Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
Von Bedeutung
Dieses Feature befindet sich in der Public Preview.
Auf dieser Seite wird der Data Engineering Agent vorgestellt, der dem Databricks-Assistenten Funktionen hinzufügt. Um den Data Engineering Agent zu verwenden, wählen Sie den Agent-Modus im Assistenten aus.
Der Data Engineering-Agent wurde speziell für Lakeflow Spark Declarative Pipelines (SDP) und den Lakeflow Pipelines Editor entwickelt, es untersucht Daten, generiert und führt Pipelinecode aus und behebt Fehler aus einer einzigen Eingabeaufforderung.
Was ist der Data Engineering Agent?
Der Data Engineering Agent ist eine leistungsstarke Funktion im Databricks Assistant Agent Mode, die den Assistenten in einen autonomen Partner transformiert, der ganze mehrstufige Data Engineering-Workflows in SDP und den Lakeflow Pipelines Editor automatisieren kann.
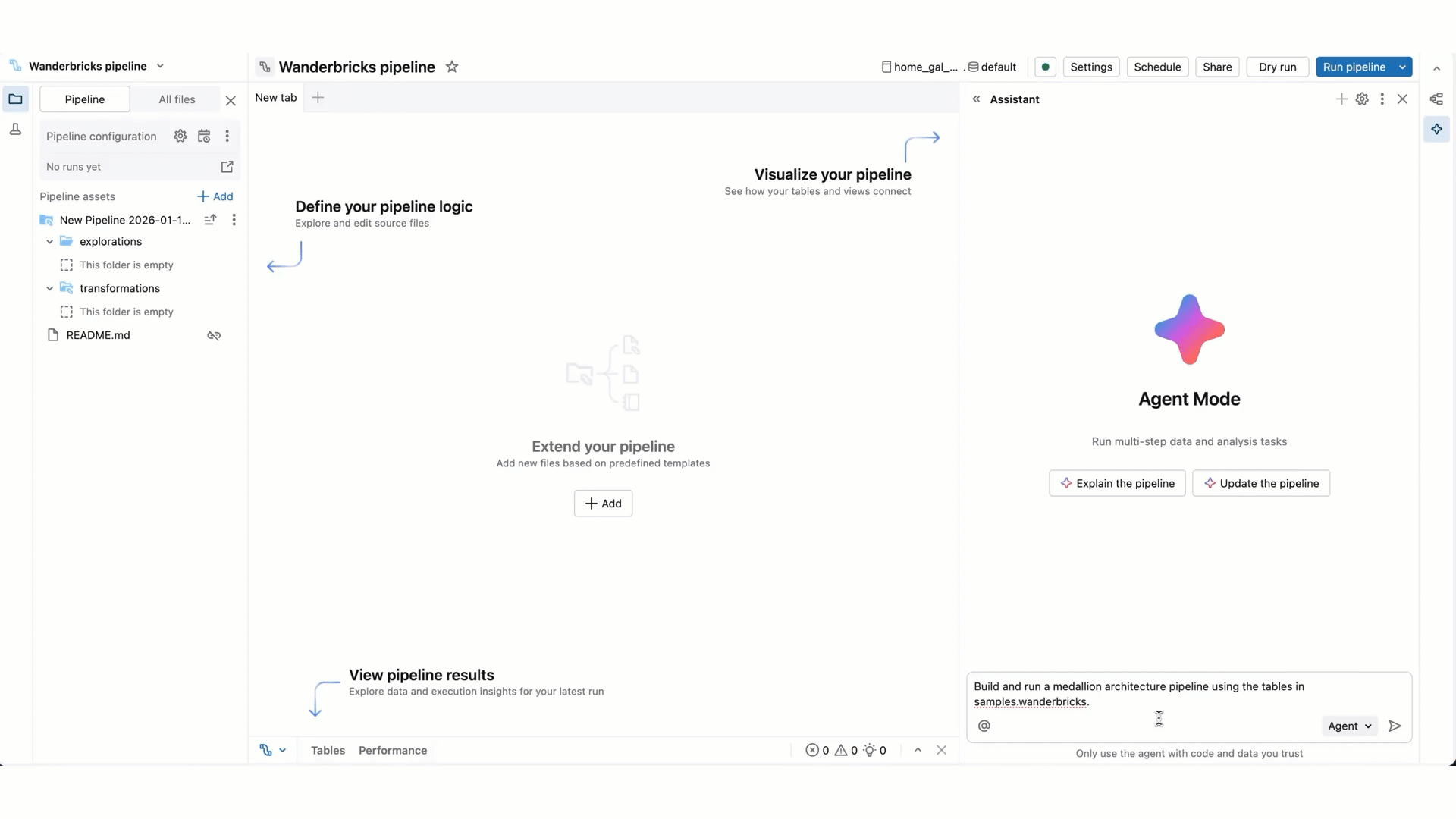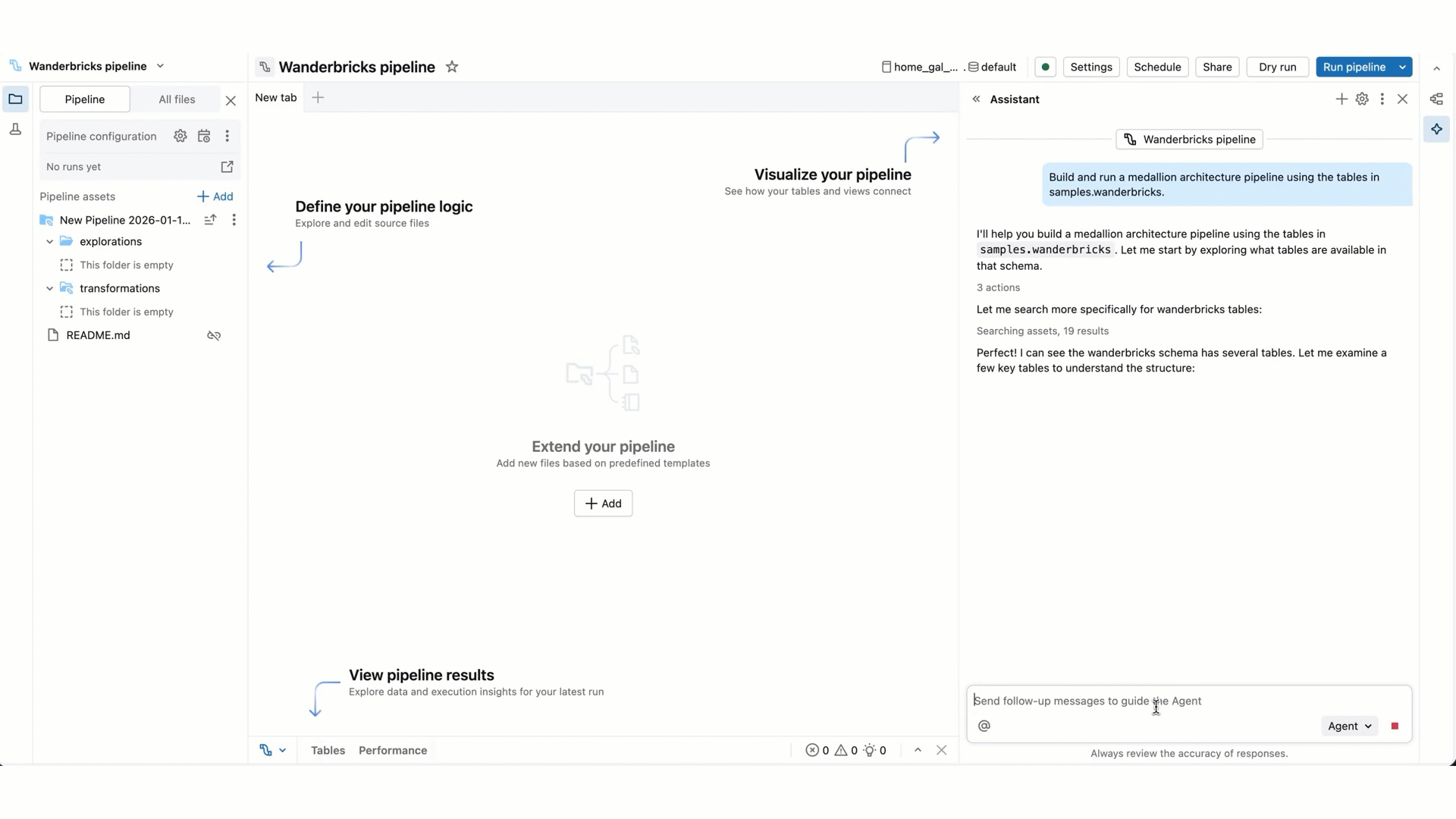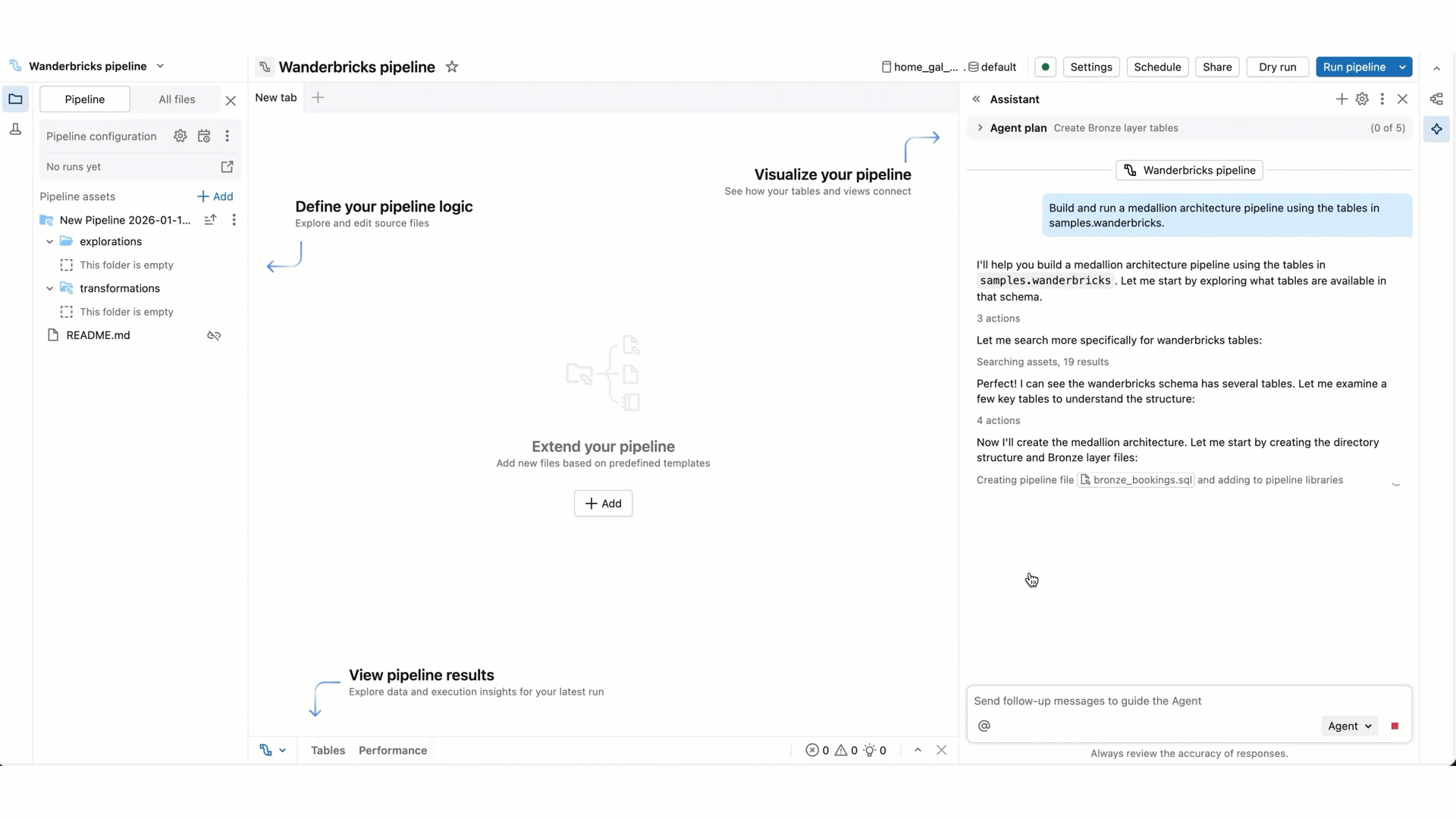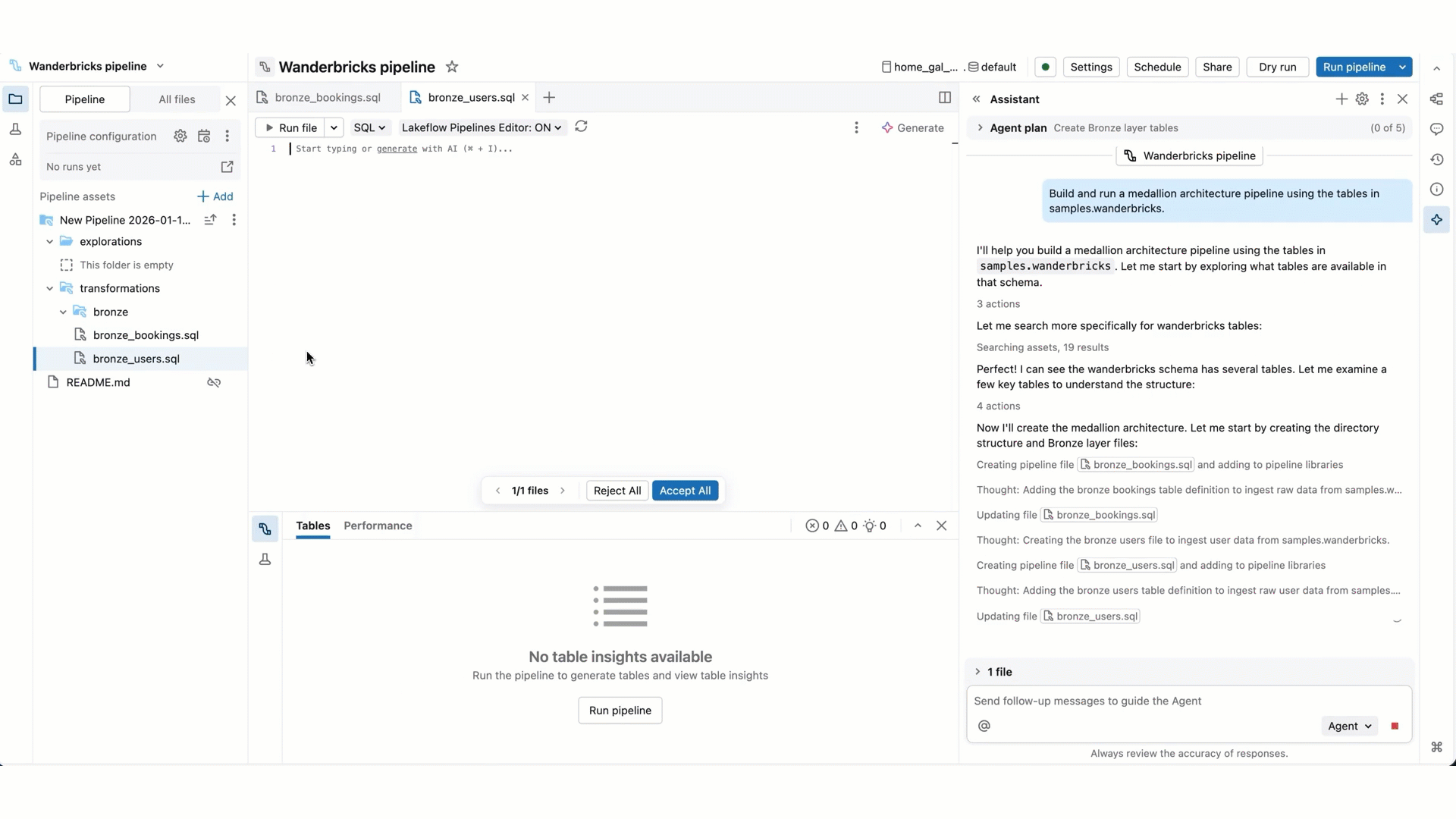
Im Vergleich zum Assistenten-Chatmodus verfügt der Agentmodus über erweiterte Funktionen: Planen einer Lösung, Abrufen relevanter Ressourcen, Ausführen von Code, Verwenden von Pipelineausgaben zur Verbesserung von Ergebnissen, automatisches Beheben von Fehlern und mehr.
Der Data Engineering Agent kann gesamte Pipelines von Grund auf neu planen und generieren oder die Arbeit an einer vorhandenen Pipeline beschleunigen. Der Agent arbeitet mit Ihnen zusammen, um seine Pläne zu genehmigen und die nächsten Schritte zu bestätigen, bevor Sie fortfahren. Mit Ihrer Genehmigung kann der Data Engineering Agent Tools verwenden, um Aufgaben wie das Durchsuchen von Tabellen, das Bearbeiten einer SQL- oder Python-Quelldatei, das Ausführen von Pipelineupdates und das Lesen von Pipeline-Datasets auszuführen.
Der Zugriff und die Aktionen des Data Engineering Agents unterliegen den Berechtigungen des Benutzers. Sie kann nur auf Daten zugreifen, für die Sie Zugriff haben und Vorgänge ausführen, für die Sie über Berechtigungen verfügen.
Hinweis
Wenn Sie den Agentmodus im Assistenten aktivieren, passt der Assistent seine Funktionen basierend auf den Features an, die Sie derzeit in Databricks verwenden. Beispielsweise konzentriert sich der Assistent im Lakeflow Pipelines Editor auf Pipelinebearbeitungs- und Datentechnikaufgaben. In Notizbüchern und dem SQL-Editor unterstützt der Assistent die Datensuche und -analyse. Weitere Informationen finden Sie unter Data Science Agent .
Anforderungen
Um den Data Engineering Agent zu verwenden, benötigt Ihr Arbeitsbereich Folgendes:
- Partnergestützte KI-Features, die sowohl für das Konto als auch für den Arbeitsbereich aktiviert sind. Siehe partnergestützte KI-Features.
- Databricks Assistant Agent Mode Preview aktiviert. Siehe Verwalten von Azure Databricks-Vorschauen.
Verwenden des Data Engineering Agents
So verwenden Sie den Data Engineering Agent:
Öffnen Sie im Lakeflow Pipelines-Editor den Assistenten-Seitenbereich, indem Sie auf das
 Assistent in der oberen rechten Ecke Ihres Arbeitsbereichs.
Assistent in der oberen rechten Ecke Ihres Arbeitsbereichs.Wählen Sie in der unteren rechten Ecke "Agent" aus. Dadurch wird der Agentmodus des Assistenten umgeschaltet, sodass Sie mit dem Data Engineering Agent interagieren können.
Geben Sie eine Eingabeaufforderung für den Agent ein. Sie können z. B. Fragen zu Ihrer Pipeline stellen, z. B. "diese Pipeline beschreiben". Sie können sie auch bitten, neue Datasets hinzuzufügen, z. B. "erstellen Sie silver_sales_data in einer neuen Datei, die aus bronze_sales_data liest, und bereinigt die Daten und fügt nützliche Qualitätserwartungen hinzu."
Hinweis
Der Agent respektiert die Unity-Katalogberechtigungen des Benutzers, sodass er nur auf die Daten und Pipelinequelle zugreifen kann, auf die Sie Zugriff haben.
Wenn der Agent seine Antwort generiert, wird sie häufig angehalten, um Ihre Eingabe zu erhalten:
Für komplexere Aufgaben kann der Agent einen schrittweisen Plan erstellen und Klärungsfragen stellen. Beantworten Sie die Klarstellungsfragen des Agenten, um ihm zu helfen, seinen Plan zu verfeinern.
Wenn der Agent Code ausführen oder eine Pipeline aktualisieren muss, fordert er ihre Genehmigung an, bevor er fortfahren kann. Zulassen oder Ablehnen der Anforderung. Sie können auch "Zulassen" in diesem Thread (verweisen auf den Unterhaltungsthread "Assistent") oder "Immer zulassen" auswählen.
Von Bedeutung
Der Data Engineering Agent kann Code in Ihrer Pipeline generieren und ausführen. Obwohl es Schutzschienen hat, um gefährliche Aktionen zu verhindern, besteht immer noch Gefahr. Sie sollten sie nur mit Daten verwenden, denen Sie vertrauen, und Sie sollten den Code überprüfen, bevor Sie ihn ausführen.
Wenn der Agent seine Arbeit fortsetzt, werden Sie möglicherweise aufgefordert, "Weiter" oder "Ablehnen " auszuwählen. Überprüfen Sie die vorhandene Arbeit des Agents, und wählen Sie dann "Weiter" aus, damit der Agent mit den nächsten Schritten fortfahren kann, oder "Ablehnen ", um ihn anzuweisen, etwas anderes zu versuchen.
Wenn Sie den Agent während der Arbeit beenden möchten, klicken Sie auf das rote

Der Agent kann neue Dateien erstellen, Text, Abfragen und Code generieren, die Dateien oder Pipelines ausführen und auf die Ausgabedatensätze zugreifen, um die Ergebnisse zu interpretieren.
Hinweis
Damit der Data Engineering Agent seine Arbeit fortsetzen und die nächsten Schritte ausführen kann, müssen Sie auf der aktuellen Registerkarte bleiben, in der der Agent arbeitet.
Tipp
Sie können Anweisungen für den Agent hinzufügen, die in den meisten Antworten verwendet werden sollen. Wenn Sie z. B. Über Codekonventionen verfügen, die Sie verwenden möchten, oder bevorzugte Bibliotheken, können Sie diese Richtlinien anweisungen für den Agent hinzufügen. Sie können auch Fähigkeiten erstellen, um den Agent mit speziellen Funktionen für Ihre domänenspezifischen Aufgaben zu erweitern. Weitere Details und weitere Tipps finden Sie unter Anpassen und Verbessern der Antworten des Databricks-Assistenten.
Fähigkeiten
Der Data Engineering Agent kann bei den meisten Pipelineentwicklungsaufgaben helfen. Wichtige Funktionen sind:
- Datenermittlung: Der Agent kann Tabellen im Arbeitsbereich durchsuchen, um die erforderlichen Daten für eine Aufgabe zu finden.
- Pipeline-Code-Bearbeitungen: Der Agent kann mehrere Dateien gleichzeitig erstellen und bearbeiten. Es informiert Sie darüber, welche Dateien sie ändern, und zeigt Ihnen den Code-Diff in jeder Datei, damit Sie die Änderungen einzeln oder alle am Ende überprüfen können.
- Pipelineausführung: Der Agent kann einzelne Dateien ausführen, die Pipeline im Trockenlauf betreiben oder eine vollständige Aktualisierung durchführen. Wenn der Agent fortfahren möchte, fordert er ihre Bestätigung an, bevor er dies tut.
- Verständnis und Verbesserung des Pipelineverhaltens: Der Agent kann Datasets und Pipelineausgaben prüfen, um Ihnen zu helfen zu verstehen, was eine Pipeline von Anfang bis Ende ausführt und warum. So können Sie beispielsweise Transformationen zusammenfassen, nachverfolgen, wie Daten in nachgeschaltete Tabellen fließen, und unerwartete Änderungen in Zeilenanzahlen oder Schemas hervorheben. Wenn potenzielle Probleme mit der Datenqualität auftreten, kann der Agent Ihnen helfen, ihre Ursache zu ermitteln und vorzuschlagen, wo und wie sie in der Pipeline behandelt werden.
Diese Funktionen unterstützen häufige Anwendungsfälle wie:
- Erstellen einer neuen Pipeline: Der Data Engineering Agent kann bei allen Schritten beim Erstellen einer neuen Medallion-Architekturpipeline helfen, von der Erfassung von Daten bis hin zum Standardisieren und Bereinigen der Daten, zum Transformieren und Analysieren der Daten.
- Erläutern einer Pipeline: Der Agent kann eine vorhandene Pipeline analysieren und erklären, damit Sie schnell hochfahren können.
- Beheben von Problemen: Wenn Sie Fehler haben, kann der Agent bei der Diagnose und Behebung der Probleme helfen und mehrere Dateien durchlaufen, bis das Problem behoben wurde.
Examples
Probieren Sie die folgenden Eingabeaufforderungen aus, um zu beginnen:
- "Erstellen und Ausführen einer Medallion-Architekturpipeline zur Betrugserkennung mithilfe der Tabellentransaktionen und Kunden in my_catalog.my_schema."
- "Erklären Sie jeden Schritt dieser Pipeline."
- "Beheben des Fehlers in dieser Pipeline."
Nächste Schritte
- Weitere Informationen zu Databricks AI-Hilfsfunktionen
- Tipps zum Anpassen und Verbessern der Antworten des Databricks-Assistenten
- Verwenden des Data Science Agent für die Datenermittlung und -erkundung
- Erkunden Sie den Lakeflow Pipelines-Editor