Erhebliche Versionsänderungen in HDInsight 4.0 und Vorteile
HDInsight 4.0 bietet gegenüber HDInsight 3.6 verschiedene Vorteile. Hier finden Sie eine Übersicht über die neuen Funktionen in Azure HDInsight 4.0.
| # | OSS-Komponente | HDInsight 4.0-Version | HDInsight 3.6-Version |
|---|---|---|---|
| 1 | Apache Hadoop | 3.1.1 | 2.7.3 |
| 2 | Apache HBase | 2.1.6 | 1.1.2 |
| 3 | Apache Hive | 3.1.0 | 1.2.1, 2.1 (LLAP) |
| 4 | Apache Kafka | 2.1.1, 2.4 (GA) | 1.1 |
| 5 | Apache Phoenix | 5 | 4.7.0 |
| 6 | Apache Spark | 2.4.4, 3.0.0 (Vorschau) | 2.2 |
| 7 | Apache TEZ | 0.9.1 | 0.7.0 |
| 8 | Apache ZooKeeper | 3.4.6 | 3.4.6 |
| 9 | Apache Kafka | 2.1.1, 2.4.1 (Vorschau) | 1.1 |
| 10 | Apache Ranger | 1.1.0 | 0.7.0 |
Workloads und Features
Hive
- Erweiterte Funktionen
- LLAP-Workloadverwaltung
- LLAP-Support von JDBC-, Druid- und Kafka-Connectors
- Bessere SQL-Features – Einschränkungen und Standardwerte
- Ersatzschlüssel
- Informationsschema.
- Leistungsvorteil
- Zwischenspeichern von Ergebnissen – Das Zwischenspeichern von Abfrageergebnissen ermöglicht die Wiederverwendung eines zuvor berechneten Abfrageergebnisses
- Dynamische materialisierte Sichten – Vorabberechnungsergebnis von Zusammenfassungen
- Leistungsverbesserungen von ACID V2 sowohl im Speicherformat als auch in der Ausführungs-Engine
- Sicherheit
- DSGVO-Compliance für Apache Hive-Transaktionen aktiviert
- Hive-UDF-Ausführungsautorisierung in Ranger
HBase
- Erweiterte Funktionen
- Prozedur 2. Prozedur V2 oder procv2 ist ein aktualisiertes Framework zum Ausführen von mehrstufigen HBase-Verwaltungsvorgängen.
- Vollständige Lese-/Schreibpfade außerhalb des Heaps.
- In-Memory-Komprimierungen
- HBase-Cluster unterstützt Premium ADLS Gen2
- Leistungsvorteil
- Bei „Beschleunigte Schreibvorgänge“ werden verwaltete Azure-Premium-SSD-Datenträger zur Verbesserung der Leistung des Apache HBase-Write-Ahead-Protokolls (Write Ahead Log, WAL) verwendet.
- Sicherheit
- Härtung von sekundären Indizes, die „Lokal“ und „Global“ enthalten
Kafka
- Erweiterte Funktionen
- Kafka-Partitionsverteilung auf Azure-Fehlerdomänen
- Support für Zstd-Komprimierung
- Inkrementelles Ausgleichen von Kafka-Consumer
- Support von MirrorMaker 2.0
- Leistungsvorteil
- Verbesserte Leistung der Fensteraggregation in Kafka Streams
- Verbesserte Broker-Resilienz durch Reduzierung des Speicherbedarfs der Nachrichtenkonvertierung
- Verbesserungen des Replikationsprotokolls für schnelles Leader-Failover
- Sicherheit
- Zugriffssteuerung für die Themenerstellung für bestimmte Themen/Themenpräfixe
- Überprüfung des Hostnamens zur Verhinderung von Man-in-the-Middle-Angriffen auf die SSL-Konfiguration
- Verbesserte Verschlüsselungsunterstützung mit schnellerer Transport Layer Security (TLS) und CRC32C-Implementierung
Spark
- Erweiterte Funktionen
- Strukturiertes Streaming: Support für ORC
- Funktion zur Integration in das neue Metastore-Katalogfeature
- Support für strukturiertes Streaming für die Hive Streaming-Bibliothek
- Transparenter Schreibzugriff auf Hive-Lager
- Spark Cruise – ein System zur automatischen Wiederverwendung von Berechnungsergebnissen für Spark.
- Leistungsvorteil
- Zwischenspeichern von Ergebnissen – Das Zwischenspeichern von Abfrageergebnissen ermöglicht die Wiederverwendung eines zuvor berechneten Abfrageergebnisses
- Dynamische materialisierte Sichten – Vorabberechnungsergebnis von Zusammenfassungen
- Sicherheit
- DSGVO-Compliance für Spark-Transaktionen aktiviert
Erkennung und Reparatur von Hive-Partitionen
Hive erkennt automatisch die Metadaten der Partition im Hive-Metastore und synchronisiert sie.
Die discover.partitions Table-Eigenschaft aktiviert und deaktiviert die Synchronisierung des Dateisystems mit Partitionen. In externen partitionierten Tabellen ist diese Eigenschaft standardmäßig aktiviert (true).
Wenn Hive Metastore Service (HMS) im Remotedienstmodus gestartet wird, wird regelmäßig alle 300 s ein Hintergrund-Thread (PartitionManagementTask) geplant (konfigurierbar über metastore.partition.management.task.frequency config), der nach Tabellen discover.partitions sucht, deren Tabelleneigenschaft auf „true“ gesetzt ist, und eine Reparatur msck im Synchronisierungsmodus durchführt.
Wenn die Tabelle eine Transaktionstabelle ist, wird die exklusive Sperre für diese Tabelle abgerufen, bevor Sie msck repair ausführen. Mit dieser Tabelleneigenschaft muss MSCK REPAIR TABLE table_name SYNC PARTITIONS nicht mehr manuell ausgeführt werden.
Angenommen, Sie haben eine externe Tabelle, die mithilfe einer Version von Hive erstellt wurde, die die Partitionsermittlung nicht unterstützt, aktivieren Sie die Partitionsermittlung für die Tabelle.
ALTER TABLE exttbl SET TBLPROPERTIES ('discover.partitions' = 'true');
Stellen Sie die Synchronisierung von Partitionen so ein, dass sie alle 10 Minuten in Sekunden erfolgt: In Ambari > Hive > Configs, set metastore.partition.management.task.frequency auf 3600 oder mehr.
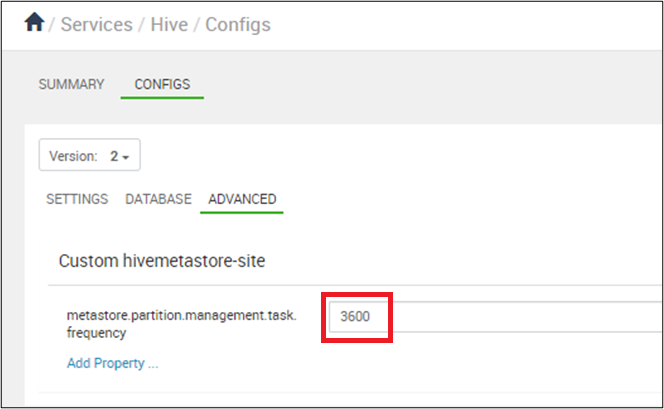
Warnung
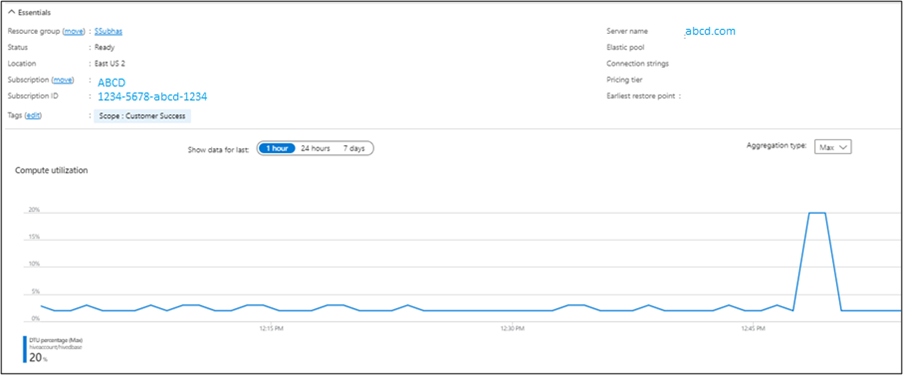
Wenn management.task alle 10 Minuten ausgeführt wird, erfolgt eine Auslastung auf der SQL-Server-DTU.
Sie können die Ausgabe im Microsoft Azure-Portal überprüfen.
Hive legt die Metadaten und die entsprechenden Daten in jeder Partition ab, die nach Ablauf des Aufbewahrungszeitraums erstellt wurde. Sie drücken die Aufbewahrungszeit mit einer Zahl und dem oder den folgenden Zeichen aus. Hive legt die Metadaten und die entsprechenden Daten in jeder Partition ab, die nach Ablauf des Aufbewahrungszeitraums erstellt wurde. Sie drücken die Aufbewahrungszeit mit einer Zahl und dem folgenden Zeichen aus.
ms (milliseconds)
s (seconds)
m (minutes)
d (days)
So konfigurieren Sie einen Aufbewahrungszeitraum für Partitionen von einer Woche.
ALTER TABLE employees SET TBLPROPERTIES ('partition.retention.period'='7d');
Die Partitionsmetadaten und die tatsächlichen Daten für Mitarbeiter in Hive werden nach einer Woche automatisch gelöscht.
Hive 3
Leistungsoptimierungen unter Hive 3 verfügbar
OLAP-Vektorisierung Dynamische Semijoin-Reduktion Parquet-Support für die Vektorisierung mit automatischem LLAP-Abfragecache.
Neue SQL-Features
Ersatzschlüsseleinschränkungen für materialisierte Sichten Metastore-CachedStore.
OLAP-Vektorisierung
Durch die Vektorisierung kann Hive einen Batch von Zeilen gleichzeitig verarbeiten, anstatt jeweils eine Zeile zu verarbeiten. Jeder Batch ist in der Regel ein Array von primitiven Typen. Vorgänge werden am gesamten Spaltenvektor durchgeführt, wodurch die Anweisungspipelines und die Cachenutzung verbessert werden. Vektorisierte Ausführung von PTF, Ausführen von Rollup und Gruppierungssätze.
Dynamische Semijoin Reduzierung
Verbessert die Leistung für selektive Verknüpfungen erheblich. Erstellt einen Bloom-Filter von einer Seite der Verknüpfung auf und filtert Zeilen von der anderen Seite. Überspringt die Überprüfung und weitere Auswertung von Zeilen, die die Verknüpfung nicht qualifizieren würden.
Parquet-Support für die Vektorisierung mit LLAP
Die vektorisierte Abfrageausführung ist ein Feature, das die CPU-Auslastung für typische Abfragevorgänge stark reduziert, wie z. B.
- Überprüfungen
- Filter
- aggregate
- Joins
Die Vektorisierung wird auch für das ORC-Format implementiert. Spark verwendet seit Spark 2.0 auch Whole-Stage-CodeGen und diese Vektorisierung (für Parquet). Zeitstempelspalte für Parquet-Vektorisierung und -Format unter LLAP hinzugefügt.
Warnung
Parquet-Schreibvorgänge sind langsam, wenn sie vom Zeitstempel in Zonenzeiten konvertiert werden. Weitere Informationen finden Sie hier.
Automatischer Abfragecache
- Mit
hive.query.results.cache.enabled=truespeichert jede in Hive 3 ausgeführte Abfrage ihr Ergebnis in einem Cache. - Wenn sich die Eingabetabelle ändert, entfernt Hive ungültige Daten aus dem Cache. Wenn Sie beispielsweise eine Aggregation durchführen und die Basistabelle ändert, bleiben die am häufigsten ausgeführten Abfragen im Cache, veraltete Abfragen werden jedoch entfernt.
- Der Cache für Abfrageergebnisse funktioniert nur mit verwalteten Tabellen, da Hive Änderungen an einer externen Tabelle nicht nachverfolgen kann.
- Wenn Sie externe und verwaltete Tabellen verknüpfen, greift Hive auf die Ausführung der vollständigen Abfrage zurück. Der Cache für Abfrageergebnisse funktioniert mit ACID-Tabellen. Wenn Sie eine ACID-Tabelle aktualisieren, führt Hive die Abfrage automatisch erneut aus.
- Sie können den Cache für Abfrageergebnisse aus der Befehlszeile aktivieren und deaktivieren. Dies kann zum Debuggen einer Abfrage sinnvoll sein.
- Deaktivieren Sie den Cache für Abfrageergebnisse, indem Sie den folgenden Parameter auf „false“ festlegen:
hive.query.results.cache.enabled=false - Hive speichert den Cache für Abfrageergebnisse in
/tmp/hive/__resultcache__/. Standardmäßig weist Hive 2 GB für den Cache für Abfrageergebnisse zu. Sie können diese Einstellung ändern, indem Sie den folgenden Parameter in Bytes konfigurieren:hive.query.results.cache.max.size - Änderungen an der Abfrageverarbeitung: Überprüfen Sie während der Abfragekompilierung den Ergebniscache, um festzustellen, ob die Abfrageergebnisse bereits vorhanden sind. Wenn ein Cachetreffer vorhanden ist, wird der Abfrageplan auf
FetchTaskfestgelegt, der vom zwischengespeicherten Speicherort gelesen wird.
Während der Abfrageausführung:
Parquet DataWriteableWriter basiert darauf NanoTimeUtils, ein Zeitstempelobjekt in einen binären Wert zu konvertieren. Diese Abfrage ruft toString() für das Zeitstempel-Objekt auf und parst dann die Zeichenfolge.
- Wenn der Ergebniscache für diese Abfrage verwendet werden kann
- Die Abfrage liest
FetchTaskaus dem zwischengespeicherten Ergebnisverzeichnis. - Es sind keine Clusteraufgaben erforderlich.
- Die Abfrage liest
- Wenn der Ergebniscache nicht verwendet werden kann, führen Sie die Clusteraufgaben wie gewohnt aus
- Überprüfen Sie, ob die berechneten Abfrageergebnisse dem Ergebniscache hinzugefügt werden können.
- Wenn Ergebnisse zwischengespeichert werden können, werden die für die Abfrage generierten temporären Ergebnisse im Ergebniscache gespeichert. Möglicherweise müssen Sie hier Schritte ausführen, um sicherzustellen, dass die Abfragebereinigung das Abfrageergebnisverzeichnis nicht löscht.
SQL-Features
Materialisierte Sichten
Die in Apache Hive 3.0.0 eingeführte erste Implementierung konzentriert sich auf die Einführung materialisierter Sichten und das automatische Umschreiben von Abfragen basierend auf diesen Materialisierungen im Projekt. Materialisierte Sichten können nativ in Hive oder in anderen benutzerdefinierten Speicher-Handlern (ORC) gespeichert werden, und sie können nahtlos neue Hive-Funktionen wie LLAP-Beschleunigung nutzen.
Weitere Informationen finden Sie unter Hive – Materialisierte Sichten – Microsoft Tech Community
Ersatzschlüssel
Verwenden Sie die integrierte SURROGATE_KEY benutzerdefinierte Funktion (UDF), um numerische IDs automatisch für Zeilen zu generieren, wenn Sie Daten in eine Tabelle eingeben. Die generierten Ersatzschlüssel können breite, mehrfach zusammengesetzte Schlüssel ersetzen.
Hive unterstützt die Ersatzschlüssel nur für ACID-Tabellen. Die Tabelle, die Sie mit Ersatzschlüsseln verknüpfen möchten, darf keine Spaltentypen haben, die umgewandelt werden müssen. Diese Datentypen müssen Primitiven sein, z. B. INT oder STRING.
Verknüpfungen mit den generierten Schlüsseln sind schneller als Verknüpfungen mit Zeichenfolgen. Die Verwendung generierter Schlüssel erzwingt keine Daten in einen einzelnen Knoten durch eine Zeilennummer. Sie können Schlüssel als Abstraktionen von natürlichen Schlüsseln generieren. Ersatzschlüssel haben einen Vorteil gegenüber UUIDs, die langsamer und probabilistisch sind.
Die SURROGATE_KEY UDF generiert eine eindeutige ID für jede Zeile, die Sie in eine Tabelle einfügen.
Sie generiert Schlüssel basierend auf der Ausführungsumgebung in einem verteilten System, das viele Faktoren enthält, z. B.
- Interne Datenstrukturen
- Zustand einer Tabelle
- Letzte Transaktions-ID.
Die Generierung von Ersatzschlüsseln erfordert keine Koordination zwischen Berechnungsaufgaben. Die UDF verwendet keine Argumente, oder zwei Argumente sind
- Schreiben von ID-Bits
- Aufgaben von ID-Bits
Einschränkungen
SQL-Einschränkungen, um die Datenintegrität zu erzwingen und die Leistung zu verbessern. Der Optimierer verwendet die Einschränkungsinformationen, um intelligente Entscheidungen zu treffen. Einschränkungen können Daten vorhersehbar und leicht auffindbar machen.
| Einschränkungen | BESCHREIBUNG |
|---|---|
| Prüfen | Beschränkt den Wertebereich, den Sie in einer Spalte platzieren können. |
| PRIMARY KEY | Identifiziert jede Zeile in einer Tabelle mithilfe eines eindeutigen Bezeichners. |
| FOREIGN KEY | Identifiziert eine Zeile in einer anderen Tabelle mit einem eindeutigen Bezeichner. |
| EINDEUTIGER SCHLÜSSEL | Überprüft, ob in einer Spalte gespeicherte Werte unterschiedlich sind. |
| NOT NULL | Stellt sicher, dass eine Spalte nicht auf NULL festgelegt werden kann. |
| ENABLE | Stellt sicher, dass alle eingehenden Daten der Einschränkung entsprechen. |
| DISABLE | Stellt nicht sicher, dass alle eingehenden Daten der Einschränkung entsprechen. |
| VALIDATEC | Überprüft, ob alle vorhandenen Daten in der Tabelle der Einschränkung entsprechen. |
| NOVALIDATE | Überprüft nicht, ob alle vorhandenen Daten in der Tabelle der Einschränkung entsprechen. |
| ENFORCED | Karten zu ENABLE NOVALIDATE. |
| NOT ENFORCED | Karten zu DISABLE NOVALIDATE. |
| RELY | Gibt eine Einschränkung an; wird vom Optimierer verwendet, um weitere Optimierungen anzuwenden. |
| NORELY | Gibt keine Einschränkung an. |
Weitere Informationen finden Sie unter https://cwiki.apache.org/confluence/display/Hive/Supported+Features%3A++Apache+Hive+3.1.
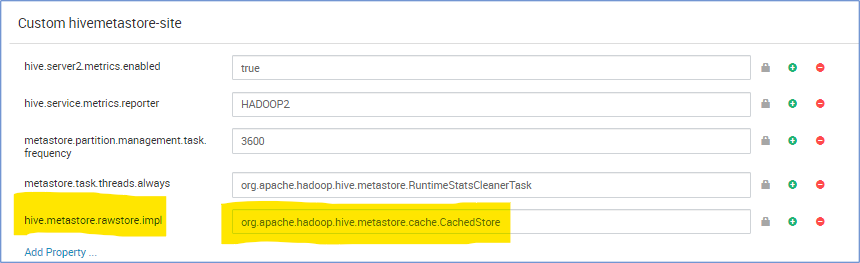
Metastore CachedStore
Der Hive-Metastore-Vorgang nimmt viel Zeit in Anspruch und verlangsamt somit die Hive-Kompilierung. In einigen Extremfällen dauert das viel länger als die tatsächliche Abfragelaufzeit. Insbesondere stellen wir fest, dass die Wartezeit von Cloud DB hoch ist und 90 % der gesamten Abfragelaufzeit auf Vorgängen der Metastore-SQL-Datenbank wartet. Basierend auf dieser Beobachtung wird die Leistung des Metastore-Vorgangs verbessert, wenn wir eine Speicherstruktur haben, die das Ergebnis der Datenbankabfrage zwischenspeichert.
hive.metastore.rawstore.impl=org.apache.hadoop.hive.metastore.cache.CachedStore
Handbuch zur Problembehandlung
Das HDInsight 3.6 zu 4.0-Handbuch zur Problembehandlung bei Hive-Workloads enthält Lösungen für häufige Probleme bei der Migration von Hive-Workloads von HDInsight 3.6 zu HDInsight 4.0.
References
Hive 3.1.0
HBase 2.1.6
https://apache.googlesource.com/hbase/+/ba26a3e1fd5bda8a84f99111d9471f62bb29ed1d/RELEASENOTES.md
Hadoop 3.1.1
Weitere Informationsquellen
- Ankündigung von HDInsight 4.0
- HDInsight 4.0 deep dive (Ausführliche Informationen zu HDInsight 4.0)
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für