwendung von Data Factory für ein Datenupgrade von Data Lake Storage Gen1 auf Data Lake Storage Gen2 vorgestellt.
Migration der Daten der Anfangsmomentaufnahme
Leistung
ADF verfügt über eine serverlose Architektur, die Parallelität auf unterschiedlichen Ebenen ermöglicht. Entwickler können dann Pipelines erstellen, um Ihre Netzwerkbandbreite vollständig zu nutzen – sowie IOPS und Bandbreite des Speichers, um den Durchsatz für die Datenverschiebung Ihrer Umgebung zu maximieren.
Kunden haben erfolgreiche Migrationen von Daten im Petabyte-Bereich durchgeführt, bei denen mit einem dauerhaften Durchsatz von mindestens 2 GBit/s Hunderte Millionen von Dateien aus Data Lake Storage Gen1 in Gen2 verschoben wurden.
Sie können höhere Geschwindigkeiten bei der Datenverschiebung erzielen, indem Sie verschiedene Parallelitätsebenen anwenden:
- Für eine einzelne Kopieraktivität können skalierbare Computeressourcen genutzt werden: Bei Verwendung der Azure Integration Runtime können Sie bis zu 256 Datenintegrationseinheiten (Data Integration Units, DIUs) serverlos für jede Kopieraktivität angeben. Wenn Sie die selbstgehostete Integration Runtime nutzen, können Sie den Computer manuell hochskalieren oder das Aufskalieren auf mehrere Computer (bis zu 4 Knoten) durchführen. Bei einer einzelnen Kopieraktivität wird die Dateigruppe dann auf alle Knoten verteilt.
- Für eine Kopieraktivität werden mehrere Threads genutzt, um für den Datenspeicher Lese- und Schreibvorgänge durchzuführen.
- Mit der ADF-Ablaufsteuerung können mehrere Kopieraktivitäten parallel gestartet werden, z. B. per foreach-Schleife.
Datenpartitionen
Wenn die Gesamtdatengröße in Data Lake Storage Gen1 kleiner als 10 TB und die Anzahl der Dateien kleiner als 1 Million ist, können Sie alle Daten in einer einzigen Kopieraktivitätsausführung kopieren. Wenn Sie eine größere Datenmenge zu kopieren haben oder die Flexibilität wünschen, die Datenmigration in Batches zu verwalten und diese jeweils innerhalb eines bestimmten Zeitraums abzuschließen, partitionieren Sie die Daten. Durch die Partitionierung verringert sich auch das Risiko unerwarteter Probleme.
Zum Partitionieren der Dateien verwenden Sie name range- listAfter/listBefore in der Eigenschaft der Kopieraktivität. Jede Kopieraktivität kann so konfiguriert werden, dass jeweils eine Partition kopiert wird, sodass mehrere Kopieraktivitäten parallel Daten aus einem einzelnen Data Lake Storage Gen1-Konto kopieren können.
Ratenbegrenzung
Die bewährte Methode besteht darin, mit einem repräsentativen Beispieldataset einen Proof of Concept-Vorgang in Bezug auf die Leistung durchzuführen, damit Sie eine geeignete Partitionsgröße ermitteln können.
Beginnen Sie mit einer einzelnen Partition und einer einzelnen Kopieraktivität mit der DIU-Standardeinstellung. Für Parallele Kopie wird immer die Festlegung auf leer (Standard) empfohlen. Wenn der Kopierdurchsatz bei Ihnen nicht zufriedenstellend ist, identifizieren und beheben Sie die Leistungsengpässe, indem Sie die Schritte zur Optimierung der Leistung ausführen.
Erhöhen Sie die DIU-Einstellung nach und nach, bis Sie das Bandbreitenlimit Ihres Netzwerks oder das IOPS-/Bandbreitenlimit der Datenspeicher erreichen bzw. bis die maximal zulässigen 256 DIUs pro Kopieraktivität erreicht sind.
Wenn Sie die Leistung bei einer einzelnen Kopieraktivität maximiert haben, die Durchsatzobergrenzen Ihrer Umgebung jedoch noch nicht erreicht haben, können Sie mehrere Kopieraktivitäten parallel ausführen.
Wenn bei Überwachung der Kopieraktivität eine erhebliche Anzahl von Drosselungsfehlern angezeigt wird, weist dies darauf hin, dass Sie das Kapazitätslimit Ihres Speicherkontos erreicht haben. ADF versucht automatisch, jeden Drosselungsfehler zu überwinden, um sicherzustellen, dass keine Daten verloren gehen, aber zu viele Wiederholungen können auch Ihren Kopierdurchsatz beeinträchtigen. In diesem Fall wird empfohlen, die Anzahl der parallel ausgeführten Kopieraktivitäten zu reduzieren, um eine erhebliche Anzahl von Drosselungsfehlern zu vermeiden. Wenn Sie eine einzelne Kopieraktivität zum Kopieren von Daten verwendet haben, wird empfohlen, die DIU zu reduzieren.
Migration von Deltadaten
Sie können mehrere Methoden verwenden, um nur die neuen oder aktualisierten Dateien aus Data Lake Storage Gen1 zu laden:
- Laden Sie neue oder aktualisierte Dateien nach zeitpartitioniertem Ordner- oder Dateinamen. Ein Beispiel hierfür ist „/2019/05/13/*“.
- Laden Sie neue oder aktualisierte Dateien nach „LastModifiedDate“. Wenn Sie große Mengen von Dateien kopieren, erstellen Sie zuerst Partitionen, um einen geringen Kopierdurchsatz zu vermeiden, der sich aus der Überprüfung des gesamten Data Lake Storage Gen1-Kontos durch eine einzelne Kopieraktivität zum Identifizieren neuer Dateien ergeben kann.
- Identifizieren Sie neue oder aktualisierte Dateien durch ein Tool bzw. eine Lösung von Drittanbietern. Übergeben Sie dann den Datei- oder Ordnernamen per Parameter, Tabelle oder Datei an die Data Factory-Pipeline.
Die richtige Häufigkeit für das inkrementelle Laden hängt von der Gesamtzahl der Dateien in Azure Data Lake Storage Gen1 und dem Volumen der neuen oder aktualisierten Dateien ab, die jedes Mal geladen werden müssen.
Netzwerksicherheit
Standardmäßig werden Daten mit ADF von Azure Data Lake Storage Gen1 in Gen2 übertragen, indem eine verschlüsselte Verbindung per HTTPS-Protokoll genutzt wird. HTTPS ermöglicht die Datenverschlüsselung während der Übertragung und verhindert Abhör- und Man-in-the-Middle-Angriffe.
Falls Sie nicht möchten, dass Daten über das öffentliche Internet übertragen werden, können Sie eine bessere Sicherheit auch erzielen, indem Sie Daten über ein privates Netzwerk übertragen.
Beibehalten von ACLs
Wenn Sie die Zugriffssteuerungslisten zusammen mit Datendateien beim Upgrade von Data Lake Storage Gen1 auf Gen2 replizieren möchten, finden Sie weitere Informationen unter Bewahren von Zugriffssteuerungslisten von Data Lake Storage Gen1.
Resilienz
Bei Ausführung einer einzelnen Kopieraktivität verfügt ADF über einen integrierten Wiederholungsmechanismus, damit in den Datenspeichern oder im zugrunde liegenden Netzwerk eine bestimmte Ebene vorübergehender Fehler verarbeitet werden kann. Wenn Sie mehr als 10 TB Daten migrieren, sollten Sie sie partitionieren, um das Risiko unerwarteter Probleme zu verringern.
Sie können auch die Fehlertoleranz in der Kopieraktivität aktivieren, um die vordefinierten Fehler zu überspringen. Die Datenkonsistenzprüfung in der Kopieraktivität kann auch aktiviert werden, um eine zusätzliche Prüfung durchzuführen. Damit stellen Sie sicher, dass die Daten nicht nur erfolgreich aus dem Quell- in den Zielspeicher kopiert werden, sondern auch, dass überprüft wird, ob sie zwischen Quell- und Zielspeicher konsistent sind.
Berechtigungen
In Data Factory unterstützt der Azure Data Lake Storage Gen1-Connector den Dienstprinzipal und die verwaltete Identität für Azure-Ressourcenauthentifizierungen. Der Azure Data Lake Storage Gen2-Connector unterstützt den Kontoschlüssel, den Dienstprinzipal und die verwaltete Identität für Azure-Ressourcenauthentifizierungen. Damit Data Factory in der Lage ist, nach Bedarf zu navigieren und alle benötigten Dateien oder Zugriffssteuerungslisten (ACLs) zu kopieren, gewähren Sie dem von Ihnen bereitgestellten Konto ausreichende Berechtigungen für den Zugriff, das Lesen oder das Schreiben aller Dateien und das Festlegen von ACLs. Sie sollten dem Konto während des Migrationszeitraums eine Rolle als Superuser oder Besitzer zuweisen und die Berechtigungen mit erhöhten Rechten entfernen, nachdem die Migration abgeschlossen ist.
Zugehöriger Inhalt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für