Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erstellen Sie einen KI-Agent, und stellen Sie ihn mithilfe von Databricks-Apps bereit. Databricks Apps bietet Ihnen die vollständige Kontrolle über den Agentcode, die Serverkonfiguration und den Bereitstellungsworkflow. Dieser Ansatz ist ideal, wenn Sie benutzerdefiniertes Serververhalten, gitbasierte Versionsverwaltung oder lokale IDE-Entwicklung benötigen.
Tip
Wenn Ihr Agent nur Azure Databricks gehostete Tools verwendet und keine benutzerdefinierte Logik zwischen Toolaufrufen benötigt, können Sie die
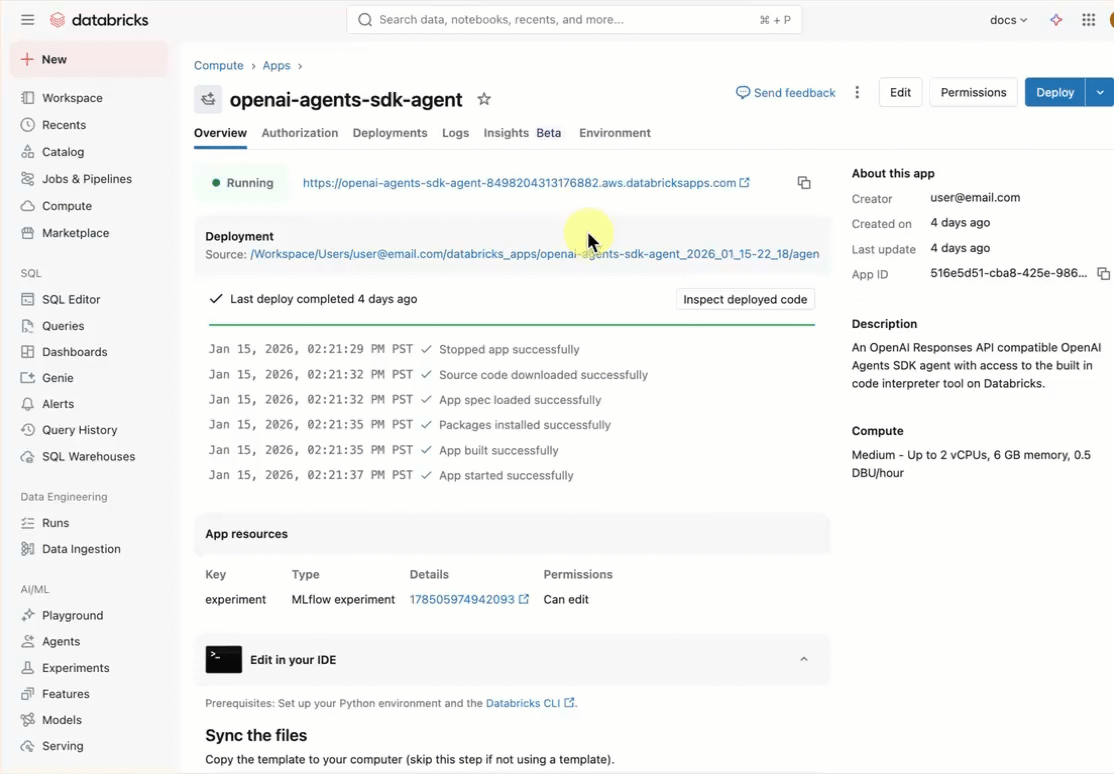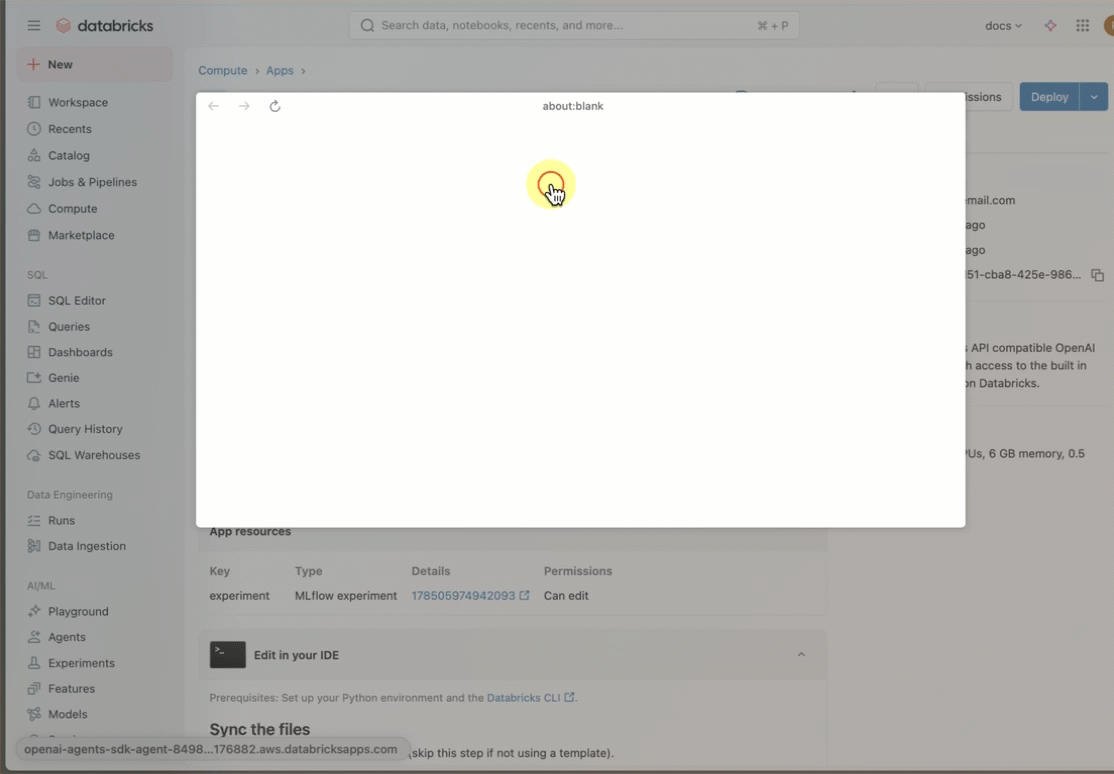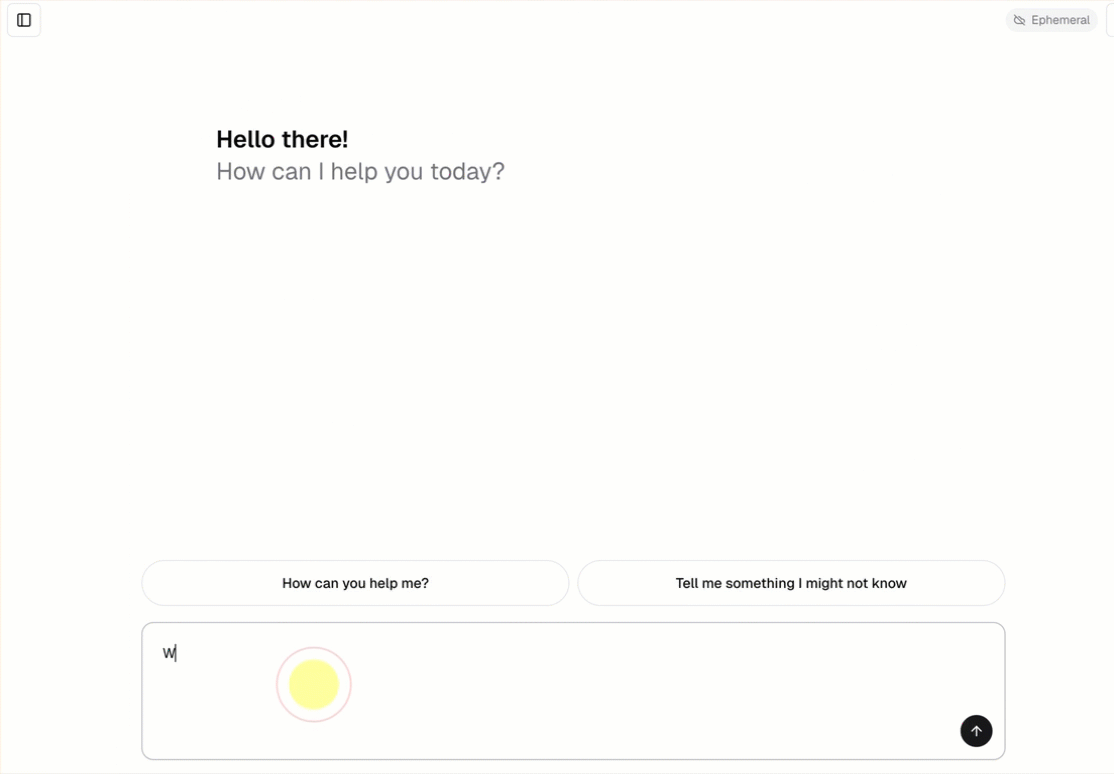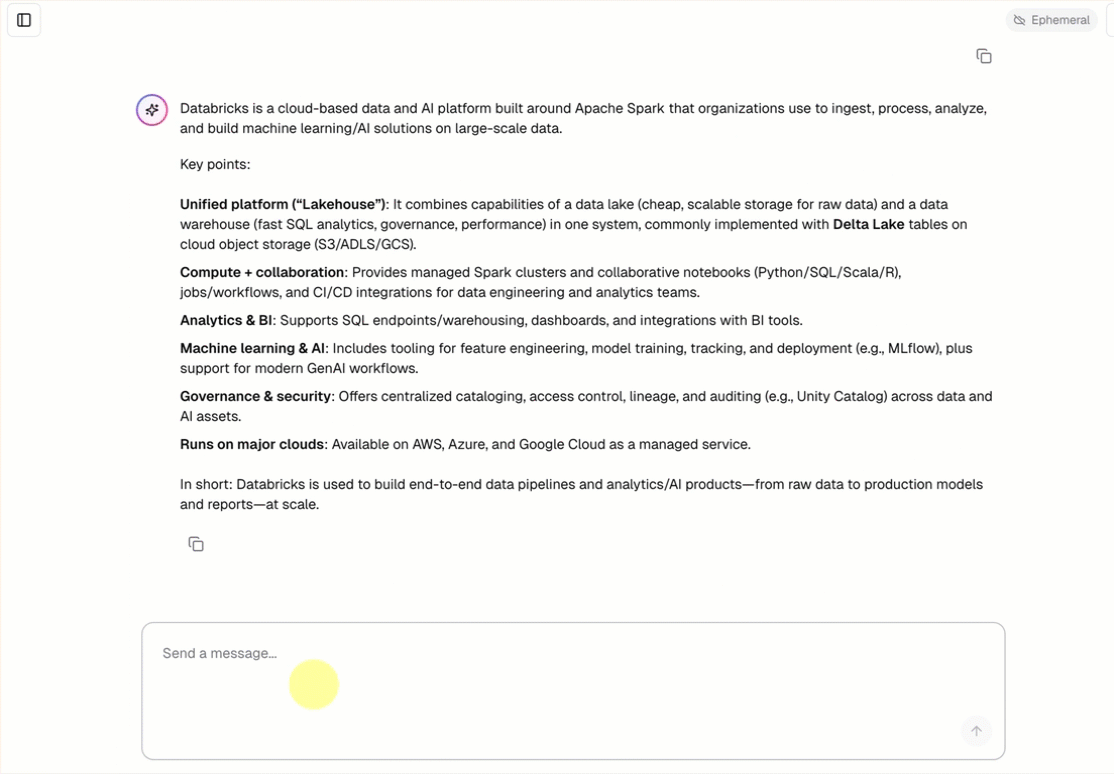
Jede Unterhaltungs-Agent-Vorlage enthält eine integrierte Chatbenutzeroberfläche (siehe oben), ohne dass zusätzliche Einrichtung erforderlich ist. Die Chat-UI unterstützt Streamingantworten, Markdown-Rendering, Databricks-Authentifizierung und optionalen beständigen Chatverlauf.
Anforderungen
Aktivieren Sie Databricks-Apps in Ihrem Arbeitsbereich. Weitere Informationen finden Sie unter Einrichten ihres Databricks-Apps-Arbeitsbereichs und ihrer Entwicklungsumgebung.
Schritt 1. Klonen der Agent-App-Vorlage
Beginnen Sie, indem Sie eine vorgefertigte Agent-Vorlage aus dem Databricks-App-Vorlagen-Repository verwenden.
In diesem Lernprogramm wird die agent-openai-agents-sdk Vorlage verwendet, die Folgendes umfasst:
- Ein Agent, der mit dem OpenAI Agent SDK erstellt wurde
- Startcode für eine Agenten-Anwendung mit einer Konversations-REST-API und einer interaktiven Chat-Benutzeroberfläche
- Code zum Auswerten des Agents mithilfe von MLflow
Wählen Sie einen der folgenden Pfade aus, um die Vorlage einzurichten:
Benutzeroberfläche des Arbeitsbereichs
Installieren Sie die App-Vorlage mithilfe der Arbeitsbereichs-Benutzeroberfläche. Dadurch wird die App installiert und auf einer Rechenressource in Ihrem Arbeitsbereich bereitgestellt. Anschließend können Sie die Anwendungsdateien zur Weiteren Entwicklung mit Ihrer lokalen Umgebung synchronisieren.
Klicken Sie in Ihrem Databricks-Arbeitsbereich auf +Neue>App.
Klicken Sie auf "Agents>Custom Agent" (OpenAI SDK).
Erstellen Sie ein neues MLflow-Experiment mit dem Namen
openai-agents-template, und schließen Sie den Rest der Einrichtung ab, um die Vorlage zu installieren.Nachdem Sie die App erstellt haben, klicken Sie auf die App-URL, um die Chat-UI zu öffnen.
Nachdem Sie die App erstellt haben, laden Sie den Quellcode auf Ihren lokalen Computer herunter, um sie anzupassen:
Kopieren des ersten Befehls unter "Dateien synchronisieren"
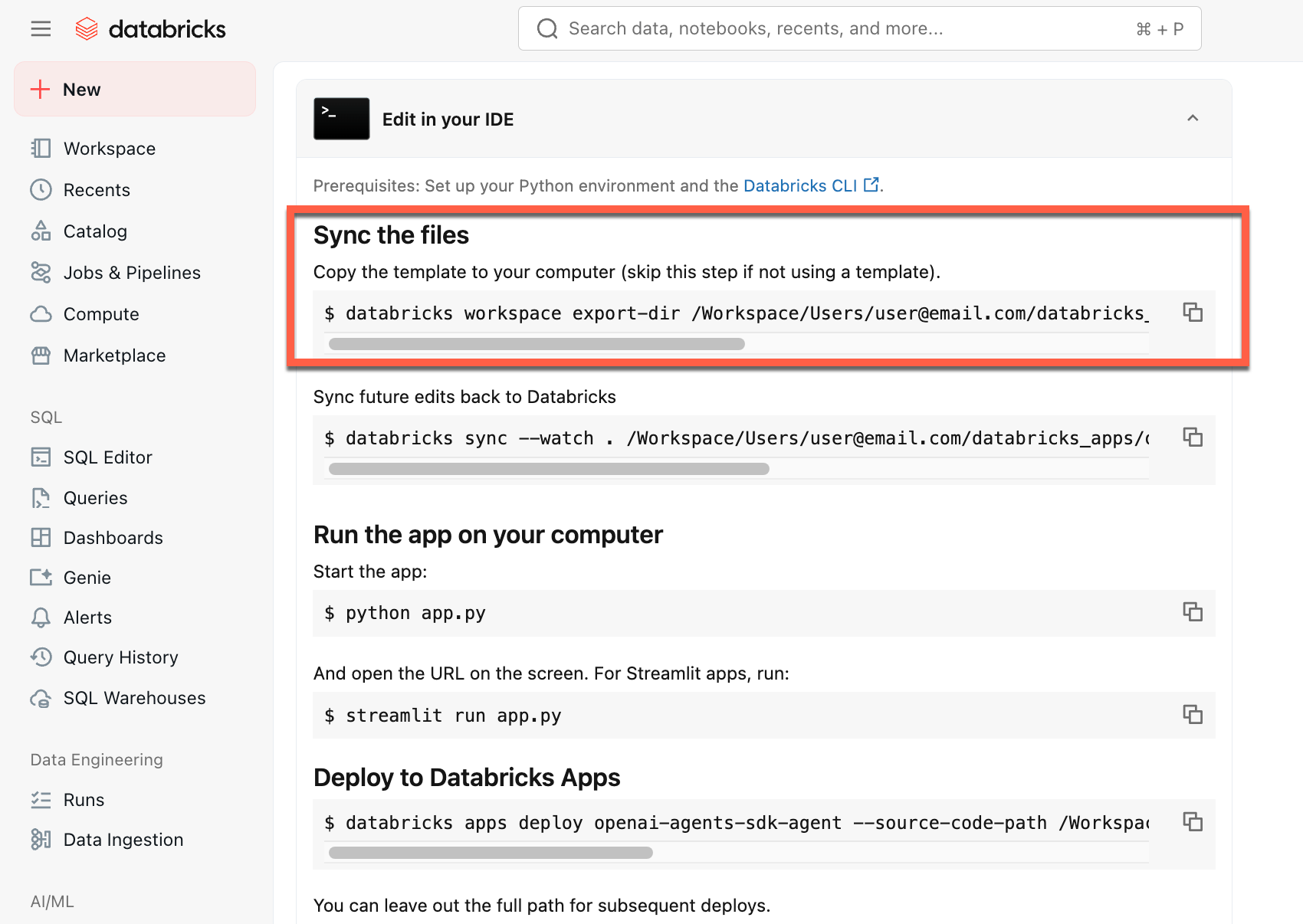
Führen Sie in einem lokalen Terminal den kopierten Befehl aus.
Klonen von GitHub
Um in einer lokalen Umgebung zu starten, klonen Sie das Agentenvorlagen-Repository und öffnen Sie das
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
Schritt 2. Grundlegendes zur Agentanwendung
Die Agentvorlage veranschaulicht eine produktionsfähige Architektur mit diesen Schlüsselkomponenten. Öffnen Sie die folgenden Abschnitte, um weitere Details zu den einzelnen Komponenten zu erhalten:

Öffnen Sie die folgenden Abschnitte, um weitere Details zu den einzelnen Komponenten zu erhalten:
 integrierte Chat-Benutzeroberfläche
integrierte Chat-Benutzeroberfläche
Die Agentvorlage ruft automatisch die Chat-App-Vorlage als Frontend ab und führt sie aus. Diese Chat-UI wird in derselben Databricks-Apps-Bereitstellung gebündelt und zusammen mit Ihrem Agent bereitgestellt, sodass keine zusätzliche Einrichtung erforderlich ist.
Sie können die Chat-Ui direkt in Ihrem Projekt anpassen. Weitere Informationen zu den Features der Chat-App, einschließlich der Aktivierung des Verlaufs für beständigen Chat und der Benutzerfeedbacksammlung, finden Sie unter Erstellen und Freigeben einer Chat-UI mit Databricks-Apps.
 MLflow AgentServer
MLflow AgentServer
Ein asynchroner FastAPI-Server, der Agentanforderungen mit integrierter Ablaufverfolgung und Observierbarkeit verarbeitet. Der AgentServer stellt den /responses Endpunkt zum Abfragen Ihres Agents bereit und verwaltet automatisch das Anforderungsrouting, die Protokollierung und die Fehlerbehandlung.

ResponsesAgent Schnittstelle
Databricks empfiehlt MLflow ResponsesAgent zum Erstellen von Agents.
ResponsesAgent Ermöglicht Es Ihnen, Agents mit jedem Drittanbieterframework zu erstellen und sie dann mit Databricks AI-Features für robuste Protokollierung, Ablaufverfolgung, Auswertung, Bereitstellung und Überwachung zu integrieren.

Informationen zum Erstellen einer ResponsesAgentDatei finden Sie in den Beispielen in der MLflow-Dokumentation – ResponsesAgent for Model Serving.
ResponsesAgent bietet die folgenden Vorteile:
Erweiterte Agent-Funktionen
- Multi-Agent-Unterstützung
- Streamingausgabe: Streamen Sie die Ausgabe in kleineren Blöcken.
- Umfassender Nachrichtenverlauf bei Toolaufrufen: Rückgabe mehrerer Nachrichten, einschließlich zwischengeschalteter Nachrichten, für eine verbesserte Qualität und Konversationsverwaltung.
- Unterstützung bei der Bestätigung von Toolaufrufen
- Unterstützung von langfristigen Tools
Vereinfachte Entwicklung, Bereitstellung und Überwachung
-
Erstellen Sie Agenten mit jedem beliebigen Framework: Verpacken Sie jeden bestehenden Agenten mithilfe der
ResponsesAgentSchnittstelle, um eine sofortige Kompatibilität mit AI Playground, Agent Evaluation und Agent Monitoring zu erreichen. - Typisierte Erstellungsschnittstellen: Schreiben Sie Agentcode mithilfe von typisierten Python Klassen, die von IDE und Notizbuch-AutoVervollständigen profitieren.
- Automatische Ablaufverfolgung: MLflow aggregiert automatisch gestreamte Antworten in Ablaufverfolgungen zur einfacheren Auswertung und Anzeige.
-
Kompatibel mit dem OpenAI-Schema
Responses: Siehe OpenAI: Antworten vs. ChatCompletion.
-
Erstellen Sie Agenten mit jedem beliebigen Framework: Verpacken Sie jeden bestehenden Agenten mithilfe der
 OpenAI Agents SDK
OpenAI Agents SDK
Die Vorlage verwendet das OpenAI Agents SDK als Agent-Framework für Konversationsverwaltung und Tool-Koordination. Sie können Agents mithilfe eines beliebigen Frameworks erstellen. Der Schlüssel liegt darin, Ihren Agenten mit der MLflow-Schnittstelle ResponsesAgent zu umwickeln.
 MCP-Server (Model Context Protocol)
MCP-Server (Model Context Protocol)
Die Vorlage stellt eine Verbindung mit Databricks MCP-Servern bereit, um Agents Zugriff auf Tools und Datenquellen zu gewähren. Siehe Model Context Protocol (MCP) für Databricks.
Autorenerstellungsagenten mit KI-Programmiierungsassistenten
Databricks empfiehlt die Verwendung von KI-gestützten Programmierungsassistenten wie Claude, Cursor und Copilot zur Erstellung von Agenten. Verwenden Sie die bereitgestellten Agent-Fähigkeiten in /.claude/skills, und die AGENTS.md Datei, um KI-Assistenten dabei zu helfen, die Projektstruktur, die verfügbaren Tools und bewährten Methoden zu verstehen. Agents können diese Dateien automatisch lesen, um die Databricks-Apps zu entwickeln und bereitzustellen.
Schritt 3. Fügen Sie Ihrem Agenten Werkzeuge hinzu
Bieten Sie Ihren Agent-Funktionen wie das Abfragen von Datenbanken, das Durchsuchen von Dokumenten oder das Aufrufen externer APIs, indem Sie sie mit MCP-Servern verbinden. Die Agentvorlage enthält eine standardmäßige MCP-Serververbindung. Um weitere Tools hinzuzufügen, konfigurieren Sie zusätzliche MCP-Server in Ihrem Agent-Code, und erteilen Sie die erforderlichen Berechtigungen in databricks.yml.
Siehe KI-Agent-Tools für unterstützte Tooltypen und Codebeispiele.
Define lokale Python-Funktionstools
Definieren Sie Tools für Vorgänge, für die keine externen Datenquellen oder APIs erforderlich sind, direkt in Ihrem Agentcode. Diese Tools werden im gleichen Prozess wie Ihr Agent ausgeführt und eignen sich für Datentransformationen, Berechnungen oder Hilfsprogramme.
OpenAI Agents SDK
Verwenden Sie den @function_tool Dekorator aus dem OpenAI Agents SDK:
from agents import Agent, function_tool
@function_tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = Agent(
name="My agent",
instructions="You are a helpful assistant.",
model="databricks-claude-sonnet-4-5",
tools=[get_current_time],
)
LangGraph
Verwenden Sie den @tool Dekorator von LangChain:
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from databricks_langchain import ChatDatabricks
@tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = create_react_agent(
ChatDatabricks(endpoint="databricks-claude-sonnet-4-5"),
tools=[get_current_time],
)
Lokale Funktionstools erfordern keine Ressourcenerteilungen databricks.yml , da sie innerhalb des Agentprozesses ausgeführt werden.
Schritt 4. Verwalten Sie die Nutzung von LLM für Ihre Agents in Databricks-Apps über das Unity AI Gateway.
Leiten Sie die LLM-Anrufe Ihres Agents über AI Gateway (Beta) weiter, sodass jede Anforderung von denselben Steuerelementen gesteuert wird, unabhängig davon, welcher Anbieter sie beantwortet. Mit dem Gateway im Anforderungspfad können Sie Berechtigungen zentralisieren, Kosten pro App zuordnen, Modelle austauschen und den Datenverkehr überprüfen oder wiedergeben, ohne den Agentcode zu ändern oder Anbieteranmeldeinformationen zu wechseln.
Important
Dieses Feature befindet sich in der Betaversion. Arbeitsbereichsadministratoren können den Zugriff auf dieses Feature über die Vorschauseite steuern. Siehe Manage Azure Databricks Previews.
Aktivieren Sie das KI-Gateway in Ihrem Arbeitsbereich. Das AI-Gateway ist in der Betaphase optional. Ein Kontoadministrator muss die Einstellung auf der Seite Vorschauen der Kontokonsole aktivieren, bevor Sie Gateway-Endpunkte erstellen oder abfragen können. Siehe Manage Azure Databricks Previews.
Verweisen Sie Ihren Agent auf einen AI-Gateway-Endpunkt. Übergeben Sie im Agentencode den Namen des AI-Gateway-Endpunkts als Argument
modelund legen Sieuse_ai_gateway=Trueim Azure Databricks LLM-Client fest. Der Client leitet Datenverkehr über das Gateway weiter und verarbeitet die Authentifizierung automatisch.OpenAI
from agents import Agent, set_default_openai_api, set_default_openai_client from databricks_openai import AsyncDatabricksOpenAI set_default_openai_client(AsyncDatabricksOpenAI(use_ai_gateway=True)) set_default_openai_api("chat_completions") agent = Agent( name="Agent", instructions="You are a helpful assistant.", model="<ai-gateway-endpoint>", )LangGraph
from databricks_langchain import ChatDatabricks llm = ChatDatabricks( model="<ai-gateway-endpoint>", use_ai_gateway=True, )Weitere API-Oberflächen (OpenAI-Antwort-API, Anthropic Nachrichten-API, Google Gemini) und REST-Beispiele finden Sie unter Query Unity AI Gateway-Endpunkte.
Themen zur erweiterten Inhaltserstellung
Streaming-Antworten
Streaming-Antworten
Streaming ermöglicht Es Agents, Antworten in Echtzeitblöcken zu senden, anstatt auf die vollständige Antwort zu warten. Um Streaming mit ResponsesAgentzu implementieren, geben Sie eine Reihe von Delta-Ereignissen aus, gefolgt von einem endgültigen Abschlussereignis:
-
Übertragen von Delta-Ereignissen: Senden Sie mehrere
output_text.deltaEreignisse mit demselbenitem_id, um Textblöcke in Echtzeit zu streamen. -
Fertig stellen: Senden Sie ein endgültiges
response.output_item.doneEreignis mit demselbenitem_idwie die Delta-Ereignisse, die den vollständigen endgültigen Ausgabetext enthalten.
Jedes Delta-Ereignis streamt einen Textabschnitt an den Client. Das letzte fertige Ereignis enthält den vollständigen Antworttext und signalisiert Databricks folgendes:
- Verfolgen Sie die Ergebnisse Ihres Agents mit der MLflow-Ablaufverfolgung
- Aggregierte gestreamte Antworten in KI-Gateway-Ableitungstabellen
- Zeige die vollständige Ausgabe in der AI Playground-Oberfläche an
Streamingfehlerverteilung
Mosaic AI propagiert alle Fehler, die beim Streaming mit dem letzten Token unter databricks_output.error auftreten. Es liegt bei dem aufrufenden Client, diesen Fehler ordnungsgemäß zu behandeln und anzuzeigen.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Benutzerdefinierte Eingaben und Ausgaben
Benutzerdefinierte Eingaben und Ausgaben
Einige Szenarien erfordern möglicherweise zusätzliche Eingaben von Agenten, wie z. B. client_type und session_id, oder Ausgaben wie Abrufquellenlinks, die nicht in den Chatverlauf für zukünftige Interaktionen einbezogen werden sollten.
Für diese Szenarien unterstützt MLflow ResponsesAgent die Felder custom_inputs und custom_outputsnativ. Sie können in den oben aufgeführten Frameworkbeispielen über request.custom_inputs auf die benutzerdefinierten Eingaben zugreifen.
Die Agent Evaluation Review-App unterstützt das Rendern von Ablaufverfolgungen für Agenten mit zusätzlichen Eingabefeldern nicht.
Bereitstellen custom_inputs in der AI-Playground- und Überprüfungs-App
Wenn Ihr Agent zusätzliche Eingaben mithilfe des custom_inputs Felds akzeptiert, können Sie diese Eingaben sowohl im AI-Playground als auch in der Rezensions-App manuell bereitstellen.
Wählen Sie in der AI Playground- oder in der Agent Review-App das Zahnradsymbol
 aus.
aus.Aktivieren Sie custom_inputs.
Stellen Sie ein JSON-Objekt bereit, das dem definierten Eingabeschema Ihres Agents entspricht.
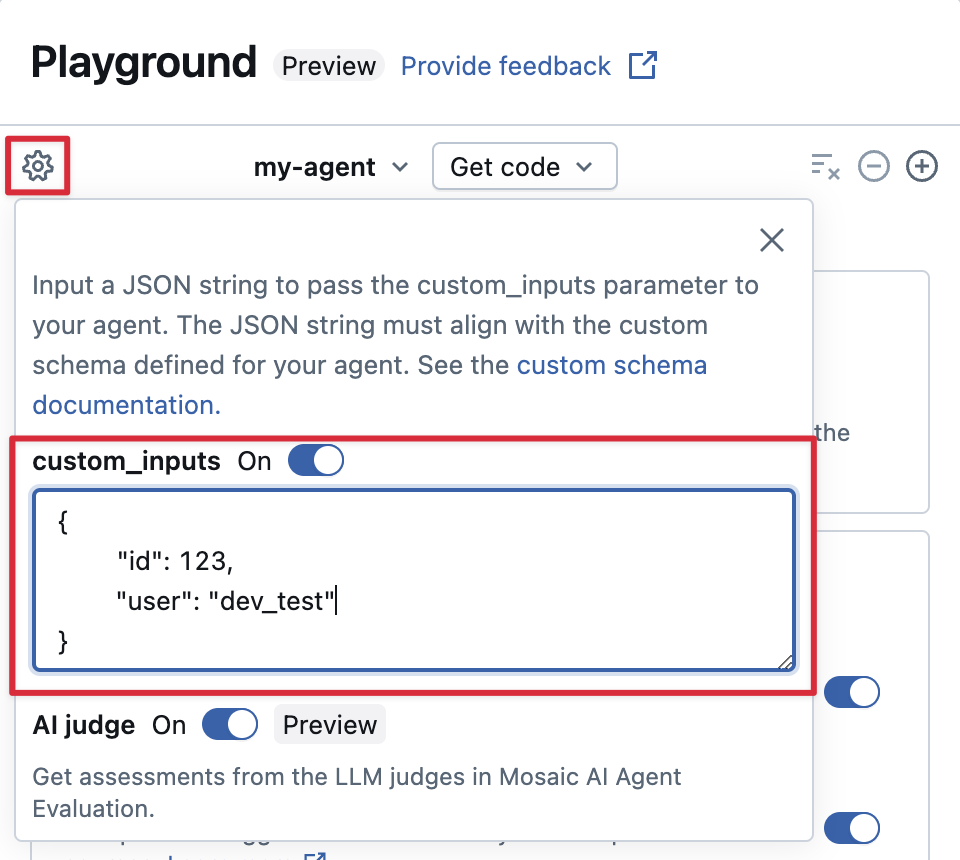
Schritt 5. Lokales Ausführen der Agent-App
Richten Sie Ihre lokale Umgebung ein:
Installieren Sie
uv(Python Paket-Manager),nvm(Node Version Manager) und die Databricks CLI:-
uvInstallation -
nvmInstallation - Führen Sie Folgendes aus, um Node 20 LTS zu verwenden:
nvm use 20 -
databricks CLIInstallation
-
Wechseln Sie in das
agent-openai-agents-sdkVerzeichnis.Führen Sie die bereitgestellten Schnellstartskripts aus, um Abhängigkeiten zu installieren, Ihre Umgebung einzurichten und die App zu starten.
uv run quickstart uv run start-app
Im Browser gehen Sie zu http://localhost:8000, um die integrierte Chatbenutzeroberfläche zu öffnen und mit dem Agenten zu chatten.
Schritt 6. Konfigurieren der Authentifizierung
Ihr Agent benötigt eine Authentifizierung, um auf Azure Databricks Ressourcen zuzugreifen. Databricks-Apps bieten zwei Authentifizierungsmethoden: App-Autorisierung (Dienstprinzipal) und Benutzerautorisierung (im Auftrag des Benutzers). Sie können entweder eine über die Arbeitsbereichs-UI oder deklarativ mit databricks.yml deklarativen Automatisierungspaketen konfigurieren. Die Agentvorlagen werden mit einem databricks.yml ausgeliefert, sodass dieser Pfad der Standard ist, wenn Sie mit einer Vorlage beginnen.
Die vollständige Referenz, einschließlich aller unterstützten Ressourcentypen, Berechtigungswerte und eines vollständigen databricks.yml Leitfadens, finden Sie unter „Authentifizierung für KI-Agenten“.
App-Autorisierung (Standard)
Azure Databricks erstellt automatisch einen Dienstprinzipal für Ihre App, der zur App-Autorisierung verwendet wird. Alle Benutzer haben dieselben Berechtigungen.
Deklarieren Sie jede Ressource, die der Agent unter resources.apps.<app>.resources in databricks.yml verwendet. Stellen Sie das Bundle bereit, um dem Dienstprinzipal die deklarierten Berechtigungen zu gewähren:
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
config:
command: ['uv', 'run', 'start-app']
env:
- name: MLFLOW_TRACKING_URI
value: 'databricks'
- name: MLFLOW_REGISTRY_URI
value: 'databricks-uc'
- name: MLFLOW_EXPERIMENT_ID
value_from: 'experiment'
resources:
- name: 'experiment'
experiment:
experiment_id: '<experiment-id>'
permission: 'CAN_EDIT'
- name: 'llm'
serving_endpoint:
name: 'databricks-claude-sonnet-4-5'
permission: 'CAN_QUERY'
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
Die vollständige Liste der Ressourcentypen finden Sie unter App-Autorisierung.
Benutzerautorisierung
Mit der Benutzerautorisierung kann Ihr Agent mit den individuellen Berechtigungen jedes Benutzers handeln. Verwenden Sie diese Vorgehensweise, wenn Sie die Zugriffssteuerung oder Überwachungspfade pro Benutzer benötigen.
Fügen Sie Ihrem Agenten diesen Code hinzu:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Important
Initialisieren Sie get_user_workspace_client() innerhalb Ihrer @invoke oder @stream Funktionen und nicht während des App-Starts. Benutzeranmeldeinformationen sind nur bei der Verarbeitung einer Anforderung vorhanden.
Konfigurieren Sie, welche Azure Databricks APIs der Agent im Namen des Benutzers aufrufen kann, indem Sie Bereiche unter user_api_scopes in der App in databricks.yml hinzufügen:
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
user_api_scopes:
- sql
- dashboards.genie
- serving.serving-endpoints
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
Eine Liste der verfügbaren Bereiche und vollständige Einrichtungsanweisungen finden Sie unter Benutzerautorisierung.
Schritt 7. Den Agenten auswerten
Die Vorlage enthält Agentenbewertungscode. Weitere Informationen finden Sie unter agent_server/evaluate_agent.py. Bewerten Sie die Relevanz und Sicherheit der Antworten Ihres Agenten, indem Sie Folgendes in einem Terminal ausführen:
uv run agent-evaluate
Schritt 8: Bereitstellen des Agents für Databricks-Apps
Stellen Sie nach der Konfiguration der Authentifizierung Ihren Agent für Azure Databricks bereit. Die Agentvorlagen verwenden Databricks Asset Bundles (DABs) für die Bereitstellung. Die databricks.yml Datei in der Vorlage definiert die App-Konfiguration und Ressourcenberechtigungen. Stellen Sie sicher, dass die Databricks CLI installiert und konfiguriert ist.
Anmerkung
Wenn Sie Ihre App über die Arbeitsbereichs-Benutzeroberfläche in Schritt 1 erstellt haben, führen Sie databricks bundle deployment bind agent_openai_agents_sdk <app-name> --auto-approve vor der Bereitstellung aus, um die vorhandene App an Ihr Paket zu binden. Andernfalls schlägt databricks bundle deploy mit "Eine App mit demselben Namen ist bereits vorhanden" fehl.
Überprüfen Sie die Bundlekonfiguration, um Fehler zu erfassen, bevor Sie Folgendes bereitstellen:
databricks bundle validateStellen Sie das Bundle bereit. Dies lädt Ihren Code hoch und konfiguriert Ressourcen (wie MLflow-Experimenten, bereitgestellte Endpunkte, usw.), die in
databricks.ymldefiniert sind.databricks bundle deployStarten oder starten Sie die App neu:
databricks bundle run agent_openai_agents_sdkAnmerkung
bundle deploylädt nur Dateien hoch und konfiguriert Ressourcen.bundle runist erforderlich, um die App mit dem neuen Code zu starten oder neu zu starten.
Führen Sie für zukünftige Updates databricks bundle deploy aus und führen Sie dann databricks bundle run agent_openai_agents_sdk erneut aus.
Schritt 9 Bereitgestellten Agent abfragen
Im folgenden Beispiel wird eine schnelle curl Anforderung mit einem OAuth-Token verwendet. Persönliche Zugriffstoken (PATs) werden für Databricks-Apps nicht unterstützt.
Eine vollständige Liste der Abfragemethoden, einschließlich der Databricks OpenAI-Client- und REST-API, finden Sie unter Abfragen eines Agents, der auf Azure Databricks bereitgestellt wurde.
Generieren Sie ein OAuth-Token mithilfe der Databricks CLI:
databricks auth login --host <https://host.databricks.com>
databricks auth token
Verwenden Sie das Token, um den Agent abzufragen:
curl -X POST <app-url.databricksapps.com>/responses \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
Einschränkungen
- Es werden nur mittlere und große Computegrößen unterstützt. Siehe Konfigurieren von Computeressourcen für eine Databricks-App.
- Die Benutzeroberfläche von MLflow Review App Chat unterstützt derzeit keine Agents, die in Databricks-Apps bereitgestellt werden. Verwenden Sie Kennzeichnungssitzungen, die unabhängig von der Bereitstellungsmethode funktionieren, um vorhandene Ablaufverfolgungen auszuwerten. Databricks erstellt Überprüfungs- und Feedbackunterstützung direkt in der Chatbot-Vorlage.