Problembehandlung für Apache Hadoop HDFS mit Azure HDInsight
Lernen Sie die wichtigsten Probleme und ihre Lösungen bei der Arbeit mit HDFS (Hadoop Distributed File System) kennen. Eine vollständige Liste der Befehle finden Sie im HDFS Commands Guide und im File System Shell Guide.
Wie greife ich aus einem Cluster heraus auf das lokale HDFS zu?
Problem
Greifen Sie von der Befehlszeile und aus dem Anwendungscode auf das lokale HDFS zu, und nicht mithilfe des Azure Blob Storage oder des Azure Data Lake Storage aus dem HDInsight-Cluster.
Schritte zur Behebung
Verwenden Sie an der Eingabeaufforderung
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...buchstäblich wie im folgenden Befehl:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userVerwenden Sie den URI
hdfs://mycluster/im Quellcode buchstäblich wie in der folgenden Beispielanwendung:import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }Führen Sie die kompilierte JAR-Datei (z.B. mit dem Namen
java-unit-tests-1.0.jar) auf dem HDInsight-Cluster mit dem folgenden Befehl aus:hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Speicherausnahme beim Schreiben in ein Blob
Problem
Wenn Sie die Befehle hadoop oder hdfs dfs verwenden, um Dateien mit einer Größe von etwa 12 GB oder mehr in einem HBase-Cluster zu schreiben, wird möglicherweise der folgende Fehler angezeigt:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
Ursache
Für HBase in HDInsight-Cluster wird beim Schreiben in den Azure-Speicher standardmäßig eine Blockgröße von 256 KB verwendet. Dies funktioniert bei HBase-APIs oder REST-APIs, bei der Verwendung der Befehlszeilenprogramme hadoop oder hdfs dfs tritt jedoch ein Fehler auf.
Auflösung
Verwenden Sie fs.azure.write.request.size, um eine größere Blockgröße anzugeben. Sie können diese Änderung auf Nutzungsbasis mithilfe des -D-Parameters erreichen. Im folgenden Beispielbefehl wird dieser Parameter mit dem Befehl hadoop verwendet:
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
Sie können auch den Wert von fs.azure.write.request.size mithilfe von Apache Ambari global erhöhen. Die folgenden Schritte können verwendet werden, um den Wert in der Ambari-Webbenutzeroberfläche zu ändern:
Öffnen Sie in Ihrem Browser die Ambari-Webbenutzeroberfläche für den Cluster. Die URL befindet sich unter
https://CLUSTERNAME.azurehdinsight.net, wobeiCLUSTERNAMEder Name Ihres Clusters ist. Geben Sie bei entsprechender Aufforderung den Namen und das Kennwort des Administrators für den Cluster ein.Wählen Sie auf der linken Bildschirmseite HDFS und dann die Registerkarte Configs aus.
Geben Sie in das Feld Filter den Text
fs.azure.write.request.sizeein.Ändern Sie den Wert von 262144 (256 KB) in den neuen Wert. Beispiel: 4194304 (4 MB).
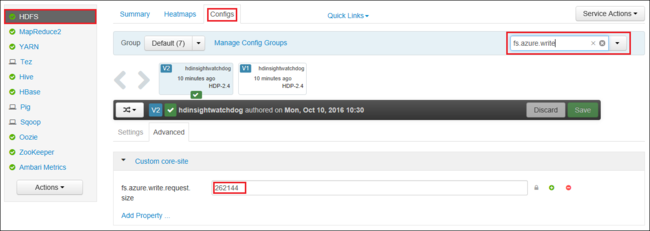
Weitere Informationen zur Verwendung von Ambari finden Sie unter Verwalten von HDInsight-Clustern mithilfe der Apache Ambari-Webbenutzeroberfläche.
du
Mit dem Befehl -du wird die Größe von Dateien und Verzeichnissen in einem jeweiligen Verzeichnis oder die Länge einer Datei angezeigt, sofern es sich lediglich um eine Datei handelt.
Mit der Option -s wird eine aggregierte Zusammenfassung der angezeigten Dateilängen erzeugt.
Mit der Option -h werden die Dateigrößen formatiert.
Beispiel:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
rm
Mit dem -rm-Befehl werden als Argumente angegebene Dateien gelöscht.
Beispiel:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
Nächste Schritte
Wenn Ihr Problem nicht aufgeführt ist oder Sie es nicht lösen können, besuchen Sie einen der folgenden Kanäle, um weitere Unterstützung zu erhalten:
Nutzen Sie den Azure-Communitysupport, um Antworten von Azure-Experten zu erhalten.
Setzen Sie sich mit @AzureSupport in Verbindung, dem offiziellen Microsoft Azure-Konto zum Verbessern der Kundenfreundlichkeit. Verbinden der Azure-Community mit den richtigen Ressourcen: Antworten, Support und Experten.
Sollten Sie weitere Unterstützung benötigen, senden Sie eine Supportanfrage über das Azure-Portal. Wählen Sie dazu auf der Menüleiste die Option Support aus, oder öffnen Sie den Hub Hilfe und Support. Ausführlichere Informationen hierzu finden Sie unter Erstellen einer Azure-Supportanfrage. Zugang zu Abonnementverwaltung und Abrechnungssupport ist in Ihrem Microsoft Azure-Abonnement enthalten. Technischer Support wird über einen Azure-Supportplan bereitgestellt.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für