Erweiterte SAP CDC-Themen
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Erfahren Sie mehr über erweiterte Themen für den SAP CDC-Connector wie beispielsweise metadatengesteuerte Datenintegration, Debuggen und vieles mehr.
Parametrisieren eines SAP CDC-Zuordnungsdatenflusses
Eine der Hauptstärken von Pipelines und Zuordnungsdatenflüssen in Azure Data Factory und Azure Synapse Analytics ist die Unterstützung für die metadatengesteuerte Datenintegration. Mit diesem Feature ist es möglich, eine einzelne (oder wenige) parametrisierte Pipeline zu entwerfen, die für die Integration von potenziell Hunderten oder sogar Tausenden von Quellen verwendet werden kann. Der SAP CDC-Connector wurde unter Berücksichtigung dieses Prinzips entwickelt: Alle relevanten Eigenschaften, unabhängig davon, ob es sich um das Quellobjekt, den Ausführungsmodus, die Schlüsselspalten usw. handelt, können über Parameter bereitgestellt werden, um die Flexibilität und das Wiederverwendungspotenzial von SAP CDC-Zuordnungsdatenflüssen zu maximieren.
Um grundlegende Konzepte der Parametrisierung von Zuordnungsdatenflüssen zu verstehen, lesen Sie Parametrisieren von Zuordnungsdatenflüssen.
Im Vorlagenkatalog von Azure Data Factory und Azure Synapse Analytics finden Sie eine Vorlagenpipeline und einen Datenfluss, in dem die Parametrisierung der SAP CDC-Datenerfassung veranschaulicht wird.
Parametrisieren von Quelle und Ausführungsmodus
Zuordnungsdatenflüsse erfordern nicht unbedingt ein Datasetartefakt: Sowohl Quell- als auch Senketransformationen bieten einen Quelltyp (oder Senketyp) inline an. In diesem Fall können alle Quelleigenschaften, die sonst in einem ADF-Dataset definiert sind, in den Quelloptionen der Quelltransformation (oder der Registerkarte Einstellungen der Senketransformation) konfiguriert werden. Die Verwendung eines Inlinedatasets bietet eine bessere Übersicht und vereinfacht die Parametrisierung eines Zuordnungsdatenflusses, da die vollständige Konfiguration der Quelle (oder Senke) an einem zentralen Ort verwaltet wird.
Für SAP CDC finden Sie die Eigenschaften, die am häufigsten über Parameter festgelegt werden, in den Registerkarten Quelloptionen und Optimieren. Wenn der QuelltypInline ist, können die folgenden Eigenschaften in den Quelloptionen parametrisiert werden.
- ODP-Kontext: gültige Parameterwerte sind
- ABAP_CDS für ABAP Core Data Services-Views
- BW für SAP BW- oder SAP BW/4HANA-InfoProviders
- HANA für SAP HANA Information-Views
- SAPI für SAP DataSources/Extractors
- wenn SAP Landscape Transformation Replication Server (SLT) als Quelle verwendet wird, lautet der ODP-Kontextname SLT~<Queue Alias>. Der Wert für Queue Alias finden Sie unter Verwaltungsdaten in der SLT-Konfiguration im SLT-Cockpit (SAP Transaktions-LTRC).
- ODP_SELF und RANDOM sind ODP-Kontexte, die für technische Validierung und Tests verwendet werden, und sie sind in der Regel nicht relevant.
- ODP-Name: Geben Sie den ODP-Namen an, aus dem Sie Daten extrahieren wollen.
- Ausführungsmodus: gültige Parameterwerte sind
- fullAndIncrementalLoad für Vollständig bei der ersten Ausführung, dann inkrementell, wodurch ein Change Data Capture-Prozess initiiert und eine aktuelle vollständige Datenmomentaufnahme extrahiert wird
- fullLoad für Vollständig bei jeder Ausführung, wodurch eine aktuelle vollständige Datenmomentaufnahme extrahiert wird, ohne einen Change Data Capture-Prozess zu initiieren.
- incrementalLoad für nur für inkrementelle Änderungen, wodurch ein Change Data Capture-Prozess initiiert wird, ohne eine aktuelle vollständige Momentaufnahme zu extrahieren.
- Schlüsselspalten: Schlüsselspalten werden als Array von Zeichenfolgen (mit doppeltem Anführungszeichen) bereitgestellt. Wenn Sie beispielsweise mit der SAP-Tabelle VBAP (Verkaufsauftragspositionen) arbeiten, müsste die Schlüsseldefinition [„VBELN“, „POSNR“] lauten (oder [„MANDT“,“VBELN“,“POSNR“], falls auch das Clientfeld berücksichtigt wird).
Parametrisieren der Filterbedingungen für die Quellpartitionierung
Auf der Registerkarte Optimieren kann ein Quellpartitionierungsschema (siehe Optimieren der Leistung für vollständige oder anfängliche Lasten) über Parameter definiert werden. In der Regel sind zwei Schritte erforderlich:
- Definieren Sie einen Parameter für das Quellpartitionierungsschema auf Ebene Pipeline.
- Erfassen Sie den Partitionierungsparameter in den Zuordnungsdatenfluss.
JSON-Format eines Partitionierungsschemas
Das Format in Schritt 1 folgt dem JSON-Standard, das aus einem Array von Partitionsdefinitionen besteht, von denen jedes selbst ein Array einzelner Filterbedingungen ist. Diese Bedingungen selbst sind JSON-Objekte mit einer Struktur, die an sogenannten Auswahloptionen in SAP ausgerichtet ist. Tatsächlich ist das vom SAP ODP-Framework erforderliche Format im Grunde das gleiche wie dynamische DTP-Filter in SAP BW:
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
Beispiel:
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
entspricht einer SQL WHERE-Klausel ... WHERE "VBELN" = '0000001000', oder
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
entspricht einer SQL WHERE-Klausel ... WHERE "VBELN" BETWEEN '0000000000' AND '0000001000'
Eine JSON-Definition eines Partitionierungsschemas, das zwei Partitionen enthält, sieht daher wie folgt aus
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
wobei die erste Partition die Geschäftsjahre (GJAHR) 2011 bis 2015 und die zweite Partition die Geschäftsjahre 2016 bis 2020 enthält.
Hinweis
Azure Data Factory führt keine Überprüfungen dieser Bedingungen durch. Beispielsweise liegt es in der Verantwortung des Benutzers, sicherzustellen, dass sich Partitionsbedingungen nicht überlappen.
Partitionsbedingungen können komplexer sein und selber aus mehreren elementaren Filterbedingungen bestehen. Es gibt keine logischen Konjunktionen, die explizit definieren, wie mehrere elementare Bedingungen innerhalb einer Partition kombiniert werden können. Die implizite Definition in SAP lautet wie folgt (nur für einschließende Auswahlen, d. h. „Vorzeichen“: „I“ – für ausschließende):
- einschließende Bedingungen („Vorzeichen“: „I“) für denselben Feldnamen werden mit OR kombiniert (setzen Sie geistig Klammern um die resultierende Bedingung)
- ausschließende Bedingungen („Vorzeichen“: „E“) für denselben Feldnamen werden mit OR kombiniert (setzen Sie wiederum geistig Klammern um die resultierende Bedingung)
- die sich ergebenden Bedingungen der Schritte 1 und 2 sind
- kombiniert mit AND für einschließende Bedingungen,
- kombiniert mit AND NOT für ausschließende Bedingungen.
Beispiel: Die Partitionsbedingung
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2020", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" }
]
entspricht einer SQL WHERE-Klausel ... WHERE ("BUKRS" = '1000') AND ("GJAHR" BETWEEN '2020' AND '2025') AND NOT ("GJAHR" = '2023')
Hinweis
Stellen Sie sicher, dass Sie das interne SAP-Format für die tiefen und hohen Werte verwenden, führende Nullen einschließen und Kalenderdaten als Zeichenfolge mit acht Zeichen mit dem Format „JJJJMMDD“ ausdrücken.
Erfassen des Partitionierungsparameters in den Zuordnungsdatenfluss
Um das Partitionierungsschema in einem Zuordnungsdatenfluss zu erfassen, erstellen Sie einen Datenflussparameter (z. B. „sapPartitions“). Um das JSON-Format an diesen Parameter zu übergeben, muss es mithilfe der Funktion @string() in eine Zeichenfolge konvertiert werden:
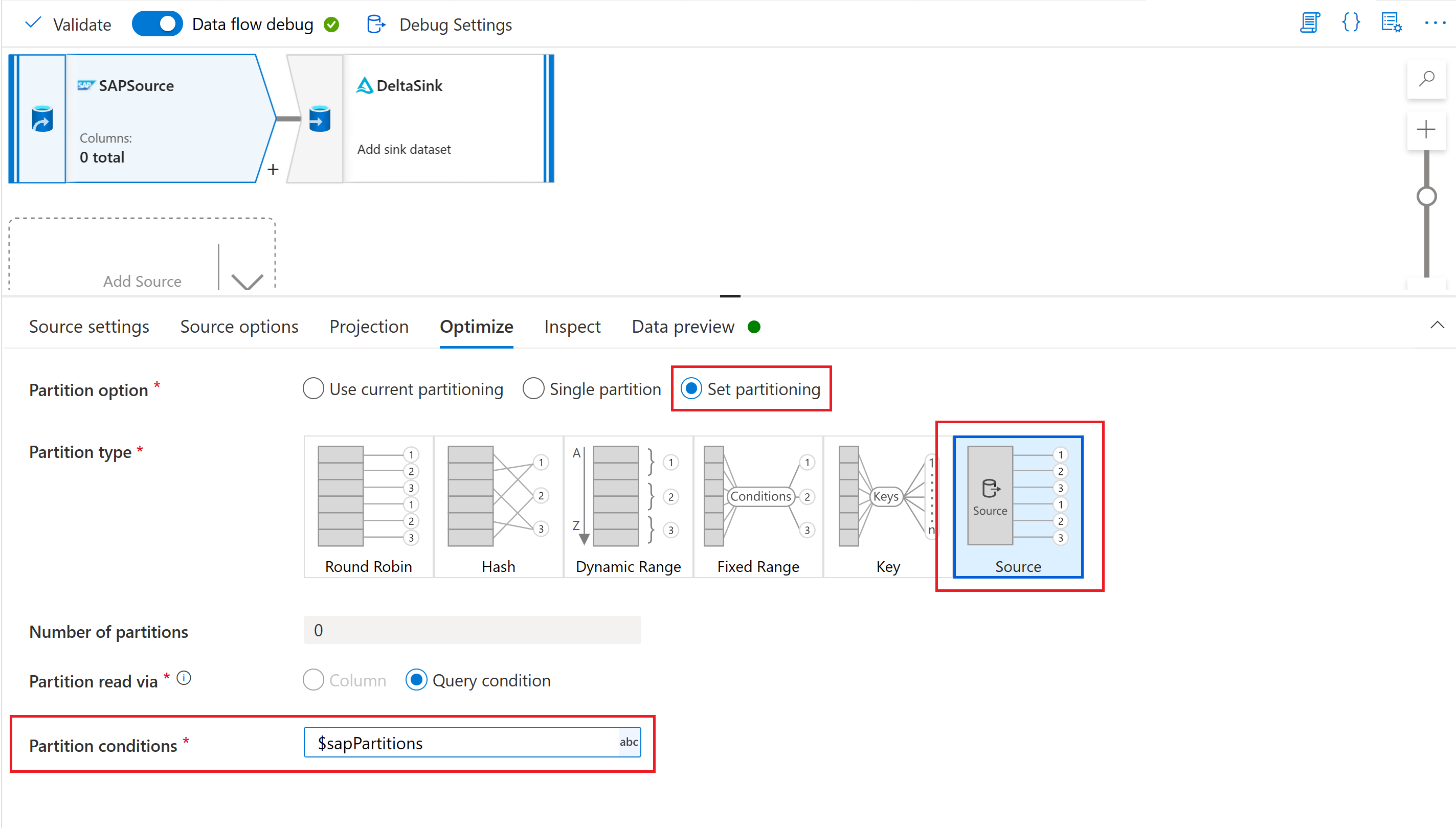
Wählen Sie schließlich auf der Registerkarte Optimieren der Quelltransformation in Ihrem Zuordnungsdatenfluss den Partitionstyp „Quelle“ aus, und geben Sie den Datenflussparameter in die Eigenschaft Partitionsbedingungen ein.
Parametrisieren des Prüfpunktschlüssels
Wenn Sie einen parametrisierten Datenfluss zum Extrahieren von Daten aus mehreren SAP CDC-Quellen verwenden, ist es wichtig, den Prüfpunktschlüssel in der Datenflussaktivität Ihrer Pipeline zu parametrisieren. Der Prüfpunktschlüssel wird von Azure Data Factory verwendet, um den Status eines Change Data Capture-Prozesses zu verwalten. Um zu vermeiden, dass der Status eines CDC-Prozesses den Status eines anderen überschreibt, stellen Sie sicher, dass die Prüfpunktschlüsselwerte für jeden in einem Dataflow verwendet Parametersatz eindeutig sind.
Hinweis
Eine bewährte Methode, um die Eindeutigkeit des Prüfpunktschlüssels sicherzustellen, besteht darin, den Prüfpunktschlüsselwert dem Satz von Parametern für Ihren Dataflow hinzuzufügen.
Weitere Informationen zum Prüfpunktschlüssel finden Sie unter Transformieren von Daten mit dem SAP CDC-Connector.
Debuggen
Azure Data Factory-Pipelines können über ausgelöste oder Debuggen-Ausführungen ausgeführt werden. Ein grundlegender Unterschied zwischen diesen beiden Optionen besteht darin, dass Debuggen-Ausführungen den Dataflow und die Pipeline basierend auf der aktuellen Version ausführen, die in der Benutzeroberfläche modelliert ist, während ausgelöste Ausführungen die letzte veröffentlichte Version eines Dataflows und einer Pipeline ausführen.
Für SAP CDC gibt es einen weiteren Aspekt, der verstanden werden muss: Um Auswirkungen von Debuggen-Ausführungen auf einen vorhandenen Change Data Capture-Prozess zu vermeiden, verwenden Debuggen-Ausführungen einen anderen Wert für den „Abonnentenprozess“ (siehe Überwachen von SAP CDC-Datenflüssen) als ausgelöste Ausführungen. Daher erstellen sie innerhalb des SAP-Systems separate Abonnements (d. h. Change Data Capture-Prozesse). Darüber hinaus ist der Wert „Abonnentenprozess“ für Debuggen-Ausführungen auf die Browsersitzung der Benutzeroberfläche beschränkt.
Hinweis
Um die Stabilität eines Change Data Capture-Prozesses mit SAP CDC über einen längeren Zeitraum (z. B. mehrere Tage) zu testen, müssen Datenfluss und Pipeline veröffentlicht werden, und ausgelöste Ausführungen müssen ausgeführt werden.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für