Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Sie eine neue Pipeline mit Lakeflow Spark Declarative Pipelines (SDP) für die Daten-Orchestrierung und das automatische Laden erstellen. In diesem Lernprogramm wird die Beispielpipeline erweitert, indem die Daten gereinigt und eine Abfrage erstellt wird, um die 100 wichtigsten Benutzer zu finden.
In diesem Lernprogramm erfahren Sie, wie Sie den Lakeflow Pipelines Editor verwenden, um:
- Erstellen Sie eine neue Pipeline mit der Standardordnerstruktur, und beginnen Sie mit einer Reihe von Beispieldateien.
- Definieren Sie Datenqualitätseinschränkungen mithilfe von Erwartungen.
- Verwenden Sie die Editorfunktionen, um die Pipeline durch eine neue Transformation zu erweitern und Analysen Ihrer Daten durchzuführen.
Anforderungen
Bevor Sie dieses Lernprogramm starten, müssen Sie:
- Melden Sie sich bei einem Azure Databricks-Arbeitsbereich an.
- Haben Sie Unity-Katalog für Ihren Arbeitsbereich aktiviert.
- Aktivieren Sie den Lakeflow-Pipeline-Editor für Ihren Arbeitsbereich, und stellen Sie sicher, dass Sie dafür angemeldet sind. Siehe Aktivieren des Lakeflow-Pipelines-Editors und der aktualisierten Überwachung.
- Verfügen Sie über die Berechtigung zum Erstellen einer Computeressource oder des Zugriffs auf eine Computeressource.
- Verfügen Sie über Berechtigungen zum Erstellen eines neuen Schemas in einem Katalog. Die erforderlichen Berechtigungen sind
ALL PRIVILEGESoderUSE CATALOGund .CREATE SCHEMA
Schritt 1: Erstellen einer Pipeline
In diesem Schritt erstellen Sie eine Pipeline mithilfe der Standardordnerstruktur und Codebeispiele. Die Codebeispiele verweisen auf die users Tabelle in der wanderbricks Beispieldatenquelle.
Klicken Sie in Ihrem Azure Databricks-Arbeitsbereich auf das
 Neu, dann
Neu, dann  ETL-Pipeline. Dadurch wird der Pipeline-Editor auf der Seite "Pipeline erstellen" geöffnet.
ETL-Pipeline. Dadurch wird der Pipeline-Editor auf der Seite "Pipeline erstellen" geöffnet.Klicken Sie auf die Kopfzeile, um Ihrer Pipeline einen Namen zu geben.
Wählen Sie direkt unter dem Namen den Standardkatalog und das Standardschema für Ihre Ausgabetabellen aus. Diese werden verwendet, wenn Sie in Ihren Pipelinedefinitionen keinen Katalog und kein Schema angeben.
Klicken Sie unter "Nächster Schritt" für Die Pipeline auf ein
 Beginnen Sie mit Beispielcode im SQL - oder Beginnen Sie mit Beispielcode in Python, basierend auf Ihrer Spracheinstellung. Dadurch wird die Standardsprache für Den Beispielcode geändert, Sie können aber später Code in der anderen Sprache hinzufügen. Dadurch wird eine Standardordnerstruktur mit Beispielcode für die ersten Schritte erstellt.
Beginnen Sie mit Beispielcode im SQL - oder Beginnen Sie mit Beispielcode in Python, basierend auf Ihrer Spracheinstellung. Dadurch wird die Standardsprache für Den Beispielcode geändert, Sie können aber später Code in der anderen Sprache hinzufügen. Dadurch wird eine Standardordnerstruktur mit Beispielcode für die ersten Schritte erstellt.Sie können den Beispielcode im Pipelineobjektbrowser auf der linken Seite des Arbeitsbereichs anzeigen. Unter
transformationssind zwei Dateien, die jeweils ein Pipeline-Dataset generieren. Unterexplorationsist ein Notizbuch mit Code, der Ihnen beim Anzeigen der Ausgabe Ihrer Pipeline hilft. Durch Klicken auf eine Datei können Sie den Code im Editor anzeigen und bearbeiten.Die Ausgabe-Datasets wurden noch nicht erstellt, und das Pipelinediagramm auf der rechten Seite des Bildschirms ist leer.
Wenn Sie den Pipelinecode (den Code im
transformationsOrdner) ausführen möchten, klicken Sie oben rechts auf dem Bildschirm auf " Pipeline ausführen ".Nach Abschluss der Ausführung zeigt der untere Teil des Arbeitsbereichs die beiden neuen Tabellen an, die erstellt wurden,
sample_users_<pipeline-name>undsample_aggregation_<pipeline-name>. Sie können auch sehen, dass das Pipelinediagramm auf der rechten Seite des Arbeitsbereichs jetzt die beiden Tabellen anzeigt, einschließlichsample_users, das die Quelle fürsample_aggregationist.
Schritt 2: Anwenden von Datenqualitätsprüfungen
In diesem Schritt fügen Sie der sample_users Tabelle eine Datenqualitätsprüfung hinzu. Sie verwenden Pipelineerwartungen , um die Daten einzuschränken. In diesem Fall löschen Sie alle Benutzerdatensätze, die nicht über eine gültige E-Mail-Adresse verfügen, und geben die bereinigte Tabelle als users_cleanedaus.
Klicken Sie im Pipelineobjektbrowser auf
, und wählen Sie "Transformation" aus.Treffen Sie im Dialogfeld "Neue Transformationsdatei erstellen" die folgenden Auswahl:
- Wählen Sie entweder Python oder SQL für die Sprache aus. Dies muss nicht mit Ihrer vorherigen Auswahl übereinstimmen.
- Geben Sie der Datei einen Namen. Wählen Sie in diesem Fall die Option
users_cleaned. - Behalten Sie für den Zielpfad die Standardeinstellung bei.
- Lassen Sie ihn für den Datasettyp entweder als Keine ausgewählt oder wählen Sie Materialisierte Ansicht aus. Wenn Sie die Materialisierte Ansicht auswählen, wird Beispielcode für Sie generiert.
Bearbeiten Sie in Der neuen Codedatei den Code so, dass er mit dem folgenden übereinstimmt (verwenden Sie SQL oder Python, basierend auf Ihrer Auswahl auf dem vorherigen Bildschirm). Ersetzen Sie
<pipeline-name>durch den vollständigen Namen Ihrersample_users-Tabelle.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<pipeline-name>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.table @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<pipeline_name>") )Klicken Sie auf "Pipeline ausführen" , um die Pipeline zu aktualisieren. Es sollte nun drei Tabellen enthalten.
Schritt 3: Analysieren der wichtigsten Benutzer
Als Nächstes ermitteln Sie die Top 100 Benutzer nach der Anzahl der Buchungen, die sie erstellt haben. Verbinden Sie die wanderbricks.bookings Tabelle mit der users_cleaned materialisierten Ansicht.
Klicken Sie im Pipelineobjektbrowser auf
, und wählen Sie "Transformation" aus.Treffen Sie im Dialogfeld "Neue Transformationsdatei erstellen" die folgenden Auswahl:
- Wählen Sie entweder Python oder SQL für die Sprache aus. Dies muss nicht mit Ihren vorherigen Auswahlen übereinstimmen.
- Geben Sie der Datei einen Namen. Wählen Sie in diesem Fall die Option
users_and_bookings. - Behalten Sie für den Zielpfad die Standardeinstellung bei.
- Lassen Sie den Datasettyp auf Keine Auswahl.
Bearbeiten Sie in Der neuen Codedatei den Code so, dass er mit dem folgenden übereinstimmt (verwenden Sie SQL oder Python, basierend auf Ihrer Auswahl auf dem vorherigen Bildschirm).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.table def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Klicken Sie auf "Pipeline ausführen" , um die Datasets zu aktualisieren. Wenn die Ausführung abgeschlossen ist, können Sie im Pipelinediagramm sehen, dass vier Tabellen vorhanden sind, einschließlich der neuen
users_and_bookingsTabelle.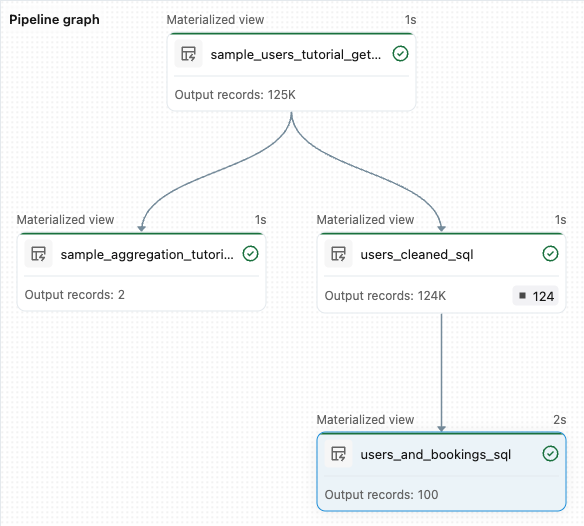
Nächste Schritte
Nachdem Sie nun erfahren haben, wie Sie einige der Features des Lakeflow-Pipelines-Editors verwenden und eine Pipeline erstellt haben, finden Sie hier einige weitere Features, um mehr darüber zu erfahren:
Tools zum Arbeiten mit und Debuggen von Transformationen beim Erstellen von Pipelines:
- Selektive Ausführung
- Datenvorschauen
- Interaktive DAG (Diagramm der Datasets in Ihrer Pipeline)
Integrierte deklarative Automatisierungspakete Integration für effiziente Zusammenarbeit, Versionskontrolle und CI/CD-Integration direkt im Editor.