Schnellstart: Ausführen von Apache Hive-Abfragen in Azure HDInsight mit Apache Zeppelin
In diesem Schnellstart erfahren Sie, wie Sie mit Apache Zeppelin Apache Hive-Abfragen in Azure HDInsight ausführen können. Interactive Query-Cluster von HDInsight umfassen Apache Zeppelin-Notebooks, mit denen Sie interaktive Hive-Abfragen ausführen können.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Ein HDInsight Interactive Query-Cluster. Weitere Informationen zum Erstellen eines HDInsight-Clusters finden Sie unter Erstellen von Clustern. Stellen Sie sicher, dass Sie den Clustertyp Interactive Query auswählen.
Erstellen einer Apache Zeppelin-Notiz
Ersetzen Sie
CLUSTERNAMEdurch den Namen Ihres Clusters in der folgenden URLhttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Geben Sie dann die URL in einem Webbrowser ein.Geben Sie Ihren Benutzernamen und das Kennwort für die Clusteranmeldung ein. Auf der Zeppelin-Seite können Sie entweder eine neue Notiz erstellen oder vorhandene Notizen öffnen. HiveSample enthält einige Hive-Beispielabfragen.
Wählen Sie Neue Notiz erstellen aus.
Geben Sie im Dialogfeld Neue Notiz erstellen die folgenden Werte ein oder wählen Sie sie aus:
- „Note Name“ (Name der Notiz): Geben Sie einen Namen für die Notiz ein.
- Standardinterpreter: Wählen Sie jdbc aus der Dropdownliste aus.
Wählen Sie Notiz erstellen aus.
Geben Sie die folgende Hive-Abfrage in den Codeabschnitt ein, und drücken Sie dann UMSCHALT + EINGABETASTE:
%jdbc(hive) show tables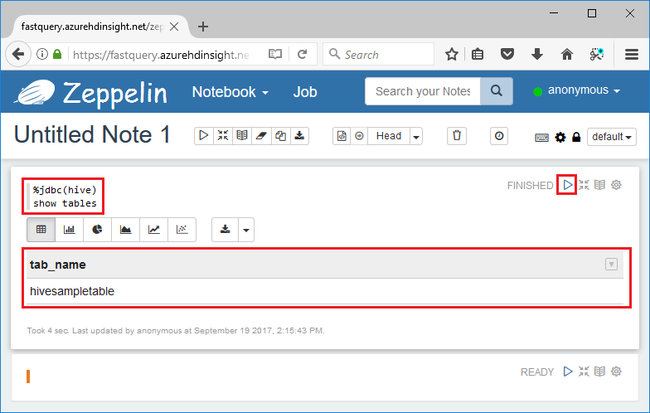
Die
%jdbc(hive)Anweisung in der ersten Zeile weist das Notizbuch an, den Hive SILK-Dolmetscher zu verwenden.Die Abfrage soll eine Hive-Tabelle namens hivesampletable zurückgeben.
Im Folgenden finden Sie zwei weitere Hive-Abfragen, die Sie für strukturesampletableausführen können:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Im Vergleich zur herkömmlichen Struktur kommen die Abfrageergebnisse viel schneller zurück.
Weitere Beispiele
Erstellen einer Tabelle Führen Sie den Code im Zeppelin-Notizbuch aus:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Laden Sie Daten in die neue Tabelle. Führen Sie den Code im Zeppelin-Notizbuch aus:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Fügen Sie einen einzelnen Datensatz ein. Führen Sie den Code im Zeppelin-Notizbuch aus:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Lesen Sie die Struktursprache manuell , um weitere Syntax zu erfahren.
Bereinigen von Ressourcen
Nachdem Sie den Schnellstart abgeschlossen haben, können Sie den Cluster löschen. Mit HDInsight werden Ihre Daten in Azure Storage gespeichert, sodass Sie einen Cluster problemlos löschen können, wenn er nicht verwendet wird. Für einen HDInsight-Cluster fallen auch dann Gebühren an, wenn er nicht verwendet wird. Da die Gebühren für den Cluster erheblich höher sind als die Kosten für den Speicher, ist es sinnvoll, nicht verwendete Cluster zu löschen.
Informationen zum Löschen eines Clusters finden Sie unter Löschen eines HDInsight-Clusters mit Ihrem Browser, PowerShell oder der Azure CLI.
Nächste Schritte
In diesem Schnellstart haben Sie erfahren, wie Sie mit Apache Zeppelin Apache Hive-Abfragen in Azure HDInsight ausführen können. Im nächsten Artikel erfahren Sie, wie Sie Abfragen mit Visual Studio ausführen können, um mehr Informationen über Hive-Abfragen zu erhalten.