Tutorial: Verwenden von Apache HBase in Azure HDInsight
Dieses Tutorial zeigt, wie Sie in Azure HDInsight einen Apache HBase-Cluster erstellen, HBase-Tabellen anlegen und Tabellen mit Apache Hive abfragen können. Allgemeine Informationen zu HBase finden Sie in der Übersicht über HDInsight HBase.
In diesem Tutorial lernen Sie Folgendes:
- Erstellen eines Apache HBase-Clusters
- Erstellen von HBase-Tabellen und Einfügen von Daten
- Verwenden von Apache Hive zum Abfragen von Apache HBase
- Verwenden der HBase-REST-APIs mit Curl
- Überprüfen des Clusterstatus
Voraussetzungen
Einen SSH-Client. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit HDInsight (Hadoop) per SSH.
Bash. In den Beispielen dieses Artikels wird die Bash-Shell unter Windows 10 für die cURL-Befehle verwendet. Die Installationsschritte finden Sie unter Windows Subsystem for Linux Installation Guide for Windows 10 (Windows-Subsystem für Linux: Installationshandbuch für Windows 10). Es funktionieren auch andere Unix-Shells. Die cURL-Beispiele können mit einigen geringfügigen Änderungen auch an einer Windows-Eingabeaufforderung verwendet werden. Alternativ dazu können Sie das Windows PowerShell-Cmdlet Invoke-RestMethod verwenden.
Erstellen eines Apache HBase-Clusters
Im folgenden Verfahren wird eine Azure Resource Manager-Vorlage verwendet, um einen HBase-Cluster zu erstellen. Mit der Vorlage wird auch das abhängige Azure Storage-Standardkonto erstellt. Informationen zu den Parametern, die in diesem Verfahren und in anderen Verfahren zur Clustererstellung verwendet werden, finden Sie unter Erstellen von Linux-basierten Hadoop-Clustern in HDInsight.
Wählen Sie die folgende Abbildung aus, um die Vorlage im Azure-Portal zu öffnen. Die Vorlage finden Sie unter Azure-Schnellstartvorlagen.

Geben Sie im Dialogfeld Benutzerdefinierte Bereitstellung die folgenden Werte ein:
Eigenschaft BESCHREIBUNG Subscription Wählen Sie Ihr Azure-Abonnement aus, das zum Erstellen des Clusters verwendet wird. Resource group Erstellen Sie eine neue Azure Resource Management-Gruppe, oder verwenden Sie eine vorhandene Ressourcengruppe. Position Geben Sie den Standort der Ressourcengruppe an. ClusterName Geben Sie einen Namen für den HBase-Cluster ein. Clusteranmeldename und Kennwort Der Standardanmeldename lautet admin.SSH-Benutzername und Kennwort Der Standardbenutzername lautet sshuser.Andere Parameter sind optional.
Jeder Cluster verfügt über eine Abhängigkeit von einem Azure Storage-Konto. Nach dem Löschen eines Clusters verbleiben die Daten im Speicherkonto. Zur Bildung des Standardnamens für das Speicherkonto des Clusters wird „store“ an den Clusternamen angehängt. Er ist im Variablenabschnitt der Vorlage hartcodiert.
Wählen Sie Ich stimme den oben genannten Geschäftsbedingungen zu, und wählen Sie anschließend Kaufen aus. Das Erstellen eines Clusters dauert ca. 20 Minuten.
Nachdem Sie den HBase-Cluster gelöscht haben, können Sie im gleichen Standardblobcontainer einen neuen HBase-Cluster erstellen. Der neue Cluster übernimmt die im vorherigen Cluster erstellten HBase-Tabellen. Es wird empfohlen, die HBase-Tabellen vor dem Löschen des Clusters zu deaktivieren, um Inkonsistenzen zu vermeiden.
Erstellen von Tabellen und Einfügen von Daten
Sie können SSH verwenden, um eine Verbindung mit Apache HBase-Clustern herzustellen, und dann mithilfe von Apache HBase Shell HBase-Tabellen erstellen, Daten einfügen und Daten abfragen.
Den meisten Benutzern werden die Daten im Tabellenformat angezeigt:

In HBase (eine Implementierung von Cloud BigTable) sehen die gleichen Daten wie folgt aus:

So verwenden Sie die HBase-Shell
Verwenden Sie zum Herstellen der Verbindung mit Ihrem HBase-Cluster
ssh. Bearbeiten Sie den folgenden Befehl, indem SieCLUSTERNAMEdurch den Namen Ihres Clusters ersetzen, und geben Sie den Befehl dann ein:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netVerwenden Sie den Befehl
hbase shell, um die interaktive HBase-Shell zu starten. Geben Sie den folgenden Befehl in Ihrer SSH-Verbindung ein:hbase shellVerwenden Sie den Befehl
create, um eine HBase-Tabelle mit zwei Spaltenfamilien zu erstellen. Für die Tabellen- und Spaltennamen wird die Groß-/Kleinschreibung beachtet. Geben Sie den folgenden Befehl ein:create 'Contacts', 'Personal', 'Office'Verwenden Sie den Befehl
list, um alle Tabellen in HBase aufzulisten. Geben Sie den folgenden Befehl ein:listVerwenden Sie den Befehl
put, um Werte in einer angegebenen Spalte einer angegebenen Zeile in einer bestimmten Tabelle einzufügen. Geben Sie die folgenden Befehle ein:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Verwenden Sie den Befehl
scan, um die Daten der TabelleContactszu überprüfen und zurückzugeben. Geben Sie den folgenden Befehl ein:scan 'Contacts'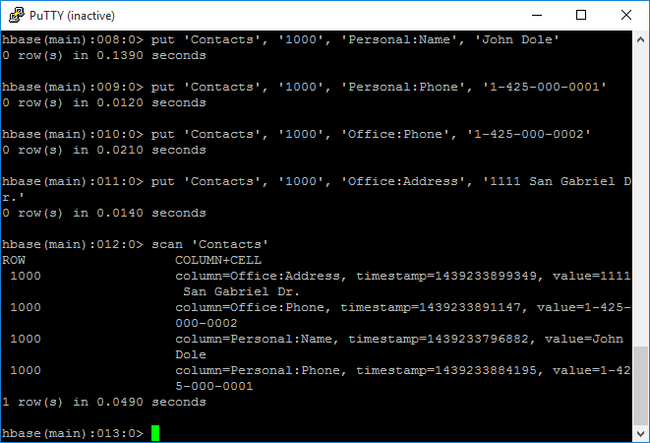
Verwenden Sie den Befehl
get, um den Inhalt einer Zeile abzurufen. Geben Sie den folgenden Befehl ein:get 'Contacts', '1000'Sie erhalten ähnliche Ergebnisse wie mit dem Befehl
scan, da nur eine Zeile vorhanden ist.Weitere Informationen zum HBase-Tabellenschema finden Sie unter Einführung in das Apache HBase-Schemadesign. Beschreibungen weiterer HBase-Befehle finden Sie im Apache HBase-Referenzhandbuch.
Verwenden Sie den Befehl
exit, um die interaktive HBase-Shell zu beenden. Geben Sie den folgenden Befehl ein:exit
So laden Sie Massendaten in die HBase-Kontakttabelle hoch
HBase bietet mehrere Methoden zum Laden von Daten in Tabellen. Weitere Informationen finden Sie unter Laden von Massendaten.
Eine Datei mit Beispieldaten finden Sie in einem öffentlichen Blobcontainer: wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. Diese Datendatei hat folgenden Inhalt:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
Sie haben die Option, eine Textdatei zu erstellen und die Datei in Ihr eigenes Speicherkonto hochzuladen. Anweisungen hierzu finden Sie unter Hochladen von Daten für Apache Hadoop-Aufträge in HDInsight.
In der folgenden Prozedur wird die soeben erstellte HBase-Tabelle Contacts verwendet.
Führen Sie über Ihre geöffnete SSH-Verbindung den folgenden Befehl aus, um die Datendatei in das StoreFiles-Format zu konvertieren und unter dem mit
Dimporttsv.bulk.outputangegebenen relativen Pfad zu speichern.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtFühren Sie den folgenden Befehl aus, um die Daten aus
/example/data/storeDataFileOutputin der HBase-Tabelle hochzuladen:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsSie können die HBase-Shell öffnen und den Tabelleninhalt mit dem Befehl
scanauflisten.
Verwenden von Apache Hive zum Abfragen von Apache HBase
Sie können Daten in HBase-Tabellen mithilfe von Apache Hive abfragen. In diesem Abschnitt erstellen Sie eine Ihrer HBase-Tabelle zugeordnete Hive-Tabelle, mit der Sie die Daten Ihrer HBase-Tabelle abfragen.
Verwenden Sie über Ihre geöffnete SSH-Verbindung den folgenden Befehl, um Beeline zu starten:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminWeitere Informationen zu Beeline finden Sie unter Verwenden von Hive mit Hadoop in HDInsight über Beeline.
Führen Sie das folgende HiveQL-Skript aus, um eine der HBase-Tabelle zugeordnete Hive-Tabelle zu erstellen. Stellen Sie vor Ausführung dieser Anweisung sicher, dass Sie mithilfe der HBase-Shell die zuvor in diesem Artikel erwähnte Beispieltabelle erstellt haben.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Führen Sie das folgende HiveQL-Skript aus, um die Daten in der HBase-Tabelle abzufragen:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Verwenden Sie
!exit, um Beeline zu beenden.Verwenden Sie zum Beenden Ihrer SSH-Verbindung den Befehl
exit.
Separate Hive- und HBase-Cluster
Die Hive-Abfrage für den Zugriff auf HBase-Daten muss nicht aus dem HBase-Cluster ausgeführt werden. Alle Cluster, die über Hive verfügen (einschließlich Spark, Hadoop, HBase oder Interactive Query), können zum Abfragen von HBase-Daten verwendet werden, sofern die folgenden Schritte ausgeführt wurden:
- Beide Cluster müssen an dasselbe virtuelle Netzwerk und Subnetz angefügt werden.
- Kopieren Sie
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmlvon den Hauptknoten des HBase-Clusters auf die Haupt- und Workerknoten des Hive-Clusters.
Sichere Cluster
HBase-Daten können auch über Hive abgefragt werden, indem HBase mit aktiviertem Enterprise-Sicherheitspaket (ESP) verwendet wird:
- Bei Verwendung eines Musters mit mehreren Clustern muss für beide Cluster ESP aktiviert sein.
- Stellen Sie sicher, dass dem Benutzer
hiveBerechtigungen zum Zugreifen auf die HBase-Daten über das Apache Ranger-Plug-In von HBase gewährt werden, um für Hive das Abfragen der HBase-Daten zu ermöglichen. - Bei Verwendung von separaten ESP-fähigen Clustern muss der Inhalt von
/etc/hostsvon den Hauptknoten des HBase-Clusters an die Datei/etc/hostsder Haupt- und Workerknoten des Hive-Clusters angefügt werden.
Hinweis
Nachdem beide Cluster skaliert wurden, muss /etc/hosts erneut angefügt werden.
Verwenden der HBase-REST-API über Curl
Die HBase-REST-API wird durch Standardauthentifizierung geschützt. Sie sollten Anforderungen immer über HTTPS (Secure HTTP) stellen, um sicherzustellen, dass Ihre Anmeldeinformationen sicher an den Server gesendet werden.
Fügen Sie das folgende benutzerdefinierte Startskript im Abschnitt Skriptaktion hinzu, um die HBase-REST-API im HDInsight-Cluster zu aktivieren. Sie können das Startskript beim Erstellen des Clusters oder nach Abschluss des Vorgangs hinzufügen. Wählen Sie unter Knotentyp die Option Regionsserver aus, um sicherzustellen, dass das Skript nur auf HBase-Regionsservern ausgeführt wird. Skript startet den HBase REST-Proxy auf 8090-Port auf Regionsservern.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiLegen Sie die Umgebungsvariable fest, um für Benutzerfreundlichkeit zu sorgen. Bearbeiten Sie die folgenden Befehle, indem Sie
MYPASSWORDdurch das Kennwort für die Anmeldung am Cluster ersetzen. Ersetzen SieMYCLUSTERNAMEdurch den Namen Ihres HBase-Clusters. Geben Sie anschließend die Befehle ein.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEVerwenden Sie den folgenden Befehl, um die vorhandenen HBase-Tabellen aufzulisten:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Verwenden Sie den folgenden Befehl, um eine neue HBase-Tabelle mit zwei Spaltenfamilien zu erstellen:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vDas Schema wird im JSON-Format bereitgestellt.
Fügen Sie mit dem folgenden Befehl Daten ein:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vCodieren Sie die im -d-Switch angegebenen Werte mit Base64. Im Beispiel:
MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Persönlich: Name
Sm9obiBEb2xl: John Dole
Mit false-row-key können Sie mehrere Werte (Batchwerte) einfügen.
Rufen Sie mit dem folgenden Befehl eine Zeile ab:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Hinweis
Die Überprüfung des Clusterendpunkts wird noch nicht unterstützt.
Weitere Informationen zu HBase-REST finden Sie im Referenzleitfaden zu Apache HBase.
Hinweis
Thrift wird von HBase in HDInsight nicht unterstützt.
Wenn Sie Curl oder eine andere REST-Kommunikation mit WebHCat verwenden, müssen Sie die Anforderungen authentifizieren, indem Sie den Benutzernamen und das Kennwort des Administrators des HDInsight-Clusters bereitstellen. Sie müssen auch den Clusternamen als Teil des URIs (Uniform Resource Identifier) verwenden, um die Anforderungen an den Server zu senden.
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Sie sollten eine Antwort empfangen, die in etwa der folgenden entspricht:
{"status":"ok","version":"v1"}
Überprüfen des Clusterstatus
HBase in HDInsight wird mit einer Web-Benutzeroberfläche ausgeliefert, über die Cluster überwacht werden können. In dieser Web-Benutzeroberfläche können Sie Statistiken und Informationen zu Regionen anfordern.
So greifen Sie auf die HBase Master-Benutzeroberfläche zu
Melden Sie sich unter
https://CLUSTERNAME.azurehdinsight.netbei der Benutzeroberfläche von Ambari Web an, wobeiCLUSTERNAMEder Name Ihres HBase-Clusters ist.Wählen Sie im linken Menü HBase aus.
Klicken Sie am oberen Rand der Seite auf Quicklinks, zeigen Sie auf den aktiven Zookeeper-Knotenlink, und klicken Sie anschließend auf HBase Master-Benutzeroberfläche. Die Benutzeroberfläche wird in einer anderen Browserregisterkarte geöffnet:
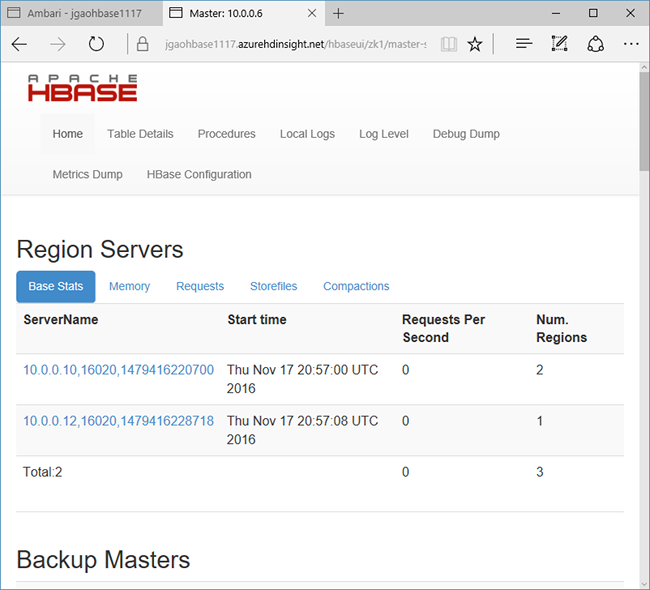
Die HBase Master-Benutzeroberfläche enthält folgende Abschnitte:
- Regionsserver
- Backup Master
- Tabellen
- Tasks
- Softwareattribute
Neuerstellung des Clusters
Nachdem Sie den HBase-Cluster gelöscht haben, können Sie im gleichen Standardblobcontainer einen neuen HBase-Cluster erstellen. Der neue Cluster übernimmt die im vorherigen Cluster erstellten HBase-Tabellen. Es wird jedoch empfohlen, die HBase-Tabellen vor dem Löschen des Clusters zu deaktivieren, um Inkonsistenzen zu vermeiden.
Sie können den HBase-Befehl disable 'Contacts' verwenden.
Bereinigen von Ressourcen
Wenn Sie diese Anwendung nicht mehr benötigen, gehen Sie wie folgt vor, um den erstellten HBase-Cluster zu löschen:
- Melden Sie sich beim Azure-Portal an.
- Geben Sie oben im Suchfeld den Suchbegriff HDInsight ein.
- Wählen Sie unter Dienste die Option HDInsight-Cluster aus.
- Klicken Sie in der daraufhin angezeigten Liste mit den HDInsight-Clustern neben dem Cluster, den Sie für dieses Tutorial erstellt haben, auf die Auslassungspunkte ( ... ).
- Klicken Sie auf Löschen. Klicken Sie auf Ja.
Nächste Schritte
In diesem Tutorial haben Sie gelernt, wie Sie einen Apache HBase-Cluster erstellen. Sie haben auch gelernt, wie Sie mit der HBase-Shell Tabellen erstellen und die Daten in diesen Tabellen anzeigen. Darüber hinaus wissen Sie jetzt, wie Sie eine Hive-Abfrage mit Daten in HBase-Tabellen verwenden. Außerdem haben Sie gelernt, wie Sie die C#-REST-API für HBase verwenden, um eine HBase-Tabelle zu erstellen und Daten aus dieser Tabelle abzurufen. Weitere Informationen finden Sie unter: